Introducción
Los datos y la información en la web están creciendo exponencialmente. Hoy en día, todos usamos Google como nuestra primera fuente de conocimiento, ya sea para encontrar reseñas sobre un lugar para comprender un nuevo término. Toda esta información ya está disponible en la web.
Con la cantidad de datos disponibles en la web, abre nuevos horizontes de posibilidad para un Científico de datos. Creo firmemente que el web scraping es una habilidad imprescindible para cualquier científico de datos. En el mundo actual, todos los datos que necesita ya están disponibles en Internet; lo único que le impide usarlos es la capacidad de acceder a ellos. Con la ayuda de este artículo, también podrá superar esa barrera.
La mayoría de los datos disponibles en la web no están disponibles. Está presente en un formato no estructurado (formato HTML) y no se puede descargar. Por lo tanto, se requiere conocimiento y experiencia para utilizar estos datos para eventualmente construye un modelo útil.
En este artículo, lo guiaré a través del proceso de raspado web en R. Con este artículo, obtendrá experiencia para utilizar cualquier tipo de datos disponibles en Internet.
Tabla de contenido
- ¿Qué es Web Scraping?
- ¿Por qué necesitamos Web Scraping en Ciencia de los datos?
- Formas de extraer datos
- Prerrequisitos
- Raspando una página web usando R
- Analizar datos extraídos de la web
1. ¿Qué es Web Scraping?
El web scraping es una técnica para convertir los datos presentes en formato no estructurado (etiquetas HTML) en la web al formato estructurado al que se puede acceder y utilizar fácilmente.
Casi todos los lenguajes principales proporcionan formas de realizar raspado web. En este artículo, usaremos R para extraer los datos de los largometrajes más populares de 2016 del IMDb sitio web.
Obtendremos una serie de funciones para cada uno de los 100 largometrajes populares lanzados en 2016. Además, veremos los problemas más comunes que uno podría enfrentar al extraer datos de Internet debido a la falta de coherencia en el sitio web. codifique y observe cómo resolver estos problemas.
Si se siente más cómodo usando Python, le recomendaré que lea esta guía para comenzar con el raspado web con Python.
2. ¿Por qué necesitamos Web Scraping?
Estoy seguro de que las primeras preguntas que deben haber surgido en su cabeza hasta ahora es «¿Por qué necesitamos web scraping»? Como dije antes, las posibilidades con el web scraping son inmensas.
Para brindarle conocimientos prácticos, vamos a extraer datos de IMDB. Algunas otras aplicaciones posibles para las que puede utilizar el web scraping son:
- Extracción de datos de clasificación de películas para crear motores de recomendación de películas.
- Extraer datos de texto de Wikipedia y otras fuentes para crear sistemas basados en PNL o entrenar modelos de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... para tareas como el reconocimiento de temas del texto dado.
- Extraer datos de imágenes etiquetadas de sitios web como Google, Flickr, etc. para entrenar modelos de clasificación de imágenes.
- Recolección de datos de sitios de redes sociales como Facebook y Twitter para realizar tareas de análisis de sentimientos, minería de opiniones, etc.
- Extraer opiniones y comentarios de los usuarios de sitios de comercio electrónico como Amazon, Flipkart, etc.
3. Formas de extraer datos
Hay varias formas de extraer datos de la web. Algunas de las formas populares son:
- Copiar y pegar humanos: Esta es una forma lenta y eficiente de extraer datos de la web. Esto implica que los propios humanos analicen y copien los datos en el almacenamiento local.
- Coincidencia de patrones de texto: Otro enfoque simple pero poderoso para extraer información de la web es mediante el uso de funciones de coincidencia de expresiones regulares de los lenguajes de programación. Puede obtener más información sobre las expresiones regulares aquí.
- Interfaz API: Muchos sitios web como Facebook, Twitter, LinkedIn, etc. proporcionan API públicas y / o privadas a las que se puede llamar utilizando el código estándar para recuperar los datos en el formato prescrito.
- Análisis DOM: Mediante el uso de navegadores web, los programas pueden recuperar el contenido dinámico generado por los scripts del lado del cliente. También es posible analizar páginas web en un árbol DOM, según los programas que pueden recuperar partes de estas páginas.
