Introducción
La industria de análisis se trata de obtener la «información» de los datos. Con la creciente cantidad de datos en los últimos años, que en su mayoría no están estructurados, es difícil obtener la información relevante y deseada. Pero, la tecnología ha desarrollado algunos métodos poderosos que se pueden usar para extraer los datos y obtener la información que estamos buscando.
Una de estas técnicas en el campo de la minería de texto es el modelado de temas. Como sugiere el nombre, es un procedimiento para identificar automáticamente los temas presentes en un objeto de texto y derivar patrones ocultos exhibidos por un corpus de texto. Por eso, ayudando a una mejor toma de decisiones.
El modelado de temas es distinto de los enfoques de minería de texto basados en reglas que usan expresiones regulares o técnicas de búsqueda de palabras clave sustentadas en diccionarios. Es un enfoque no supervisado que se utiliza para buscar y observar el conjunto de palabras (llamadas «temas») en grandes grupos de textos.
Los temas se pueden establecer como «un patrón repetido de términos concurrentes en un corpus». Un buen modelo de tema debe dar como consecuencia: «salud», «médico», «paciente», «hospital» para un tema – Atención médica y «granja», «cultivos», «trigo» para un tema – «Agricultura».
Los modelos de temas son muy útiles para la agrupación de documentos, la organización de grandes bloques de datos textuales, la recuperación de información de texto no estructurado y la selección de características. A modo de ejemplo, el New York Times está usando modelos de temas para impulsar sus motores de recomendación de posts de usuario. Varios profesionales están usando modelos temáticos para las industrias de contratación, en los que su objetivo es extraer características latentes de las descripciones de puestos y asignarlas a los candidatos adecuados. Se usan para organizar grandes conjuntos de datos de correos electrónicos, reseñas de clientes y perfiles de redes sociales de usuarios.
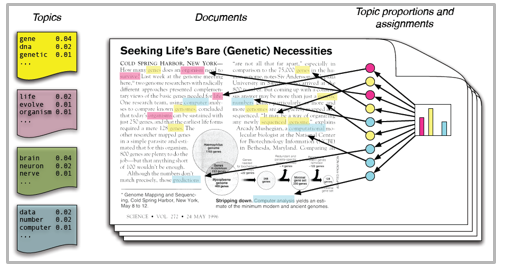
Entonces, si no está seguro sobre el procedimiento completo de modelado de temas, esta guía le presentará varios conceptos seguidos de su implementación en Python.
Tabla de contenidos
- Asignación de Dirichlet latente para el modelado de temas
- Implementación de Python
- Preparando documentos
- Limpieza y preprocesamiento
- Preparación de la matriz de términos del documento
- Ejecución del modelo LDA
- Resultados
- Consejos para impulsar los resultados del modelado de temas
- Filtro de frecuencia
- Parte del filtro de etiquetas de voz
- LDA Wise por lotes
- Modelado de temas para la selección de características
Asignación de Dirichlet latente para el modelado de temas
Hay muchos enfoques para obtener temas de un texto como: Frecuencia de términos y Frecuencia de documento inversa. Técnicas de factorización matricial no negativa. La asignación de Dirichlet latente es la técnica de modelado de temas más popular y en este post discutiremos lo mismo.
LDA asume que los documentos se producen a partir de una combinación de temas. Posteriormente, esos temas generan palabras sustentadas en su distribución de probabilidad. Dado un conjunto de datos de documentos, LDA retrocede e intenta averiguar qué temas crearían esos documentos en primer lugar.
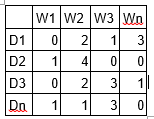
LDA es una técnica de factorización matricial. En el espacio vectorial, cualquier corpus (colección de documentos) se puede representar como una matriz documento-término. La próxima matriz muestra un corpus de N documentos D1, D2, D3… Dn y el tamaño de vocabulario de M palabras W1, W2 .. Wn. El valor de la celda i, j da el recuento de frecuencia de la palabra Wj en el documento Di.
LDA convierte esta matriz de documentos y términos en dos matrices de menor dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y...: M1 y M2.
M1 es una matriz de documentos y temas y M2 es una matriz de temas y términos con dimensiones (N, K) y (K, M) respectivamente, donde N es el número de documentos, K es el número de temas y M es el tamaño del vocabulario .
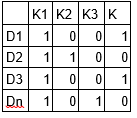
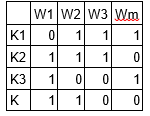
Tenga en cuenta que estas dos matrices ya proporcionan distribuciones de temas de documentos y palabras. A pesar de esto, estas distribuciones deben mejorarse, que es el objetivo principal de LDA. LDA utiliza técnicas de muestreo para impulsar estas matrices.
