Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
En el procesamiento del lenguaje natural, la extracción de características es uno de los pasos triviales que se deben seguir para comprender mejor el contexto de lo que estamos tratando. Después de limpiar y normalizar el texto inicial, debemos transformarlo en sus características para usarlo en el modelado. Usamos algún método particular para asignar pesos a palabras particulares dentro de nuestro documento antes de modelarlas. Optamos por la representación numérica de palabras individuales, ya que es fácil para la computadora procesar números; en tales casos, optamos por incrustaciones de palabras.

Fuente: https://www.analyticsvidhya.com/blog/2020/06/nlp-project-information-extraction/
En este artículo, discutiremos los diversos métodos de extracción de características e incrustaciones de palabras que se practican en el procesamiento del lenguaje natural.
Extracción de características:
Bolsa de palabras:
En este método, tomamos cada documento como una colección o bolsa que contiene todas las palabras. La idea es analizar los documentos. El documento aquí se refiere a una unidad. En caso de que queramos encontrar todos los tweets negativos durante la pandemia, cada tweet aquí es un documento. Para obtener la bolsa de palabras siempre realizamos todos esos pasos previos como limpieza, derivación, lematización, etc… Luego generamos un conjunto de todas las palabras que están disponibles antes de enviarlo para modelar.
«La entrada es la mejor parte del fútbol» -> {‘entrada’, ‘mejor’, ‘parte’, ‘fútbol’}
Podemos obtener palabras repetidas dentro de nuestro documento. Una mejor representación es una forma vectorial, que nos puede decir cuántas veces puede aparecer cada palabra en un documento. Lo siguiente se denomina matriz de términos del documento y se muestra a continuación:
Fuente: https://qphs.fs.quoracdn.net/main-qimg-27639a9e2f88baab88a2c575a1de2005
Nos informa sobre la relación entre un documento y los términos. Cada uno de los valores de la tabla se refiere al término frecuencia. Para encontrar la similitud, elegimos la medida de similitud del coseno.
TF-IDF:
