Introducción
El aprendizaje automático no es más que construir una ‘máquina’ que ‘aprende’ de su experiencia. Y mejora con la experiencia, al igual que los humanos. También aprendemos de nuestras experiencias. Derecha ? Empresas como Google, Facebook, Microsoft están utilizando técnicas de aprendizaje automático a mayor escala.
Sin embargo, un error común que tienen las personas es que necesitan aprender a codificar para iniciar el aprendizaje automático. Si bien la codificación se vuelve necesaria para cualquiera que esté haciendo aprendizaje automático en serio, pero no para iniciarlo. Puede mirar una herramienta impulsada por GUI como Weka o incluso Excel para comenzar con el aprendizaje automático.
Aquí, le presentaré una forma más sencilla de comenzar con el aprendizaje automático.

¿Le resulta difícil entender la codificación?
El aprendizaje automático requiere poderosas habilidades de codificación / algoritmos. Y es por eso que a las personas con un título en ciencias de la computación les resulta relativamente más fácil tener éxito en el dominio del aprendizaje automático.
Pero el escenario ha cambiado. Sin embargo, no puede escapar de la codificación por completo, aún puede comenzar con el aprendizaje automático. Una vez que comiences, podrás mejorar tus habilidades de codificación.
La buena noticia es que ahora puedes empezar aprendizaje automático utilizando Microsoft Excel. ¡Sí! lo escuchaste bien.
Frontline Solvers ha introducido ‘MINERÍA DE DATOS XLMINER‘complemento para MS Excel. Es una herramienta fácil de usar, hecha para profesionales, para visualización de datos, pronóstico y minería de datos. Le resultará fácil de usar si:
- Ha trabajado en MS Excel en el pasado
- Tiene experiencia laboral con SPSS
Lea también: Trucos simples pero poderosos para analizar datos en Excel
¿Cuáles son las tareas que puede realizar XLMiner?
Sabía que esto vendría. ¡Bien! XLMiner puede hacer muchas cosas que usted hace en R, Python o Julia. Eso también, sin escribir un fragmento de código. Ofrece una gran oferta en tareas de aprendizaje automático y minería de datos. XLMiner es compatible con Excel 2007, Excel 2010 y Excel 2013 (32 y 64 bits). Aquí está la lista de tareas que se pueden realizar con XLMiner:
- Exploración y visualización de datos
- Ingeniería de funciones
- Extracción de textos
- Análisis de series temporales
- Aprendizaje automático
- Regresión
- Clasificación
- Agrupación
- Modelado de conjuntos
- Redes neuronales
Nota: no está disponible de forma gratuita. Puede descargarlo en un período de prueba de 15 días y luego comprar una licencia de dos años por $ 2495.
En este artículo, demostraré los pasos para realizar regresión, clasificación y agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo... en Excel. Te recomiendo que trabajes en pequeños conjuntos de datos en Excel, ya que podría fallar. Es bueno usarlo en conjuntos de datos como Titánico.
Para obtener lo mejor de este artículo, debe tener / adquirir conocimientos básicos de estos algoritmos. Si necesita un repaso rápido sobre el aprendizaje automático, le recomiendo que consulte estos tutoriales: Conceptos básicos de los algoritmos de aprendizaje automático
He instalado XLMiner. Después de la instalación, notará que XLMINER aparece en las pestañas principales (imagen a continuación). También puedes ver esto visión de conjunto de la plataforma XLMiner.
Empecemos !
Tutorial: regresión lineal múltiple
La regresión no es gran cosa. También puede realizarlo usando el complemento ‘paquete de herramientas de análisis de datos‘disponible en Excel. Es bueno para el análisis estadístico. Para el aprendizaje automático, necesitaría XLMiner. Aquí he demostrado la regresión múltiple usando XLMiner. Para la regresión lineal, todos los pasos siguen siendo los mismos, excepto que selecciona una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... independiente para el modelado. Los siguientes son los pasos:
1. He utilizado el conjunto de datos de vivienda de Boston. Estos datos representan los precios de la vivienda en Boston basados en varios factores que influyen. Puede cargar el conjunto de datos usando: Ayuda -> Ejemplos -> Boston Housing.
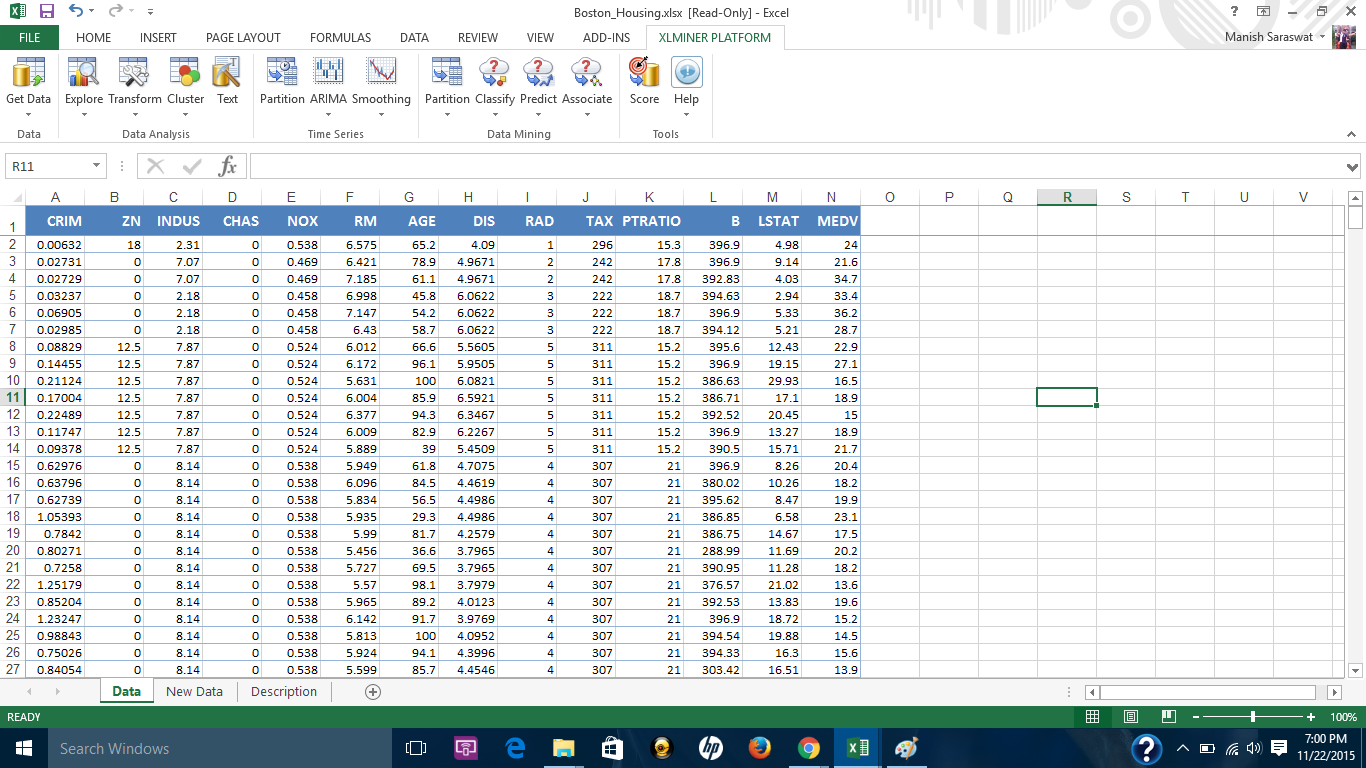
2. Aquí está el conjunto de datos.
3. No hay valores perdidos en este conjunto de datos. Sin embargo, este complemento proporciona una opción conveniente para hacer frente a los valores perdidos. Puede acceder a esta opción desde aquí.
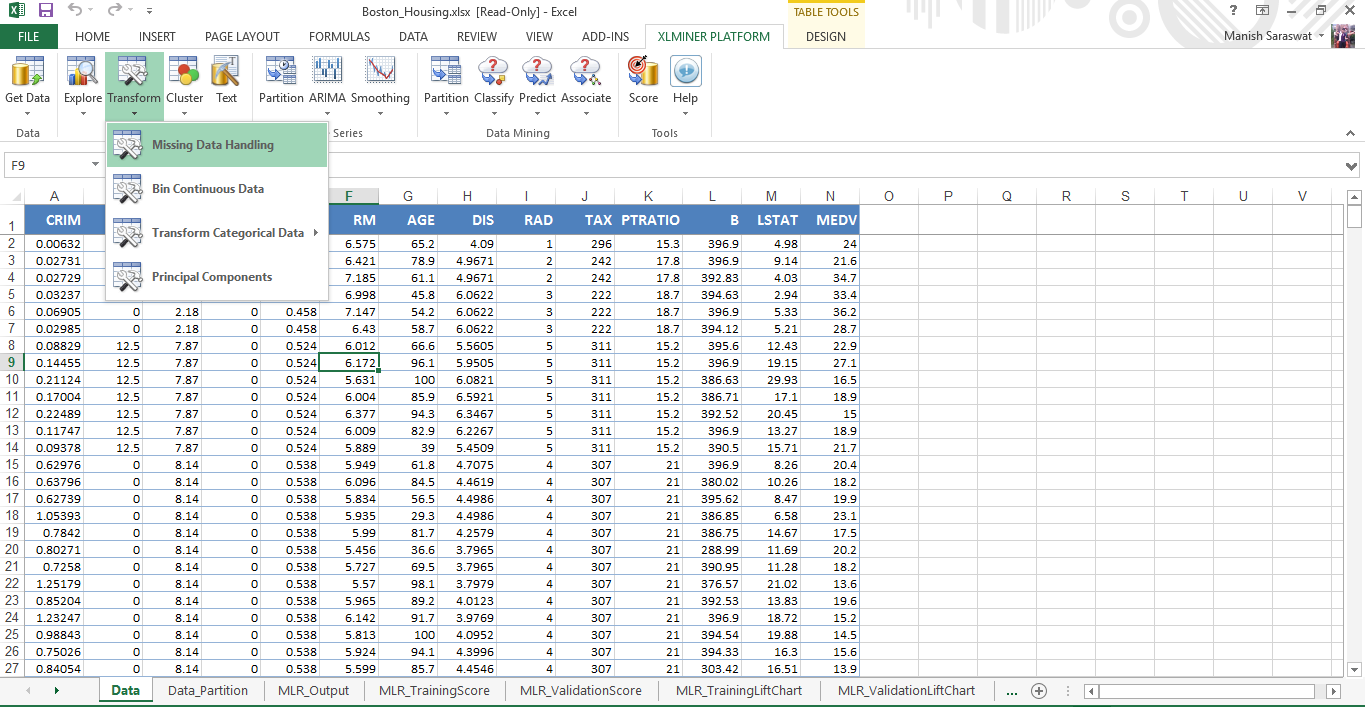
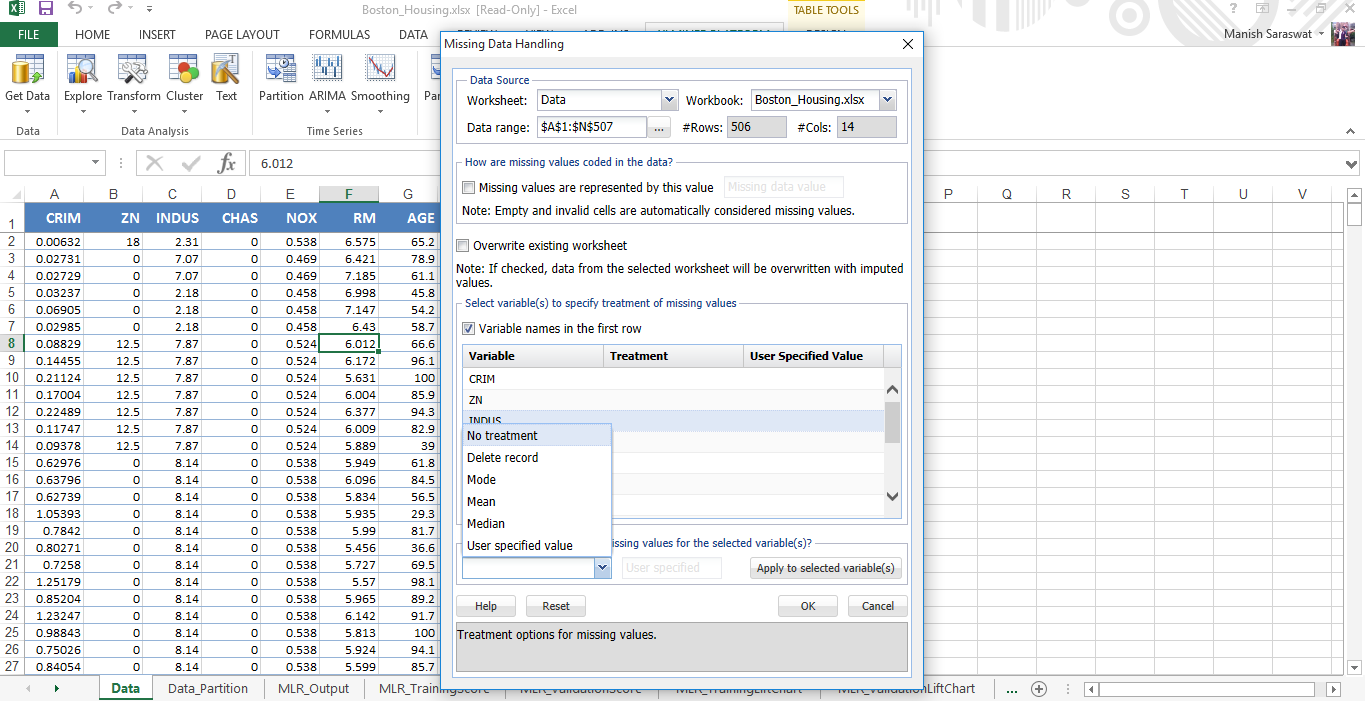
Simplemente, seleccione las variables donde encuentre los valores faltantes. Si los valores faltantes están representados por ‘nulo’, ‘N / A’ o en cualquier otra forma, menciónelo. Finalmente, puede elegir el método de tratamiento y listo.