Repite cada palabra «w» para cada documento «d» e intenta ajustar el tema actual – asignación de palabras con una nueva asignación. Se asigna un nuevo tema «k» a la palabra «w» con una probabilidad P que es un producto de dos probabilidades p1 y p2.
Para cada tema, se calculan dos probabilidades p1 y p2. P1 – p (tema t / documento d) = la proporción de palabras en el documento d que están hoy en día asignadas al tema t. P2 – p (palabra w / tema t) = la proporción de asignaciones al tema t sobre todos los documentos que provienen de esta palabra w.
El tema actual: la asignación de palabras se actualiza con un nuevo tema con la probabilidad, producto de p1 y p2. En este paso, el modelo asume que todas las asignaciones de palabra y tema existentes, excepto la palabra actual, son correctas. Esta es esencialmente la probabilidad de que el tema t genere la palabra w, por lo que tiene sentido ajustar el tema de la palabra actual con una nueva probabilidad.
Después de varias iteraciones, se logra un estado estable en el que las distribuciones del tema del documento y de los términos del tema son bastante buenas. Este es el punto de convergencia de LDA.
Parámetros de LDA
Hiperparámetros alfa y beta: alfa representa la densidad de documentos y temas y Beta representa la densidad de temas y palabras. Cuanto mayor sea el valor de alfa, los documentos se componen de más temas y menor el valor de alfa, los documentos contienen menos temas. Por otra parte, a mayor beta, los temas se componen de una gran cantidad de palabras en el corpus, y con menor valor de beta, se componen de pocas palabras.
Número de temas: número de temas que se extraerán del corpus. Los investigadores han desarrollado enfoques para obtener un número óptimo de temas usando Kullback Leibler Divergence Score. No discutiré esto en detalle, puesto que es demasiado matemático. Para comprender, uno puede referirse a este[1] documento original sobre el uso de la divergencia KL.
Número de términos de tema: número de términos compuestos en un solo tema. De forma general se decide según el requisito. Si el enunciado del problema habla sobre la extracción de temas o conceptos, se recomienda seleccionar un número mayor, si el enunciado del problema habla sobre la extracción de características o términos, se recomienda un número bajo.
Número de iteraciones / pasadas: número máximo de iteraciones permitidas al algoritmo LDA para la convergencia.
Puede aprender a modelar temas en profundidad aquí.
Corriendo en Python
Preparando documentos
Aquí están los documentos de muestra que se combinan para formar un corpus.
doc1 = "Sugar is bad to consume. My sister likes to have sugar, but not my father." doc2 = "My father spends a lot of time driving my sister around to dance practice." doc3 = "Doctors suggest that driving may cause increased stress and blood pressure." doc4 = "Sometimes I feel pressure to perform well at school, but my father never seems to drive my sister to do better." doc5 = "Health experts say that Sugar is not good for your lifestyle."
# compile documents doc_complete = [doc1, doc2, doc3, doc4, doc5]
Limpieza y preprocesamiento
La limpieza es un paso importante antes de cualquier tarea de minería de texto, en este paso eliminaremos los signos de puntuación, palabras vacías y normalizaremos el corpus.
``` from nltk.corpus import stopwords from nltk.stem.wordnet import WordNetLemmatizer import stringstop = set(stopwords.words('english')) exclude = set(string.punctuation) lemma = WordNetLemmatizer()def clean(doc): stop_free = " ".join([i for i in doc.lower().split() if i not in stop]) punc_free="".join(ch for ch in stop_free if ch not in exclude) normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split()) return normalized
doc_clean = [clean(doc).split() for doc in doc_complete] ```
Preparación de la matriz de plazo del documento
Todos los documentos de texto combinados se conocen como corpus. Para ejecutar cualquier modelo matemático en un corpus de texto, es una buena práctica convertirlo en una representación matricial. El modelo LDA busca patrones de términos repetidos en toda la matriz DT. Python proporciona muchas bibliotecas excelentes para las prácticas de minería de texto, «gensim» es una de esas bibliotecas limpias y hermosas para manejar datos de texto. Es escalable, robusto y eficiente. El siguiente código muestra cómo convertir un corpus en una matriz de documentos y términos.
