Este artículo fue publicado como parte del Blogatón de ciencia de datos
«Generative Adversarial Networks es la idea más interesante en los últimos diez años en Machine Learning» – Yann LeCun
Introducción
comprensión matemática y práctica de la misma, pero antes de eso, si desea echar un vistazo a los conceptos básicos de las GAN, puede continuar con el siguiente enlace:
La mayoría de los gigantes de la tecnología (como Google, Microsoft, Amazon, etc.) están trabajando arduamente para aplicar las GAN a un uso práctico, algunos de estos casos de uso son:
- Adobe: uso de GAN para su Photoshop de próxima generación.
- Google: uso de GAN para la generación de texto.
- IBM: uso de GAN para aumento de datos (para generar imágenes sintéticas para entrenar sus modelos de clasificación).
- Snap Chat / TikTok: para crear varios filtros de imagen (que es posible que ya haya visto).
- Disney: uso de GAN para súper resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... (mejora de la calidad de video) para sus películas.
Algo que es especial con las GAN es que estas empresas dependen de ellas para su futuro, ¿no crees?
Entonces, ¿qué te detiene para obtener el conocimiento de esta tecnología épica? Te responderé, nada, solo necesitas una ventaja y este artículo lo haría. Primero discutamos las matemáticas detrás de Generator y Discriminator.
Funcionamiento matemático del discriminador:
El único propósito del Discriminador es clasificar imágenes reales y falsas. Para la clasificación, utiliza una red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... (CNN) tradicional con una función de costo específica. El proceso de formación de Discriminator funciona de la siguiente manera:
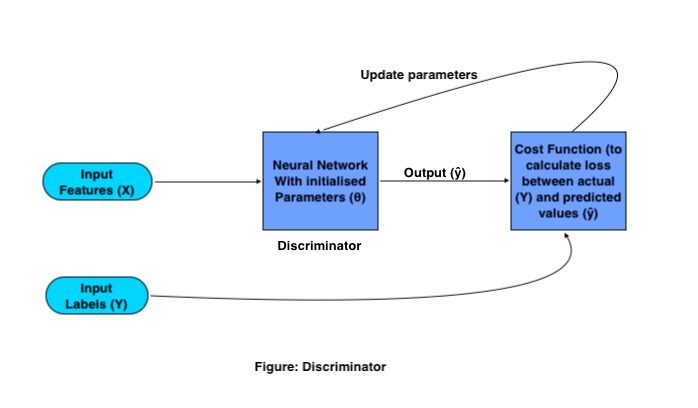
Donde X e Y son características de entrada y etiquetas respectivamente, la salida se representa con (ŷ) y los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de red se representan con (θ).
Los GAN de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... necesitan un conjunto de imágenes de entrenamiento y sus respectivas etiquetas, estas imágenes como característica de entrada van a CNN, con un conjunto de parámetros inicializados. Esta CNN genera salida multiplicando la matriz de peso (W) con las características de entrada (X) y agregando un Bias (B) en ella y convirtiéndola en una matriz no lineal pasándola a una función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones.....
Esta salida se conoce como salida predicha, luego la pérdida se calcula en función de los parámetros de peso que se ajustan en la red para minimizar la pérdida.
Funcionamiento matemático del generador:
El objetivo del Generador es generar una imagen falsa a partir de la distribución dada (conjunto de imágenes), lo hace con el siguiente procedimiento:
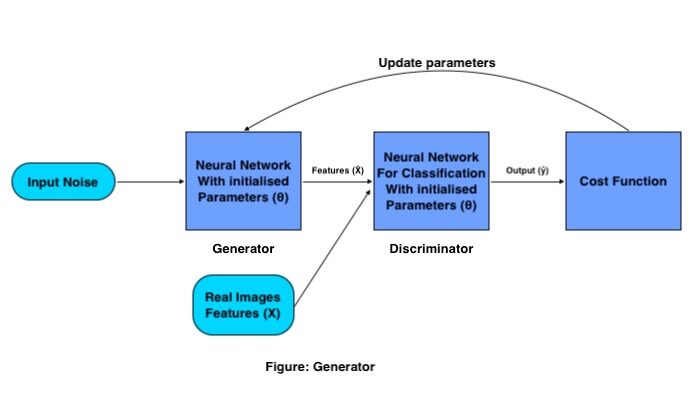
Se pasa un conjunto de vectores de entrada (ruido aleatorio) a través de la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... del generador, que crea una imagen completamente nueva al multiplicar la matriz de peso del generador con el ruido de entrada.
