Visión general
- Presentamos 21 herramientas de código abierto para el aprendizaje automático con las que quizás no se haya encontrado
- Cada herramienta de código abierto aquí agrega un aspecto diferente al repertorio de un científico de datos
- Nuestro enfoque está principalmente en herramientas para cinco aspectos de aprendizaje automático: para no programadores (Ludwig, Orange, KNIME), implementación de modelos (CoreML, Tensorflow.js), Big Data (Hadoop, Spark), Visión por computador(SimpleCV), PNL(StanfordNLP), audio y aprendizaje reforzado (OpenAI Gym)
Introducción
Me encanta el código abierto aprendizaje automático comunidad. La mayor parte de mi aprendizaje como aspirante y luego como científico de datos establecido provino de recursos y herramientas de código abierto.
Si aún no ha aceptado la belleza de las herramientas de código abierto en el aprendizaje automático, ¡se lo está perdiendo! La comunidad de código abierto es enorme y tiene una actitud de apoyo increíble hacia las nuevas herramientas y la adopción del concepto de democratización del aprendizaje automático.
Ya debe conocer las herramientas populares de código abierto como R, Python, cuadernos de Jupyter, etc. Pero hay un mundo más allá de estas herramientas populares: un lugar donde existen herramientas de aprendizaje automático ocultas. Estos no son tan eminentes como sus contrapartes, pero pueden salvar la vida de muchas tareas de aprendizaje automático.
En este artículo, veremos 21 de estas herramientas de código abierto para aprendizaje automático. Le recomiendo encarecidamente que dedique un tiempo a analizar cada una de las categorías que he mencionado. Hay MUCHO que aprender más allá de lo que normalmente aprendemos en cursos y videos.
Tenga en cuenta que muchas de estas son bibliotecas / herramientas basadas en Python porque seamos sinceros: ¡Python es un lenguaje de programación tan versátil como podríamos obtener!
Hemos dividido las herramientas de aprendizaje automático de código abierto en 5 categorías:
- Herramientas de aprendizaje automático de código abierto para no programadores
- Implementación del modelo de aprendizaje automático
- Herramientas de código abierto de Big Data
- Visión por computadora, PNL y audio
- Aprendizaje reforzado
1. Herramientas de aprendizaje automático de código abierto para no programadores
El aprendizaje automático puede parecer complejo para las personas que no tienen antecedentes técnicos ni de programación. Es un campo vasto y puedo imaginar lo desalentador que puede parecer ese primer paso. ¿Puede una persona sin experiencia en programación tener éxito en el aprendizaje automático?
¡Pues resulta que puedes! Aquí hay algunas herramientas que pueden ayudarlo a cruzar el abismo y entrar en el famoso mundo del aprendizaje automático:
- Uber Ludwig: Ludwig de Uber es una caja de herramientas construida sobre TensorFlow. Ludwig nos permite entrenar y probar modelos de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... sin la necesidad de escribir código. Todo lo que necesita proporcionar es un archivo CSV que contenga sus datos, una lista de columnas para usar como entradas y una lista de columnas para usar como salidas; Ludwig hará el resto. Es muy útil para la experimentación, ya que puede construir modelos complejos con muy poco esfuerzo y en poco tiempo, y puede modificarlo y jugar con él antes de decidir implementarlo en el código.
- KNIME: KNIME le permite crear flujos de trabajo completos de ciencia de datos utilizando una interfaz de arrastrar y soltar. Básicamente, puede implementar todo, desde la ingeniería de funciones hasta la selección de funciones e incluso agregar modelos predictivos de aprendizaje automático a su flujo de trabajo de esta manera. Este enfoque de implementar visualmente todo el flujo de trabajo de su modelo es muy intuitivo y puede ser realmente útil cuando se trabaja en enunciados de problemas complejos.

- Naranja: No es necesario que sepa cómo codificar para poder utilizar Orange para extraer datos, procesar números y obtener información. Puede realizar tareas que van desde la visualización básica hasta la manipulación, transformación y minería de datos. Orange se ha vuelto popular últimamente entre estudiantes y profesores debido a su facilidad de uso y la capacidad de agregar múltiples complementos para complementar su conjunto de funciones.
Hay mucho más software gratuito y de código abierto interesante que proporciona una gran accesibilidad para realizar el aprendizaje automático sin escribir (mucho) código.
En el otro lado de la moneda, hay algunos servicios pagados listos para usar que puede considerar, como Google AutoML, Estudio Azure, Cognición profunda, y Robot de datos.
2. Herramientas de aprendizaje automático de código abierto para la implementación de modelos
La implementación de modelos de aprendizaje automático es una de las tareas más olvidadas pero importantes que debe tener en cuenta. Es casi seguro que surgirá en las entrevistas, por lo que es posible que esté bien versado en el tema.
Aquí hay algunos marcos que pueden facilitar la implementación de ese proyecto favorito en un dispositivo del mundo real.
- MLFlow: MLFlow está diseñado para funcionar con cualquier biblioteca o algoritmo de aprendizaje automático y administrar todo el ciclo de vida, incluida la experimentación, la reproducibilidad y la implementación de modelos de aprendizaje automático. MLFlow se encuentra actualmente en alfa y tiene 3 componentes: seguimiento, proyectos y modelos.

