Visión general
- Familiarícese con el sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Además, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... de Hadoop (HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información...)
- Comprender los componentes de HDFS
Introducción
En la actualidad, es habitual tratar con cantidades masivas de datos. Desde su próximo mensaje de WhatsApp hasta su próximo Tweet, está creando datos en cada paso cuando interactúa con la tecnología. Ahora multiplique eso por 4.5 mil millones de personas en Internet: ¡las matemáticas son simplemente alucinantes!
Pero, ¿alguna vez se preguntó cómo manejar esos datos? ¿Está almacenado en una sola máquina? ¿Y si falla la máquina? ¿Perderás tus adorables tweets de las 3 AM * tos *?
La respuesta es No. Estoy bastante seguro de que ya estás pensando en Hadoop. Hadoop es un marco asombroso. Con Hadoop a su lado, puede aprovechar los increíbles poderes del Sistema de archivos distribuido de Hadoop (HDFS), el componente de almacenamiento de Hadoop. Probablemente sea el componente más importante de Hadoop y exige una explicación detallada.
Entonces, en este artículo, aprenderemos qué es realmente el Sistema de archivos distribuido de Hadoop (HDFS) y sus diversos componentes. Además, veremos qué hace que HDFS funcione, eso es lo que lo hace tan especial. ¡Vamos a averiguar!
Tabla de contenido
- ¿Qué es el sistema de archivos distribuido de Hadoop (HDFS)?
- ¿Cuáles son los componentes de HDFS?
- ¿Bloques en HDFS?
- NamenodeEl NameNode es un componente fundamental del sistema de archivos distribuido Hadoop (HDFS). Su función principal es gestionar y almacenar la metadata de los archivos, como su ubicación en el clúster y el tamaño. Además, coordina el acceso a los datos y asegura la integridad del sistema. Sin el NameNode, el funcionamiento de HDFS se vería gravemente afectado, ya que actúa como el maestro en la arquitectura del almacenamiento distribuido.... en HDFS
- Nodos de datos en HDFS
- NodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... secundario en HDFS
- Gestión de la replicación
- ReplicaciónLa replicación es un proceso fundamental en biología y ciencia, que se refiere a la duplicación de moléculas, células o información genética. En el contexto del ADN, la replicación asegura que cada célula hija reciba una copia completa del material genético durante la división celular. Este mecanismo es crucial para el crecimiento, desarrollo y mantenimiento de los organismos, así como para la transmisión de características hereditarias en las generaciones futuras.... de bloques
- ¿Qué es un rack en Hadoop?
- Conciencia de rack
¿Qué es el sistema de archivos distribuido de Hadoop (HDFS)?
Es difícil mantener grandes volúmenes de datos en una sola máquina. Por lo tanto, es necesario dividir los datos en fragmentos más pequeños y almacenarlos en varias máquinas.
Los sistemas de archivos que administran el almacenamiento en una red de máquinas se denominan sistemas de archivos distribuidos.
El sistema de archivos distribuido de Hadoop (HDFS) es el componente de almacenamiento de Hadoop. Todos los datos almacenados en Hadoop se almacenan de manera distribuida en un grupo de máquinas. Pero tiene algunas propiedades que definen su existencia.
- Enormes volúmenes – Al ser un sistema de archivos distribuido, es altamente capaz de almacenar petabytes de datos sin ningún problema técnico.
- Acceso a los datos – Se basa en la filosofía de que “el patrón de procesamiento de datos más eficaz es escribir una vez y leer muchas veces”.
- Económico – HDFS se ejecuta en un grupo de hardware básico. Estas son máquinas económicas que se pueden comprar a cualquier proveedor.
¿Cuáles son los componentes del sistema de archivos distribuido de Hadoop (HDFS)?
HDFS tiene dos componentes principales, en términos generales: bloques de datos y nodos que almacenan esos bloques de datos. Pero hay más de lo que parece. Entonces, veamos esto uno por uno para comprenderlo mejor.