Usaremos el enfoque de análisis de DOM durante el transcurso de este artículo. Y confíe en los selectores CSS de la página web para encontrar los campos relevantes que contienen la información deseada. Pero antes de comenzar, hay algunos requisitos previos que se necesitan para extraer datos de manera competente de cualquier sitio web.
4. Requisitos previos
Los requisitos previos para realizar el raspado web en R se dividen en dos grupos:
- Para comenzar con el web scraping, debe tener conocimientos prácticos del lenguaje R. Si recién está comenzando o desea repasar los conceptos básicos, le recomiendo encarecidamente seguir esta ruta de aprendizaje en R. Durante el transcurso de este artículo, usaremos el paquete ‘rvest’ en R escrito por Hadley Wickham. Puede acceder a la documentación del paquete rvest aquí. Asegúrese de tener este paquete instalado. Si aún no tiene este paquete, puede seguir el siguiente código para instalarlo.
install.packages('rvest')
- Agregar conocimiento de HTML y CSS será una ventaja adicional. Una de las mejores fuentes que pude encontrar para aprender HTML y CSS es esta. He observado que la mayoría de los científicos de datos no son muy sólidos con conocimientos técnicos de HTML y CSS. Por lo tanto, usaremos un software de código abierto llamado Selector Gadget que será más que suficiente para que cualquiera pueda realizar el web scraping. Puede acceder y descargar la extensión Selector Gadget aquí. Asegúrese de tener instalada esta extensión siguiendo las instrucciones del sitio web. He hecho lo mismo. Estoy usando Google Chrome y puedo acceder a la extensión en la barra de extensión en la parte superior derecha.
Con esto, puede seleccionar las partes de cualquier sitio web y obtener las etiquetas relevantes para acceder a esa parte simplemente haciendo clic en esa parte del sitio web. Tenga en cuenta que esta es una manera de aprender HTML y CSS y hacerlo manualmente. Pero para dominar el arte del web scraping, le recomiendo encarecidamente que aprenda HTML y CSS para comprender y apreciar mejor lo que está sucediendo bajo el capó.
4. Raspado de una página web con R
Ahora, comencemos a buscar en el sitio web de IMDb los 100 largometrajes más populares lanzados en 2016. Puede acceder a ellos aquí.
#Loading the rvest package
library('rvest')
#Specifying the url for desired website to be scraped
url <- 'http://www.imdb.com/search/title?count=100&release_date=2016,2016&title_type=feature'
#Reading the HTML code from the website
webpage <- read_html(url)
Ahora, extraeremos los siguientes datos de este sitio web.
- Rango: El rango de la película de 1 a 100 en la lista de las 100 películas más populares estrenadas en 2016.
- Título: El título del largometraje.
- Descripción: La descripción del largometraje.
- Tiempo de ejecución: La duración del largometraje.
- Género: El género del largometraje,
- Clasificación: La calificación de IMDb del largometraje.
- Metascore: El metascore en el sitio web de IMDb para el largometraje.
- Votos: Votos emitidos a favor del largometraje.
- Ingresos_brutos_en_Mil: Las ganancias brutas del largometraje en millones.
- Director: El director principal del largometraje. Tenga en cuenta que, en el caso de varios directores, tomaré solo el primero.
- Actor: El actor principal del largometraje. Tenga en cuenta que, en el caso de varios actores, tomaré solo el primero.
Aquí hay una captura de pantalla que contiene cómo están organizados todos estos campos.
