Este post fue difundido como parte del Blogatón de ciencia de datos.
Visión general
Introducción
Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y... es un marco de procesamiento de datos que puede realizar rápidamente tareas de procesamiento en conjuntos de datos muy grandes y además puede repartir tareas de procesamiento de datos en múltiples computadoras, ya sea por sí solo o en conjunto con otras herramientas informáticas distribuidas. Es un motor de análisis unificado ultrarrápido para big data y aprendizaje automático.
Para admitir Python con Spark, la comunidad de Apache Spark lanzó una herramienta, PySpark. Con PySpark, se puede trabajar con RDD en el lenguaje de programación Python.
Los componentes de Spark son:
- Spark Core
- Spark SQL
- Spark Streaming
- Spark MLlib
- GraphX
- Chispa R
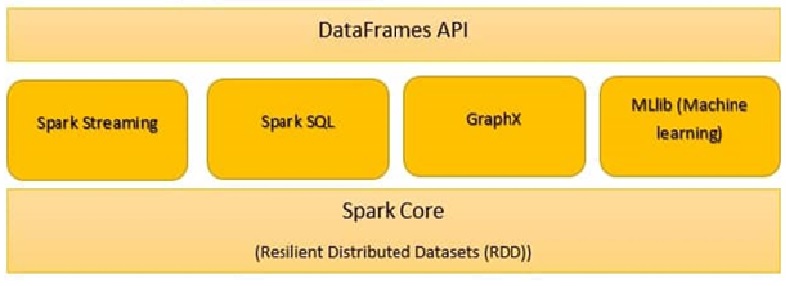
Spark Core
Todas las funcionalidades proporcionadas por Apache Spark se centran en la parte de arriba de Spark Core. Gestiona todas las funcionalidades de E / S esenciales. Se utiliza para el despacho de tareas y la recuperación de fallos. Spark Core está incrustado con una colección especial llamada RDD (conjunto de datos distribuido resistente). RDD se encuentra entre las abstracciones de Spark. Spark RDD maneja la partición de datos en todos los nodos de un clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo..... Los mantiene en el grupo de memoria del clúster como una sola unidad. Hay dos operaciones hechas en RDD:
Transformación: Es una función que produce nuevos RDD a partir de los RDD existentes.
Acción: En Transformation, los RDD se crean entre sí. Pero cuando queremos trabajar con el conjunto de datos real, entonces, en ese punto, usamos Action.
Spark SQL
El componente Spark SQL es un marco distribuido para el procesamiento de datos estructurados. Spark SQL trabaja para entrar a información estructurada y semiestructurada. Además posibilita aplicaciones analíticas potentes e interactivas en datos históricos y de transmisión. DataFrames y SQL proporcionan una forma común de entrar a una gama de fuentes de datos. Su característica principal es ser un optimizador basado en costos y tolerancia a fallas de consulta media.
Spark Streaming
Es un complemento de la API central de Spark que posibilita el procesamiento de transmisiones escalable, de alto rendimiento y tolerante a fallas de transmisiones de datos en vivo. Spark Streaming, agrupa los datos en vivo en pequeños lotes. Después lo entrega al sistema por lotes para su procesamiento. Además proporciona características de tolerancia a fallos.
Spark GraphX:
GraphX en Spark es una API para gráficos y ejecución paralela de gráficos. Es un motor de análisis de gráficos de red y un almacén de datos. En los gráficos además es factible agrupar, categorizar, recorrer, buscar y hallar rutas.
SparkR:
SparkR proporciona una implementación de marco de datos distribuido. Admite operaciones como selección, filtrado, agregación, pero en grandes conjuntos de datos.
Spark MLlib:
Spark MLlib se utiliza para realizar aprendizaje automático en Apache Spark. MLlib consta de algoritmos y utilidades populares. MLlib en Spark es una biblioteca de aprendizaje automático escalable que analiza tanto el algoritmo de alta calidad como la alta velocidad. Los algoritmos de aprendizaje automático como regresión, clasificación, agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo..., minería de patrones y filtrado colaborativo. Las primitivas de aprendizaje automático de nivel inferior, como el algoritmo genérico de optimización del descenso de gradientes, además están presentes en MLlib.
Spark.ml es la API de aprendizaje automático principal para Spark. La biblioteca Spark.ml ofrece una API de nivel superior construida sobre DataFrames para construir canalizaciones de ML.
Las herramientas Spark MLlib se proporcionan a continuación:
- Algoritmos ML
- Caracterización
- Oleoductos
- Persistencia
- Utilidades
-
Algoritmos ML
Los algoritmos ML forman el núcleo de MLlib. Estos incluyen algoritmos de aprendizaje comunes como clasificación, regresión, agrupación y filtrado colaborativo.
MLlib estandariza las API para ayudar la combinación de varios algoritmos en una única canalización o flujo de trabajo. Los conceptos clave son la API Pipelines, donde el concepto de canalización se inspira en el proyecto scikit-learn.
Transformador:
Un transformador es un algoritmo que puede transformar un DataFrame en otro DataFrame. Técnicamente, un Transformer implementa un método transform (), que convierte un DataFrame en otro, de forma general agregando una o más columnas. A modo de ejemplo:
Un transformador de características puede tomar un DataFrame, leer una columna (a modo de ejemplo, texto), asignarla a una nueva columna (a modo de ejemplo, vectores de características) y generar un nuevo DataFrame con la columna asignada adjunta.
Un modelo de aprendizaje puede tomar un DataFrame, leer la columna que contiene los vectores de características, predecir la etiqueta para cada vector de características y generar un nuevo DataFrame con etiquetas predichas agregadas como una columna.