Bloques HDFS
HDFS divide un archivo en unidades más pequeñas. Cada una de estas unidades se almacena en diferentes máquinas del clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo..... Sin embargo, esto es transparente para el usuario que trabaja en HDFS. Para ellos, parece almacenar todos los datos en una sola máquina.
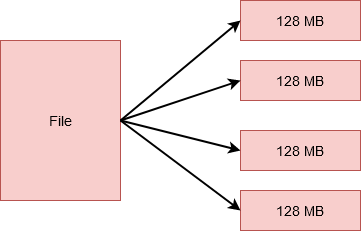
Estas unidades más pequeñas son las bloques en HDFS. El tamaño de cada uno de estos bloques es de 128 MB de forma predeterminada, puede cambiarlo fácilmente según los requisitos. Por lo tanto, si tuviera un archivo de 512 MB, se dividiría en 4 bloques que almacenan 128 MB cada uno.
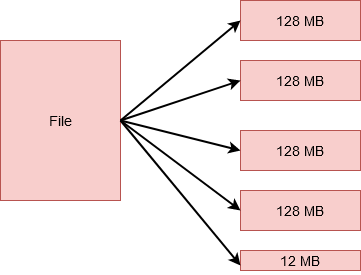
Sin embargo, si tuviera un archivo de 524 MB de tamaño, se dividiría en 5 bloques. 4 de estos almacenarían 128 MB cada uno, lo que equivale a 512 MB. Y el quinto almacenaría los 12 MB restantes. ¡Eso es correcto! Este último bloque no ocupará los 128 MB completos del disco.
Pero, debe preguntarse, ¿por qué una cantidad tan grande en un solo bloque? ¿Por qué no varios bloques de 10 KB cada uno? Bueno, la cantidad de datos con la que generalmente tratamos en Hadoop suele ser del orden de petra bytes o más.
Por tanto, si creamos bloques de pequeño tamaño, acabaríamos con una cantidad colosal de bloques. Esto significaría que tendríamos que lidiar con metadatos igualmente grandes con respecto a la ubicación de los bloques, lo que generaría mucha sobrecarga. ¡Y realmente no queremos eso!
Hay varias ventajas para almacenar datos en bloques en lugar de guardar el archivo completo.
- El archivo en sí sería demasiado grande para almacenarlo en un solo disco. Por lo tanto, es prudente distribuirlo entre diferentes máquinas del clúster.
- También permitiría una distribución adecuada de la carga de trabajo y evitaría el estrangulamiento de una sola máquina al aprovechar el paralelismo.
Ahora, debe preguntarse, ¿qué pasa con las máquinas en el clúster? ¿Cómo almacenan los bloques y dónde se almacenan los metadatos? Vamos a averiguar.
Namenode en HDFS
HDFS opera en una arquitectura maestro-trabajador, esto significa que hay un nodo maestroEl "nodo maestro" es un componente clave en redes de computadoras y sistemas distribuidos. Se encarga de gestionar y coordinar las operaciones de otros nodos, asegurando una comunicación eficiente y el flujo de datos. Su función principal incluye la toma de decisiones, la asignación de recursos y la supervisión del rendimiento del sistema. La correcta implementación de un nodo maestro es fundamental para optimizar el funcionamiento general de la red.... y varios nodos trabajadores en el clúster. El nodo maestro es el Namenode.
Namenode es el nodo principal que se ejecuta en un nodo independiente del clúster.
- Administra el espacio de nombres del sistema de archivos, que es el árbol del sistema de archivos o la jerarquía de los archivos y directorios.
- Almacena información como propietarios de archivos, permisos de archivos, etc. para todos los archivos.
- También conoce la ubicación de todos los bloques de un archivo y su tamaño.
Toda esta información se mantiene de forma persistente en el disco local en forma de dos archivos: Fsimage y Editar registro.
- Fsimage almacena la información sobre los archivos y directorios en el sistema de archivos. Para los archivos, almacena el nivel de replicación, los tiempos de modificación y acceso, los permisos de acceso, los bloques que componen el archivo y sus tamaños. Para los directorios, almacena la hora y los permisos de modificación.