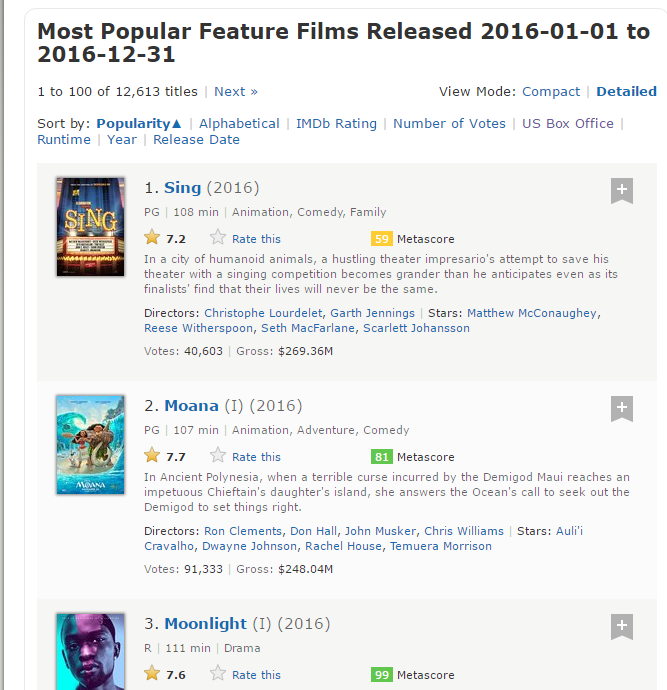
Paso 1: Ahora, comenzaremos raspando el campo Rango. Para eso, usaremos el gadget selector para obtener los selectores CSS específicos que encierran las clasificaciones. Puede hacer clic en la extensión en su navegador y seleccionar el campo de clasificación con el cursor.
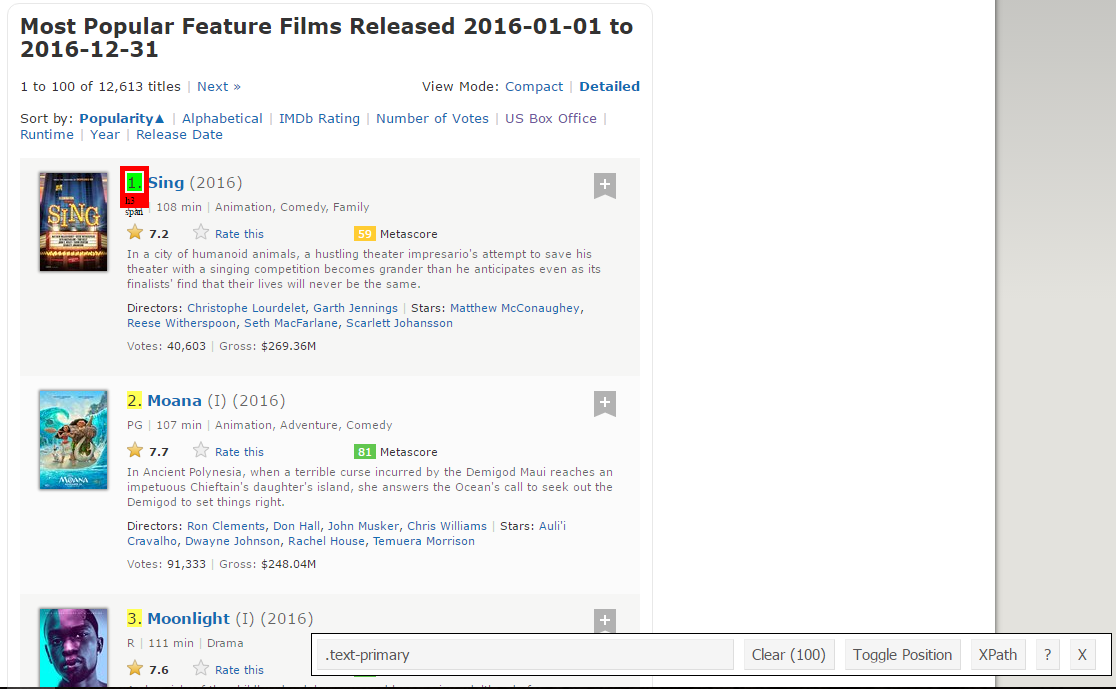
Asegúrese de que todas las clasificaciones estén seleccionadas. Puede seleccionar algunas secciones de clasificación más en caso de que no pueda obtenerlas todas y también puede deseleccionarlas haciendo clic en la sección seleccionada para asegurarse de que solo tenga las secciones resaltadas que desea raspar para ese momento. .
Paso 2: Una vez que esté seguro de haber realizado las selecciones correctas, debe copiar el selector de CSS correspondiente que puede ver en la parte inferior central.