4. Ahora haremos la selección de funciones. MEDV es la variable de respuesta. MEDV representa el valor medio de las viviendas ocupadas por el propietario en $ 1000.
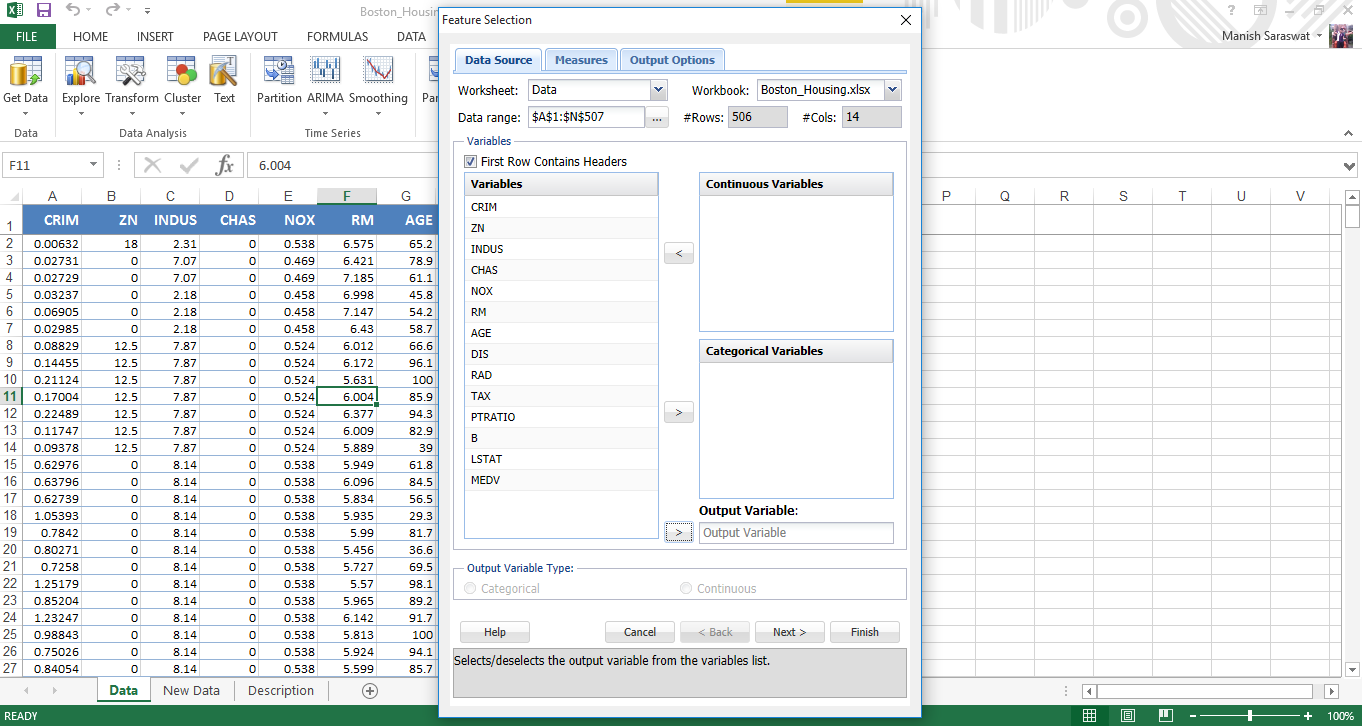
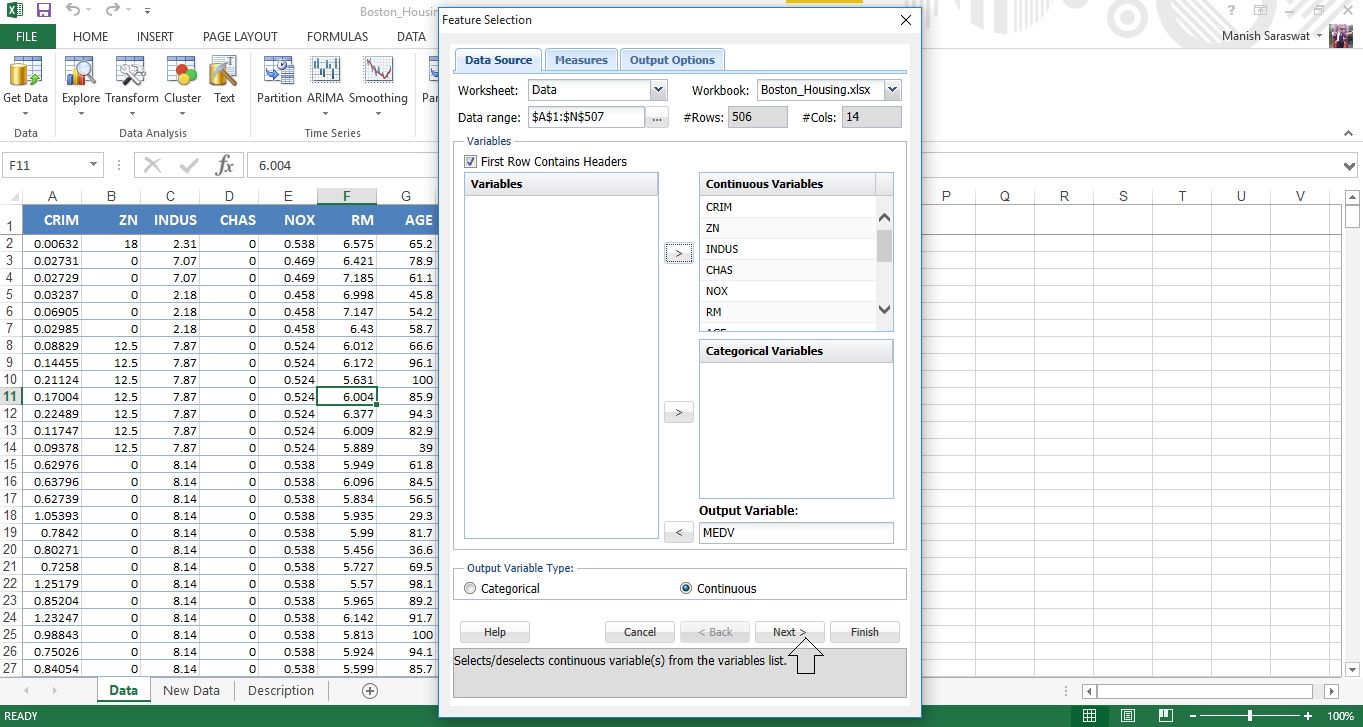
5. Utilice Mayús + clic para seleccionar todas las variables independientes a la vez. Envíe MEDV a la variable de salida. Haga clic en Siguiente.
6. Seleccione filtros de correlación. He seleccionado los tres. Haga clic en Siguiente
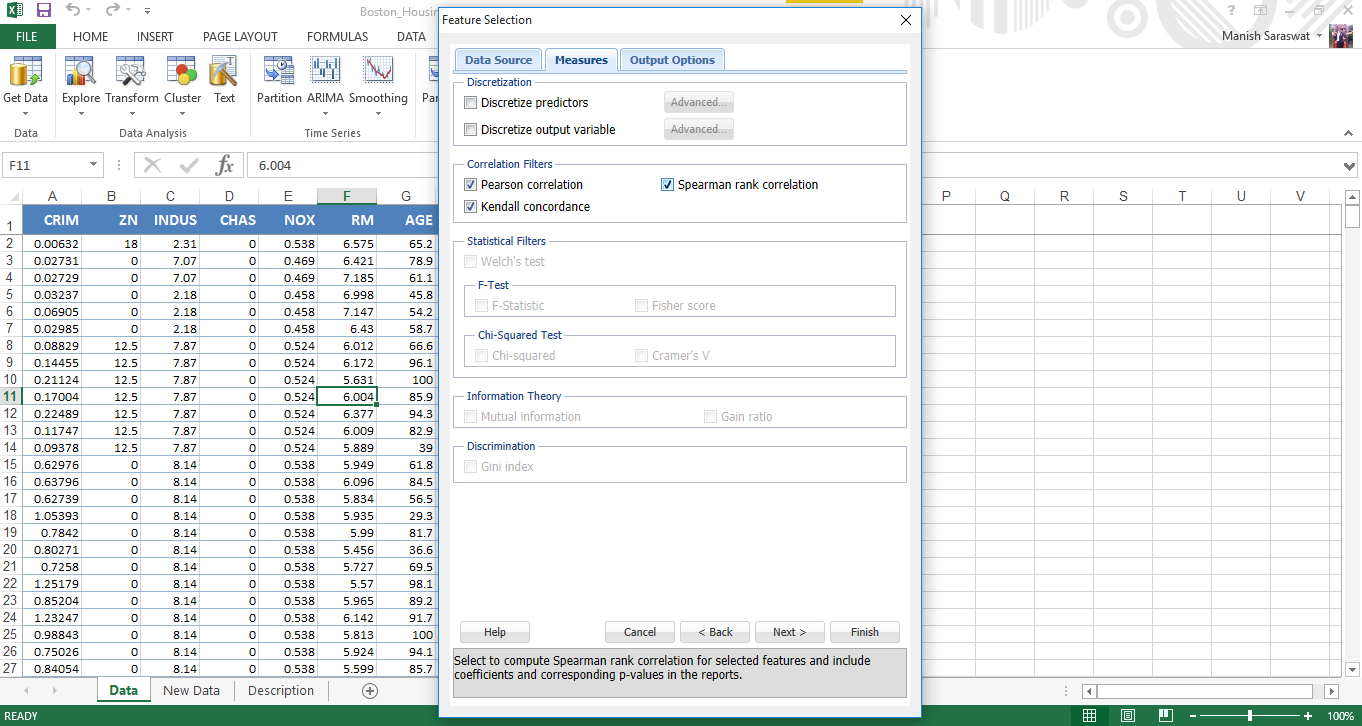
7. Ahora seleccione las funciones. Averigüemos las 5 principales variables predictoras importantes. Haga clic en Finalizar.
