Visión general
- Introducción
- reducir el tiempo de ejecución
- conjunto de datos
- lectura de conjunto de datos
- manejo de variables categóricas
- característica dependiente e independiente
- entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... de modelos con núcleos de CPU
- Nota final
Introducción
«Los 65.536 procesadores estaban dentro de la máquina de conexión»
~ Philip Emeagwali
Todos tenemos experiencia en ciencias de la computación, usamos una computadora a diario y tenemos una mejor comprensión de lo que es la computadora. Las computadoras tienen un corazón como los humanos, se llama CPU.
Todos conocemos la CPU, si no es así, el UPC es la unidad central de procesamiento en la computadora, o es un circuito electrónico que ejecuta las diversas instrucciones que comprenden un programa de computadora. La CPU realiza aritmética básica, lógica, etc.

Las generaciones anteriores de CPU se implementaron como componentes discretos y numerosos circuitos integrados pequeños en una o más placas de circuito. Con el tiempo, las CPU se cambian, se actualizan. Se implementan en un circuito integrado, con una o más CPU en un solo chip IC. Hay muchas funciones u operaciones que realiza la computadora, por lo que lleva mucho tiempo, para eso el científico diseñó el procesadores multinúcleo, era una combinación de chips de microprocesador con múltiples CPU.
Los procesadores de varios núcleos son muy rápidos, pueden funcionar en un tiempo. Como científico de datos, encontramos que algunas de las bibliotecas de Python son muy lentas y también largas, ralentizan la ejecución del programa, se necesita mucho tiempo para la ejecución de nuestros modelos de aprendizaje automático o aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud.... Si desea ver cuántos núcleos hay en su computadora, simplemente abra su PanelUn panel es un grupo de expertos que se reúne para discutir y analizar un tema específico. Estos foros son comunes en conferencias, seminarios y debates públicos, donde los participantes comparten sus conocimientos y perspectivas. Los paneles pueden abordar diversas áreas, desde la ciencia hasta la política, y su objetivo es fomentar el intercambio de ideas y la reflexión crítica entre los asistentes.... de control y buscar sistema verá toda la información sobre su computadora.

Si hablamos de la biblioteca de python panda que se utiliza en el aprendizaje automático para la manipulación de datos y el análisis de datos, si analizamos una pequeña cantidad de datos no llevará tanto tiempo realizar las operaciones, pero ¿y si nuestro conjunto de datos es grande? sin saberlo, llevará mucho tiempo realizar cálculos sobre una gran cantidad de datos. Entonces, este es un gran problema, que todos los científicos de datos enfrentan en su carrera. ¿Y si reducimos este tiempo? es beneficioso para nosotros?
vamos a discutir a continuación:
Reducir el tiempo de ejecución
Arriba tenemos una breve discusión sobre la CPU, entonces, ¿qué significa? Significa que usamos núcleos de la unidad central de procesamiento para entrenar nuestro modelo de aprendizaje automático.Hay uno de los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... especiales dentro del algoritmo de aprendizaje automático que normalmente lo usamos, pero no tenemos conocimiento al respecto o no. sé el significado exacto de eso, ¡esto suena increíble!
Estos núcleos de CPU son partes muy importantes del entrenamiento de cualquier modelo de aprendizaje automático, esto también es importante cuando se trabaja con aprendizaje profundo, debido a que estos núcleos de CPU serán posibles la programación en paralelo o la ejecución en paralelo del programa. No podemos entrenar modelos de aprendizaje automático con la ayuda de GPU, por lo tanto, las CPU son más útiles en esta condición.
Para un entrenamiento de aprendizaje automático más rápido en cualquier proyecto de aprendizaje automático, puede usar estos núcleos de CPU siempre que tenga una gran cantidad de datos en el conjunto de datos para entrenar el modelo de aprendizaje automático.
Ahora, vemos cómo entrenamos el modelo de aprendizaje automático utilizando núcleos de CPU para mejorar el rendimiento con respecto al modelo de aprendizaje automático:
Conjunto de datos
Para entrenar este enunciado de problema en particular, tenemos que tomar el Wine_Quality conjunto de datos, el enlace de referencia de este conjunto de datos es aquí.
Para comprender mejor este conjunto de datos, puede consultar este enlace: haga clic aquí
Recuerde que si tiene que resolver este problema en particular con los núcleos de la CPU, entonces debe tener un conjunto de datos simple con un gran tamaño de datos.
La razón detrás del uso de este conjunto de datos es que es un conjunto de datos simple con un gran tamaño de datos presentes dentro de este conjunto de datos.
Veamos cuál es el tamaño de estos datos:
Leer conjunto de datos
En primer lugar, tenemos que leer el conjunto de datos de calidad del vino utilizando pandas.
#importing pandas
df = pd.read_csv('wine_quality.csv')
df.head()

df.shape()