- Editar registro por otro lado, realiza un seguimiento de todas las operaciones de escritura que realiza el cliente. Esto se actualiza periódicamente a los metadatos en memoria para atender las solicitudes de lectura.
Siempre que un cliente desee escribir información en HDFS o leer información de HDFS, se conecta con el Namenode. El Namenode devuelve la ubicación de los bloques al cliente y se lleva a cabo la operación.
Sí, es cierto, el Namenode no almacena los bloques. Para eso, tenemos nodos separados.
Nodos de datos en HDFS
Nodos de datos son los nodos trabajadores. Son hardware básico de bajo costo que se pueden agregar fácilmente al clúster.
Nodos de datos son responsables de almacenar, recuperar, replicar, eliminar, etc. de bloques cuando lo solicite el Namenode.
Periódicamente envían latidos al Namenode para que esté al tanto de su salud. Con eso, un DataNodeDataNode es un componente clave en arquitecturas de big data, utilizado para almacenar y gestionar grandes volúmenes de información. Su función principal es facilitar el acceso y la manipulación de datos distribuidos en clústeres. A través de su diseño escalable, DataNode permite a las organizaciones optimizar el rendimiento, mejorar la eficiencia en el procesamiento de datos y garantizar la disponibilidad de la información en tiempo real.... también envía una lista de bloques que se almacenan en él para que Namenode pueda mantener la asignación de bloques a Datanodes en su memoria.
Pero además de estos dos tipos de nodos en el clúster, también hay otro nodo llamado nodo de nombre secundario. Veamos qué es eso.
Nodo de nombre secundario en HDFS
Suponga que necesitamos reiniciar el Namenode, lo que puede suceder en caso de falla. Esto significaría que tenemos que copiar la Fsimage del disco a la memoria. Además, también tendríamos que copiar la última copia de Edit Log en Fsimage para realizar un seguimiento de todas las transacciones. Pero si reiniciamos el nodo después de mucho tiempo, entonces el registro de edición podría haber aumentado de tamaño. Esto significaría que llevaría mucho tiempo aplicar las transacciones del registro de edición. Y durante este tiempo, el sistema de archivos estaría fuera de línea. Por lo tanto, para resolver este problema, traemos el Nodo de nombre secundario.
Nodo de nombre secundario es otro nodo presente en el clúster cuya tarea principal es fusionar regularmente el registro de edición con Fsimage y producir puntos de control de los metadatos del sistema de archivos en memoria del primario. Esto también se conoce como Checkpointing.

Pero el procedimiento de puntos de control es computacionalmente muy costoso y requiere mucha memoria, razón por la cual el nodo de nombre secundario se ejecuta en un nodo separado del clúster.
Sin embargo, a pesar de su nombre, el Namenode secundario no actúa como un Namenode. Simplemente está ahí para hacer Checkpointing y mantener una copia de la última Fsimage.
Gestión de la replicación en HDFS
Ahora, una de las mejores características de HDFS es la replicación de bloques, lo que lo hace muy confiable. Pero, ¿cómo replica los bloques y dónde los almacena? Respondamos esas preguntas ahora.
Replicación de bloques
HDFS es un componente de almacenamiento confiable de Hadoop. Esto se debe a que cada bloque almacenado en el sistema de archivos se replica en diferentes nodos de datos del clúster. Esto hace que HDFS sea tolerante a errores.
El factor de replicación predeterminado en HDFS es 3. Esto significa que cada bloque tendrá dos copias más, cada una almacenada en DataNodes separados en el clúster. Sin embargo, este número es configurable.