- CoreML de Apple: CoreML es un marco popular que se puede utilizar para integrar modelos de aprendizaje automático en su aplicación iOS / Apple Watch / Apple TV / MacOS. La mejor parte de CoreML es que no requiere un conocimiento extenso sobre redes neuronales o aprendizaje automático. ¡Un ganar-ganar!
- TensorFlow Lite: TensorFlow Lite es un conjunto de herramientas para ayudar a los desarrolladores a ejecutar modelos de TensorFlow en dispositivos móviles (Android e iOS), integrados y de IoT. Está diseñado para facilitar la realización de aprendizaje automático en dispositivos, «en el borde» de la red, en lugar de enviar y recibir datos desde un servidor.
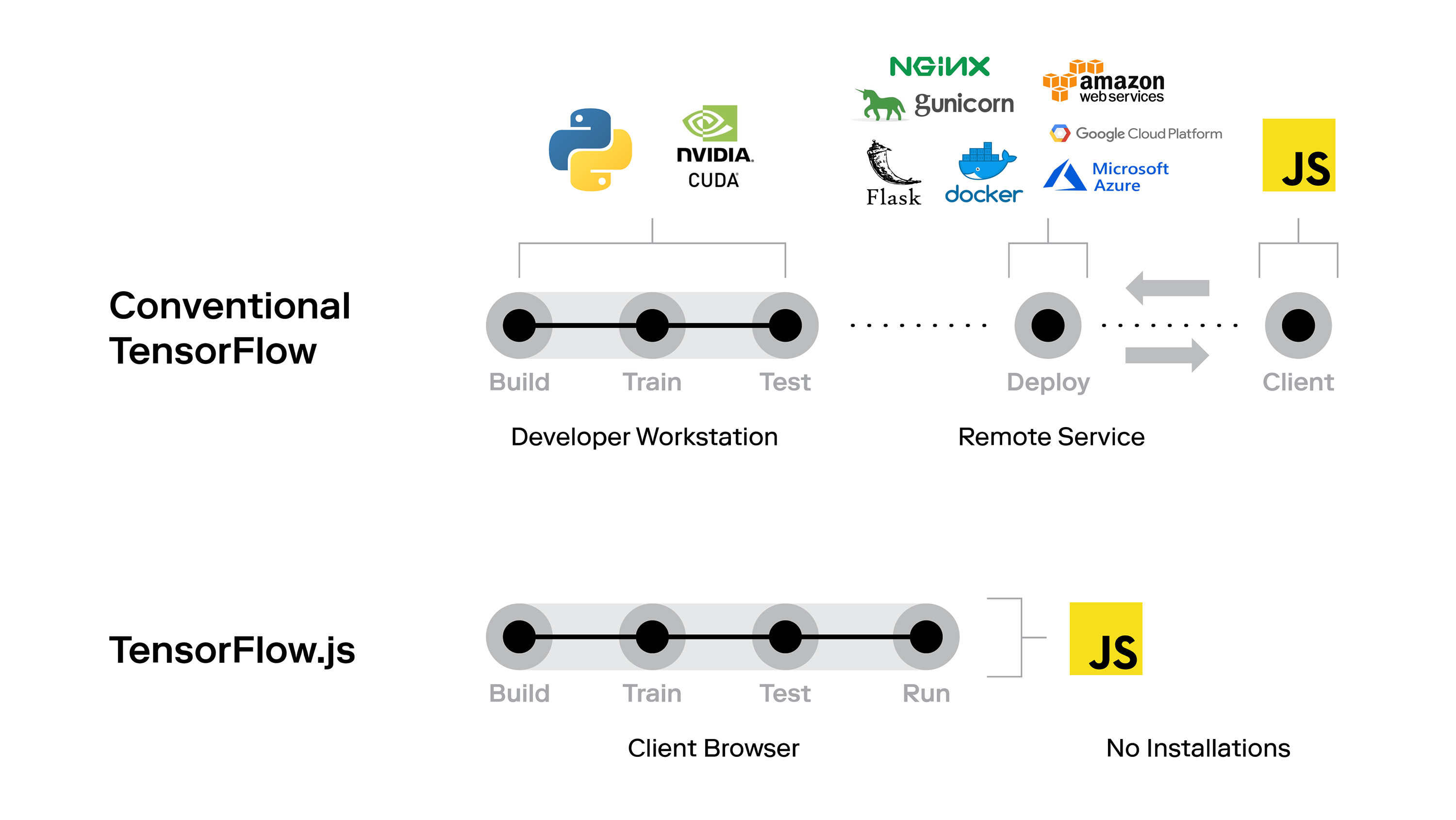
- TensorFlow.js – TensorFlow.js puede ser su opción preferida para implementar su modelo de aprendizaje automático en la Web. Es una biblioteca de código abierto que le permite crear y entrenar modelos de aprendizaje automático en su navegador. Está disponible con aceleración de GPU y también admite automáticamente WebGL. ¡Puede importar modelos pre-entrenados existentes y también volver a entrenar modelos completos de aprendizaje automático existentes en el propio navegador!
3. Herramientas de aprendizaje automático de código abierto para macrodatos
Big Data es un campo que trata las formas de analizar, extraer información de forma sistemática o, de otro modo, tratar con conjuntos de datos que son demasiado grandes o complejos para ser tratados por el software de aplicación de procesamiento de datos tradicional. Imagínese procesar millones de tweets en un día para el análisis de sentimientos. Esto se siente como una tarea enorme, ¿no es así?
¡No te preocupes! A continuación, se incluyen algunas herramientas que pueden ayudarlo a trabajar con Big Data.
- Hadoop: Una de las herramientas más destacadas y relevantes para trabajar con Big Data es el proyecto Hadoop. Hadoop es un marco que permite el procesamiento distribuido de grandes conjuntos de datos en grupos de computadoras utilizando modelos de programación simples. Está diseñado para escalar de servidores únicos a miles de máquinas, cada una de las cuales ofrece computación y almacenamiento locales.
- Chispa – chispear: Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y... se considera un sucesor natural de Hadoop para aplicaciones de big data. El punto clave de esta herramienta de big data de código abierto es que llena los vacíos de Apache Hadoop con respecto al procesamiento de datos. Curiosamente, Spark puede manejar tanto datos por lotes como datos en tiempo real.
- Neo4j: Es posible que Hadoop no sea una buena elección para todos los problemas relacionados con big data. Por ejemplo, cuando necesita lidiar con un gran volumen de datos de red o problemas relacionados con gráficos, como redes sociales o patrones demográficos, una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... de gráficos puede ser la elección perfecta.

