Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Fast.ai utiliza métodos y enfoques avanzados en el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... para generar resultados de vanguardia. Este enfoque que discutiremos nos permite entrenar modelos más precisos, más rápidamente, con menos datos y en menos tiempo y dinero.
Fast.ai fue fundado por Jeremy Howard y Raquel thomas para proporcionar a los profesionales del aprendizaje profundo una manera rápida y fácil de lograr resultados de vanguardia en los dominios de aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... estándar del aprendizaje profundo, es decir, Filtrado de visión, texto, tabular y colaborativo.
Ahora comencemos con Fast.ai.
Este tutorial asume tener conocimientos básicos de python3. Se requiere una computadora portátil Jupyter con una GPU, ya que la GPU acelera el proceso de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... en 100 veces en comparación con la CPU. Puedes acceder al mismo desde Colaboratorio de Google que es un entorno de portátil jupyter y proporciona una GPU gratuita. Referir esta para habilitar la GPU gratuita en Colab.
Entrenar un clasificador de imágenes
Entrenemos un clasificador de imágenes MNIST básico usando Fast.ai. El conjunto de datos MNIST consta de imágenes de dígitos escritos a mano del 0 al 9. Por lo tanto, tiene 10 clases y es un problema de clasificación de varias clases. Consta de 60000 imágenes en el conjunto de entrenamiento y 10000 imágenes en el conjunto de validación.
Importaciones
En la primera celda, ejecute lo siguiente para asegurarse de que estén instaladas todas las bibliotecas necesarias. De lo contrario, se instalará la biblioteca fastai y tendrá que reiniciar el tiempo de ejecución.
!pip install fastai --upgrade
Luego, importemos la biblioteca de visión fastai,
from fastai.vision.all import *
Si ha tenido alguna experiencia en programación de Python o desarrollo de software, se preguntará si importar todos los submódulos y funciones de la clase (es decir, usar *) es una práctica poco saludable. Pero la biblioteca fastai está diseñada de tal manera que solo se importan las funciones requeridas y asegura que no habrá ninguna carga innecesaria en la memoria.
Descarga de datos
Ahora, descarguemos los datos requeridos,
path = untar_data(URLs.MNIST)
Aquí usamos una función fastai untar_data que toma la URL del conjunto de datos y descarga y extrae el conjunto de datos y luego devuelve la ruta de los datos. Devuelve un Pathlib’s PosixPath objeto que se puede utilizar para acceder y navegar por los sistemas de archivos con facilidad. Accedemos a la URL del conjunto de datos MNIST desde el fastai URLs método que consta de URL de muchos conjuntos de datos diferentes.
Podemos verificar el contenido en la ruta usando
#to list the contents path.ls()
Podemos ver que hay dos carpetas. capacitación y pruebas que consta de datos de entrenamiento y datos de validación, respectivamente.
Cargando datos
Ahora podemos cargar los datos,
dls = ImageDataLoaders.from_folder(path=path,
train='training',
valid='testing',
shuffle=True)
ImageDataLoaders es uno de los tipos de clases que usamos para cargar conjuntos de datos para problemas de visión por computadora. Generalmente, los conjuntos de datos de visión por computadora están estructurados de tal manera que la etiqueta de una imagen es el nombre de la carpeta en la que está presente la imagen. Como nuestro conjunto de datos está estructurado de esa manera, usamos un método from_folder para cargar las imágenes de las carpetas en la ruta dada.
Especificamos la ruta del conjunto de datos desde donde se cargan las imágenes en lotes, especificamos el nombre de las carpetas que consisten en datos de entrenamiento y validación que se usarán para entrenamiento y validación, y luego inicializamos barajar a True, lo que garantiza que mientras el modelo se entrena, las imágenes se mezclan y se introducen en el modelo.
Para obtener más información sobre cualquier función fastai, podemos usar el método doc () que muestra la breve documentación sobre esa función.
doc(ImageDataLoaders.from_folder)
Podemos ver algunos de los datos usando show_batch () método,
dls.train.show_batch() dls.valid.show_batch()
Muestra algunas imágenes del conjunto de entrenamiento y del conjunto de validación respectivamente.