Esta imagen generada funciona como entrada para el discriminador que está entrenado para clasificar imágenes falsas y reales. Luego se calcula la pérdida para las imágenes generadas, en base a qué parámetros se actualizan para el generador hasta que obtengamos una buena precisión.
Una vez que estamos satisfechos con la precisión del Generador, guardamos los pesos del Generador y eliminamos el Discriminador de la red, y usamos esa matriz de pesos para generar más imágenes nuevas pasándole una matriz de ruido aleatorio diferente cada vez.
Pérdida de entropía cruzada binaria para GAN:
Para optimizar los parámetros de las GAN, necesitamos una función de costo que le diga a la red cuánto necesita mejorar simplemente calculando la diferencia entre el valor real y el predicho. La función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y... que se utiliza en las GAN se denomina entropía cruzada binaria y se representa como:
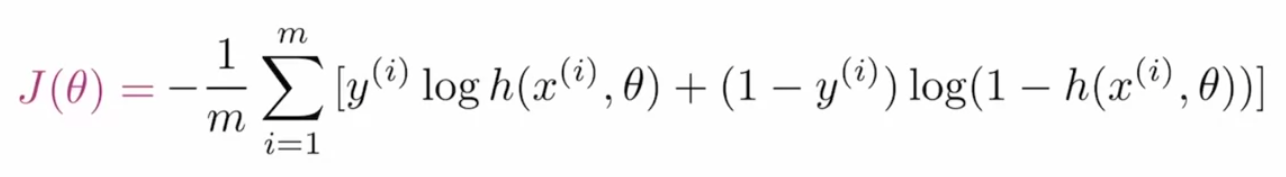
Donde m es el tamaño del lote, y(I) es el valor de etiqueta real, h es el valor de etiqueta predicho, x(I) es la característica de entrada y θ representa el parámetro.
Dividamos esta función de costo en subpartes para comprender mejor. La fórmula dada es la combinación de dos términos donde uno se usa cuando es efectivo cuando la etiqueta es «0» y el otro es importante cuando la etiqueta es «1». El primer término es:
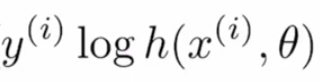
si el valor real es «1» y el valor predicho es «~ 0» en este caso, ya que log (~ 0) tiende a infinito negativo o muy alto, y si el valor predicho también es «~ 1», entonces el log ( ~ 1) estaría cerca de «0» o muy menos, por lo que este término ayuda a calcular la pérdida para los valores de la etiqueta «1».
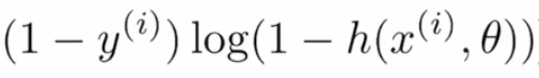
Si el valor real es «0» y el valor predicho es «~ 1», entonces log (1- (~ 1)) daría como resultado un infinito negativo o muy alto, y si el valor predicho es «~ 0», entonces el término sería producen resultados “~ 0” o una pérdida muy inferior, por lo que este término se utiliza para los valores de etiqueta reales “0”.
Cualquiera de los términos de la pérdida devolvería los valores negativos en caso de que la predicción sea incorrecta, la combinación de estos términos se denomina Entropía (pérdida logarítmica). Pero como es negativo, para hacerlo mayor que “1” le aplicamos un signo negativo (se puede ver en la fórmula principal), aplicar este signo negativo es lo que lo hace Entropía cruzada (pérdida logarítmica negativa).
Entrenemos el primer modelo GAN:
Crearemos un modelo GAN que podría generar dígitos escritos a mano a partir de la distribución de datos MNIST utilizando el módulo PyTorch.
Primero, importemos los módulos requeridos:
%matplotlib inline import numpy as np import torch import matplotlib.pyplot as plt
Luego leeríamos los datos del submódulo proporcionado por PyTorch llamado conjuntos de datos.
# number of subprocesses to use for data loading
num_workers = 0
# how many samples per batch to load
batch_size = 64
# convert data to torch.FloatTensor
transform = transforms.ToTensor()
# get the training datasets
train_data = datasets.MNIST(root="data", train=True,
download=True, transform=transform)
# prepare data loader
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
num_workers=num_workers)
Visualiza los datos
Dado que estaríamos creando nuestro modelo en el marco de PyTorch que usa tensores, estaríamos convirtiendo nuestros datos en tensores de antorcha. Si desea visualizar los datos, puede seguir adelante y usar el siguiente fragmento de código:
# obtain one batch of training images dataiter = iter(train_loader) images, labels = dataiter.next() images = images.numpy() # get one image from the batch img = np.squeeze(images[0]) fig = plt.figure(figsize = (3,3)) ax = fig.add_subplot(111) ax.imshow(img, cmap='gray')

Discriminado
Ahora es el momento de definir la red Discriminator, que es la combinación de varias capas de CNN.