Un problema que encontramos en el enfoque de la bolsa de palabras es que trata todas las palabras por igual, pero en un documento, existe una alta probabilidad de que determinadas palabras se repitan con más frecuencia que otras. En un reportaje sobre la victoria de Messi en la Copa América, la palabra Messi se repetiría con más frecuencia. No podemos darle a Messi el mismo peso que cualquier otra palabra de ese documento. En el reportaje, si tomamos cada frase como un documento, podemos contar la cantidad de documentos cada vez que aparece Messi. Este método se llama frecuencia de documentos.
Luego dividimos la frecuencia del término por la frecuencia del documento de esa palabra. Esto nos ayuda con la frecuencia de aparición de términos en ese documento e inversamente al número de documentos en los que aparece. Por lo tanto, tenemos el TF-IDF. La idea es asignar pesos particulares a las palabras que nos dicen qué tan importantes son en el documento.
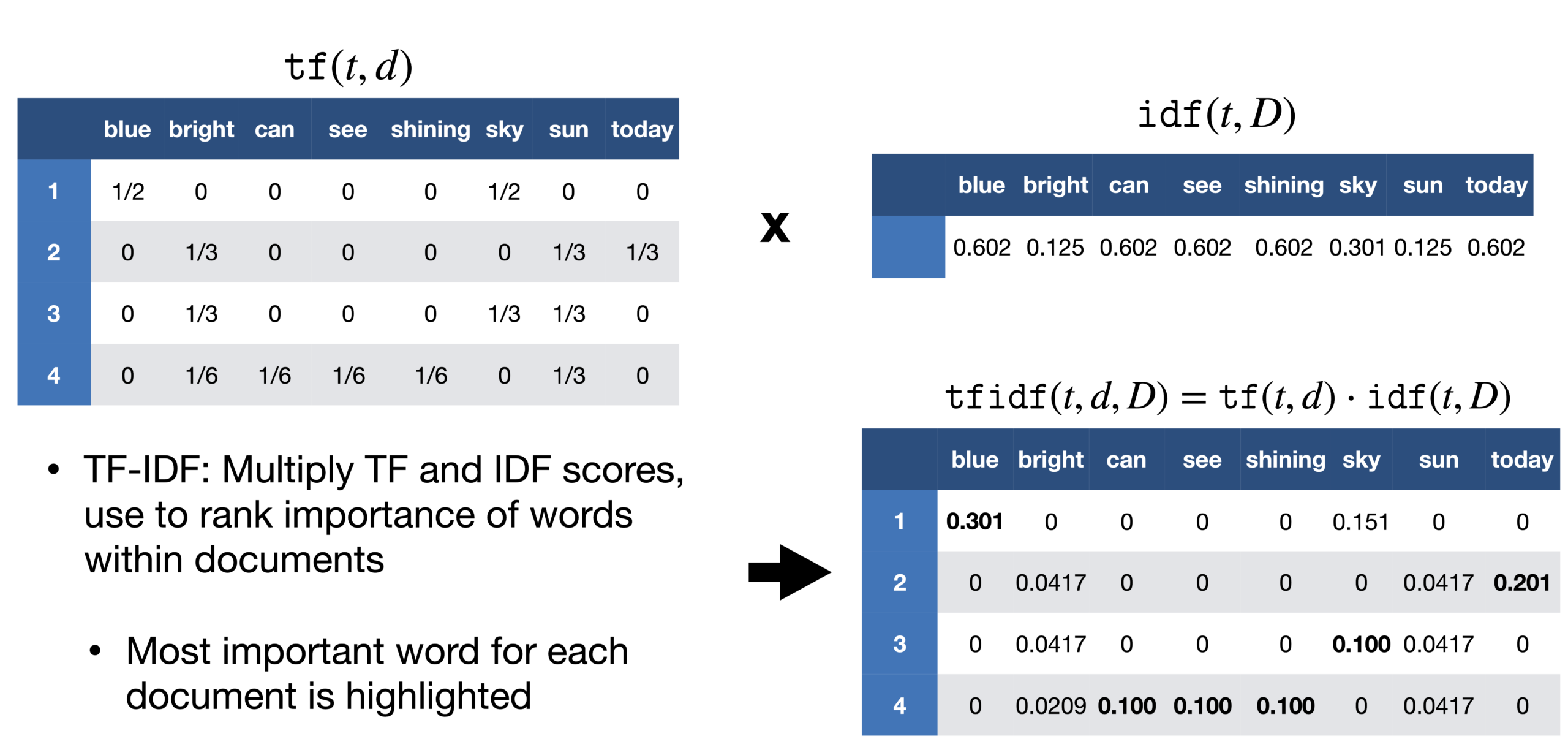
Fuente: https://sci2lab.github.io/ml_tutorial/tfidf/
Codificación one-hot:
Para un mejor análisis del texto que queremos procesar, debemos crear una representación numérica de cada palabra. Esto se puede solucionar utilizando el método de codificación One-hot. Aquí tratamos cada palabra como una clase y en un documento, donde sea que esté la palabra, le asignamos 1 en la tabla y todas las demás palabras en ese documento obtienen 0. Esto es similar a la bolsa de palabras, pero aquí solo mantenemos cada palabra en una bolsa.
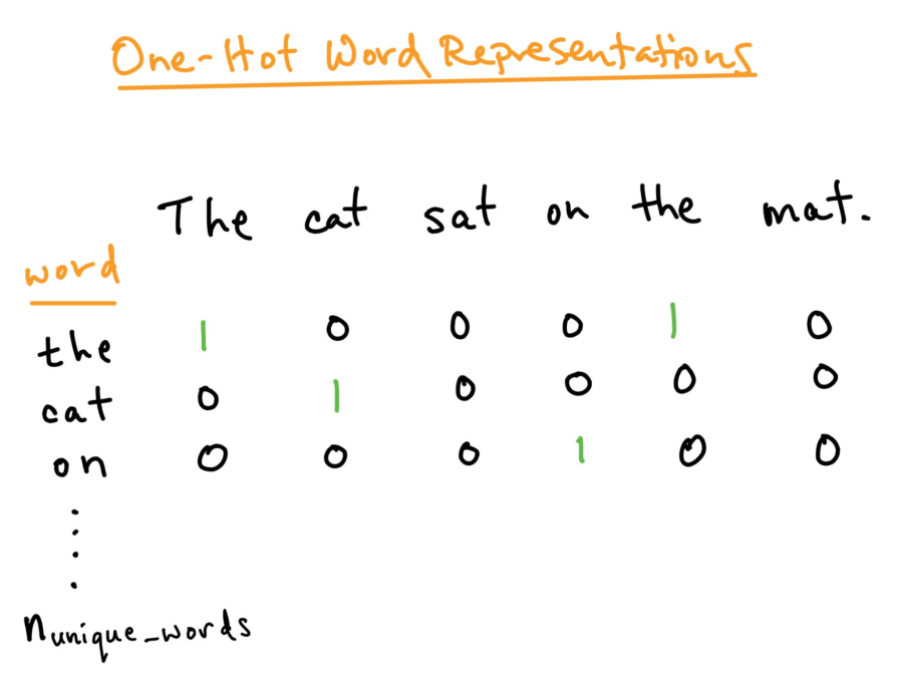
Fuente: https: //towardsdatascience.com/word-embedding-in-nlp-one-hot-encoding-and-skip-gram-neural-network-81b424da58f2
Incrustación de palabras:
La codificación one-hot funciona bien cuando tenemos un pequeño conjunto de datos. Cuando hay un vocabulario enorme, podemos codificarlo usando este método ya que la complejidad aumenta mucho. Necesitamos un método que pueda controlar el tamaño de las palabras que representamos. Hacemos esto limitándolo a un vector de tamaño fijo. Queremos encontrar una incrustación para cada palabra. Queremos que nos muestren algunas propiedades. Por ejemplo, si dos palabras son similares, deben estar más cerca una de la otra en representación, y dos palabras opuestas si existen sus pares, ambas deben tener la misma diferencia de distancias. Estos nos ayudan a encontrar sinónimos, analogías, etc.