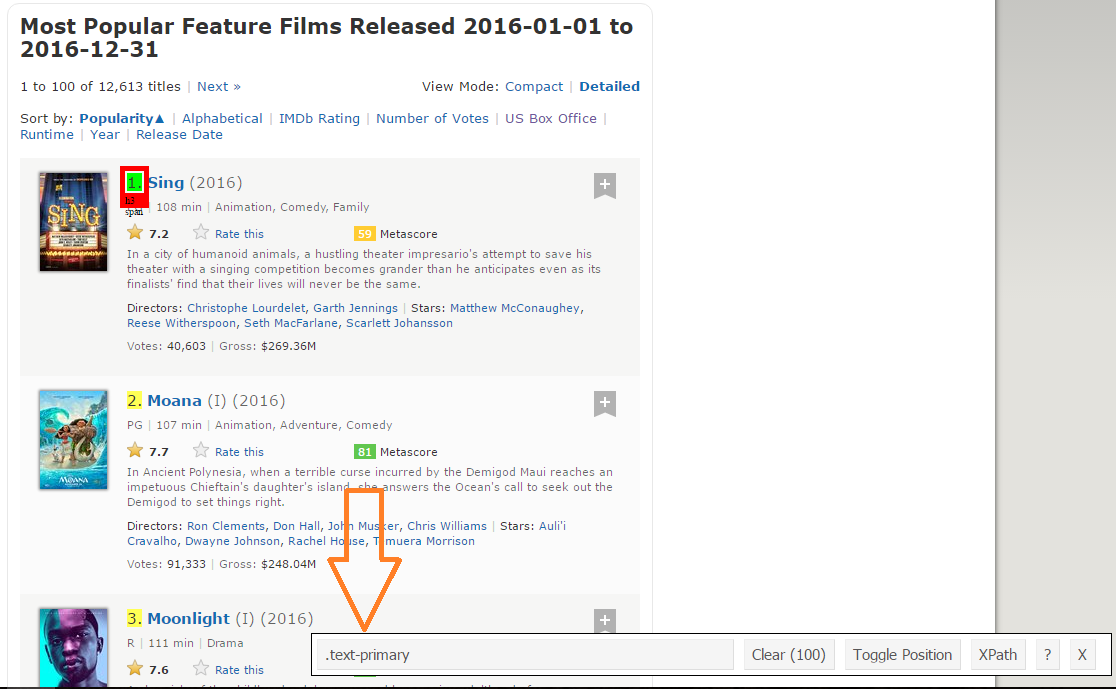
Paso 3: Una vez que conozca el selector de CSS que contiene las clasificaciones, puede usar este simple código R para obtener todas las clasificaciones:
#Using CSS selectors to scrape the rankings section rank_data_html <- html_nodes(webpage,'.text-primary') #Converting the ranking data to text rank_data <- html_text(rank_data_html) #Let's have a look at the rankings head(rank_data) [1] "1." "2." "3." "4." "5." "6."
Paso 4: Una vez que tenga los datos, asegúrese de que se vean en el formato deseado. Estoy preprocesando mis datos para convertirlos a formato numérico.
#Data-Preprocessing: Converting rankings to numerical rank_data<-as.numeric(rank_data) #Let's have another look at the rankings head(rank_data) [1] 1 2 3 4 5 6
Paso 5: Ahora puede borrar la sección del selector y seleccionar todos los títulos. Puede inspeccionar visualmente que todos los títulos estén seleccionados. Realice las adiciones y eliminaciones necesarias con la ayuda de su cursor. Yo he hecho lo mismo aquí.
Paso 6: Nuevamente, tengo el selector de CSS correspondiente para los títulos: .lister-item-header a. Usaré este selector para raspar todos los títulos usando el siguiente código.
#Using CSS selectors to scrape the title section title_data_html <- html_nodes(webpage,'.lister-item-header a') #Converting the title data to text title_data <- html_text(title_data_html) #Let's have a look at the title head(title_data) [1] "Sing" "Moana" "Moonlight" "Hacksaw Ridge" [5] "Passengers" "Trolls"
Paso 7: En el siguiente código, he hecho lo mismo para el raspado: descripción, tiempo de ejecución, género, calificación, metapuntuacion, votos, ingresos brutos en mil, datos de director y actor.
#Using CSS selectors to scrape the description section
description_data_html <- html_nodes(webpage,'.ratings-bar+ .text-muted')
#Converting the description data to text
description_data <- html_text(description_data_html)
#Let's have a look at the description data
head(description_data)
[1] "nIn a city of humanoid animals, a hustling theater impresario's attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists' find that their lives will never be the same."
