Introducción
Teoría de la estimación y Prueba de hipótesis son los conceptos muy importantes de Estadística que son muy utilizados por Estadísticos, Ingenieros de aprendizaje automático, y Científicos de datos.
Entonces, en este post, discutiremos los estimadores puntuales en la teoría de estimación de la estadística.
Tabla de contenido
1. Estimadores y estimadores
2. ¿Qué son los estimadores de puntos?
3. ¿Qué es la muestra aleatoria y la estadística?
4. Dos estadísticas comunes utilizadas:
- Muestra promedio
- Varianza de la muestra
5. Propiedades de los estimadores puntuales
- Imparcialidad
- Eficiente
- Consistente
- Suficiente
6. Métodos comunes para hallar estimaciones puntuales
7. Estimación puntual frente a estimación por intervalo
Estimación y estimadores
Sea X una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... aleatoria con distribución FX(x; θ), donde θ es un parámetro desconocido. Una muestra aleatoria, X1, X2, –, Xnorte, de tamaño n tomado en X.
El problema de la estimación puntual es seleccionar una estadística, g (X1, X2, —, Xnorte), que mejor estima el parámetro θ.
Una vez observado, el valor numérico de g (x1, X2, —, Xnorte) se llama estimación y estadística g (X1, X2, —, Xnorte) se llama estimadorEl "Estimador" es una herramienta estadística utilizada para inferir características de una población a partir de una muestra. Se basa en métodos matemáticos para proporcionar estimaciones precisas y confiables. Existen diferentes tipos de estimadores, como los insesgados y los consistentes, que se eligen según el contexto y el objetivo del estudio. Su correcto uso es fundamental en investigaciones científicas, encuestas y análisis de datos.....
¿Qué son los estimadores de puntos?
Los estimadores puntuales se definen como las funciones que se usan para hallar un valor aproximado de un parámetro de población a partir de muestras aleatorias de la población. Toman la ayuda de los datos de muestra de una población para establecer una estimación puntual o una estadística que sirve como la mejor estimación de un parámetro desconocido de una población.
Fuente de la imagen: imágenes de Google
Muy a menudo, los métodos existentes para hallar los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de grandes poblaciones no son realistas.
A modo de ejemplo, cuando queremos hallar la altura promedio de las personas que asisten a una conferencia, será imposible recolectar la altura exacta de todos los pueblos de la conferencia en el mundo. En cambio, un estadístico puede utilizar el estimador puntual para estimar el parámetro de población.
Muestra aleatoria y estadística
Muestra aleatoria: Un conjunto de IID (independiente e idénticamente distribuido) variables aleatorias, X1, X2, X3, —, Xnorte establecida en el mismo espacio muestral se denomina muestra aleatoria de tamaño n.
Estadística: Una función de una muestra aleatoria se llama estadística (si no depende de ninguna entidad desconocida)
A modo de ejemplo, X1+ X2+ —— + Xnorte, X12X2+ eX3, X1– Xnorte
Media muestral y varianza muestral
Dos estadísticas importantes:
Deje X1, X2, X3, —, Xnorte ser una muestra aleatoria, entonces:
La media muestral se denota por X, y la varianza de la muestra se denota por s2
Aquí x̄ ys2 se llaman los parámetros de muestra.
Los parámetros de población se indican a través de:
σ2 = varianza de la población y µ = media de la población

Fig. Población y media muestral
Fuente de la imagen: imágenes de Google

Fig. Población y varianza de la muestra
Fuente de la imagen: imágenes de Google
Características de la media muestral:
E (x̄) = 1 / n (Σ E (XI)) = 1 / n (nµ) = µ
Var (x̄) = 1 / n2(Σ Var (XI)) = 1 / n2 (nσ2) = σ2/norte
Características de la varianza de la muestra:
s2 = 1 / (n-1) (Σ (xI– X )2 ) = 1 / (n-1) (Σ xI2 – 2x̄ Σ xI + nx̄2 ) = 1 / (n-1) (Σ xI2 – nx̄2 )
Ahora, tomemos la expectativa de ambos lados, obtenemos:
E (s2) = 1 / (n-1) (Σ E (xI2) – n E (x̄2)) = 1 / (n-1) (Σ (µ2+ σ2) – n (µ2+ σ2/ n)) = 1 / (n-1) ((n-1) σ2) = σ2.
Propiedades de los estimadores puntuales
En cualquier problema de estimación dado, podemos tener una clase infinita de estimadores apropiados para seleccionar. El problema es hallar un estimador g (X1, X2, —, Xnorte), para un parámetro desconocido θ o su función Ψ (θ), que tiene propiedades «agradables».
Esencialmente, nos gustaría que el estimador g estuviera “cerca” de Ψ.