8. Aquí está el cuadro de importancia variable. Vemos, LSTAT es la variable más importante, seguida de RM, PTRATIO, INDUS e TAX.
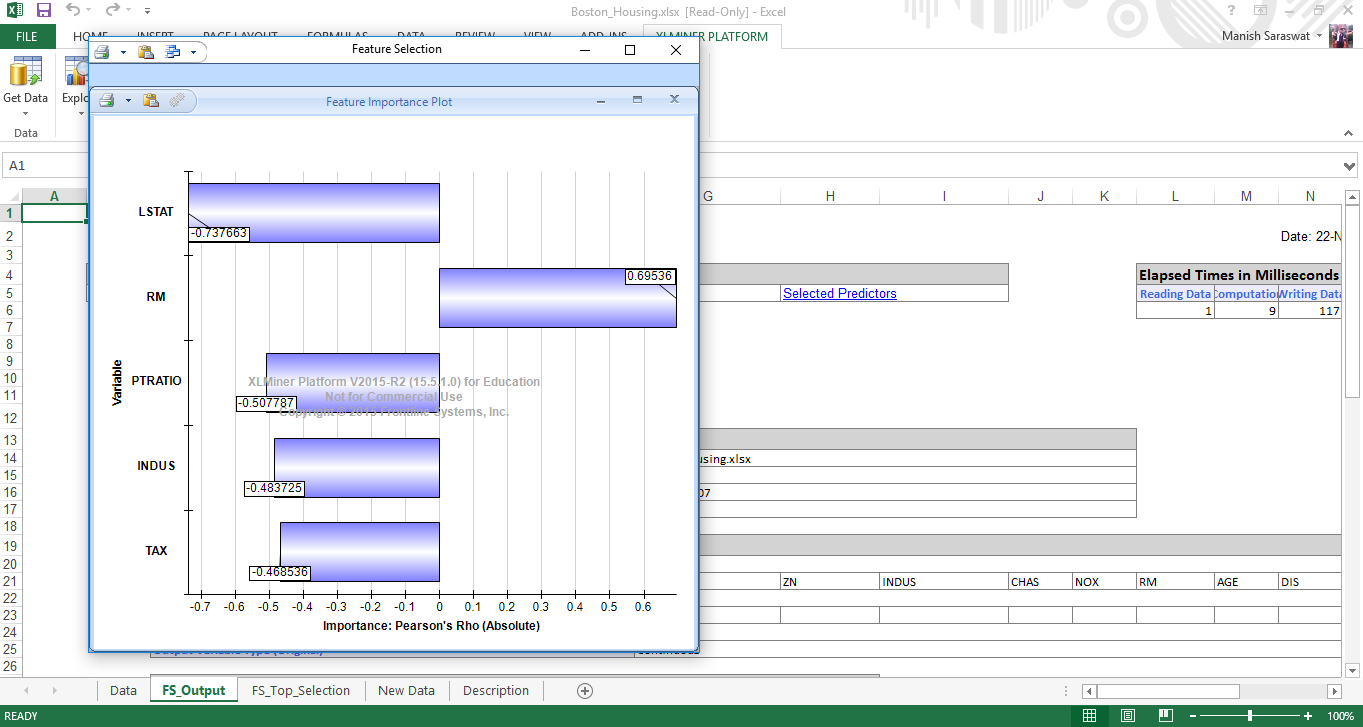
9. Cierre este gráfico. Verá Output Navigator. Esto le ayuda a navegar entre varias hojas de salida. Echemos un vistazo a los ‘predictores seleccionados’.
