Introducción
Los recursos liderados en ciencia de datos no están creciendo como se esperaba y el crecimiento es solo del 14%.
Incluso en la era digital actual, la ciencia de datos todavía requiere mucho trabajo manual. Almacenar los datos generados, limpiarlos, análisis exploratorio, visualizar los datos y finalmente ajustarle un modelo para permitir la toma de decisiones. El trabajo manual se puede automatizar hasta cierto punto y, por lo tanto, el comienzo de la automatización en la ciencia de datos.
El ciclo de vida de un conjunto de datos en el proyecto de ciencia de datos es el siguiente
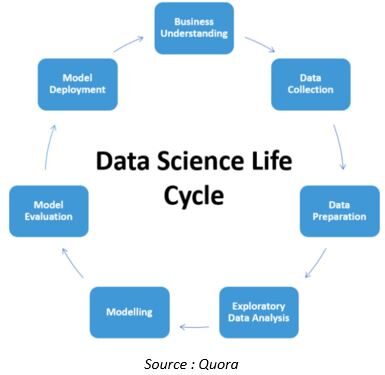
A excepción de la comprensión empresarial y la implementación del modelo, casi todos los aspectos de la canalización de la ciencia de datos están en proceso de automatización. Veamos algunos de los desarrollos en esta área.
Recopilación automática de datos
Dado que los datos son la piedra angular de todo análisis, debemos invertir una cantidad considerable de nuestro tiempo en comprenderlos. Los datos incompletos podrían dar lugar a modelos poco fiables o sesgados y, si la empresa tomara decisiones sobre estos modelos, no hace falta decir que conduciría a desastres que uno ni siquiera podría imaginar.
Dataprep es una biblioteca de Python de código abierto que nos permite preparar los datos con solo unas pocas líneas de código. Dataprep nos permite visualizar cualquier dato que falte en nuestro conjunto de datos, descubrir los datos que faltan es obligatorio mientras preparamos los datos para que podamos reemplazarlos con datos útiles en consecuencia.
A continuación se muestra la sintaxis para instalar la biblioteca Dataprep usando pip install
pip install -U dataprep
El conector es un componente de DataPrep que tiene como objetivo simplificar la recopilación de datos de las API web al proporcionar un conjunto estándar de operaciones. Es un contenedor de API de código abierto que acelera el desarrollo al realizar llamadas a múltiples API. Agiliza la llamada a múltiples API a través de una biblioteca intuitiva.
A continuación se muestra la sintaxis para instalar Dataprep.connector
from dataprep.connector import *
Veamos un ejemplo del uso de connect para recopilar datos. Con Connector, puede recopilar datos de uno de los principales sitios de recomendaciones en línea: Gañido.
from dataprep.connector import connect
# use the connect function with the "yelp" string and Yelp access token, both specified as parameters. This action allows us to create a Connector to the Yelp Web API:
yelp_connector = connect("yelp", _auth={"access_token":"<Your Yelp access token>"})
yelp_connector.info()# gives information on using Connector over Web API
Producción

en este ejemplo, solo hay un punto final disponible para Yelp: empresas. Sin embargo, si desea conectarse a un punto final de Yelp diferente, puede crear un nuevo archivo de configuración.
yelp_connector.show_schema («business») # explorar el esquema de punto final «empresarial» de acuerdo con su definición de archivo de configuración
Limpieza automática de datos
La limpieza de datos es una de las tareas más tediosas para un científico de datos, ocupa su valioso tiempo. Ha sido un tema de investigación exclusiva durante los últimos años. Tanto las nuevas empresas como las empresas grandes y establecidas ofrecen automatización y herramientas para la limpieza de datos.
DataPrep.Clean tiene como objetivo proporcionar una gran cantidad de funciones con una interfaz unificada para limpiar y estandarizar datos de varios tipos semánticos en Pandas.
DataPrep.Clean contiene funciones simples diseñadas para limpiar y validar datos en un DataFrame. A continuación se muestran los aspectos más destacados de la biblioteca DataPrep.Clean.
El siguiente código demuestra cómo usar DataPrep.Clean. Usaremos el conjunto de datos waste_hauler del repositorio interno de conjuntos de datos de DataPrep.
from dataprep.clean import *
from dataprep.datasets import load_dataset
df = load_dataset('waste_hauler')
df.head()
Producción