import torch.nn as nn
import torch.nn.functional as F
class Discriminator(nn.Module):
def __init__(self, input_size, hidden_dim, output_size):
super(Discriminator, self).__init__()
# define hidden linear layers
self.fc1 = nn.Linear(input_size, hidden_dim*4)
self.fc2 = nn.Linear(hidden_dim*4, hidden_dim*2)
self.fc3 = nn.Linear(hidden_dim*2, hidden_dim)
# final fully-connected layer
self.fc4 = nn.Linear(hidden_dim, output_size)
# dropout layer
self.dropout = nn.Dropout(0.3)
def forward(self, x):
# flatten image
x = x.view(-1, 28*28)
# all hidden layers
x = F.leaky_relu(self.fc1(x), 0.2) # (input, negative_slope=0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc2(x), 0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc3(x), 0.2)
x = self.dropout(x)
# final layer
out = self.fc4(x)
return out
El código anterior sigue la arquitectura tradicional de Python basada en objetos orientados. fc1, fc2, fc3, fc3 son las capas completamente conectadas. Cuando pasamos nuestras entidades de entrada, pasa a través de todas estas capas comenzando desde fc1, y al final, tenemos una capa de abandono que se usa para abordar el problema de sobreajuste.
En el mismo código, verá una función llamada forward (self, x), esta función es la implementación del mecanismo de propagación hacia adelante real donde cada capa (fc1, fc2, fc3 y fc4) va seguida de una función de activación (leaping_relu ) para convertir la salida del trazador de líneas en no lineal.
Modelo de generador
Después de esto, verificaremos el segmento Generador de GAN:
class Generator(nn.Module):
def __init__(self, input_size, hidden_dim, output_size):
super(Generator, self).__init__()
# define hidden linear layers
self.fc1 = nn.Linear(input_size, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim*2)
self.fc3 = nn.Linear(hidden_dim*2, hidden_dim*4)
# final fully-connected layer
self.fc4 = nn.Linear(hidden_dim*4, output_size)
# dropout layer
self.dropout = nn.Dropout(0.3)
def forward(self, x):
# all hidden layers
x = F.leaky_relu(self.fc1(x), 0.2) # (input, negative_slope=0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc2(x), 0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc3(x), 0.2)
x = self.dropout(x)
# final layer with tanh applied
out = F.tanh(self.fc4(x))
return out
La red del generador también se construye a partir de las capas completamente conectadas, las funciones de activación de reluLa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Definida como ( f(x) = max(0, x) ), ReLU permite que las neuronas se activen solo cuando la entrada es positiva, lo que contribuye a mitigar el problema del desvanecimiento del gradiente. Su uso ha demostrado mejorar el rendimiento en diversas tareas de aprendizaje profundo, haciendo de ReLU una opción... con fugas y la deserción. Lo único que lo hace diferente de Discriminator es que da salida dependiendo del parámetro output_size (que es el tamaño de la imagen a generar).
Ajuste de hiperparámetros
Los hiperparámetros que vamos a utilizar para entrenar las GAN son:
# Discriminator hyperparams # Size of input image to discriminator (28*28) input_size = 784 # Size of discriminator output (real or fake) d_output_size = 1 # Size of last hidden layer in the discriminator d_hidden_size = 32 # Generator hyperparams # Size of latent vector to give to generator z_size = 100 # Size of discriminator output (generated image) g_output_size = 784 # Size of first hidden layer in the generator g_hidden_size = 32
Crear una instancia de los modelos
Y finalmente, la red completa se vería así:
# instantiate discriminator and generator D = Discriminator(input_size, d_hidden_size, d_output_size) G = Generator(z_size, g_hidden_size, g_output_size) # check that they are as you expect print(D) print( ) print(G)

Calcular pérdidas
Hemos definido el Generador y el Discriminador ahora es el momento de definir sus pérdidas para que esas redes mejoren con el tiempo. Para las GAN tendríamos dos pérdidas reales de función de pérdida y pérdida falsa que se definirían así:
# Calculate losses
def real_loss(D_out, smooth=False):
batch_size = D_out.size(0)
# label smoothing
if smooth:
# smooth, real labels = 0.9
labels = torch.ones(batch_size)*0.9
else:
labels = torch.ones(batch_size) # real labels = 1
# numerically stable loss
criterion = nn.BCEWithLogitsLoss()
# calculate loss
loss = criterion(D_out.squeeze(), labels)
return loss
def fake_loss(D_out):
batch_size = D_out.size(0)
labels = torch.zeros(batch_size) # fake labels = 0
criterion = nn.BCEWithLogitsLoss()
# calculate loss
loss = criterion(D_out.squeeze(), labels)
return loss
Optimizadores
Una vez definidas las pérdidas, elegiríamos un optimizador adecuado para el entrenamiento:
import torch.optim as optim # Optimizers lr = 0.002 # Create optimizers for the discriminator and generator d_optimizer = optim.Adam(D.parameters(), lr) g_optimizer = optim.Adam(G.parameters(), lr)
Entrenamiento de los modelos
Dado que hemos definido Generador y Discriminador tanto las redes, sus funciones de pérdida como los optimizadores, ahora usaríamos las épocas y otras características para entrenar toda la red.