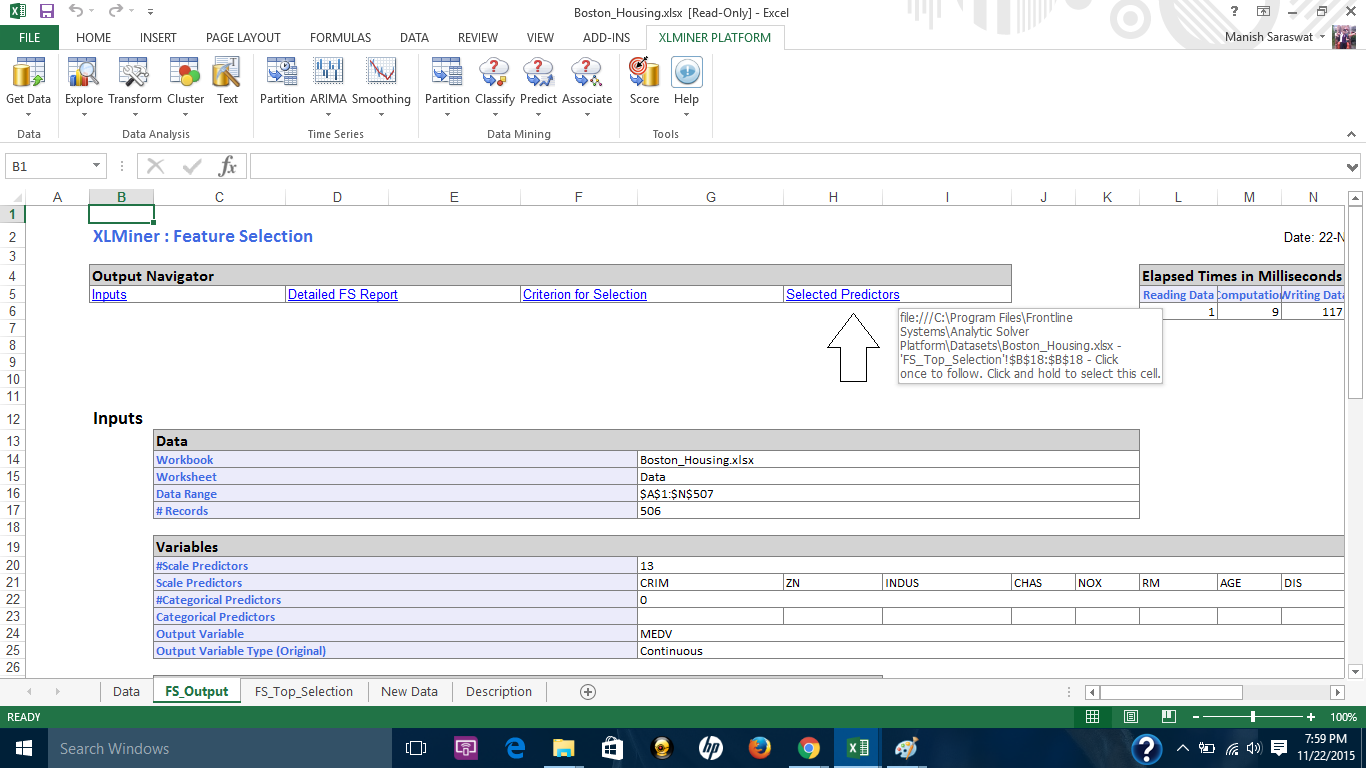
10. Aquí están los predictores seleccionados. Procedamos a construir un modelo de regresión usando estas variables.
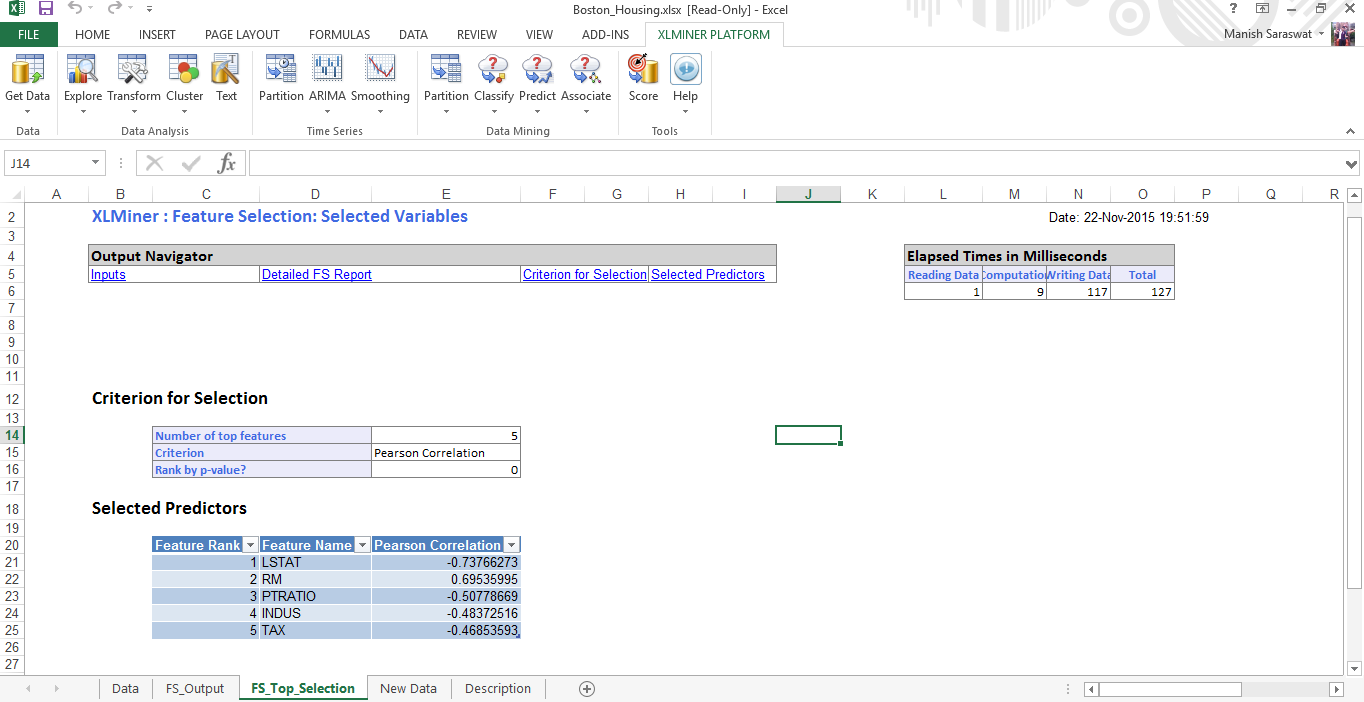
11. Antes de modelar, dividamos (particionemos) estos datos en tren y validación.
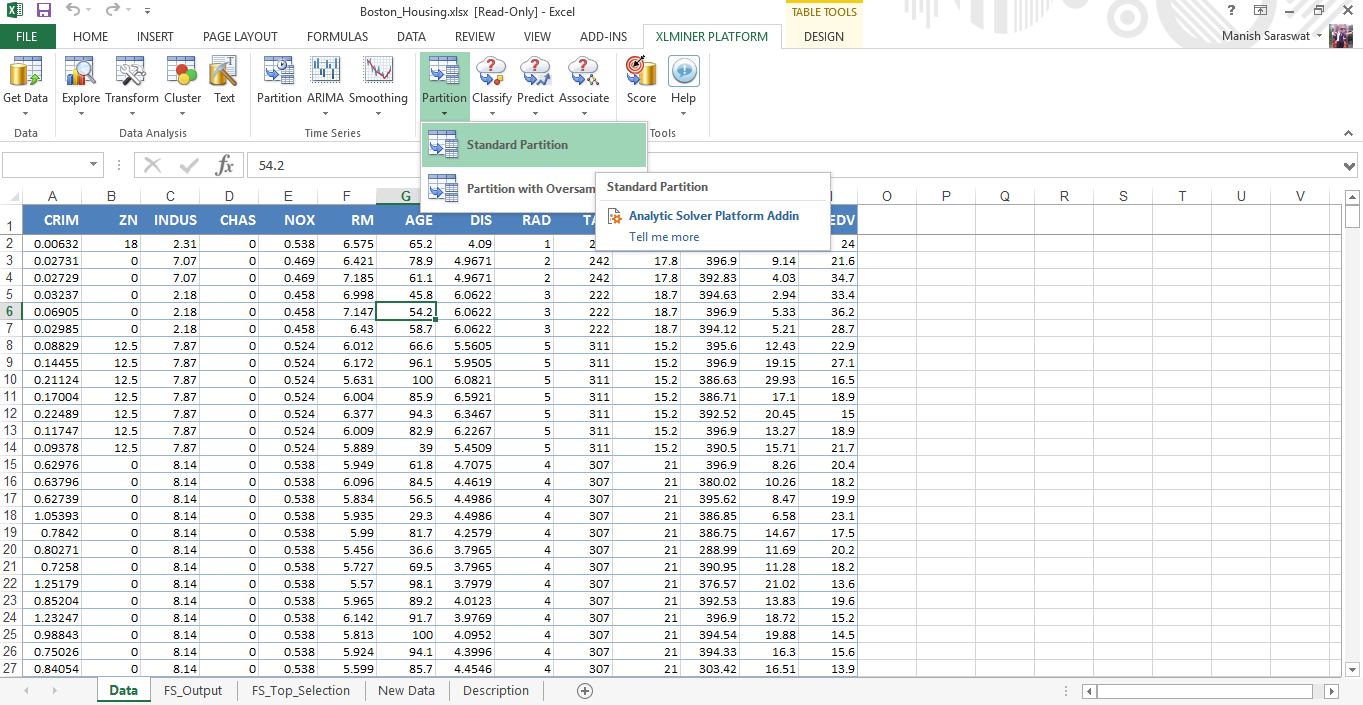
12. Sobre la base de la selección de características, seleccione las variables que se incluirán en la partición. Deje el resto como valores predeterminados y haga clic en Aceptar.
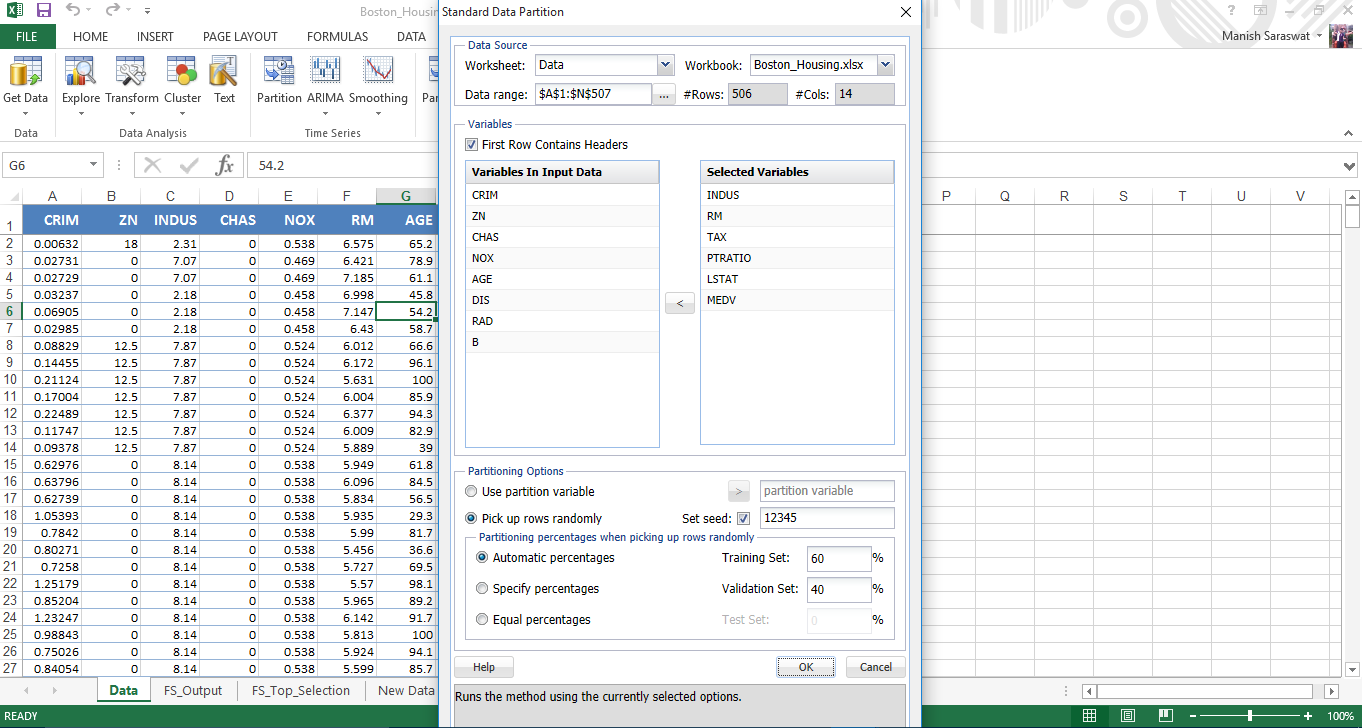
13. Y aquí tenemos el conjunto de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... listo para modelar.
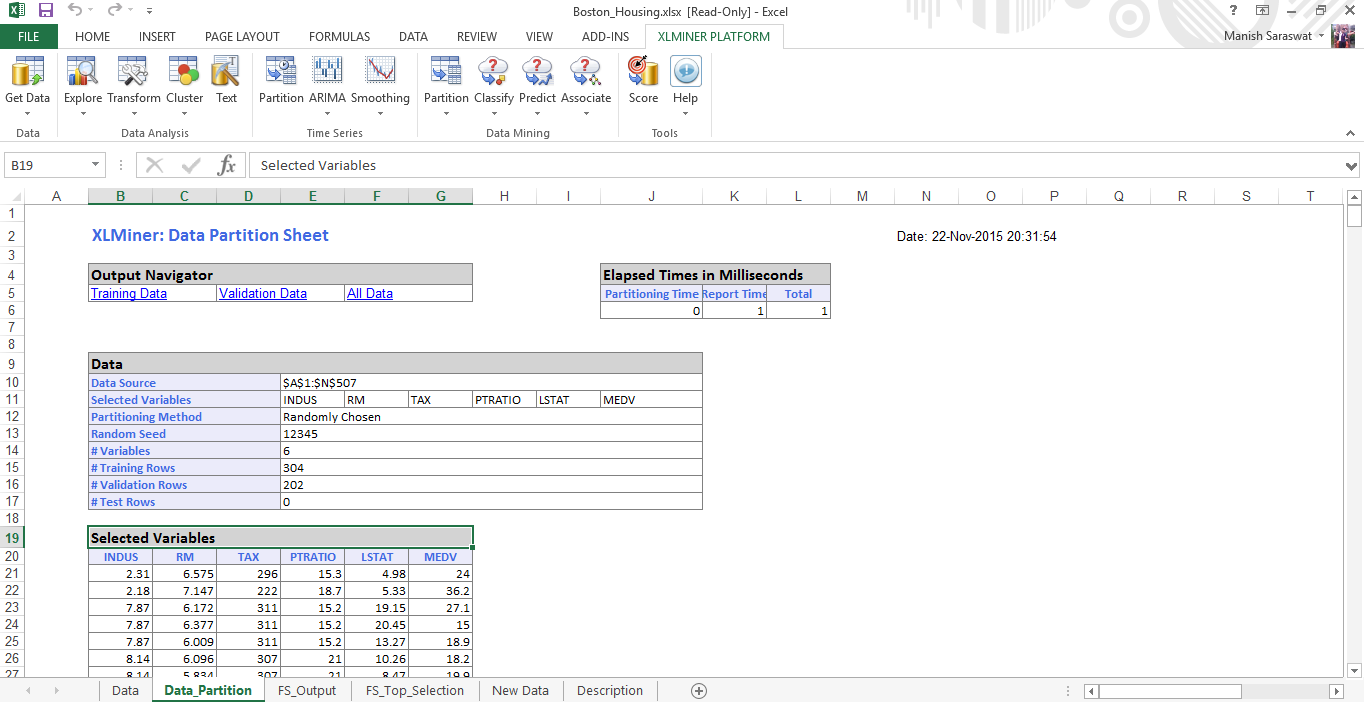
14. Haga clic en cualquier celda en Variables seleccionadas y proceda a construir el modelo de regresión múltiple. Haga clic en Regresión lineal múltiple
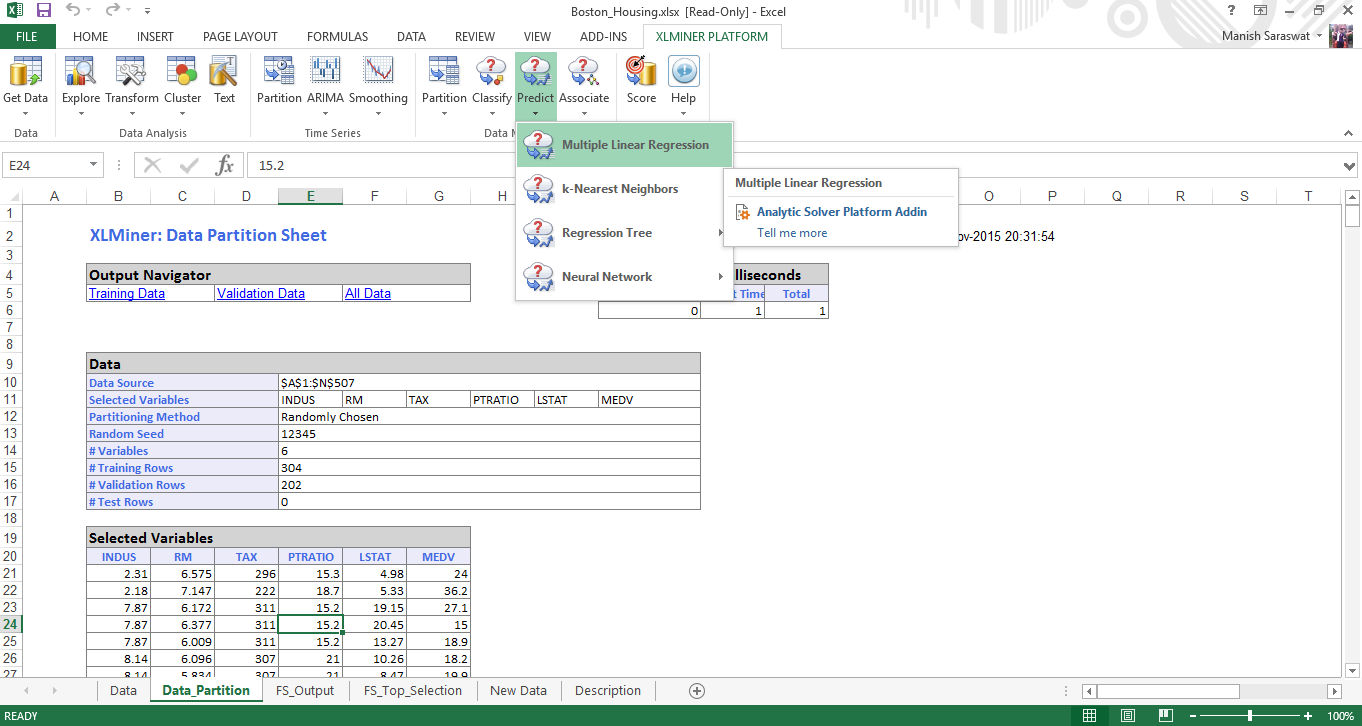
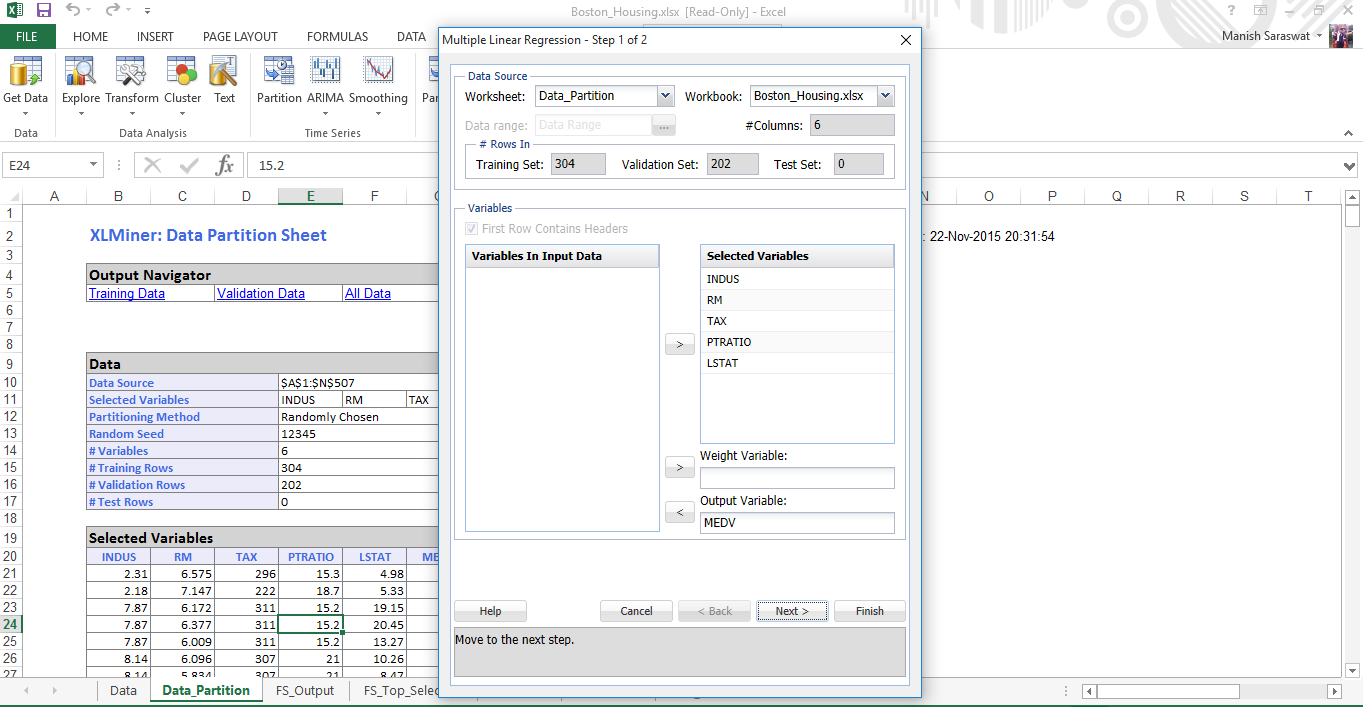
15. Seleccione el conjunto de variables predictoras y de respuesta. Haga clic en Siguiente