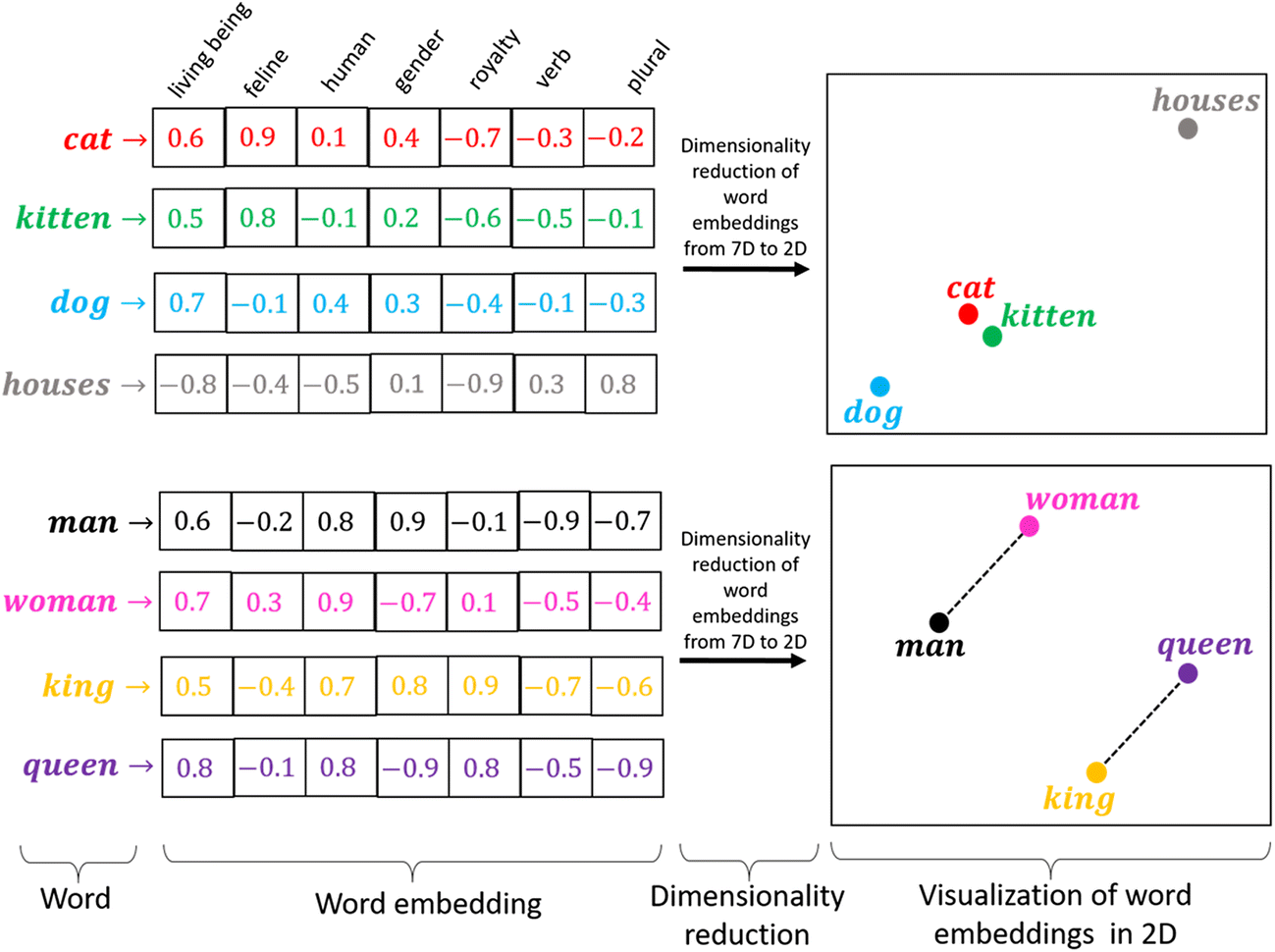
Fuente: https://miro.medium.com/max/1400/1*sAJdxEsDjsPMioHyzlN3_A.png
Word2Vec:
Word2Vec se usa ampliamente en la mayoría de los modelos de PNL. Transforma la palabra en vectores. Word2vec es una red de dos capas que procesa texto con palabras. La entrada está en el corpus de texto y la salida es un conjunto de vectores: los vectores de características representan las palabras en ese corpus. Si bien Word2vec no es una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... profunda, convierte texto en una forma inequívoca de cálculo para redes neuronales profundas. El propósito y el beneficio de Word2vec es recopilar vectores de las mismas palabras en el espacio vectorial. Es decir, encuentra similitudes matemáticas. Word2vec crea vectores que se distribuyen mediante presentaciones numéricas de elementos de palabras, características como el contexto de palabras individuales. Lo hace sin intervención humana.
Con suficientes datos, uso y condiciones, Word2vec puede hacer las predicciones más precisas sobre el significado de una palabra basándose en apariencias anteriores. Esa conjetura se puede usar para formar combinaciones de palabras y palabras (por ejemplo, “grande”, es decir, “grande” para decir que “pequeño” es “diminuto”), o agrupar textos y separarlos por tema. Esas colecciones pueden formar la base para la búsqueda, el análisis emocional y las recomendaciones en varios campos, como la investigación científica, el descubrimiento legal, el comercio electrónico y la gestión de relaciones con los clientes. El resultado de la red Word2vec es un glosario donde cada elemento tiene un vector adjunto, que se puede incrustar en una red de lectura en profundidad o simplemente pedirle que encuentre la relación entre las palabras.