4. Herramientas de aprendizaje automático de código abierto para visión artificial, PNL y audio
«Si queremos que las máquinas piensen, debemos enseñarles a ver».
– Dr. Fei-Fei Li sobre visión artificial
- SimpleCV: Debe haber utilizado OpenCV si ha trabajado en algún proyecto de visión por computadora. Pero, ¿te has encontrado alguna vez con SimpleCV? SimpleCV le brinda acceso a varias bibliotecas de visión por computadora de alta potencia, como OpenCV, sin tener que aprender primero sobre profundidades de bits, formatos de archivo, espacios de color, administración de búfer, valores propios o almacenamiento de matriz versus mapa de bits. Esta es la visión por computadora simplificada.

- Tesseract OCR: ¿Ha utilizado aplicaciones creativas que le permiten escanear documentos o facturas de compras usando la cámara de su teléfono inteligente o depositar dinero en su cuenta bancaria simplemente tomando una foto de un cheque? Todas estas aplicaciones utilizan lo que llamamos OCR o software de reconocimiento óptico de caracteres. Tesseract es uno de esos motores de OCR que tiene la capacidad de reconocer más de 100 idiomas fuera de la caja. También se le puede enseñar a reconocer otros idiomas.
- Detectron: Detectron es el sistema de software de Facebook AI Research que implementa algoritmos de detección de objetos de última generación, que incluyen Máscara R-CNN. Está escrito en Python y funciona con Caffe2 marco de aprendizaje profundo.