Entrenamiento de modelos
Ahora creemos el modelo,
learn = cnn_learner(dls,
resnet18,
metrics=[accuracy, error_rate])
Aquí estamos usando cnn_learner es decir, especificar fastai para construir un modelo de red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... a partir de la arquitectura dada, es decir resnet18 y entrenar en el cargador de datos especificado, es decir dls y realizar un seguimiento de las métricas proporcionadas, es decir precisión y Tasa de error.
CNN es el enfoque actual de vanguardia para la creación de modelos de visión por computadora. Aquí estamos usando una técnica llamada transferencia de aprendizaje para entrenar nuestro modelo. Esta técnica utiliza un Modelo preentrenado es decir, una arquitectura estándar y ya entrenada para un propósito diferente. Entremos en detalle en la siguiente sección.
Ahora entrenemos (en realidad, afinemos) el modelo,
Podemos ver que el modelo comienza a entrenarse con datos durante 4 épocas. Los resultados se parecen a los siguientes,
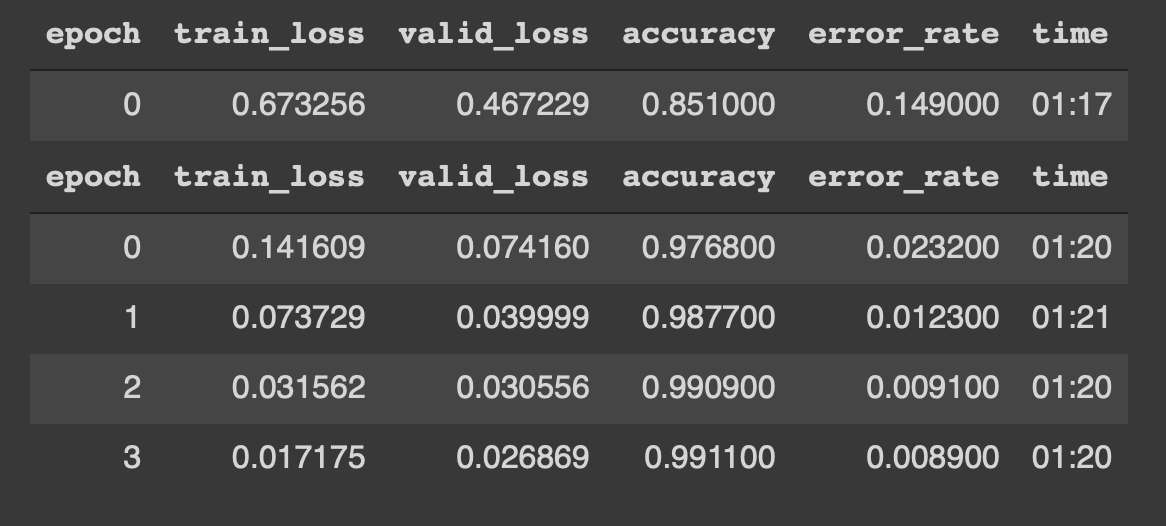
¡¡Woah !! una precisión del 99% y casi un 0,8% de error_rate son, literalmente, resultados de vanguardia. Además, pudimos lograr esto con solo 4 épocas, 5 líneas de código y 5 minutos de entrenamiento.
Poner juntos,
from fastai.vision.all import *
path = untar_data(URLs.MNIST)
dls = ImageDataLoaders.from_folder(path=path,
train='training',
valid='testing',
shuffle=True)
learn = cnn_learner(dls,
resnet18,
metrics=[accuracy, error_rate])
learn.fine_tune(4)
Esto es posible gracias a una técnica llamada Transferir aprendizaje. Discutámoslo con cierto detalle.
Transferir aprendizaje
Antes de continuar, debemos conocer los modelos Pretrained.