[2] "nIn Ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain's daughter's island, she answers the Ocean's call to seek out the Demigod to set things right."
[3] "nA chronicle of the childhood, adolescence and burgeoning adulthood of a young, African-American, gay man growing up in a rough neighborhood of Miami."
[4] "nWWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot."
[5] "nA spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early."
[6] "nAfter the Bergens invade Troll Village, Poppy, the happiest Troll ever born, and the curmudgeonly Branch set off on a journey to rescue her friends.
#Data-Preprocessing: removing 'n'
description_data<-gsub("n","",description_data)
#Let's have another look at the description data
head(description_data)
[1] "In a city of humanoid animals, a hustling theater impresario's attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists' find that their lives will never be the same."
[2] "In Ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain's daughter's island, she answers the Ocean's call to seek out the Demigod to set things right."
[3] "A chronicle of the childhood, adolescence and burgeoning adulthood of a young, African-American, gay man growing up in a rough neighborhood of Miami."
[4] "WWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot."
[5] "A spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early."
[6] "After the Bergens invade Troll Village, Poppy, the happiest Troll ever born, and the curmudgeonly Branch set off on a journey to rescue her friends."
#Using CSS selectors to scrape the Movie runtime section
runtime_data_html <- html_nodes(webpage,'.text-muted .runtime')
#Converting the runtime data to text
runtime_data <- html_text(runtime_data_html)
#Let's have a look at the runtime
head(runtime_data)
[1] "108 min" "107 min" "111 min" "139 min" "116 min" "92 min"
#Data-Preprocessing: removing mins and converting it to numerical
runtime_data<-gsub(" min","",runtime_data)
runtime_data<-as.numeric(runtime_data)
#Let's have another look at the runtime data
head(runtime_data)
[1] 1 2 3 4 5 6
#Using CSS selectors to scrape the Movie genre section
genre_data_html <- html_nodes(webpage,'.genre')
#Converting the genre data to text
genre_data <- html_text(genre_data_html)
#Let's have a look at the runtime
head(genre_data)
[1] "nAnimation, Comedy, Family "
[2] "nAnimation, Adventure, Comedy "
[3] "nDrama "
[4] "nBiography, Drama, History "
[5] "nAdventure, Drama, Romance "
[6] "nAnimation, Adventure, Comedy "
#Data-Preprocessing: removing n
genre_data<-gsub("n","",genre_data)
#Data-Preprocessing: removing excess spaces
genre_data<-gsub(" ","",genre_data)
#taking only the first genre of each movie
genre_data<-gsub(",.*","",genre_data)
#Convering each genre from text to factor
genre_data<-as.factor(genre_data)
#Let's have another look at the genre data
head(genre_data)
[1] Animation Animation Drama Biography Adventure Animation
10 Levels: Action Adventure Animation Biography Comedy Crime Drama ... Thriller
#Using CSS selectors to scrape the IMDB rating section
rating_data_html <- html_nodes(webpage,'.ratings-imdb-rating strong')
#Converting the ratings data to text
rating_data <- html_text(rating_data_html)
#Let's have a look at the ratings
head(rating_data)
[1] "7.2" "7.7" "7.6" "8.2" "7.0" "6.5"
#Data-Preprocessing: converting ratings to numerical
rating_data<-as.numeric(rating_data)
#Let's have another look at the ratings data
head(rating_data)
[1] 7.2 7.7 7.6 8.2 7.0 6.5
#Using CSS selectors to scrape the votes section
votes_data_html <- html_nodes(webpage,'.sort-num_votes-visible span:nth-child(2)')
#Converting the votes data to text
votes_data <- html_text(votes_data_html)
#Let's have a look at the votes data
head(votes_data)
[1] "40,603" "91,333" "112,609" "177,229" "148,467" "32,497"
#Data-Preprocessing: removing commas
votes_data<-gsub(",","",votes_data)
#Data-Preprocessing: converting votes to numerical
votes_data<-as.numeric(votes_data)
#Let's have another look at the votes data
head(votes_data)
[1] 40603 91333 112609 177229 148467 32497
#Using CSS selectors to scrape the directors section
directors_data_html <- html_nodes(webpage,'.text-muted+ p a:nth-child(1)')
#Converting the directors data to text
directors_data <- html_text(directors_data_html)
#Let's have a look at the directors data
head(directors_data)
[1] "Christophe Lourdelet" "Ron Clements" "Barry Jenkins"
[4] "Mel Gibson" "Morten Tyldum" "Walt Dohrn"
#Data-Preprocessing: converting directors data into factors
directors_data<-as.factor(directors_data)
#Using CSS selectors to scrape the actors section
actors_data_html <- html_nodes(webpage,'.lister-item-content .ghost+ a')
#Converting the gross actors data to text
actors_data <- html_text(actors_data_html)
#Let's have a look at the actors data
head(actors_data)
[1] "Matthew McConaughey" "Auli'i Cravalho" "Mahershala Ali"
[4] "Andrew Garfield" "Jennifer Lawrence" "Anna Kendrick"
#Data-Preprocessing: converting actors data into factors
actors_data<-as.factor(actors_data)
Pero quiero que siga de cerca lo que sucede cuando hago lo mismo con los datos de Metascore.