df = clean_headers(df)#converts the headers into snake case print(df.columns)
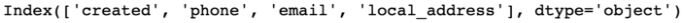
Hay muchas más funciones en dataprep.clean como se muestra a continuación
df = clean_phone(df, 'phone')#To standardize their formats, we can use the function clean_phone() df = clean_address(df, 'local_address')#to standardize the inconsistencies in address
Exploración automática de datos:
La exploración de datos se refiere a los pasos preliminares en el análisis de datos y la construcción de modelos en los que los analistas de datos utilizan técnicas estadísticas para describir las características del conjunto de datos, como tamaño, calidad, cantidad y precisión, y resumirlo para comprender mejor la naturaleza de los datos.
DataPrep.EDA es la herramienta EDA más rápida y sencilla de Python. Permite a los científicos de datos comprender a los pandas con unas pocas líneas de código en segundos.
La función plot_missing () permite un análisis exhaustivo de los valores faltantes y su impacto en el conjunto de datos. A continuación se describe la funcionalidad de plot_missing () para un marco de datos dado df.
from dataprep.eda import plot_missing
from dataprep.datasets import load_dataset
df = load_dataset("titanic")
plot_missing(df)
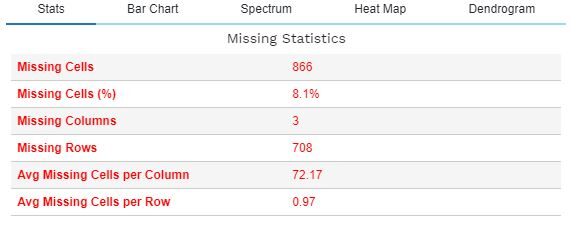
Hay muchas más funciones en dataprep.eda como se muestra a continuación
plot_correlation() #generates correlation matrices and correlation coefficient
plot(df) #plots a histogram for each numerical column, a bar chart for each categorical column, and computes datasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos.... statistics.
Nos permite crear informes detallados desde un Pandas / Dask DataFrame con la función create_report. DataPrep.EDA es 100 veces más rápido que las herramientas de creación de perfiles basadas en Pandas, genera visualizaciones interactivas en un informe que hace que el informe parezca más atractivo y también admite big data con millones de filas trabajando con lo que no era fácil con la biblioteca de pandas tradicional.
Modelado automático de ML:
El siguiente paso y el más buscado en el ciclo de vida de la ciencia de datos es el ajuste de modelos. El aprendizaje automático automatizado (AutoML) es actualmente la comidilla de la ciudad dentro de la comunidad de ciencia de datos. Auto ML nos proporciona las herramientas que nos ayudan a encontrar el modelo de aprendizaje automático apropiado para el conjunto de datos dado con la mínima participación del usuario.
LightAutoML es una de las bibliotecas de Python diseñada para realizar varias tareas como clasificación y regresión binaria / multiclase en conjuntos de datos tabulares, que contienen diferentes tipos de datos como numéricos, categóricos, textos, etc.
Otro ejemplo es Auto-Sklearn. Es una biblioteca de Python que se utiliza para descubrir automáticamente modelos de alto rendimiento para tareas de regresión. Utiliza modelos de aprendizaje automático de la biblioteca de aprendizaje automático scikit-learn.
El beneficio de Auto-Sklearn es que, además de descubrir la preparación de datos y el modelo que funciona para un conjunto de datos, también puede aprender de modelos que funcionaron bien en conjuntos de datos similares y pueden crear automáticamente un conjunto de datos de alto rendimiento. modelos descubiertos como parte del proceso de optimización.
En el siguiente ejemplo, usaremos Auto-Sklearn para descubrir un modelo para el conjunto de datos de la sonda. los AutoSklearnClassifier está configurado para funcionar durante 5 minutos con 8 núcleos y limitar la evaluación de cada modelo a 30 segundos.
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from autosklearn.classification import AutoSklearnClassifier
url="https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv"
dataframe = read_csv(url, header=None)
# split into input and output elements
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
# minimally prepare dataset
X = X.astype('float32')
y = LabelEncoder().fit_transform(y.astype('str'))
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# define search
model = AutoSklearnClassifier(time_left_for_this_task=5*60, per_run_time_limit=30, n_jobs=8)
model.fit(X_train, y_train)#perform the search
print(model.sprint_statistics())#summarize
Producción
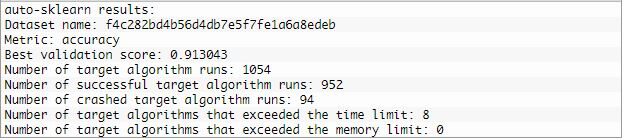
Evaluación del modelo:
Una vez construido el modelo, es hora de comprobar el rendimiento del mismo o más bien la precisión con la que está funcionando el modelo. Si la precisión no está a la altura de la marca, el modelo no se considera el ajuste correcto para ese conjunto de datos.

Como en el caso del ejemplo anterior, definimos una clase AutoSklearnClassifier para controlar la búsqueda y configurarla para que se ejecute durante un tiempo específico, digamos 2 minutos, y descartar cualquier modelo que tarde más de 30 segundos en evaluarse. Al final de estos 2 minutos, podemos revisar las estadísticas de la búsqueda y evaluar el modelo con mejor rendimiento.
# evaluate best model
y_hat = model.predict(X_test)
acc = accuracy_score(y_test, y_hat)
print("Accuracy: %.2f" % acc)
Se logró la precisión de clasificación del 81,2 por ciento, lo que es razonablemente hábil.
Limitaciones

A pesar de que la automatización ha ido en aumento en los últimos tiempos, definitivamente hay algunas advertencias / desventajas. Lo más importante es que AutoML necesita más recursos, de lo contrario, llevará más tiempo ejecutarlo. El procesamiento automático de aprendizaje automático de datos no estructurados y semiestructurados es técnicamente difícil.
A menudo, los problemas realistas son una combinación de múltiples objetivos, como tal, existe la necesidad de hacer diferencias sutiles entre la toma de decisiones y el costo, lo que requiere la intervención de un científico de datos. Siempre existirá la necesidad de puntos de control manuales donde los seres humanos puedan intervenir y firmar partes del proceso automatizado. Esto puede agregar la responsabilidad necesaria y ayudar con la regulación y la gobernanza. Por lo tanto, la aprobación final siempre la dará el científico de datos.
Referencias
https://machinelearningmastery.co
Los medios que se muestran en este artículo sobre Automatización en la ciencia de datos no son propiedad de DataPeaker y se utilizan a discreción del autor.