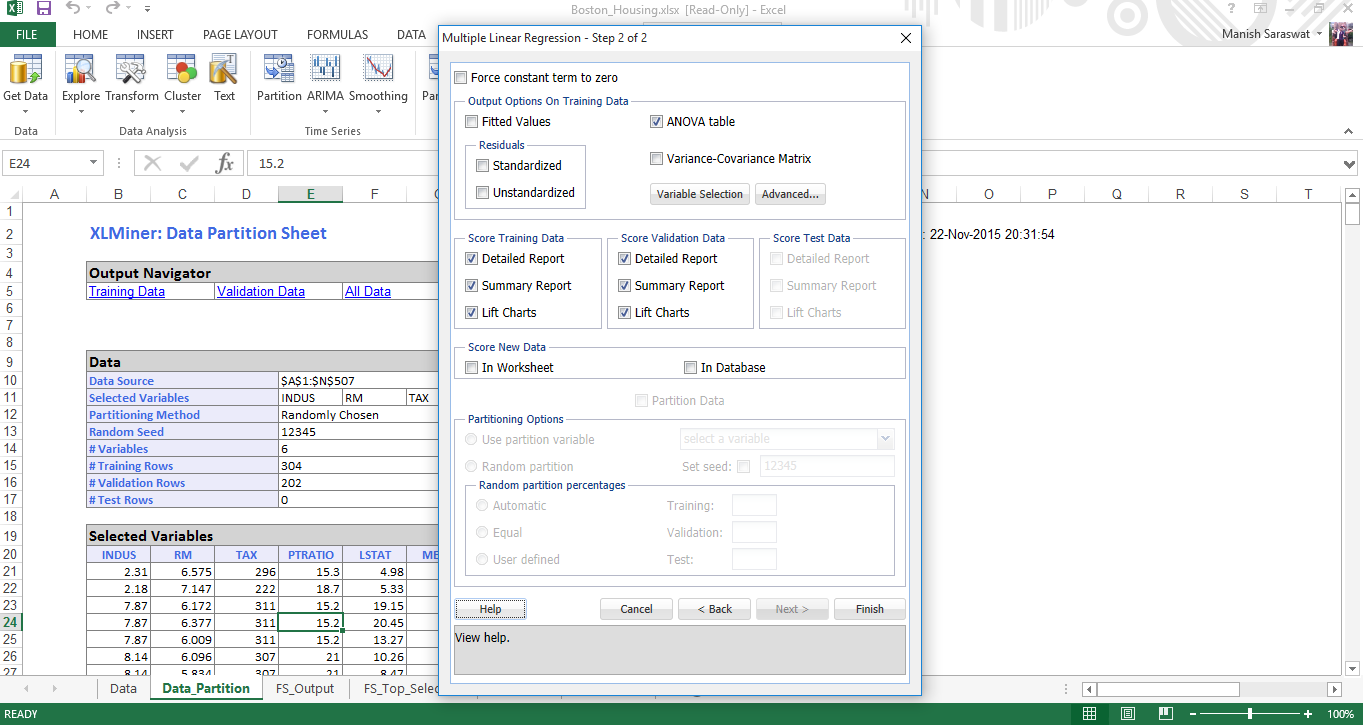
16. Seleccione sus métricas requeridas. Haga clic en Finalizar
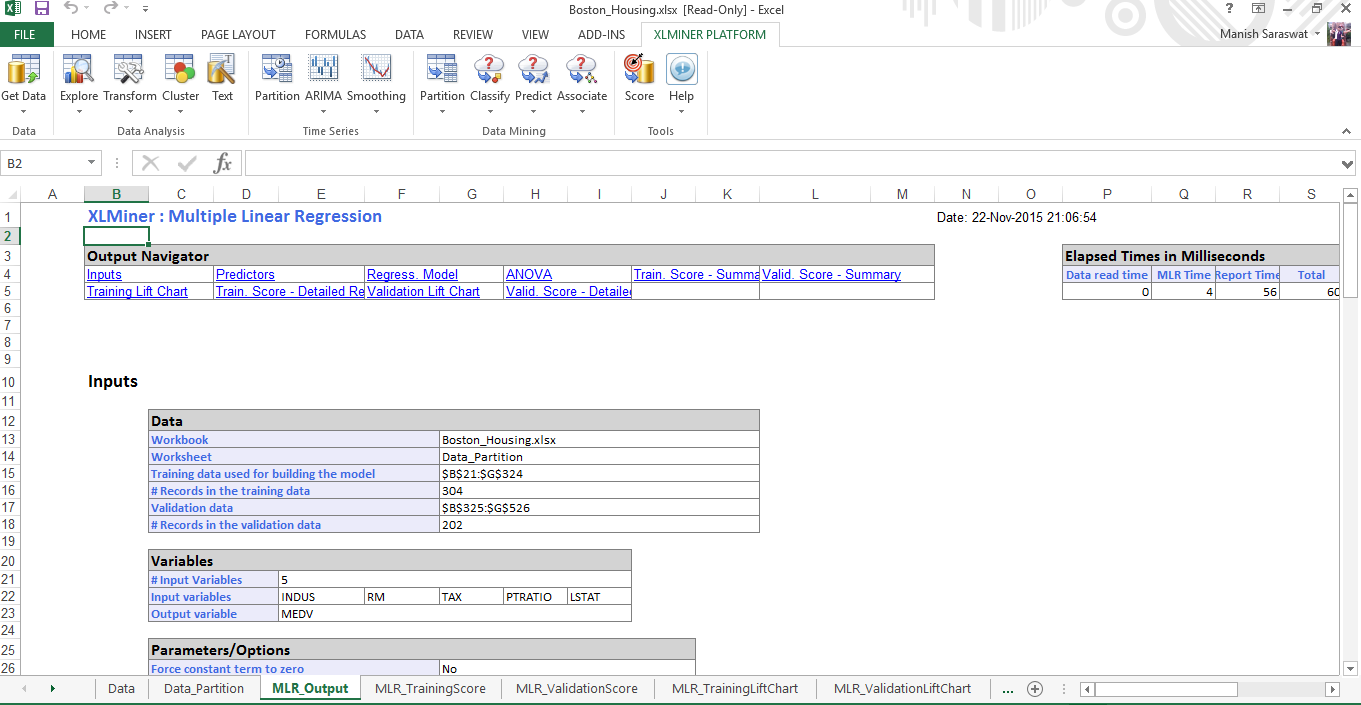
17. Su modelo de regresión lineal múltiple está listo. Utilice el navegador de salida para acceder a diferentes métricas y precisión del modelo.
Tutorial: regresión logística
La regresión logística es un ejemplo clásico de algoritmo de clasificación. Similar a la regresión lineal múltiple, a continuación se muestran los pasos para construir un modelo de regresión logística. Si desea actualizar rápidamente sus conceptos de regresión logística, puede consultar este tutorial: Guía simple de regresión logística
1. Cargue el conjunto de datos ‘Charles_bookclub’. En XLMiner Ribbon, haga clic en Ayuda -> Ejemplo. Seleccione este conjunto de datos. Este conjunto de datos representa información asociada con personas que son miembros de un club de lectura. Construiremos un modelo para predecir si una persona comprará un libro sobre la ciudad de Florencia en base a compras anteriores.