#Using CSS selectors to scrape the metascore section
metascore_data_html <- html_nodes(webpage,'.metascore')
#Converting the runtime data to text
metascore_data <- html_text(metascore_data_html)
#Let's have a look at the metascore
data head(metascore_data)
[1] "59 " "81 " "99 " "71 " "41 "
[6] "56 "
#Data-Preprocessing: removing extra space in metascore
metascore_data<-gsub(" ","",metascore_data)
#Lets check the length of metascore data
length(metascore_data)
[1] 96
Paso 8: La longitud de los datos de metascore es 96 mientras estamos raspando los datos de 100 películas. La razón por la que esto sucedió es que hay 4 películas que no tienen los campos Metascore correspondientes.
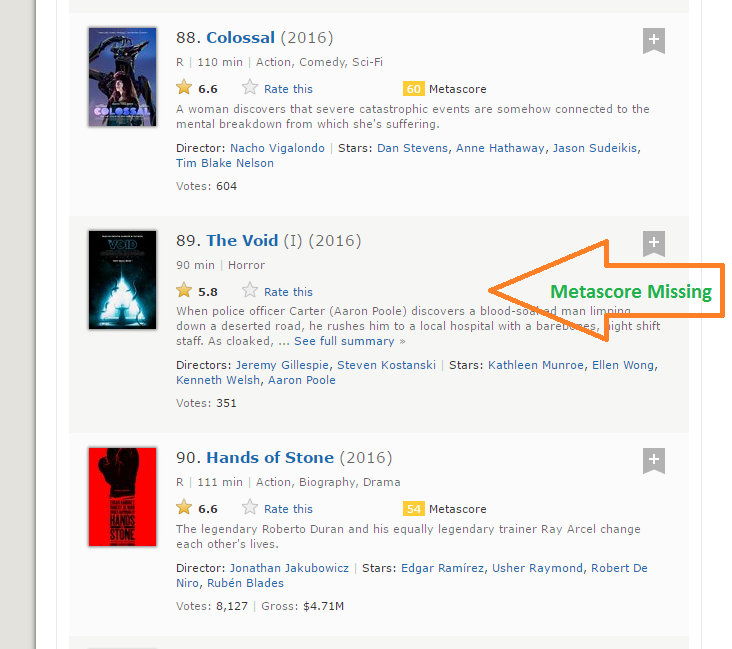
Paso 9: Es una situación práctica que puede surgir al raspar cualquier sitio web. Desafortunadamente, si simplemente agregamos NA a las últimas 4 entradas, se asignará NA como Metascore para las películas 96 a 100, mientras que en realidad, faltan los datos para algunas otras películas. Después de una inspección visual, encontré que faltaba el Metascore para las películas 39, 73, 80 y 89. Escribí la siguiente función para solucionar este problema.