Las siguientes son las principales propiedades de los estimadores puntuales:
1. imparcialidad:
Primero entendamos el significado del término «Parcialidad»
La diferencia entre el valor esperado del estimador y el valor del parámetro que se estima se denomina sesgo de un estimador puntual.
Por eso, el estimador se considera insesgado cuando el valor estimado del parámetro y el valor del parámetro que se está estimando son iguales.
Al mismo tiempo, cuanto más cerca esté el valor esperado de un parámetro al valor del parámetro que se está midiendo, menor será el valor del sesgo.
Matemáticamente,
Un estimador g (X1, X2, —, Xnorte) se dice que es un estimador insesgado de θ si
E (g (X1, X2, —, Xnorte)) = θ
Dicho de otra forma, en promedio, esperamos que g esté cerca del parámetro verdadero θ. Hemos visto que si X1, X2, —, Xnorte ser una muestra aleatoria de una población con media µ y varianza σ2, después
E (x̄) = µ y E (s2) = σ2
Por eso, x̄ y s2 son estimadores insesgados para µ y σ2
2. Eficiente:
El estimador puntual más eficiente es el que tiene la varianza más pequeña de todos los estimadores insesgados y consistentes. La varianza representa el nivel de dispersión de la estimación, y la varianza más pequeña debe variar menos de una muestra a otra.
De forma general, la eficiencia del estimador depende de la distribución de la población.
Matemáticamente,
Un estimador gramo1(X1, X2, —, Xnorte) es más eficiente que gramo2(X1, X2, —, Xnorte), por θ si
Var (g1(X1, X2, —, Xnorte)) <= Var (g2(X1, X2, —, Xnorte))
3. Consistente:
La consistencia describe qué tan cerca permanece el estimador puntual del valor del parámetro a medida que aumenta de tamaño. Para que sea más consistente y preciso, el estimador puntual necesita un tamaño de muestra grande.
Además podemos verificar si un estimador puntual es consistente observando su respectivo valor esperado y varianza.
Para que el estimador puntual sea consistente, el valor esperado debe moverse hacia el valor real del parámetro.
Matemáticamente,
Deje g1, g2, g3, ——- ser una secuencia de estimadores, se dice que la secuencia es consistente si converge a θ en probabilidad, dicho de otra forma,
P (| gmetro(X1, X2, —, Xnorte) – θ | > ε) -> 0 cuando m-> ∞
Si X1, X2, —, Xnorte es una secuencia de variables aleatorias IID tal que E (XI) = µ, después por WLLN (Ley débil de números grandes):
Xnorte‘—–> µ de probabilidad
Donde Xnorte‘es la media de X1, X2, X3, —, Xnorte
4. Suficiente:
Sea una muestra de X ~ f (x; θ). Si Y = g (X1, X2, —, Xnorte) es una estadística tal que para cualquier otra estadística Z = h (X1, X2, —, Xnorte), la distribución condicional de Z, dado que Y = y no depende de θ, entonces Y se llama estadística suficiente para θ.
Métodos comunes para hallar estimaciones puntuales
El procedimiento de estimación puntual implica la utilización del valor de una estadística que se obtiene con la ayuda de datos de muestra para establecer la mejor estimación del respectivo parámetro desconocido de la población. Se pueden usar varios métodos para calcular o determinar los estimadores puntuales, y cada técnica tiene propiedades diferentes. Algunos de los métodos son los siguientes:
1. Método de los momentos (MOM)
Comienza tomando en consideración todos los hechos conocidos sobre una población y después aplicando esos hechos a una muestra de la población. En primer lugar, deriva ecuaciones que relacionan los momentos poblacionales con los parámetros desconocidos.
El siguiente paso es extraer una muestra de la población que se utilizará para estimar los momentos poblacionales. Las ecuaciones generadas en el paso uno se resuelven después con la ayuda de la media muestral de los momentos poblacionales. Esto da la mejor estimación de los parámetros de población desconocidos.
Matemáticamente,
Considere una muestra X1, X2, X3, —, Xnorte de f (x; θ1, θ2, —–, θmetro) .El objetivo es estimar los parámetros θ1, θ2, —–, θmetro.
Sean los momentos poblacionales (teóricos) α1, α2, ——–, αr, que son funciones de parámetros desconocidos θ1, θ2, —–, θmetro.
Al igualar los momentos muestrales y los momentos poblacionales, obtenemos los estimadores de θ1, θ2, —–, θmetro.
2. Estimador de máxima verosimilitud (MLE)
Este método de hallar estimadores puntuales intenta hallar los parámetros desconocidos que maximizan la función de verosimilitud. Toma un modelo conocido y utiliza los valores para comparar conjuntos de datos y hallar la coincidencia más adecuada para los datos.
