Introducción
Me encanta trabajar con C ++, inclusive después de descubrir el lenguaje de programación Python para el aprendizaje automático. C ++ fue el primer lenguaje de programación que aprendí y estoy encantado de usarlo en el espacio del aprendizaje automático.
Escribí sobre la creación de modelos de aprendizaje automático en mi post anterior y a la comunidad le encantó la idea. Recibí una respuesta abrumadora y una consulta se destacó para mí (de varias personas): ¿hay bibliotecas de C ++ para el aprendizaje automático?
Es una pregunta justa. Los lenguajes como Python y R disponen una gran cantidad de paquetes y bibliotecas que se adaptan a diferentes tareas de aprendizaje automático. Entonces, ¿C ++ tiene alguna oferta de este tipo?

¡Sí, lo hace! Destacaré dos de estas bibliotecas de C ++ en este post, y además las veremos en acción (con código). Si es nuevo en C ++ para el aprendizaje automático, le recomendaré nuevamente que lea el primer post.
Tabla de contenido
- ¿Por qué deberíamos utilizar bibliotecas de aprendizaje automático?
- Bibliotecas de aprendizaje automático en C ++
- Biblioteca SHARK
- Biblioteca MLPACK
¿Por qué deberíamos utilizar bibliotecas de aprendizaje automático?
Esta es una pregunta que tendrán muchos recién llegados. ¿Cuál es la relevancia de las bibliotecas en el aprendizaje automático? Déjame intentar explicarte eso en esta sección.
Digamos que los profesionales experimentados y los veteranos de la industria se han esforzado mucho y han encontrado una solución a un obstáculo. ¿Preferiría utilizar eso o preferiría pasar horas tratando de recrear lo mismo desde cero? Por lo general, no tiene mucho sentido decantarse por el último método, especialmente cuando está trabajando o aprendiendo dentro de los plazos establecidos.
Lo mejor de nuestra comunidad de aprendizaje automático es que ya existen muchas soluciones en forma de bibliotecas y paquetes. Alguien más, desde expertos hasta entusiastas, ya hizo el trabajo duro y reunió la respuesta muy bien empaquetada en una biblioteca.
Estas bibliotecas de aprendizaje automático son eficientes y optimizadas, y se prueban minuciosamente para múltiples casos de uso. Confiar en estas bibliotecas es lo que impulsa nuestro aprendizaje y hace que escribir código, ya sea en C ++ o Python, sea mucho más fácil e intuitivo.
Bibliotecas de aprendizaje automático en C ++
En esta sección, veremos las dos bibliotecas de aprendizaje automático más populares en C +:
- Biblioteca SHARK
- Biblioteca MLPACK
Veamos cada uno individualmente y veamos cómo funciona el código C ++.
1) Biblioteca SHARK C ++
Shark es una biblioteca modular rápida y tiene un soporte abrumador para algoritmos de aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en..., como regresión lineal, redes neuronales, agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo..., k-medias, etc. Además incluye la funcionalidad de álgebra lineal y optimización numérica. Estas son funciones o áreas matemáticas clave que son muy importantes al realizar tareas de aprendizaje automático.
Primero veremos cómo instalar Shark y configurar un entorno. Después, implementaremos la regresión lineal con Shark.
Instale Shark y configure el entorno (haré esto para Linux)
- Shark confía en Boost y cmake. Por suerte, todas las dependencias se pueden instalar con el siguiente comando:
sudo apt-get install cmake cmake-curses-gui libatlas-base-dev libboost-all-dev
- Para instalar Shark, ejecute los siguientes comandos línea por línea en su terminal:
- clon de git https://github.com/Shark-ML/Shark.git (además puede descargar el archivo zip y extraerlo)
- cd tiburón
- compilación de mkdir
- construcción de cd
- cmake ..
- hacer
Si no ha visto esto antes, eso no es un obstáculo. Es bastante sencillo y hay mucha información en línea si se mete en problemas. Para Windows y otros sistemas operativos, puede hacer una búsqueda rápida en el buscador de Google acerca de cómo instalar Shark. Aquí está el sitio de referencia Guía de instalación de tiburones.
Compilar programas con Shark
Implementación de regresión lineal con Shark
Mi primer post de esta serie tenía una introducción a la regresión lineal. Usaré la misma idea en este post, pero esta vez usando la biblioteca Shark C ++.
Etapa de inicialización
Comenzaremos por incluir las bibliotecas y las funciones de encabezado para la regresión lineal:
Después viene el conjunto de datos. He creado dos archivos CSV. El archivo input.csv contiene los valores xy el archivo labels.csv contiene los valores y. A continuación se muestra una instantánea de los datos:
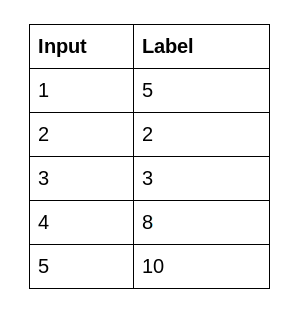
Puede hallar ambos archivos aquí: Aprendizaje automático con C ++. Primero, crearemos contenedores de datos para guardar los valores de los archivos CSV:
A continuación, necesitamos importarlos. Shark viene con una buena función de importación CSV, y especificamos el contenedor de datos que queremos inicializar, y además la ubicación del archivo de ruta del CSV:
Después, necesitamos crear una instancia de un tipo de conjunto de datos de regresión. Ahora, esto es solo un objeto general para la regresión, y lo que haremos en el constructor es pasar nuestras entradas y además nuestras etiquetas para los datos.