- StanfordNLP: StanfordNLP es un paquete de análisis de lenguaje natural de Python. ¡La mejor parte de esta biblioteca es que admite más de 70 lenguajes humanos! Contiene herramientas que se pueden utilizar en una canalización para
- Convierta una cadena que contenga texto en lenguaje humano en listas de oraciones y palabras
- Generar formas base de esas palabras, sus partes del discurso y características morfológicas, y
- Dar un análisis de dependencia de estructura sintáctica

- BERT como servicio: Todos los entusiastas de la PNL ya habrán oído hablar de BERT, la arquitectura innovadora de PNL de Google, pero probablemente no se hayan encontrado con este proyecto tan útil. Bert-as-a-service usa BERT como un codificador de oraciones y lo aloja como un servicio a través de ZeroMQ, lo que le permite mapear oraciones en representaciones de longitud fija en solo dos líneas de código.
- Google Magenta: Esta biblioteca proporciona utilidades para manipular datos de origen (principalmente música e imágenes), usar estos datos para entrenar modelos de aprendizaje automático y, finalmente, generar contenido nuevo a partir de estos modelos.
- LibROSA: LibROSA es un paquete de Python para análisis de audio y música. Proporciona los componentes básicos necesarios para crear sistemas de recuperación de información musical. Se utiliza mucho en el preprocesamiento de señales de audio cuando trabajamos en aplicaciones como la conversión de voz a texto con aprendizaje profundo, etc.
Herramientas de código abierto para el aprendizaje por refuerzo
RL es la nueva comidilla de la ciudad cuando se trata de Machine Learning. El objetivo del aprendizaje por refuerzoEl aprendizaje por refuerzo es una técnica de inteligencia artificial que permite a un agente aprender a tomar decisiones mediante la interacción con un entorno. A través de la retroalimentación en forma de recompensas o castigos, el agente optimiza su comportamiento para maximizar las recompensas acumuladas. Este enfoque se utiliza en diversas aplicaciones, desde videojuegos hasta robótica y sistemas de recomendación, destacándose por su capacidad de aprender estrategias complejas.... (RL) es capacitar a agentes inteligentes que puedan interactuar con su entorno y resolver tareas complejas, con aplicaciones del mundo real hacia la robótica, automóviles autónomos y más.
El rápido progreso en este campo se ha visto impulsado por hacer que los agentes jueguen juegos como los icónicos juegos de la consola Atari, el antiguo juego de Go, o videojuegos jugados profesionalmente como Dota 2 o Starcraft 2, todos los cuales brindan entornos desafiantes donde nuevos algoritmos y las ideas se pueden probar rápidamente de forma segura y reproducible. Estos son algunos de los entornos de formación más útiles para RL:
- Fútbol de investigación de Google: Google Research Football Environment es un entorno de RL novedoso en el que los agentes tienen como objetivo dominar el deporte más popular del mundo: el fútbol. Este entorno le brinda una gran cantidad de control para capacitar a sus agentes de RL, mire el video para saber más:
- Gimnasio OpenAI: Gym es un conjunto de herramientas para desarrollar y comparar algoritmos de aprendizaje por refuerzo. Es compatible con la enseñanza de los agentes de todo, desde caminar hasta jugar juegos como Pong o Pinball. En el siguiente gif, verá un agente que está aprendiendo a caminar.

- Agentes de AA de Unity: El kit de herramientas de agentes de aprendizaje automático de Unity (ML-Agents) es un complemento de Unity de código abierto que permite que los juegos y las simulaciones sirvan como entornos para la formación de agentes inteligentes. Los agentes se pueden capacitar mediante el aprendizaje por refuerzo, el aprendizaje por imitación, la neuroevolución u otros métodos de aprendizaje automático a través de una API de Python fácil de usar.

- Proyecto Malmo: La plataforma Malmo es una sofisticada plataforma de experimentación de inteligencia artificial construida sobre Minecraft y diseñada para respaldar la investigación fundamental en inteligencia artificial. Está desarrollado por Microsoft.
Notas finales
Como debe haber sido evidente por el conjunto de herramientas anterior, el código abierto es el camino a seguir cuando consideramos la ciencia de datos y los proyectos relacionados con la inteligencia artificial. Probablemente acabo de raspar la punta del iceberg, pero hay numerosas herramientas disponibles para una variedad de tareas que le facilitan la vida como científico de datos, solo necesita saber dónde buscar.
En este artículo, hemos cubierto 5 áreas interesantes de la ciencia de datos de las que nadie habla mucho sobre ML sin código, implementación de ML, Big data, Vision / NLP / Sound and Reinforcement learning. Personalmente, creo que estas 5 áreas tienen el mayor impacto cuando se tiene en cuenta el valor real de la IA.
¿Cuáles son las herramientas que cree que deberían haber estado en esta lista? ¡Escriba sus favoritos a continuación para que la comunidad los conozca!