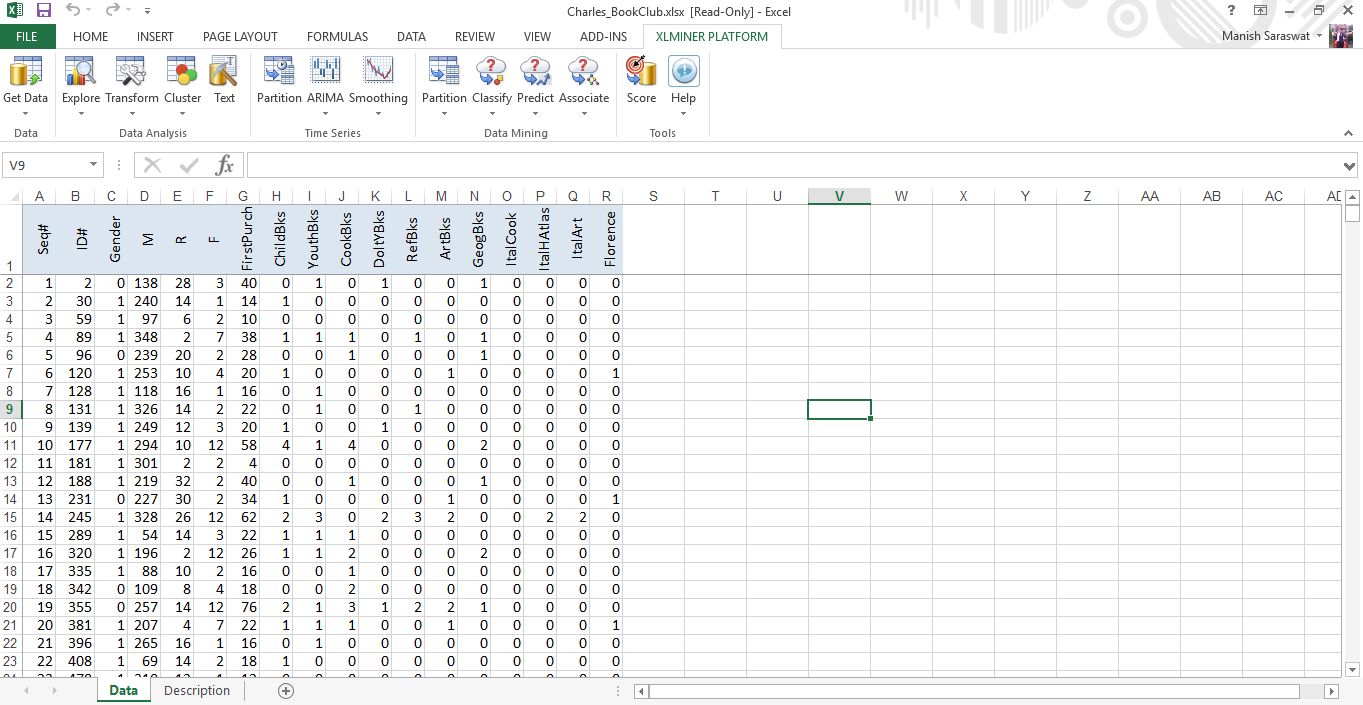
2. Ahora, dividiremos el conjunto de datos en entrenamiento (70%) y validación (30%). Esta vez necesita especificar porcentajes para la partición. Haga clic en Aceptar
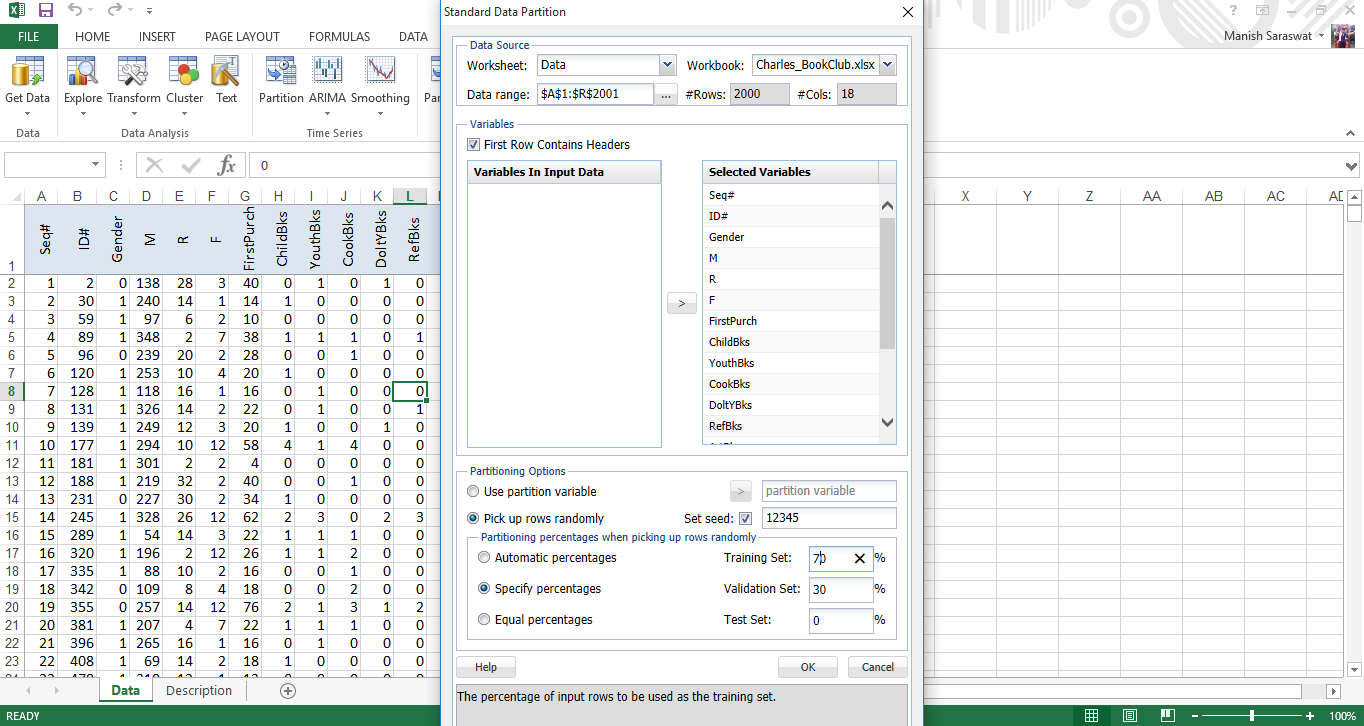
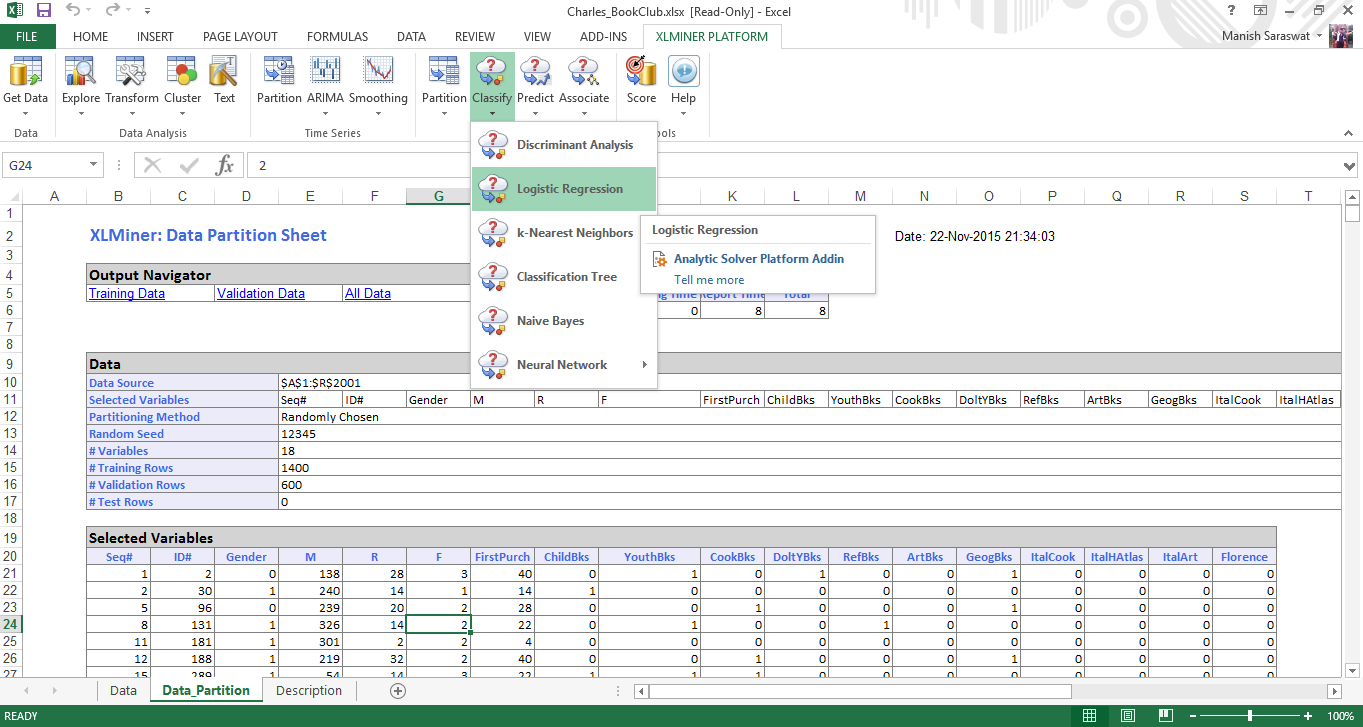
3. Verá una hoja de partición de datos. Haga clic en cualquier celda en la tabla de ‘variables seleccionadas’ y haga clic en regresión logística como se muestra.