Matemáticamente,
Considere una muestra X1, X2, X3, —, Xnorte de f (x; θ). El objetivo es estimar los parámetros θ (escalar o vectorial).
La función de verosimilitud se establece como:
L (θ; x1, X2, —, Xnorte) = f (x1, X2, —, Xnorte; θ)
Un MLE de θ es el valor θ ‘(una función de muestra) que maximiza la función de verosimilitud
Si L es una función diferenciable de θ, entonces se utiliza la próxima ecuación de verosimilitud para obtener el MLE (θ ‘):
d / dθ (ln (L (θ; x1, X2, —, Xnorte) = 0
Si θ es un vector, entonces se considera que las derivadas parciales obtienen las ecuaciones de verosimilitud.
Estimación puntual frente a estimación por intervalo
Simplemente, hay dos tipos principales de estimadores en estadística:
- Estimadores puntuales
- Estimadores de intervalo
La estimación puntual es lo opuesto a la estimación por intervalos.
La estimación puntual genera un valor único, mientras que la estimación por intervalos genera un rango de valores.
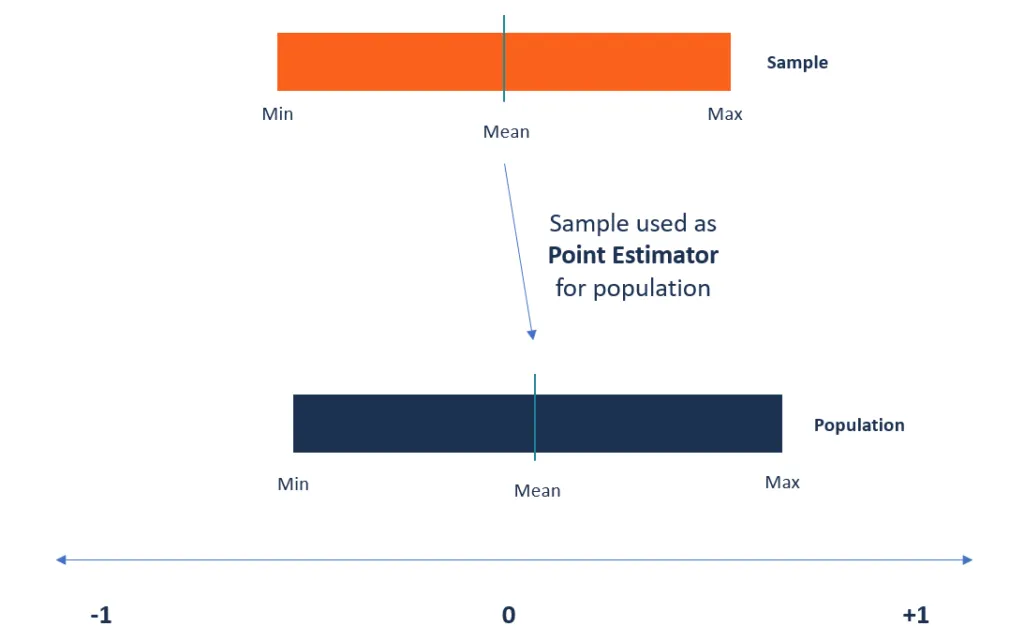
Un estimador puntual es una estadística que se utiliza para estimar el valor de un parámetro desconocido de una población. Utiliza datos de muestra de la población al calcular una única estadística que se considerará como la mejor estimación para el parámetro desconocido de la población.

Fuente de la imagen: imágenes de Google
Por el contrario, la estimación de intervalo toma datos de muestra para establecer el intervalo de los posibles valores de un parámetro desconocido de una población. El intervalo del parámetro se selecciona de manera que esté dentro de un 95% o más de probabilidad, además conocido como intervalo de confianza. El intervalo de confianza describe qué tan confiable es una estimación y se calcula a partir de los datos observados. Los puntos finales de los intervalos se conocen como superior y límites de confianza más bajos.
Notas finales
¡Gracias por leer!
Espero que haya disfrutado del post y haya aumentado sus conocimientos sobre la teoría de la estimación.
Por favor no dude en ponerse en contacto conmigo sobre Correo electrónico
¿Algo no mencionado o deseas compartir tus pensamientos? No dude en comentar a continuación y me pondré en contacto con usted.
Sobre el Autor
Aashi Goyal
En este momento, estoy cursando mi Licenciatura en Tecnología (B.Tech) en Ingeniería Electrónica y de la Comunicación de Universidad Guru Jambheshwar (GJU), Hisar. Estoy muy entusiasmado con la estadística, el aprendizaje automático y el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud....
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