EstimadorEl "Estimador" es una herramienta estadística utilizada para inferir características de una población a partir de una muestra. Se basa en métodos matemáticos para proporcionar estimaciones precisas y confiables. Existen diferentes tipos de estimadores, como los insesgados y los consistentes, que se eligen según el contexto y el objetivo del estudio. Su correcto uso es fundamental en investigaciones científicas, encuestas y análisis de datos....:
Un estimador es un algoritmo que se puede ajustar a un DataFrame para producir un transformador. Técnicamente, un Estimador implementa un método fit (), que acepta un DataFrame y produce un Modelo, que es un Transformer. A modo de ejemplo, un algoritmo de aprendizaje como LogisticRegression es un Estimador, y llamar a fit () entrena un LogisticRegressionModel, que es un Modelo y, por eso, un Transformador.
Transformer.transform () y Estimator.fit () son apátridas. En el futuro, los algoritmos con estado pueden ser compatibles con conceptos alternativos.
Cada instancia de un Transformer o Estimator tiene un ID único, que es útil para especificar parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... (que se describen a continuación).
-
Caracterización
La caracterización incluye extracción, transformación, disminución de dimensionalidad y selección de características.
- Feature Extraction se trata de extraer características de datos sin procesar.
- La transformación de características incluye escalar, renovar o modificar características
- La selección de características implica elegir un subconjunto de características indispensables de un gran conjunto de características.
-
Tuberías:
Una canalización encadena varios transformadores y estimadores para especificar un flujo de trabajo de AA. Además proporciona herramientas para construir, examinar y ajustar ML Pipelines.
En el aprendizaje automático, es común ejecutar una secuencia de algoritmos para procesar y aprender de los datos. MLlib representa un flujo de trabajo como PipelinePipeline es un término que se utiliza en diversos contextos, principalmente en tecnología y gestión de proyectos. Se refiere a un conjunto de procesos o etapas que permiten el flujo continuo de trabajo desde la concepción de una idea hasta su implementación final. En el ámbito del desarrollo de software, por ejemplo, un pipeline puede incluir la programación, pruebas y despliegue, garantizando así una mayor eficiencia y calidad en los..., que se trata de una secuencia de Etapas de Pipeline (Transformadores y Estimadores) que se ejecutarán en un orden específico. Usaremos este sencillo flujo de trabajo como ejemplo de ejecución en esta sección.
Ejemplo: la muestra de canalización que se muestra a continuación hace el preprocesamiento de datos en un orden específico como se indica a continuación:
1. Aplicar el método String Indexer para hallar el índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de las columnas categóricas
2. Aplicar codificación OneHot para las columnas categóricas
3. Aplicar el indexador de cadenas para la columna «etiqueta» de la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de salida
4. VectorAssembler se aplica tanto a columnas categóricas como a columnas numéricas. VectorAssembler es un transformador que combina una lista determinada de columnas en una sola columna de vector.
El flujo de trabajo de la canalización ejecutará el modelado de datos en el orden específico anterior.
from pyspark.ml.feature import OneHotEncoderEstimator, StringIndexer, VectorAssembler
categoricalColumns = ['job', 'marital', 'education', 'default', 'housing', 'loan'] stages = [] for categoricalCol in categoricalColumns: stringIndexer = StringIndexer(inputCol = categoricalCol, outputCol = categoricalCol + 'Indexer') encoder = OneHotEncoderEstimator(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "Vec"]) stages += [stringIndexer, encoder] label_stringIdx = StringIndexer(inputCol="deposit", outputCol="label") stages += [label_stringIdx] numericColumns = ['age', 'balance', 'duration'] assemblerInputs = [c + "Vec" for c in categoricalColumns] + numericColumns Vassembler = VectorAssembler(inputCols = assemblerInputs, outputCol="features") stages += [Vassembler]from pyspark.ml import Pipeline pipeline = Pipeline(stages = stages) pipelineModel = pipeline.fit(df) df = pipelineModel.transform(df) selectedCols = ['label', 'features'] + cols df = df.select(selectedCols)
Marco de datos
Los marcos de datos proporcionan una API más fácil de utilizar que los RDD. La API basada en DataFrame para MLlib proporciona una API uniforme en todos los algoritmos de ML y en varios idiomas. Los marcos de datos facilitan las canalizaciones de aprendizaje automático prácticas, en particular las transformaciones de características.
from pyspark.sql import SparkSession spark = SparkSession.builder.appName('mlearnsample').getOrCreate() df = spark.read.csv('loan_bank.csv', header = True, inferSchema = True) df.printSchema() -
Persistencia:
La persistencia ayuda a guardar y cargar algoritmos, modelos y canalizaciones. Esto ayuda a reducir el tiempo y los esfuerzos, dado que el modelo es persistente, se puede cargar / reutilizar en cualquier momento cuando sea necesario.
from pyspark.ml.classification import LogisticRegression lr = LogisticRegression(featuresCol="features", labelCol="label") lrModel = lr.fit(train)
de pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluador = BinaryClassificationEvaluator ()
print (‘Test Area Under ROC’, evaluator.evaluate (predicciones))
predictions = lrModel.transform(test) predictions.select('age', 'label', 'rawPrediction', 'prediction').show() -
Utilidades:
Utilidades para álgebra lineal, estadística y manejo de datos. Ejemplo: mllib.linalg son las utilidades MLlib para álgebra lineal.
Material de referencia:
https://spark.apache.org/docs/latest/ml-guide.html
Notas finales
Spark MLlib es necesario si se trata de big data y aprendizaje automático. En este post, aprendió sobre los detalles de Spark MLlib, marcos de datos y canalizaciones. En el post futuro, trabajaremos en código práctico para poner en práctica Pipelines y construir modelos de datos usando MLlib.