for (i in c(39,73,80,89)){
a<-metascore_data[1:(i-1)]
b<-metascore_data[i:length(metascore_data)]
metascore_data<-append(a,list("NA"))
metascore_data<-append(metascore_data,b)
}
#Data-Preprocessing: converting metascore to numerical
metascore_data<-as.numeric(metascore_data)
#Let's have another look at length of the metascore data
length(metascore_data)
[1] 100
#Let's look at summary statistics
summary(metascore_data)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
23.00 47.00 60.00 60.22 74.00 99.00 4
Paso 10: Lo mismo sucede con la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... Bruto que representa los ingresos brutos de esa película en millones. He usado la misma solución para trabajar a mi manera:
#Using CSS selectors to scrape the gross revenue section
gross_data_html <- html_nodes(webpage,'.ghost~ .text-muted+ span')
#Converting the gross revenue data to text
gross_data <- html_text(gross_data_html)
#Let's have a look at the votes data
head(gross_data)
[1] "$269.36M" "$248.04M" "$27.50M" "$67.12M" "$99.47M" "$153.67M"
#Data-Preprocessing: removing '$' and 'M' signs
gross_data<-gsub("M","",gross_data)
gross_data<-substring(gross_data,2,6)
#Let's check the length of gross data
length(gross_data)
[1] 86
#Filling missing entries with NA
for (i in c(17,39,49,52,57,64,66,73,76,77,80,87,88,89)){
a<-gross_data[1:(i-1)]
b<-gross_data[i:length(gross_data)]
gross_data<-append(a,list("NA"))
gross_data<-append(gross_data,b)
}
#Data-Preprocessing: converting gross to numerical
gross_data<-as.numeric(gross_data)
#Let's have another look at the length of gross data
length(gross_data)
[1] 100
summary(gross_data)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.08 15.52 54.69 96.91 119.50 530.70 14
Paso 11: Ahora hemos eliminado con éxito las 11 funciones de las 100 películas más populares estrenadas en 2016. Combinémoslas para crear un marco de datos e inspeccionar su estructura.
#Combining all the lists to form a data frame movies_df<-data.frame(Rank = rank_data, Title = title_data, Description = description_data, Runtime = runtime_data, Genre = genre_data, Rating = rating_data, Metascore = metascore_data, Votes = votes_data, Gross_Earning_in_Mil = gross_data, Director = directors_data, Actor = actors_data) #Structure of the data frame str(movies_df) 'data.frame': 100 obs. of 11 variables: $ Rank : num 1 2 3 4 5 6 7 8 9 10 ... $ Title : Factor w/ 99 levels "10 Cloverfield Lane",..: 66 53 54 32 58 93 8 43 97 7 ... $ Description : Factor w/ 100 levels "19-year-old Billy Lynn is brought home for a victory tour after a harrowing Iraq battle. Through flashbacks the film shows what"| __truncated__,..: 57 59 3 100 21 33 90 14 13 97 ... $ Runtime : num 108 107 111 139 116 92 115 128 111 116 ... $ Genre : Factor w/ 10 levels "Action","Adventure",..: 3 3 7 4 2 3 1 5 5 7 ... $ Rating : num 7.2 7.7 7.6 8.2 7 6.5 6.1 8.4 6.3 8 ... $ Metascore : num 59 81 99 71 41 56 36 93 39 81 ... $ Votes : num 40603 91333 112609 177229 148467 ... $ Gross_Earning_in_Mil: num 269.3 248 27.5 67.1 99.5 ... $ Director : Factor w/ 98 levels "Andrew Stanton",..: 17 80 9 64 67 95 56 19 49 28 ... $ Actor : Factor w/ 86 levels "Aaron Eckhart",..: 59 7 56 5 42 6 64 71 86 3 ...
Ahora ha raspado con éxito el sitio web de IMDb para los 100 largometrajes más populares lanzados en 2016.
6. Analizar datos extraídos de la Web
Una vez que tenga los datos, puede realizar varias tareas como analizar los datos, hacer inferencias a partir de ellos, entrenar modelos de aprendizaje automático sobre estos datos, etc. Seguí creando una visualización interesante a partir de los datos que acabamos de extraer. Siga las visualizaciones y responda las preguntas que se dan a continuación. Publique sus respuestas en la sección de comentarios a continuación.