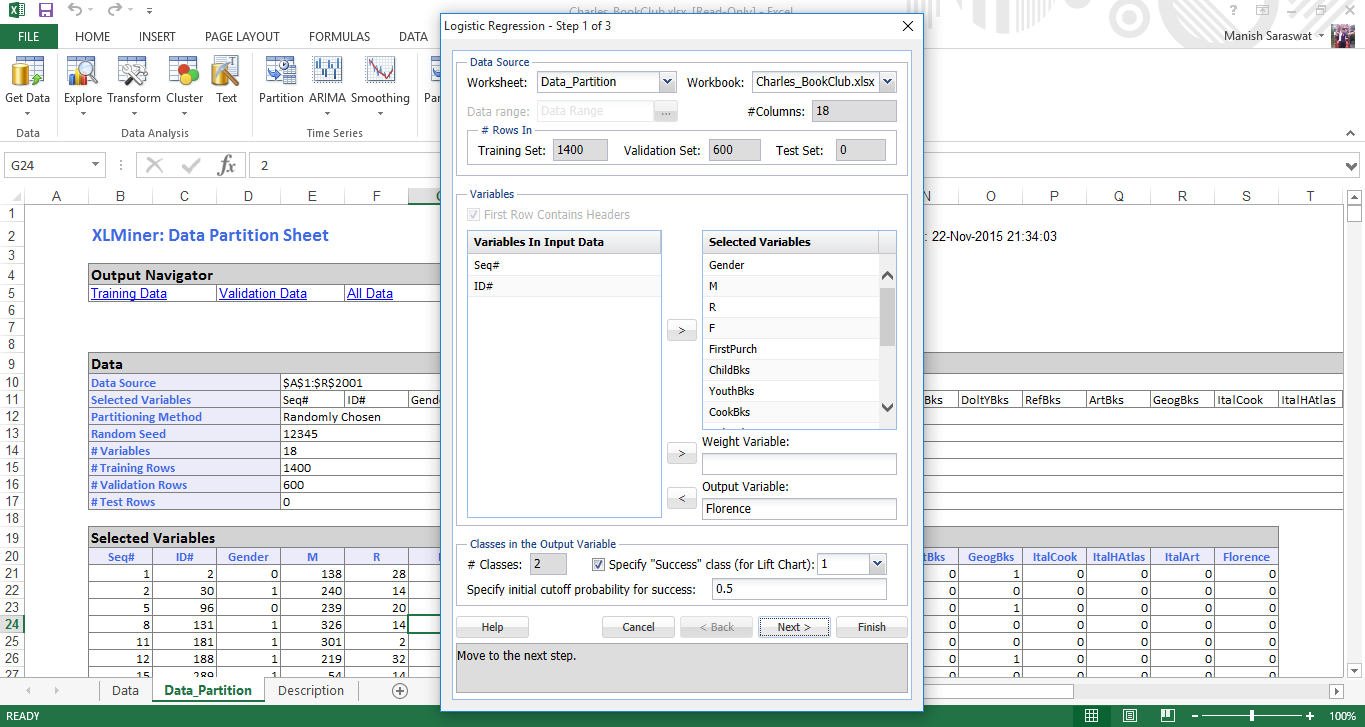
4. Aquí selecciona las variables de entrada y salida. Florencia es la variable de salida donde obtiene 1 cuando un cliente compró un libro sobre la ciudad de Florencia y 0 en caso contrario. Aquí 1 es el éxito. 0 es un error como se indica en la siguiente opción. Deje el resto como valores predeterminados. Haga clic en Siguiente
5. Seleccione el intervalo de confianza como 95%. Si marca ‘Forzar término constante a cero’, omitirá el término constante en la regresión. Por lo tanto, no lo seleccione. Haga clic en avanzado y marque ‘realizar diagnósticos de colinealidad’. Mostrará información útil al tratar con variables correlacionadas que tienen grandes errores estándar. Haga clic en Aceptar. Ahora, haga clic en Selección de variable.
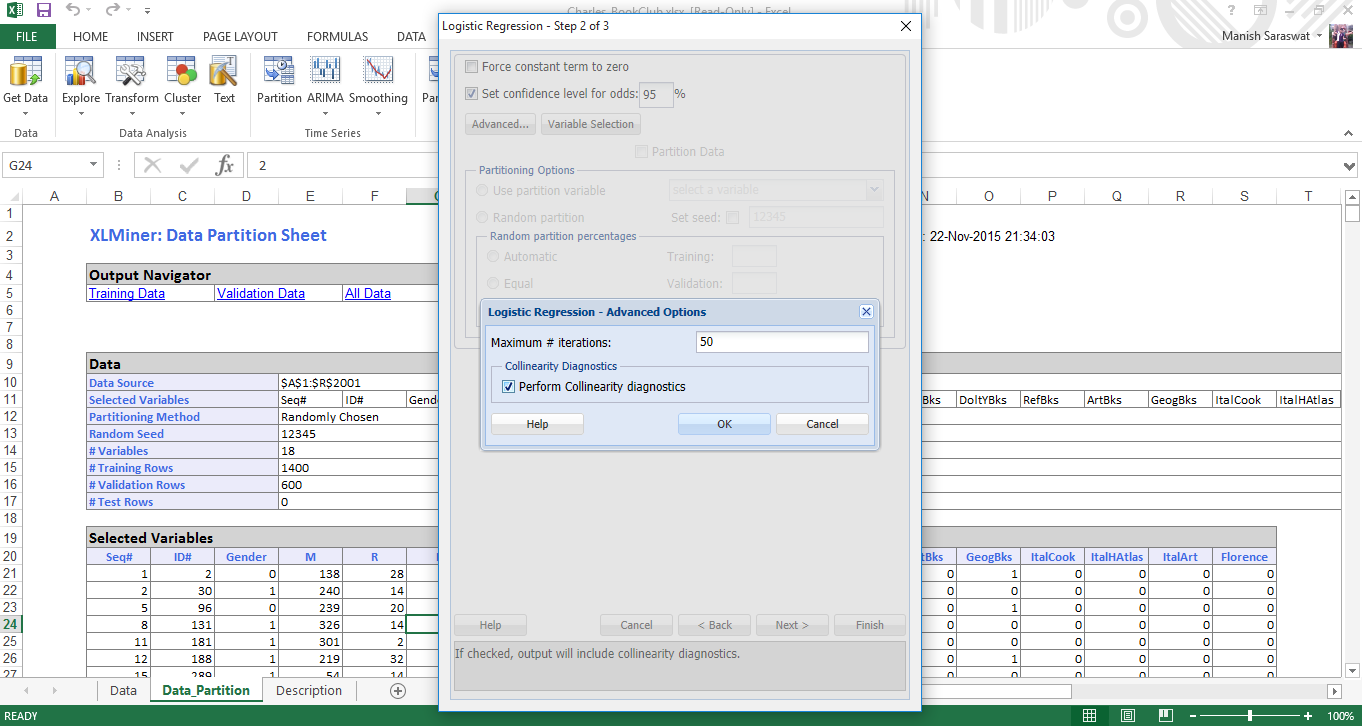
6. La selección de variables nos ayuda a tratar con un gran número de variables predictoras y encontrar la mejor entre ellas. ‘Tamaño máximo del mejor subconjunto’ toma un valor de 1 a N, donde N es el número de variables de entrada. No cambiaremos este valor. En el procedimiento de selección, puede elegir cualquiera según sus preferencias. Elegí ‘Mejores subconjuntos’ porque busca todas las combinaciones de variables y selecciona solo las que mejor se ajustan. Haga clic en Aceptar. Haga clic en Siguiente.
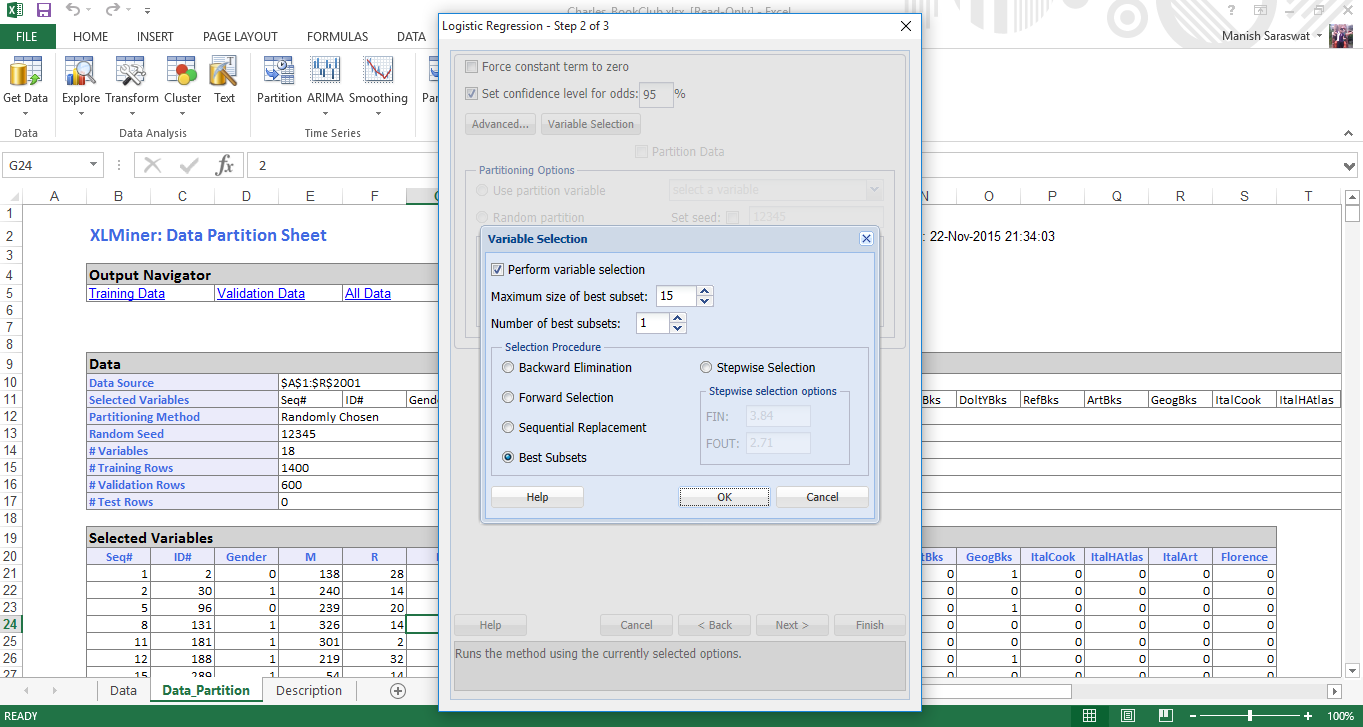
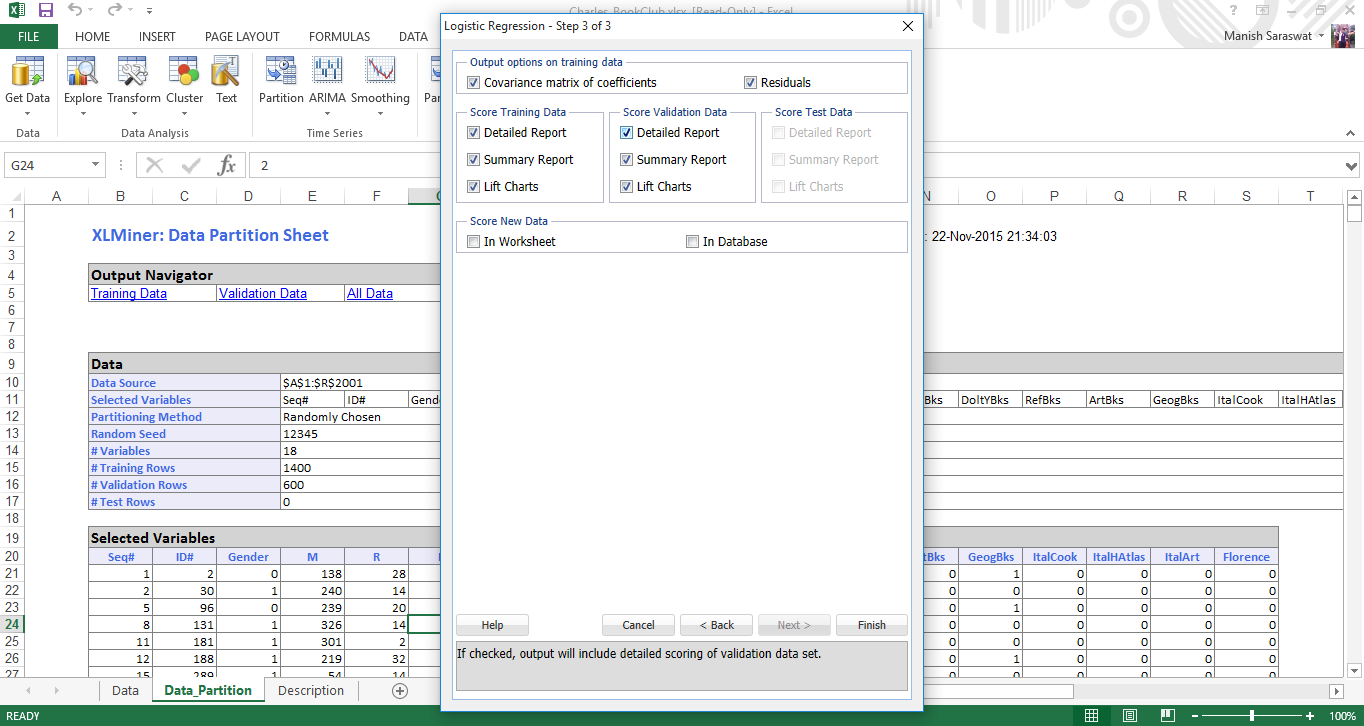
7. Ahora seleccionaremos los coeficientes de cálculo necesarios para evaluar el modelo. Seleccione Matriz de covarianza de coeficientes y residuos. Los residuos producirán una tabla de valores ajustados y sus residuos en la salida. Haga clic en Finalizar.