Word2Vec puede capturar muy bien el significado contextual de las palabras. Hay dos sabores. En uno de los métodos, se nos dan las palabras vecinas llamadas bolsa continua de palabras (CBoW), y en el que se nos da la palabra del medio llamada skip-gram y predecimos las palabras vecinas. Una vez que obtenemos un conjunto de pesos previamente entrenados, podemos guardarlo y esto se puede usar más tarde para la vectorización de palabras sin la necesidad de transformar nuevamente. Los almacenamos en una tabla de búsqueda.
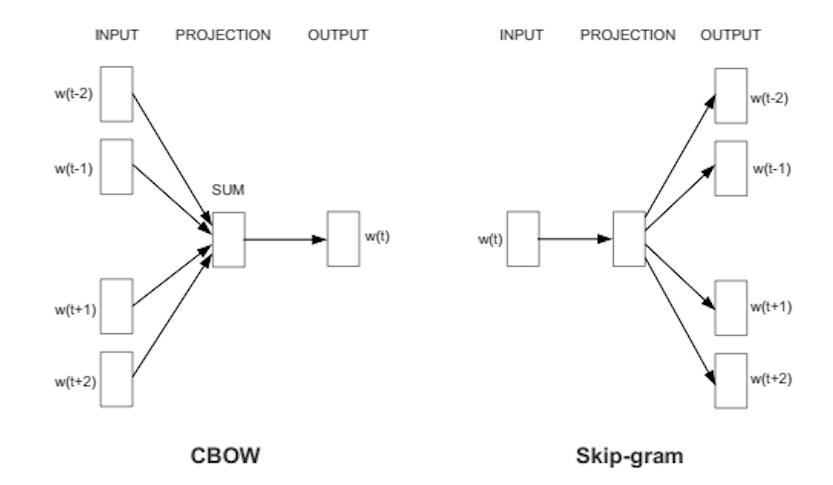
Fuente: https://wiki.pathmind.com/word2vec
Guante:
GloVe – vector global para representación de palabras. Se utiliza un algoritmo de aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la... de Stanford para generar palabras integradas combinando una matriz de palabras para la co-ocurrencia de palabras de la matriz del corpus. El texto incrustado emergente muestra un formato de línea atractivo para una palabra en un espacio vectorial. El modelo GloVe se entrena en la matriz de co-ocurrencia global de nivel cero, que muestra la frecuencia con la que las palabras se encuentran en un corpus particular. Completar esta matriz requiere una pasada por corporación completa para recopilar estadísticas. Para un corpus grande, esta transacciónLa "transacción" se refiere al proceso mediante el cual se lleva a cabo un intercambio de bienes, servicios o dinero entre dos o más partes. Este concepto es fundamental en el ámbito económico y legal, ya que implica el acuerdo mutuo y la consideración de términos específicos. Las transacciones pueden ser formales, como contratos, o informales, y son esenciales para el funcionamiento de mercados y negocios.... puede costar una computadora, pero es un gasto único en el futuro. La capacitación de seguimiento posterior es mucho más rápida porque la cantidad de entradas que no son de la matriz suele ser mucho menor que la cantidad total de entradas en el corpus.
