Introducción
¡Los científicos de datos son una raza de animales perezosos! Detestamos la práctica de hacer cualquier trabajo repetible manualmente. Nos encogemos de miedo ante la mera idea de hacer tediosas tareas manuales y cuando nos encontramos con una, intentamos automatizarla para que el mundo se convierta en un lugar mejor.
Hemos estado organizando algunas reuniones en India durante los últimos meses y queríamos ver qué estaban haciendo algunas de las mejores reuniones de todo el mundo. Para un ser humano normal, esto significaría navegar por las páginas de las reuniones y encontrar esta información manualmente.
¡No para un científico de datos!
¿Qué son las reuniones?
Meetup se puede entender mejor como una reunión autoorganizada de personas para lograr un objetivo predefinido. Meetup.com es la red de grupos locales más grande del mundo. La misión de Meetup es «revitalizar la comunidad local y ayudar a las personas de todo el mundo a organizarse por sí mismas».
El proceso de búsqueda de reuniones puede llevar bastante tiempo (prefiero decirlo). Hay múltiples limitaciones adjuntas (que he explicado en la siguiente sección). Pero, ¿cómo realizaría esta tarea un científico de datos para ahorrar tiempo? ¡Por supuesto, se esforzaría por automatizar este proceso!
En este artículo, le presentaré el enfoque de un científico de datos para ubicar grupos de reunión utilizando Python. Tomando esto como referencia, puedes encontrar grupos ubicados en cualquier rincón de la tierra. También puede agregar su propia capa de análisis para descubrir algunas ideas interesantes.
Regístrese en Data Hackathon 3.X: gane un cupón de Amazon por valor de 10.000 rupias (~ 200 dólares)
El desafío con enfoque manual
Digamos que quieres averiguarlo y unirte a algunas de las mejores reuniones en tu área. Obviamente, puede hacer esta tarea manualmente, pero hay algunos desafíos con los que se enfrenta:
- Podría haber varios grupos con nombres y propósitos similares. Se vuelve difícil encontrar los correctos con solo leer los nombres.
- Digamos que está buscando reuniones en ciencia de datos, deberá navegar manualmente a través de cada uno de los grupos, ver varios parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... para juzgar su calidad (por ejemplo, frecuencia de reunión, número de miembros, revisión promedio, etc.) y luego tomar la decisión de unirse al grupo o no, ¡ya me parece mucho trabajo!
- Además, si tiene algún requisito específico, como si desea ver grupos presentes en varias ciudades, terminará navegando por los grupos de cada ciudad manualmente; ya me encojo al pensarlo.
Suponga que se encuentra en una localidad con más de 200 grupos en el área de su interés. ¿Cómo encontrarías las mejores?

La solución del científico de datos
En este artículo, he identificado varios Grupos de Meetup de Python de ciudades de India, EE. UU., Reino Unido, HK, TW y Australia. Los siguientes son los pasos que realizaré:
- Obtener información de meetup.com utilizando la API que han proporcionado.
- Mueva los datos a un DataFrame y
- Analízalo y únete a los grupos adecuados
Estos pasos son bastante fáciles de realizar. A continuación, enumero los pasos para realizarlos. Como se mencionó anteriormente, este es solo el comienzo de las posibilidades que se abren. Puede utilizar esta información para obtener una gran cantidad de conocimientos sobre varias comunidades en todo el mundo.
Paso 0: importar bibliotecas
A continuación se muestra la lista de bibliotecas que he utilizado para codificar este proyecto.
import urllib import json import pandas as pd import matplotlib.pyplot as plt from geopy.geocoders import Nominatim
Aquí hay una descripción general rápida de estas bibliotecas:
- urllib: Este módulo proporciona una interfaz de alto nivel para obtener datos de la World Wide Web.
- json (Notación de objetos de script de Java): la biblioteca jsonJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software... puede analizar JSON a partir de cadenas o archivos. La biblioteca analiza JSON en un diccionario o lista de Python.
- pandas: Se utiliza para operaciones y manipulaciones de datos estructurados. Se utiliza mucho para la preparación y procesamiento de datos.
- matplotlib: Se utiliza para trazar una gran variedad de gráficos, desde histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.... hasta gráficos de líneas y gráficos de calor.
- geocodificadores: Biblioteca de codificación geográfica simple y coherente escrita en Python.