A continuación, necesitamos entrenar el modelo de regresión lineal. ¿Como hacemos eso? Necesitamos crear una instancia de un entrenador y establecer un modelo lineal:
Etapa de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina....
Después viene el paso clave donde verdaderamente entrenamos el modelo. Aquí, el entrenador dispone de una función miembro llamada tren. Entonces, esta función entrena este modelo y encuentra los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... para el modelo, que es exactamente lo que queremos hacer.
Etapa de predicción
En conclusión, generemos los parámetros del modelo:
Los modelos lineales disponen una función miembro llamada compensar que genera la intersección de la línea de mejor ajuste. A continuación, generamos una matriz en lugar de un multiplicador. Esto se debe a que el modelo se puede generalizar (no solo lineal, podría ser un polinomio).
Calculamos la línea de mejor ajuste minimizando los mínimos cuadrados, dicho de otra forma, minimizando la pérdida al cuadrado.
Entonces, por suerte, el modelo nos posibilita generar esa información. La biblioteca Shark es muy útil para dar una indicación de qué tan bien se ajustan los modelos:
Primero, necesitamos inicializar un objeto de pérdida al cuadrado, y después necesitamos crear una instancia de un contenedor de datos. Después, el pronóstico se calcula en función de las entradas al sistema, y después todo lo que haremos es generar la pérdida, que se calcula pasando las etiquetas y además el valor de predicción.
En conclusión, necesitamos compilar. En la terminal, escriba el siguiente comando (asegúrese de que el directorio esté configurado correctamente):
g++ -o lr linear_regression.cpp -std=c++11 -lboost_serialization -lshark -lcblas
Una vez compilado, habría creado un lr objeto. Ahora simplemente ejecute el programa. La salida que obtenemos es:
B : [1](-0,749091)
A :[1,1]((2.00731))
Pérdida: 7.83109
El valor de b está un poco lejos de 0, pero eso se debe al ruido en las etiquetas. El valor del multiplicador está cerca de 2, lo que es bastante equivalente a los datos. ¡Y así es como puede utilizar la biblioteca Shark en C ++ para construir un modelo de regresión lineal!
2) Biblioteca MLPACK C ++
mlpack es una biblioteca de aprendizaje automático rápida y flexible escrita en C ++. Su objetivo es proporcionar implementaciones rápidas y extensibles de algoritmos de aprendizaje automático de vanguardia. mlpack proporciona estos algoritmos como programas simples de línea de comandos, links de Python, links de Julia y clases de C ++ que después se pueden integrar en soluciones de aprendizaje automático a mayor escala.
Primero veremos cómo instalar mlpack y el entorno de configuración. Después implementaremos el algoritmo k-means usando mlpack.
Instale mlpack y el entorno de configuración (haré esto para Linux)
mlpack depende de las siguientes bibliotecas que deben instalarse en el sistema y disponen encabezados presentes:
- Armadillo> = 8.400.0 (con soporte LAPACK)
- Impulsar (math_c99, program_options, serialization, unit_test_framework, heap, spirit)> = 1.49
- ensmallen> = 2.10.0
En Ubuntu y Debian, puede obtener todas estas dependencias por medio de apto:
sudo apt-get install libboost-math-dev libboost-program-options-dev libboost-test-dev libboost-serialization-dev binutils-dev python-pandas python-numpy cython python-setuptools
Ahora que todas las dependencias están instaladas en su sistema, puede ejecutar de forma directa los siguientes comandos para compilar e instalar mlpack:
- wget
- tar -xvzpf mlpack-3.2.2.tar.gz
- mkdir mlpack-3.2.2 / compilar && cd mlpack-3.2.2 / construir
- cmake ../
- make -j4 # El -j es la cantidad de núcleos que desea utilizar para una compilación
- sudo make install
En muchos sistemas Linux, mlpack se instalará de forma predeterminada para / usr / local / lib y es factible que deba configurar la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de entorno LD_LIBRARY_PATH:
export LD_LIBRARY_PATH=/usr/local/lib
Las instrucciones anteriores son la forma más sencilla de obtener, compilar e instalar mlpack. Si su distribución de Linux admite binarios, siga este sitio para instalar mlpack usando un comando de una línea dependiendo de su distribución: Instrucciones de instalación de MLPACK. El método anterior funciona para todas las distribuciones.
