Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción:
La extracción de datos es el proceso de extraer datos de varias fuentes como archivos CSV, web, PDF, etc. Aunque en algunos archivos, los datos se pueden extraer fácilmente como en CSV, mientras que en archivos como PDF no estructurados tenemos que realizar tareas adicionales para extraer datos.
Hay un par de bibliotecas de Python con las que puede extraer datos de archivos PDF. Por ejemplo, puede utilizar el PyPDF2 biblioteca para extraer texto de archivos PDF donde el texto es secuencial o formateado, es decir, en líneas o formas. También puede extraer tablas en PDF a través del Camelot Biblioteca. En todos estos casos, los datos están en forma estructurada, es decir, secuenciales, formularios o tablas.
Sin embargo, en el mundo real, la mayoría de los datos no están presentes en ninguno de los formularios y no hay ningún orden de datos. Está presente en forma no estructurada. En este caso, no es factible utilizar las bibliotecas de Python anteriores, ya que darán resultados ambiguos. Para analizar datos no estructurados, necesitamos convertirlos a una forma estructurada.
Como tal, no existe una técnica o procedimiento específico para extraer datos de archivos PDF no estructurados, ya que los datos se almacenan aleatoriamente y depende del tipo de datos que desee extraer del PDF.
Aquí, le mostraré una técnica más exitosa y una biblioteca de Python a través de la cual puede extraer datos de cuadros delimitadores en archivos PDF no estructurados y luego realizar la operación de limpieza de datos en los datos extraídos y convertirlos a un formato estructurado.
PyMuPDF:
He usado el PyMuPDF biblioteca para este propósito. Esta biblioteca proporcionó muchas aplicaciones, como extraer imágenes de PDF, extraer textos de diferentes formas, hacer anotaciones, dibujar un cuadro delimitado alrededor de los textos junto con las características de bibliotecas como PyPDF2.
Ahora, les mostraré cómo extraje datos de los cuadros delimitadores en un PDF con varias páginas.
Aquí están el PDF y los cuadros delimitadores rojos de los que necesitamos extraer datos.
He probado muchas bibliotecas de Python como PyPDF2, PDFMiner, luciopdf, Camelot y tabulado. Sin embargo, ninguno de ellos funcionó excepto PyMuPDF.
Antes de entrar en el código, es importante comprender el significado de 2 términos importantes que ayudarían a comprender el código.
Palabra: Secuencia de caracteres sin espacios. Ex – ceniza, 23, 2, 3.
Anotaciones: una anotación asocia un objeto como una nota, una imagen o un cuadro delimitador con una ubicación en una página de un documento PDF, o proporciona una forma de interactuar con el usuario mediante el mouse y el teclado. Los objetos se llaman anotaciones.
Tenga en cuenta que, en nuestro caso, el cuadro delimitador, las anotaciones y los rectángulos son lo mismo. Por tanto, estos términos se utilizarían indistintamente.
Primero, extraeremos texto de uno de los cuadros delimitadores. Luego usaremos el mismo procedimiento para extraer datos de todos los cuadros delimitadores de pdf.
Código:
import fitz
import pandas as pd
doc = fitz.open('Mansfield--70-21009048 - ConvertToExcel.pdf')
page1 = doc[0]
words = page1.get_text("words")
En primer lugar, importamos el Fitz módulo de la PyMuPDF biblioteca y biblioteca de pandas. Luego, el objeto del archivo PDF se crea y se almacena en el documento y la primera página del pdf se almacena en la página 1. page.get_text () extrae todas las palabras de la página 1. Cada palabra consta de una tupla con 8 elementos.
En palabras variables, los primeros 4 elementos representan las coordenadas de la palabra, el quinto elemento es la palabra en sí, el sexto, séptimo, octavo elementos son números de bloque, línea y palabra, respectivamente.