Modelos previamente entrenados son básicamente arquitecturas que ya están entrenadas en un conjunto de datos diferente y para un propósito diferente. Por ejemplo, hemos utilizado resent18 como nuestra red pre-capacitada. También conocidas como redes residuales, resent18 consta de 18 capas y se entrena en más de un millón de imágenes del conjunto de datos ImageNet. Esta red previamente entrenada puede clasificar fácilmente imágenes en 1000 clases, como libros, lápices, animales, etc. Por lo tanto, este modelo conoce varios objetos y cosas incluso antes de que se entrene en nuestro conjunto de datos. Por eso se llama Red preentrenada.
Ahora, el aprendizaje por transferencia es la técnica que nos permite utilizar un modelo previamente entrenado para una nueva tarea y conjunto de datos. Transferir aprendizaje es básicamente el proceso de usar un modelo pre-entrenado para una tarea diferente a la que fue entrenado originalmente, es decir, en este caso estamos usando resent18 para entrenar en imágenes de dígitos escritos a mano.
Esto es posible debido a un paso fundamental llamado sintonia FINA. Cuando tenemos un modelo previamente entrenado, usamos este paso para actualizar el modelo previamente entrenado de acuerdo con las necesidades de nuestra tarea / datos. El ajuste fino es básicamente una técnica de aprendizaje por transferencia que actualiza los pesos del modelo preentrenado entrenando para algunas épocas en el nuevo conjunto de datos.
Por lo tanto, al utilizar esta técnica podemos lograr resultados de vanguardia en nuestra tarea, es decir, clasificar dígitos escritos a mano.
Ahora hagamos algunas predicciones
Predecir imágenes
Primero, obtengamos todas las rutas de imagen en el conjunto de prueba y luego conviértalas en una imagen y realicemos la predicción.
# get all the image paths from testing folder images = get_image_files(path/'testing')
# select an image and display img = PILImage.create(images[4432]) img
Predecir la imagen
# predict the image class lbl, _ , _ = learn.predict(img) lbl
Informe de clasificación
También podemos generar un informe de clasificación a partir del modelo para inferencia.
interep = ClassificationInterpretation.from_learner(learn) interep.plot_confusion_matrix()
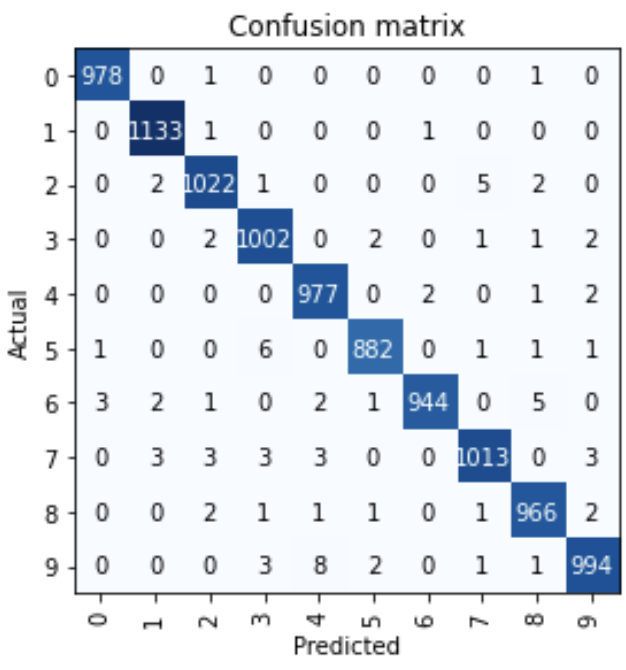
Podemos ver que de casi 10000 imágenes, solo algunas imágenes se clasificaron erróneamente.
¡Gracias y feliz aprendizaje profundo!
Referencias:
1. Aprendizaje profundo práctico para codificadores por Jeremy Howard y Sylvain Gugger
Por Narasimha Karthik J
Puedes conectarte conmigo a través de Linkden o Gorjeo
Los medios que se muestran en este artículo sobre la formación de modelos de aprendizaje profundo de última generación con Fast.ai no son propiedad de DataPeaker y se utilizan a discreción del autor.