La siguiente es una representación visual de incrustaciones de palabras:
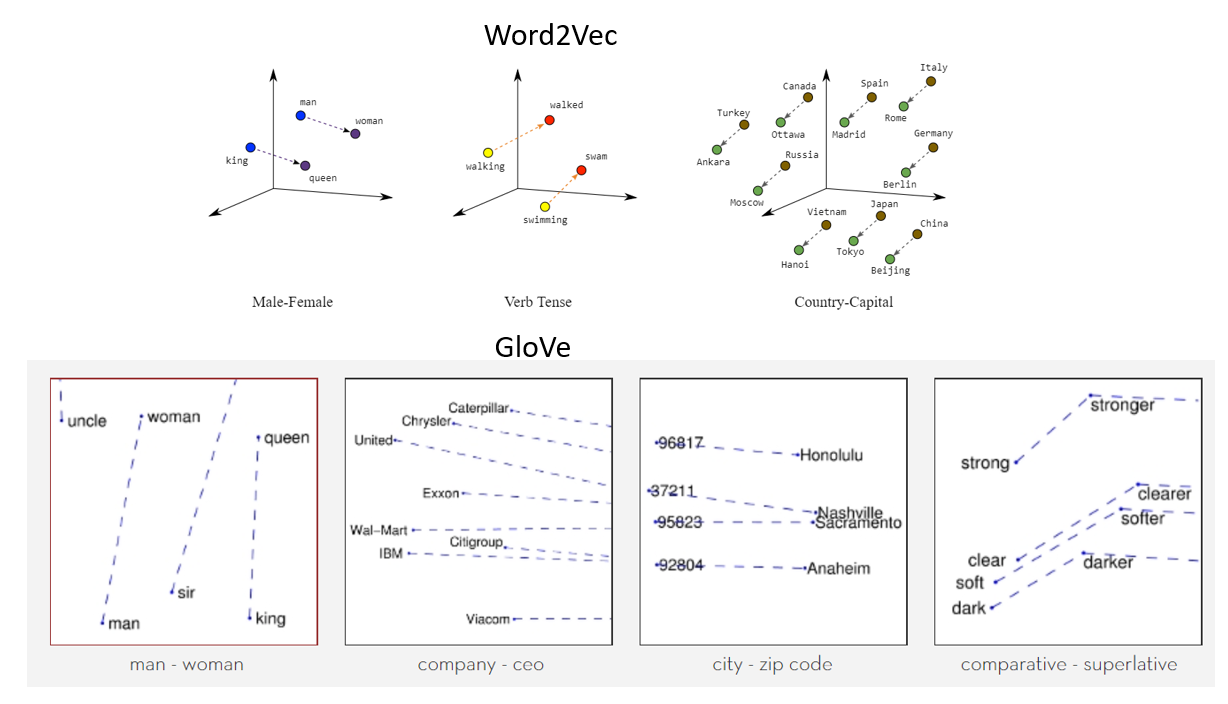
Fuente: https://miro.medium.com/max/1400/1*gcC7b_v7OKWutYN1NAHyMQ.png
Referencias:
1. Imagen – https://www.develandoo.com/blog/do-robots-read/
2. https://nlp.stanford.edu/projects/glove/
3. https://wiki.pathmind.com/word2vec
4. https://www.udacity.com/course/natural-language-processing-nanodegree–nd892
Conclusión:

Fuente: https: //medium.com/datatobiz/the-past-present-and-the-future-of-natural-language-processing-9f207821cbf6
Sobre mí: Soy un estudiante de investigación interesado en el campo del aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y el procesamiento del lenguaje natural y actualmente estoy realizando un posgrado en Inteligencia Artificial.
No dudes en conectarte conmigo en:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698