PRODUCCIÓN
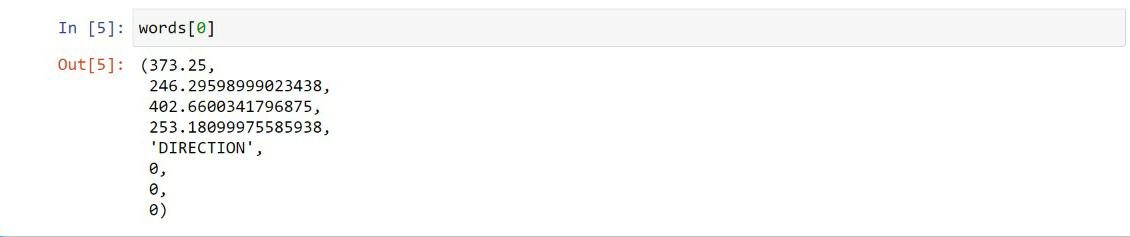
Extrae las coordenadas del primer objeto:
first_annots=[] rec=page1.first_annot.rect rec #Information of words in first object is stored in mywords mywords = [w for w in words if fitz.Rect(w[:4]) in rec] ann= make_text(mywords) first_annots.append(ann)
Esta función selecciona las palabras contenidas en el cuadro, ordena las palabras y regresa en forma de cadena:
def make_text(words):
line_dict = {}
words.sort(key=lambda w: w[0])
for w in words:
y1 = round(w[3], 1)
word = w[4]
line = line_dict.get(y1, [])
line.append(word)
line_dict[y1] = line
lines = list(line_dict.items())
lines.sort()
return "n".join([" ".join(line[1]) for line in lines])
PRODUCCIÓN

page.first_annot () da la primera anotación, es decir, el cuadro delimitador de la página.
.recto da las coordenadas de un rectángulo.
Ahora, obtuvimos las coordenadas del rectángulo y todas las palabras en la página. Luego filtramos las palabras que están presentes en nuestro cuadro delimitador y las almacenamos en mis palabras variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.....
Tenemos todas las palabras del rectángulo con sus coordenadas. Sin embargo, estas palabras están en orden aleatorio. Como necesitamos el texto secuencialmente y eso solo tiene sentido, usamos una función make_text () que primero ordena las palabras de izquierda a derecha y luego de arriba a abajo. Devuelve el texto en formato de cadena.
¡Hurra! Hemos extraído datos de un comentario. Nuestra siguiente tarea es extraer datos de todas las anotaciones del PDF, lo que se haría con el mismo enfoque.
Extrayendo cada página del documento y todas las anotaciones / rectanges:
for pageno in range(0,len(doc)-1):
page = doc[pageno]
words = page.get_text("words")
for annot in page.annots():
if annot!=None:
rec=annot.rect
mywords = [w for w in words if fitz.Rect(w[:4]) in rec]
ann= make_text(mywords)
all_annots.append(ann)
all_annots, se inicializa una lista para almacenar el texto de todas las anotaciones en el pdf.
La función del ciclo externo en el código anterior es recorrer cada página del PDF, mientras que la del ciclo interno es revisar todas las anotaciones de la página y realizar la tarea de agregar textos a la lista all_annots como se discutió anteriormente.
La impresión de all_annots nos proporciona el texto de todas las anotaciones del pdf que puede ver a continuación.
PRODUCCIÓN
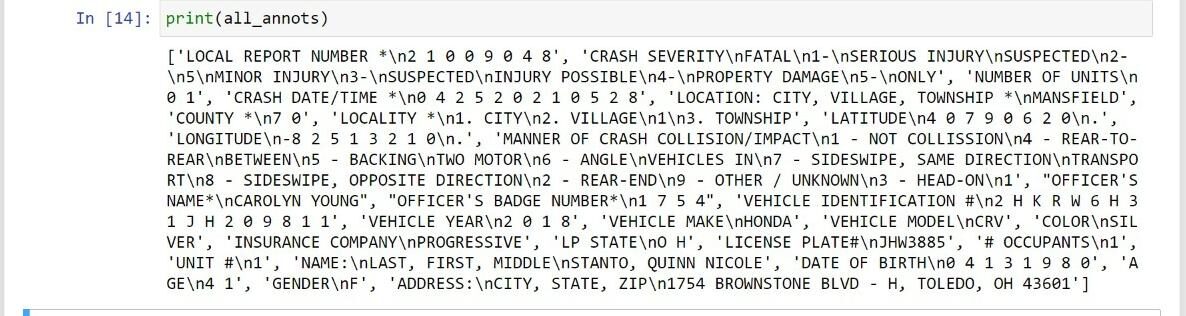
Finalmente, hemos extraído los textos de todas las anotaciones / cuadros delimitadores.
Es hora de limpiar los datos y traerlos de una forma comprensible.
Limpieza y procesamiento de datos
Dividiendo para formar el nombre de la columna y sus valores:
cont=[]
for i in range(0,len(all_annots)):
cont.append(all_annots[i].split('n',1))
Eliminar símbolos innecesarios *, # ,:
liss=[]
for i in range(0,len(cont)):
lis=[]
for j in cont[i]:
j=j.replace('*','')
j=j.replace('#','')
j=j.replace(':','')
j=j.strip()
#print(j)
lis.append(j)
liss.append(lis)
Dividir en claves y valores y eliminar espacios en los valores que solo contienen dígitos:
keys=[]
values=[]
for i in liss:
keys.append(i[0])
values.append(i[1])
for i in range(0, len(values)):
for j in range(0,len(values[i])):
if values[i][j]>='A' and values[i][j]<='Z':
break
if j==len(values[i])-1:
values[i]=values[i].replace(' ','')
Dividimos cada cadena en función de un carácter de nueva línea (n) para separar el nombre de la columna de sus valores. Al limpiar más, se eliminan los símbolos innecesarios como (*, #, 🙂. Se eliminan los espacios entre dígitos.