```# Importing Gensim
import gensim
from gensim import corpora
# Creating the term dictionary of our courpus, where"WHERE" es un término en inglés que se traduce como "dónde" en español. Se utiliza para hacer preguntas sobre la ubicación de personas, objetos o eventos. En contextos gramaticales, puede funcionar como adverbio de lugar y es fundamental en la formación de preguntas. Su correcta aplicación es esencial en la comunicación cotidiana y en la enseñanza de idiomas, facilitando la comprensión y el intercambio de información sobre posiciones y direcciones.... every unique term is assigned an index. dictionary = corpora.Dictionary(doc_clean)
# Converting list of documents (corpus) into Document Term Matrix using dictionary prepared above.
doc_term_matrix = [dictionary.doc2bow(doc) for doc in doc_clean] ```
Ejecución del modelo LDA
El siguiente paso es crear un objeto para el modelo LDA y entrenarlo en la matriz Documento-Término. El entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... además necesita algunos parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... como entrada que se explican en la sección anterior. El módulo gensim posibilita tanto la estimación del modelo LDA a partir de un corpus de entrenamiento como la inferencia de la distribución de temas en documentos nuevos e inéditos.
```# Creating the object for LDA model using gensim library
Lda = gensim.models.ldamodel.LdaModel
# Running and Trainign LDA model on the document term matrix.ldamodel = Lda(doc_term_matrix, num_topics=3, id2word = dictionary, passes=50)
```
Resultados
``` print(ldamodel.print_topics(num_topics=3, num_words=3)) ['0.168*health + 0.083*sugar + 0.072*bad,
'0.061*consume + 0.050*drive + 0.050*sister,
'0.049*pressur + 0.049*father + 0.049*sister] ```
Cada línea es un tema con términos y pesos individuales. Topic1 puede denominarse Mala salud y Topic3 puede denominarse Familia.
Consejos para impulsar los resultados del modelado de temas
Los resultados de los modelos de temas dependen totalmente de las características (términos) presentes en el corpus. El corpus se representa como matriz de términos del documento, que en general es de naturaleza muy escasa. Reducir la dimensionalidad de la matriz puede mejorar los resultados del modelado de temas. Según mi experiencia práctica, hay pocos enfoques que funcionen.
1. Filtro de frecuencia – Organice cada término de acuerdo con su frecuencia. Es más probable que los términos con frecuencias más altas aparezcan en los resultados en comparación con los de baja frecuencia. Los términos de baja frecuencia son esencialmente características débiles del corpus, por lo que es una buena práctica deshacerse de todas esas características débiles. Un análisis exploratorio de los términos y su frecuencia puede ayudar a elegir qué valor de frecuencia debe considerarse como umbral.
2. Parte del filtro de etiquetas de voz: El filtro de etiquetas POS tiene más que ver con el contexto de las funciones que con la frecuencia de las mismas. El modelado de temas intenta trazar los patrones recurrentes de términos en temas. A pesar de esto, es factible que todos los términos no sean igualmente importantes contextualmente. A modo de ejemplo, la etiqueta POS IN contiene términos como – «dentro de», «sobre», «excepto». «CD» contiene – «uno», «dos», «cien», etc. «MD» contiene «puede», «debe», etc. Estos términos son las palabras de apoyo de un idioma y pueden eliminarse estudiando sus etiquetas de publicación.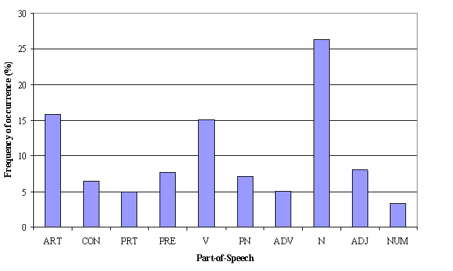
3. LDA Wise por lotes –Para recuperar los términos del tema más importantes, un corpus se puede dividir en lotes de tamaños fijos. La ejecución de LDA varias veces en estos lotes proporcionará resultados diferentes; a pesar de esto, los mejores términos de tema serán la intersección de todos los lotes.
Nota: Si desea aprender modelado de temas en detalle y además hacer un proyecto usándolo, entonces tenemos a curso basado en video en PNL, que cubre el modelado de temas y su implementación en Python.
Modelado de temas para la selección de características
A veces, LDA además se puede usar como técnica de selección de características. Tomemos un ejemplo de un obstáculo de clasificación de texto en el que los datos de capacitación contienen documentos por categorías. Si LDA se ejecuta en conjuntos de documentos de categoría. Seguido por la eliminación de términos de temas comunes en los resultados de diferentes categorías, se obtendrán las mejores características para una categoría.
Notas finales
Con esto, llegamos al final del tutorial sobre Modelado de Temas. Espero que esto le ayude a mejorar sus conocimientos para trabajar con datos de texto. Para obtener los máximos beneficios de este tutorial, le sugiero que practique los códigos uno al lado del otro y verifique los resultados.
¿Le fue útil el post? Comparta con nosotros si ha realizado un tipo de análisis semejante previamente. Háganos saber su opinión sobre este post en el cuadro a continuación.
Referencias
- http://link.springer.com/chapter/10.1007%2F978-3-642-13657-3_43