Paso 1: use la API para leer datos en formato JSON
Puede obtener datos de cualquier sitio web de varias formas:
- Rastree las páginas web utilizando una combinación de bibliotecas como BeautifulSoup y Scrapy. Encuentre tendencias subyacentes en html usando expresiones regulares para extraer los datos requeridos.
- Si el sitio web proporciona una API (interfaz de programación de aplicaciones), úsela para obtener los datos. Puede entender esto como un intermediario entre un programador y una aplicación. Este intermediario acepta solicitudes y, si se permite esa solicitud, devuelve los datos.
- Herramientas como import.io también pueden ayudarlo a hacer esto.
Para los sitios web que proporcionan una API, suele ser la mejor forma de obtener la información. El primer método mencionado anteriormente es susceptible a cambios de diseño en una página y, a veces, puede resultar muy complicado. Afortunadamente, Meetup.com ofrece varios API para acceder a los datos requeridos. Usando esta API, podemos acceder a información sobre varios grupos.
Para acceder a la solución automatizada basada en API, necesitaríamos valor para sig_id y sig (diferente para diferentes usuarios). Siga los pasos a continuación para acceder a estos.
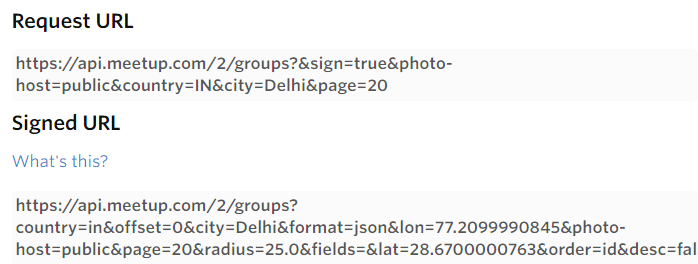
Paso 2: Genere una lista de URL firmadas para todas las ciudades dadas
Ahora, deberíamos solicitar una URL firmada para cada búsqueda (en nuestro caso, ciudad + tema) y la salida de estas URL firmadas proporcionará la información detallada sobre los grupos coincidentes:
- Crea una lista de todas las ciudades
- Crea un objeto para acceder a la longitud y latitud de la ciudad.
- Acceda a la ciudad de la lista dada y genere la latitud y la longitud usando «geolocalizador « objeto
- Genere una cadena de URL con los atributos requeridos como formato de datos (json), radio (número de millas desde el centro de la ciudad, 50), tema (Python), latitud y longitud
- Repita este paso para cada ciudad y agregue todas las URL en una lista
places = [ "san fransisco", "california", "boston ", "new york" , "pennsylvania", "colorado", "seattle", "washington","los angeles", "san diego", "houston", "austin", "kansas", "delhi", "chennai", "bangalore", "mumbai" , "Sydney","Melbourne", "Perth", "Adelaide", "Brisbane", "Launceston", "Newcastle" , "beijing", "shanghai", "Suzhou", "Shenzhen","Guangzhou","Dongguan", "Taipei", "Chengdu", "Hong Kong"] urls = [] #url lists radius = 50.0 #add the radius in miles data_format = "json" topic = "Python" #add your choice of topic here sig_id = "########" # initialize with your sign id, check sample signed key sig = "##############" # initialize with your sign, check sample signed key
for place in places:
location = geolocator.geocode(place)
urls.append("https://api.meetup.com/2/groups?offset=0&format=" + data_format + "&lon=" + str(location.longitude) + "&topic=" + topic + "&photo-host=public&page=500&radius=" + str(radius)+"&fields=&lat=" + str(location.latitude) + "&order=id&desc=false&sig_id=" +sig_id + "&sig=" + sig)
Paso 3: lea los datos de la URL y acceda a las funciones relevantes en un DataFrame
Ahora, tenemos una lista de URL para todas las ciudades. A continuación, usaremos la biblioteca urllib para leer datos en formato JSON. Luego, leeremos los datos en una lista antes de convertirlos en un DataFrame.
city,country,rating,name,members = [],[],[],[],[] for url in urls: response = urllib.urlopen(url) data = json.loads(response.read()) data=data["results"] #accessed data of results key only for i in data : city.append(i['city']) country.append(i['country']) rating.append(i['rating']) name.append(i['name']) members.append(i['members']) df = pd.DataFrame([city,country,rating,name,members]).T df.columns=['city','country','rating','name','members']
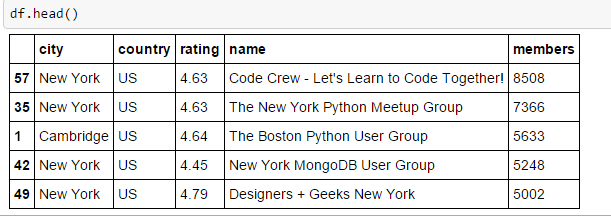
Paso 4: compara los grupos de Meetup en varias ciudades
Es hora de analizar los datos ahora y encontrar los grupos adecuados en función de varias métricas, como el número de miembros, las calificaciones, la ciudad y otros. A continuación se muestran algunos hallazgos básicos, que he generado para grupos de pitones en diferentes ciudades de India, EE. UU., Reino Unido, HK, TW y Australia.