Con los pares clave-valor, creamos un diccionario que se muestra a continuación:
Conversión a diccionario:
report=dict(zip(keys,values))
reporte[‘VEHICLE IDENTIFICATION’]= informe[‘VEHICLE IDENTIFICATION’].reemplazar(‘ ‘,»)
dic=[report['LOCALITY'],report['MANNER OF CRASH COLLISION/IMPACT'],report['CRASH SEVERITY']]
l=0
val_after=[]
for local in dic:
li=[]
lii=[]
k=''
extract=""
l=0
for i in range(0,len(local)-1):
if local[i+1]>='0' and local[i+1]<='9':
li.append(local[l:i+1])
l=i+1
li.append(local[l:])
print(li)
for i in li:
if i[0] in lii:
k=i[0]
break
lii.append(i[0])
for i in li:
if i[0]==k:
extraer = yo
val_after.append(extract) break report['LOCALITY']=val_after[0] report['MANNER OF CRASH COLLISION/IMPACT']=val_after[1] report['CRASH SEVERITY']=val_after[2]
PRODUCCIÓN
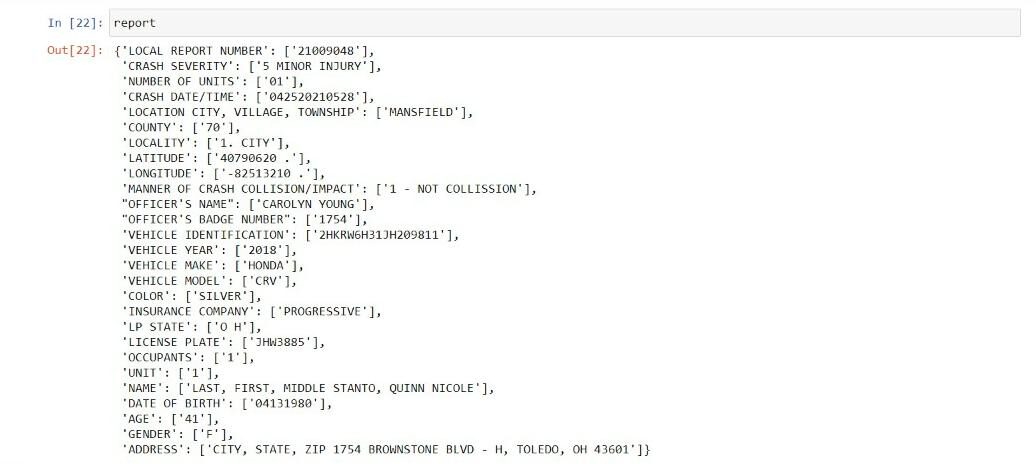
Por último, el diccionario se convierte en marco de datos con la ayuda de pandas.
Conversión a DataFrame y exportación a CSV:
data=pd.DataFrame.from_dict(report)
data.to_csv('final.csv',index=False)
PRODUCCIÓN
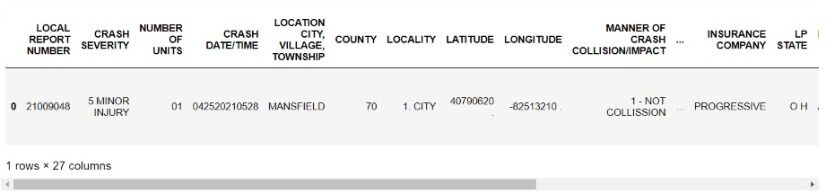
Ahora, podemos realizar análisis de nuestros datos estructurados o exportarlos a Excel.
Espero que hayas disfrutado leyendo este blog y te haya dado la intuición de cómo lidiar con datos no estructurados.
Referencias:
Fuente de la imagen destacada: Real Python https://realpython.com/python-data-engineer/
Documentación de PyMuPDF: https://pymupdf.readthedocs.io/en/latest/
Sobre el Autor:
¡Hola! Soy Ashish Choudhary. Estoy estudiando B.Tech de la Universidad de Ciencia y Tecnología JC Bose. La ciencia de datos es mi pasión y me enorgullece escribir blogs interesantes relacionados con ella. No dudes en contactarme en Linkedin linkedin.com/in/ashish-choudhary-7b6029166.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