library('ggplot2')
qplot(data = movies_df,Runtime,fill = Genre,bins = 30)
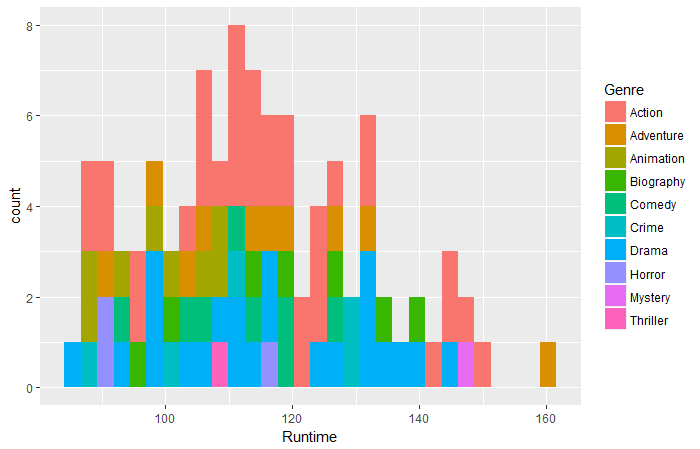
Pregunta 1: Según los datos anteriores, ¿qué película de qué género tuvo el tiempo de ejecución más largo?
ggplot(movies_df,aes(x=Runtime,y=Rating))+ geom_point(aes(size=Votes,col=Genre))
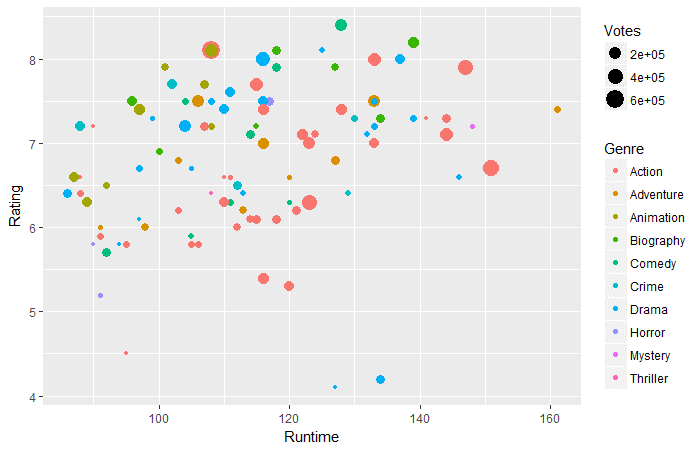
Pregunta 2: Según los datos anteriores, en el tiempo de ejecución de 130-160 minutos, ¿qué género tiene los votos más altos?
ggplot(movies_df,aes(x=Runtime,y=Gross_Earning_in_Mil))+ geom_point(aes(size=Rating,col=Genre))
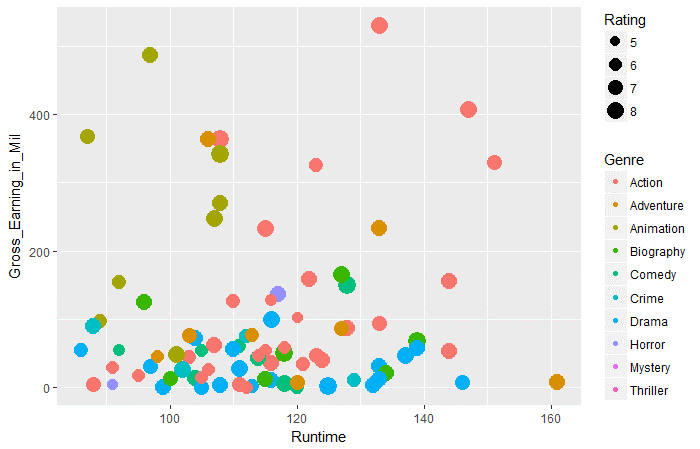
Pregunta 3: Según los datos anteriores, en todos los géneros, qué género tiene las ganancias brutas promedio más altas en tiempo de ejecución de 100 a 120.
Notas finales
Creo que este artículo le habría dado una comprensión completa del web scraping en R. Ahora, también tiene una idea clara de los problemas que podría encontrar y cómo puede solucionarlos. Como la mayoría de los datos en la web están presentes en un formato no estructurado, el web scraping es una habilidad muy útil para cualquier científico de datos.
Además, puede publicar las respuestas a las tres preguntas anteriores en la sección de comentarios a continuación. ¿Disfrutaste leyendo este artículo? Comparta sus opiniones conmigo. Si tiene alguna duda / pregunta, no dude en enviarla a continuación.