Para saber más sobre estos códigos de Python, puede leer artículos sobre exploración y visualización de datos usando Python
Número de grupos de Python en seis países
freq = df.groupby('country').city.count()
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Country')
ax1.set_ylabel('Count of Groups')
ax1.set_title("Number of Python Meetup Groups")
freq.plot(kind='bar') 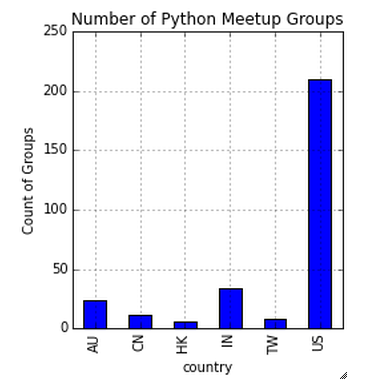 Above you can notice that US is the leader in python meetup groups. This stats can also help us to estimate the penetration of python in US data science industry compare to others.
Above you can notice that US is the leader in python meetup groups. This stats can also help us to estimate the penetration of python in US data science industry compare to others.
Tamaño medio de los grupos en todos los países
freq = df.groupby('country').members.sum()/df.groupby('country').members.count()
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Country')
ax1.set_ylabel('Average Members in each group')
ax1.set_title("Python Meetup Groups")
freq.plot(kind='bar')
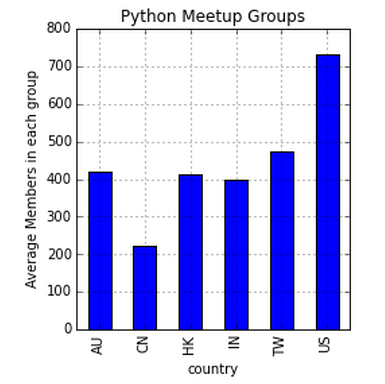
Una vez más, EE. UU. Emerge como líder en número promedio de miembros en cada grupo, mientras que CN tiene el promedio más bajo.
Calificación promedio de grupos en todos los países
freq = df.groupby('country').rating.sum()/df.groupby('country').rating.count()
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Country')
ax1.set_ylabel('Average rating')
ax1.set_title("Python Meetup Groups")
freq.plot(kind='bar')
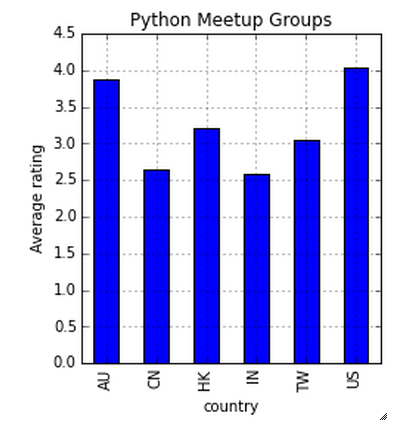 AU y EE. UU. Tienen una calificación promedio similar (~ 4) en todos los grupos.
AU y EE. UU. Tienen una calificación promedio similar (~ 4) en todos los grupos.
Los 2 mejores grupos de cada país
df=df.sort(['country','members'], ascending=[False,False])
df.groupby('country').head(2)
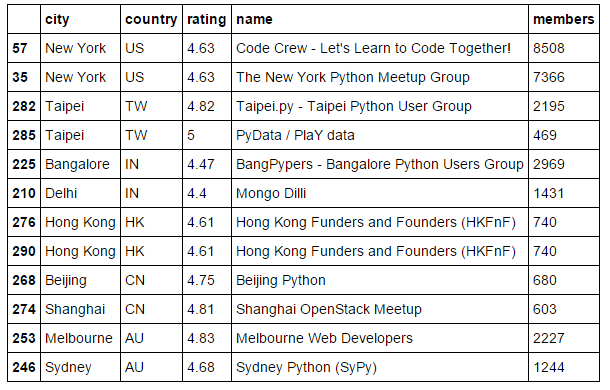
Es hora de identificar los dos grupos principales de cada país en función del número de miembros. También puede identificar los grupos según la calificación. Aquí he realizado un análisis básico para ilustrar este enfoque. Puede acceder a otras API también para encontrar información como próximos eventos, número de eventos, duración de los eventos y otros y luego fusionar toda la información relevante basada en group_id (o valor clave).