import pickle as pkl
# training hyperparams
num_epochs = 100
# keep track of loss and generated, "fake" samples
samples = []
losses = []
print_every = 400
# Get some fixed data for sampling. These are images that are held
# constant throughout training, and allow us to inspect the model's performance
sample_size=16
fixed_z = np.random.uniform(-1, 1, size=(sample_size, z_size))
fixed_z = torch.from_numpy(fixed_z).float()
# train the network
D.train()
G.train()
for epoch in range(num_epochs):
for batch_i, (real_images, _) in enumerate(train_loader):
batch_size = real_images.size(0)
## Important rescaling step ##
real_images = real_images*2 - 1 # rescale input images from [0,1) to [-1, 1)
# ============================================
# TRAIN THE DISCRIMINATOR
# ============================================
d_optimizer.zero_grad()
# 1. Train with real images
# Compute the discriminator losses on real images
# smooth the real labels
D_real = D(real_images)
d_real_loss = real_loss(D_real, smooth=True)
# 2. Train with fake images
# Generate fake images
# gradients don't have to flow during this step
with torch.no_grad():
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
fake_images = G(z)
# Compute the discriminator losses on fake images
D_fake = D(fake_images)
d_fake_loss = fake_loss(D_fake)
# add up loss and perform backprop
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
d_optimizer.step()
# =========================================
# TRAIN THE GENERATOR
# =========================================
g_optimizer.zero_grad()
# 1. Train with fake images and flipped labels
# Generate fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
fake_images = G(z)
# Compute the discriminator losses on fake images
# using flipped labels!
D_fake = D(fake_images)
g_loss = real_loss(D_fake) # use real loss to flip labels
# perform backprop
g_loss.backward()
g_optimizer.step()
# Print some loss stats
if batch_i % print_every == 0:
# print discriminator and generator loss
print('Epoch [{:5d}/{:5d}] | d_loss: {:6.4f} | g_loss: {:6.4f}'.format(
epoch+1, num_epochs, d_loss.item(), g_loss.item()))
## AFTER EACH EPOCH##
# append discriminator loss and generator loss
losses.append((d_loss.item(), g_loss.item()))
# generate and save sample, fake images
G.eval() # eval mode for generating samples
samples_z = G(fixed_z)
samples.append(samples_z)
G.train() # back to train mode
# Save training generator samples
with open('train_samples.pkl', 'wb') as f:
pkl.dump(samples, f)
Una vez que ejecute el fragmento de código anterior, el proceso de entrenamiento comenzaría así:

Generar imágenes
Finalmente, cuando se entrena el modelo, puede usar el generador entrenado para producir las nuevas imágenes escritas a mano.
# randomly generated, new latent vectors sample_size=16 rand_z = np.random.uniform(-1, 1, size=(sample_size, z_size)) rand_z = torch.from_numpy(rand_z).float() G.eval() # eval mode # generated samples rand_images = G(rand_z) # 0 indicates the first set of samples in the passed in list # and we only have one batch of samples, here view_samples(0, [rand_images])
A la salida generada con el siguiente código le gustaría algo como esto:

Entonces, ahora que tiene su propio modelo GAN entrenado, puede usar este modelo para entrenarlo en un conjunto diferente de imágenes, para producir nuevas imágenes invisibles.
Referencias:
1. Aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... de Udacity: https://www.udacity.com/
2. Inteligencia artificial de aprendizaje profundo: https://www.deeplearning.ai/
Gracias por leer este artículo. Si has aprendido algo nuevo, siéntete libre de comentar ¡¡¡Nos vemos la próxima vez !!! ❤️
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