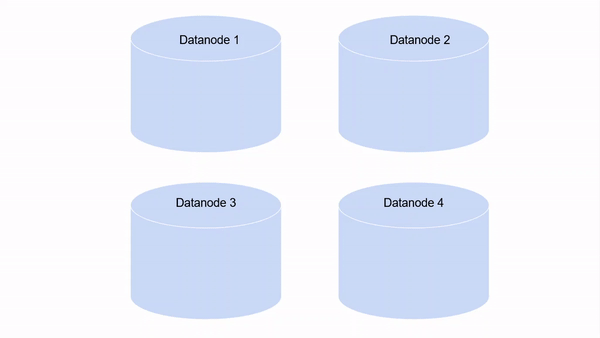
Pero debe estar preguntándose, ¿no significa eso que estamos ocupando demasiado espacio de almacenamiento? Por ejemplo, si tenemos 5 bloques de 128 MB cada uno, eso equivale a 5 * 128 * 3 = 1920 MB. Verdadero. Pero estos nodos son hardware básico. Podemos escalar fácilmente el clúster para agregar más de estas máquinas. ¡El costo de comprar máquinas es mucho menor que el costo de perder los datos!
Ahora, debe preguntarse, ¿cómo decide Namenode en qué Datanode almacenar las réplicas? Bueno, antes de responder esa pregunta, debemos echar un vistazo a lo que es un Rack en Hadoop.
¿Qué es un rack en Hadoop?
A Estante es una colección de máquinas (30-40 en Hadoop) que se almacenan en la misma ubicación física. Hay varios racks en un clúster de Hadoop, todos conectados a través de conmutadores.
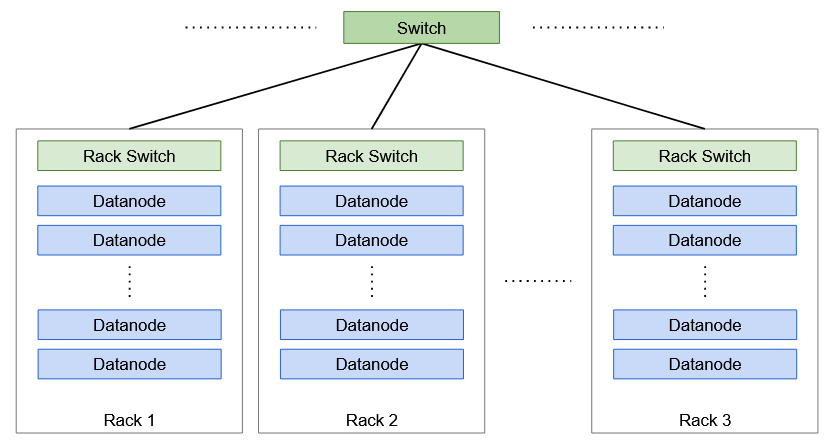
Conciencia de rack
El almacenamiento de réplica es un compromiso entre confiabilidad y ancho de banda de lectura / escritura. Para aumentar la confiabilidad, necesitamos almacenar réplicas de bloques en diferentes racks y Datanodes para aumentar la tolerancia a fallas. Mientras que el ancho de banda de escritura es más bajo cuando las réplicas se almacenan en el mismo nodo. Por lo tanto, Hadoop tiene una estrategia predeterminada para lidiar con este enigma, también conocido como Conciencia de rack algoritmo.
Por ejemplo, si el factor de replicación de un bloque es 3, la primera réplica se almacena en el mismo Datanode en el que escribe el cliente. La segunda réplica se almacena en un Datanode diferente pero en un rack diferente, elegido al azar. Mientras que la tercera réplica se almacena en el mismo rack que la segunda pero en un Datanode diferente, nuevamente elegido al azar. Sin embargo, si el factor de replicación fuera mayor, las siguientes réplicas se almacenarían en nodos de datos aleatorios en el clúster.
Notas finales
Espero que ya tenga un conocimiento sólido de qué es el sistema de archivos distribuido de Hadoop (HDFS), cuáles son sus componentes importantes y cómo almacena los datos. Sin embargo, todavía hay algunos conceptos más que debemos cubrir con respecto al Sistema de archivos distribuido de Hadoop (HDFS), pero esa es una historia para otro artículo.
Por ahora, le recomiendo que lea los siguientes artículos para comprender mejor Hadoop y este mundo de Big Data.
Por último, pero no menos importante, recomiendo leer Hadoop: la guía definitiva de Tom White. Este artículo se inspiró mucho en él.