Código final
A continuación se muestra el código final de este ejercicio, puede jugar con él colocando su sig_id y sig key y buscar varios resultados de diferentes temas en diferentes ciudades. También lo he subido en GitHub.
import urllib import json import pandas as pd import matplotlib.pyplot as plt from geopy.geocoders import Nominatim
geolocator = Nominatim() #create object
places = [ "san fransisco", "california", "boston ", "new york" , "pennsylvania", "colorado", "seattle", "washington","los angeles", "san diego", "houston", "austin", "kansas", "delhi", "chennai", "bangalore", "mumbai" , "Sydney","Melbourne", "Perth", "Adelaide", "Brisbane", "Launceston", "Newcastle" , "beijing", "shanghai", "Suzhou", "Shenzhen","Guangzhou","Dongguan", "Taipei", "Chengdu", "Hong Kong"]
# login on meetup.com. if you dont have an account, then please signup # Go to https://secure.meetup.com/meetup_api/console/?path=/2/groups # In the topics like "Python", enter topic of your choice. and click on show response # copy the signed key. in the singed key, copy the sig_id and sig and initialise variables sig_id and sig # sample signed key : "https://api.meetup.com/2/groups?offset=0&format=json&topic=python&photo-host=public&page=20&radius=25.0&fields=&order=id&desc=false&sig_id=******&sig=*****************"
urls = [] #url lists radius = 50.0 #add the radius in miles data_format = "json" #you can add another format like XML topic = "Python" #add your choice of topic here
sig_id = "186640998" # initialise with your sign id, check sample signed key sig = "6dba1b76011927d40a45fcbd5147b3363ff2af92" # initialise with your sign, check sample signed key
for place in places:
location = geolocator.geocode(place)
urls.append("https://api.meetup.com/2/groups?offset=0&format=" + data_format + "&lon=" + str(location.longitude) + "&topic=" + topic + "&photo-host=public&page=500&radius=" + str(radius)+"&fields=&lat=" + str(location.latitude) + "&order=id&desc=false&sig_id=" +sig_id + "&sig=" + sig)
city,country,rating,name,members = [],[],[],[],[] for url in urls: response = urllib.urlopen(url) data = json.loads(response.read()) data=data["results"] for i in data : city.append(i['city']) country.append(i['country']) rating.append(i['rating']) name.append(i['name']) members.append(i['members']) df = pd.DataFrame([city,country,rating,name,members]).T df.columns=['city','country','rating','name','members'] df.sort(['members','rating'], ascending=[False, False])
freq = df.groupby('country').city.count()
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Country')
ax1.set_ylabel('Count of Groups')
ax1.set_title("Number of Python Meetup Groups")
freq.plot(kind='bar')
freq = df.groupby('country').members.sum()/df.groupby('country').members.count()
ax1.set_xlabel('Country')
ax1.set_ylabel('Average Members in each group')
ax1.set_title("Python Meetup Groups")
freq.plot(kind='bar')
freq = df.groupby('country').rating.sum()/df.groupby('country').rating.count()
ax1.set_xlabel('Country')
ax1.set_ylabel('Average rating')
ax1.set_title("Python Meetup Groups")
freq.plot(kind='bar')
df=df.sort(['country','members'], ascending=[False,False])
df.groupby('country').head(2)
Notas finales
En este artículo, analizamos la aplicación de Python para automatizar un proceso manual y el nivel de precisión para encontrar los grupos de Meetup adecuados. Usamos API para acceder a información desde la web y la transferimos a un DataFrame. Posteriormente, analizamos esta información para generar conocimientos prácticos.
Podemos hacer que esta aplicación sea más inteligente agregando información adicional como próximos eventos, número de eventos, RSVP y varias otras métricas. También puede utilizar estos datos para obtener información interesante sobre la comunidad y las personas. Por ejemplo, ¿el RSVP a la tasa de asistencia para revisar el embudo de tasa difiere de un país a otro? ¿Qué países planean sus reuniones con más anticipación?
Pruébelo al final y comparta sus conocimientos en la sección de comentarios a continuación.