Compilar programas con mlpack
- Incluya los archivos de encabezado relevantes en su programa (asumiendo la implementación de k-means):
-
- #include
- #include
- #include
- Para compilar necesitamos vincular las siguientes bibliotecas:
-
- std = c ++ 11 -larmadillo -lmlpack -lboost_serialization
Implementando K-Means con mlpack
K-means es un algoritmo basado en centroides, o un algoritmo basado en distancias, donde calculamos las distancias para adjudicar un punto a un grupo. En K-Means, cada grupo está relacionado con un centroide.
El objetivo principal del algoritmo K-Means es minimizar la suma de distancias entre los puntos y su respectivo centroide de clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.....
K-means es efectivamente un procedimiento iterativo en el que queremos segmentar los datos en ciertos grupos. Primero, asignamos algunos centroides iniciales, por lo que estos pueden ser absolutamente aleatorios. A continuación, para cada punto de datos, encontramos el centroide más cercano. Después asignaremos ese punto de datos a ese centroide. Entonces, cada centroide representa una clase. Y una vez que asignamos todos los puntos de datos a cada centroide, calcularemos la media de esos centroides.
Para una comprensión detallada del algoritmo de K-medias, lea este tutorial: La guía más completa para la agrupación de K-medias que necesitará.
Aquí, implementaremos k-means usando la biblioteca mlpack en C ++.
Etapa de inicialización
Comenzaremos por incluir las bibliotecas y las funciones de encabezado para k-means:
A continuación, crearemos algunas variables básicas para determinar el número de clústeres, la dimensionalidad del programa, el número de muestras y la cantidad máxima de iteraciones que queremos hacer. ¿Por qué? Debido a que K-means es un procedimiento iterativo.
A continuación, crearemos los datos. Por lo tanto aquí es donde vamos a usar por primera vez el Armadillo Biblioteca. Crearemos una clase de mapa que es efectivamente un contenedor de datos:
¡Ahí tienes! Esta clase mat, los datos del objeto que tiene, le hemos dado una dimensionalidad de dos, y sabe que va a tener 50 muestras, y ha inicializado todos estos valores de datos para que sean 0.
A continuación, asignaremos algunos datos aleatorios a esta clase de datos y después ejecutaremos K-means de manera efectiva. Voy a crear 25 puntos alrededor de la posición 1 1, y podemos hacer esto diciendo efectivamente que cada punto de datos es 1 1 o en la posición X es igual a 1, y es igual a 1. Después, agregaremos algo de ruido aleatorio. para cada uno de los 25 puntos de datos. Veamos esto en acción:
Aquí, para i de 0 a 25, la i-ésima columna debe ser este vector de tipo arma en la posición 11, y después agregaremos una cierta cantidad de ruido aleatorio de tamaño 2. Entonces, será un El vector de ruido aleatorio bidimensional multiplicado por 0,25 hasta esta posición, y esa será nuestra columna de datos. Y después haremos exactamente lo mismo para el punto x es igual a 2 e y es igual a 3.
¡Y nuestros datos ya están listos! Es hora de pasar a la etapa de entrenamiento.
Etapa de entrenamiento
Entonces, primero, creemos una instancia de un tipo de fila arma mat para contener los grupos, y después instanciamos una arma mat para contener los centroides:
Ahora, necesitamos crear una instancia de la clase K-means:
Hemos creado una instancia de la clase K-means y hemos especificado la cantidad máxima de iteraciones que pasamos al constructor. Por lo tanto ahora podemos seguir adelante y agrupar.
Llamaremos a la función de miembro Cluster de esta clase K-means. Necesitamos pasar los datos, el número de clústeres, y después además necesitamos pasar el objeto del clúster y el objeto del centroide.
Ahora, esta función de clúster ejecutará K-means en estos datos con un número específico de clústeres, y después inicializará estos dos objetos: clústeres y centroides.
Generando resultados
Simplemente podemos mostrar los resultados usando el centroids.print función. Esto le dará la ubicación de los centroides:
A continuación, necesitamos compilar. En la terminal, escriba el siguiente comando (nuevamente, asegúrese de que el directorio esté configurado correctamente):
g++ k_means.cpp -o kmeans_test -O3 -std=c++11 -larmadillo -lmlpack -lboost_serialization && ./kmeans_test
Una vez compilado, habría creado un objeto kmeans. Ahora simplemente ejecute el programa. La salida que obtenemos es:
Centroides:
0,9497 1,9625
0,9689 3,0652
¡Y eso es!
Notas finales
En este post, vimos dos bibliotecas de aprendizaje automático populares que nos ayudan a poner en práctica modelos de aprendizaje automático en c ++. Me encanta el amplio soporte disponible en la documentación oficial, por lo tanto compruébalo. Si necesita ayuda, comuníquese conmigo a continuación y estaré feliz de comunicarme con usted.
En el próximo post, implementaremos algunos modelos interesantes de aprendizaje automático como árboles de decisión y bosque aleatorio. ¡Por lo tanto estad atentos!