Después de ejecutar este código, puede ver que tenemos 6497 filas y 13 columnas en el conjunto de datos de calidad del vino.
Ahora, verificamos las categorías únicas que están presentes dentro de un calidad variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos....,
unique_points= df['quality'].unique() unique_points

Como vemos, hay 6, 5, 7, 8, 4, 3, 9 puntos de datos únicos en la variable de calidad, donde estos puntos de datos son las medidas de calidad del vino.
Variables categóricas de Handel
# catogerical vars next_df = pd.get_dummies(new_df,drop_first=True) # display new dataframe next_df

Característica dependiente e independiente
Para aplicar el modelo de aprendizaje automático, tenemos que dividir las características dependientes e independientes:
# independent features x= next_df.drop(['quality','best quality'],axis=1) # dependent feature y= next_df['best quality']
Entrenamiento de modelos con núcleos de CPU
Al llegar a la ejecución ahora, lo estamos haciendo aplicando algunos pasos:
Paso 1: Usando el algoritmo de aprendizaje automático RandomForestClassifier.
Paso 2: Uso de RepeatedStratifiedKFold para la validación cruzada.
Paso 3: Entrene el modelo utilizando la puntuación de validación cruzada.
Cuando inicializamos todas estas cosas, el tiempo se calculará en función de esta puntuación de validación cruzada. Antes de verificar el tiempo importamos los módulos requeridos:
Importación de módulos:
from time import time # importing RepeatedStratifiedKFold from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score # importing RandomForestClassifier
Ahora, verificamos el tiempo usando los diferentes núcleos de CPU:
Aquí usamos el algoritmo de aprendizaje automático RandomForestClassifie, cuando verificas los parámetros de RandomForestClassifier, encuentras que hay un n_jobs parámetro.

n_jobs es el parámetro que realmente le ayudará a asignar básicamente cuántos núcleos debe tomar un entrenamiento particular del sistema.
Por ejemplo, si queremos tomar n_jobs = 1 luego tomará 1 núcleo de la CPU, si toma 2, tomará 2 núcleos de la CPU, y así sucesivamente. Cuando desee usar todos los núcleos de la CPU para el entrenamiento y no sepa cuántos núcleos hay en el sistema, simplemente use n_jobs = -1.
1 CPU Núcleos:
## CPU cores we use n_jobs
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs=1)
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time is : {}'.format(final_time))

Aquí vemos que con 1 núcleo se necesitan alrededor de 10 segundos para ejecutarse, y este es un tiempo enorme.
No escribimos el n_jobs dentro del RandomForestClassifier en su lugar lo escribimos en el cross_val_score porque nos ayuda a hacer la validación cruzada usando RepeatedStratifiedKFold
Ahora, usamos este mismo código con un pequeño cambio para más núcleos:
2 núcleos de CPU:
## CPU cores we use n_jobs
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs=2) # 2 cores
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time is : {}'.format(final_time))

sí, aquí puedes ver que cuál es la diferencia entre 1 núcleo y 2 núcleos, el tiempo de ejecución es muy diferente al de 1 núcleo.
3 núcleos de CPU:
## CPU cores we use n_jobs
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs=3) # 3 cores
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time is : {}'.format(final_time))

Toma todos los núcleos:
## CPU cores we use n_jobs
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs= -1) # all cores
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time is : {}'.format(final_time))

Comparación de tiempos de núcleos:
## CPU cores we use n_jobs
for core in [1,2,3,4,5,6,7,8,9,10]:
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs = core)
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time of core {} is : {}'.format(core,final_time))
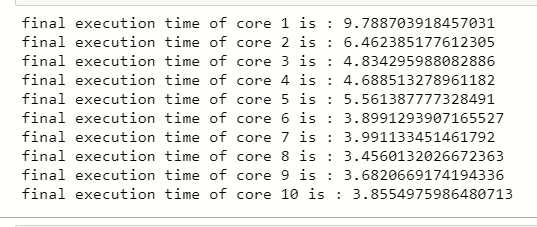
Puede ver que hay una gran diferencia cuando usamos 1 núcleo para entrenar nuestro modelo ML y 10 núcleos para entrenar el modelo ML.
Notas finales
Hola, en este artículo aprendiste el entrenamiento de modelos ML usando núcleos de CPU, ahora es el momento de implementar esta técnica en tu modelo de aprendizaje automático para reducir el tiempo de ejecución.
Espero que disfrutes este artículo, compártelo con tus amigos.
Puedes conectarte conmigo en LinkedIn: www.linkedin.com/in/mayur-badole-189221199
Consulte mis otros artículos: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Gracias.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