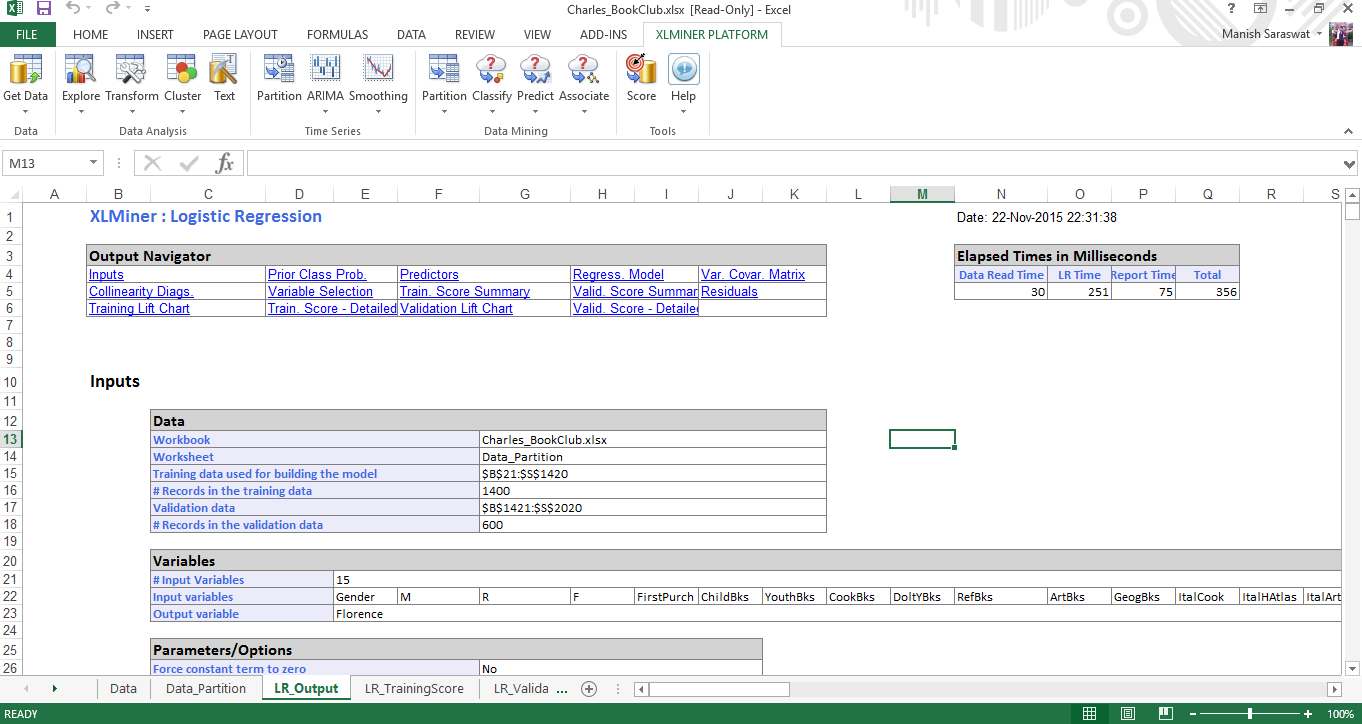
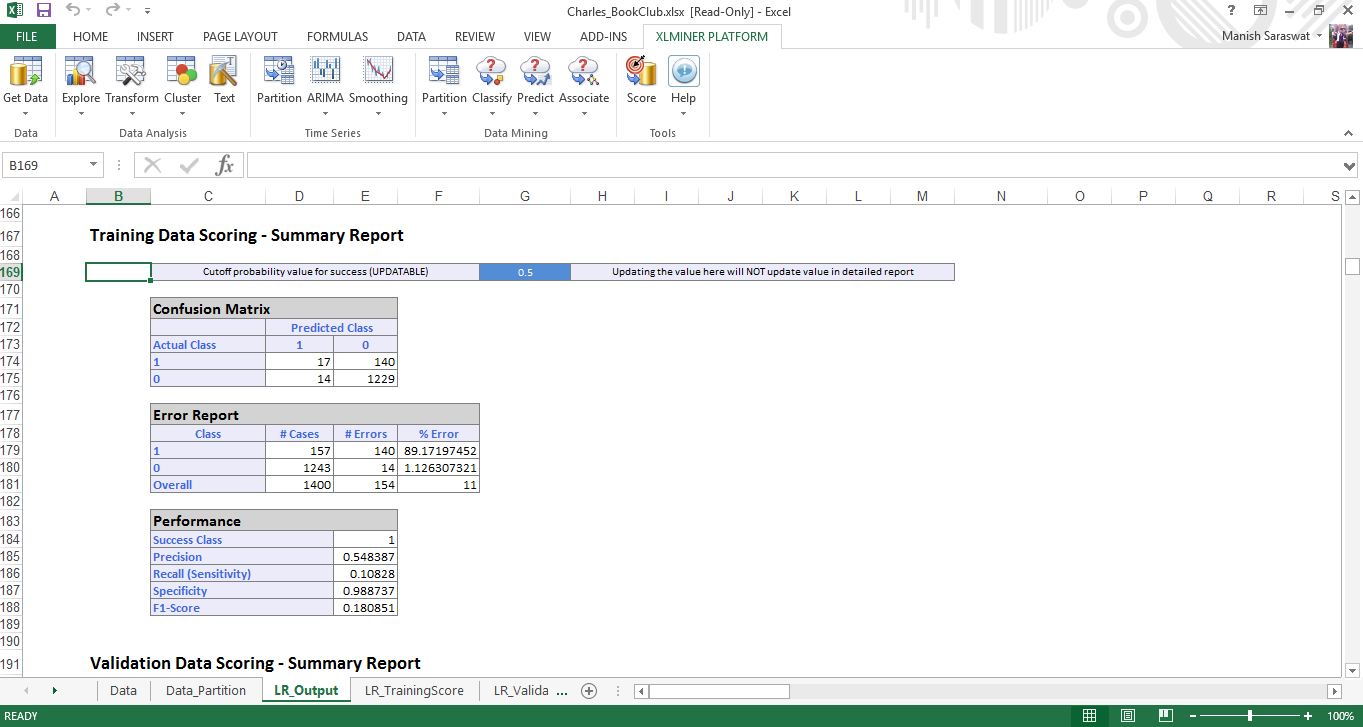
8. Aquí está su modelo de regresión logística. Si se desplaza hacia abajo en esta hoja, encontrará varias métricas útiles para evaluar el rendimiento de este modelo. Una métrica comúnmente utilizada para verificar la precisión del modelo es la matriz de confusión. A medida que se desplaza hacia abajo, encontrará esto.
Tutorial: k – Agrupación de medias
Si es nuevo en la agrupación en clústeres, este es un repaso rápido al análisis de agrupación. En palabras simples, la agrupación en clústeres es una técnica de agrupación de variables con atributos similares. Esta técnica se utiliza generalmente para la elaboración de perfiles de clientes y la creación de productos según sus necesidades.
Veamos los pasos para realizar la agrupación en clústeres de k-medias en XLMiner.
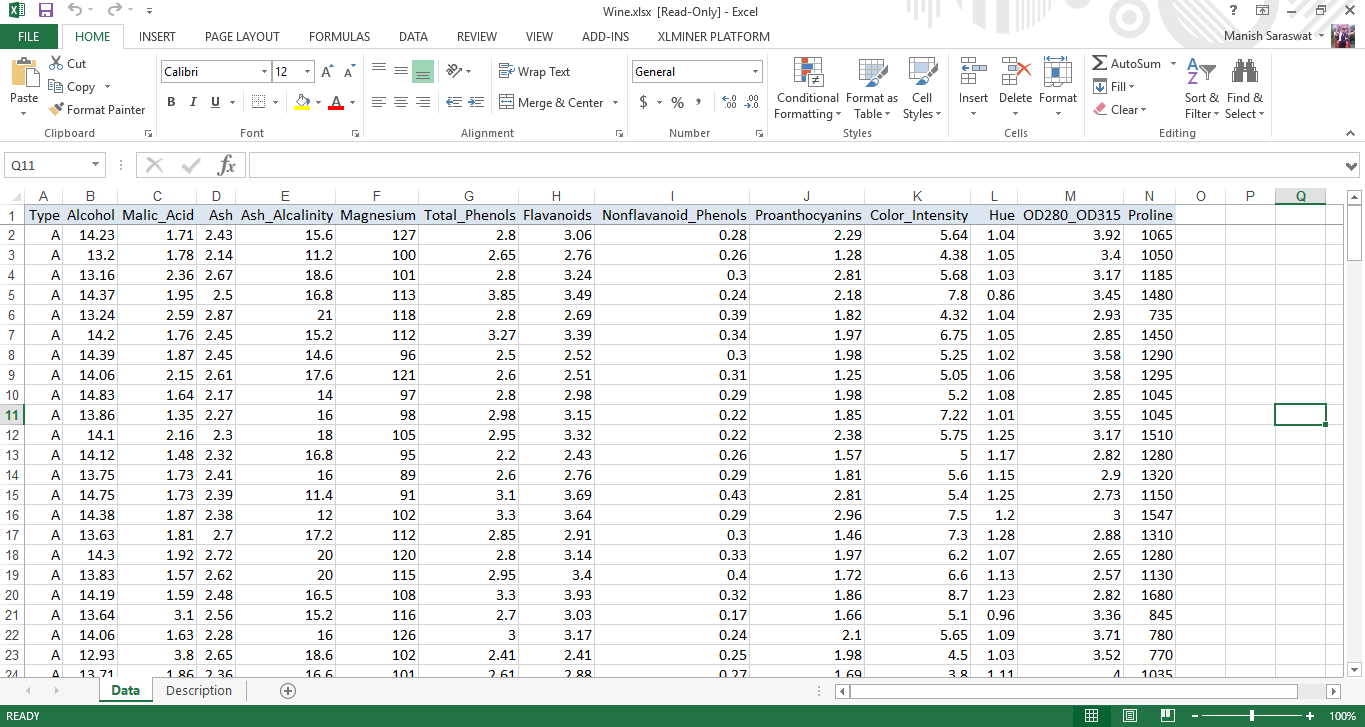
1. Cargue el conjunto de datos Wine. Vaya a la cinta de XLMiner, haga clic en Ayuda -> Ejemplos. Seleccione Vino. En este conjunto de datos, cada fila representa una muestra de vino que pertenece a 3 clases (A, B y C). Sobre la base de estos datos, crearemos un modelo de agrupamiento para determinar la clase de vino. Aquí está el conjunto de datos.
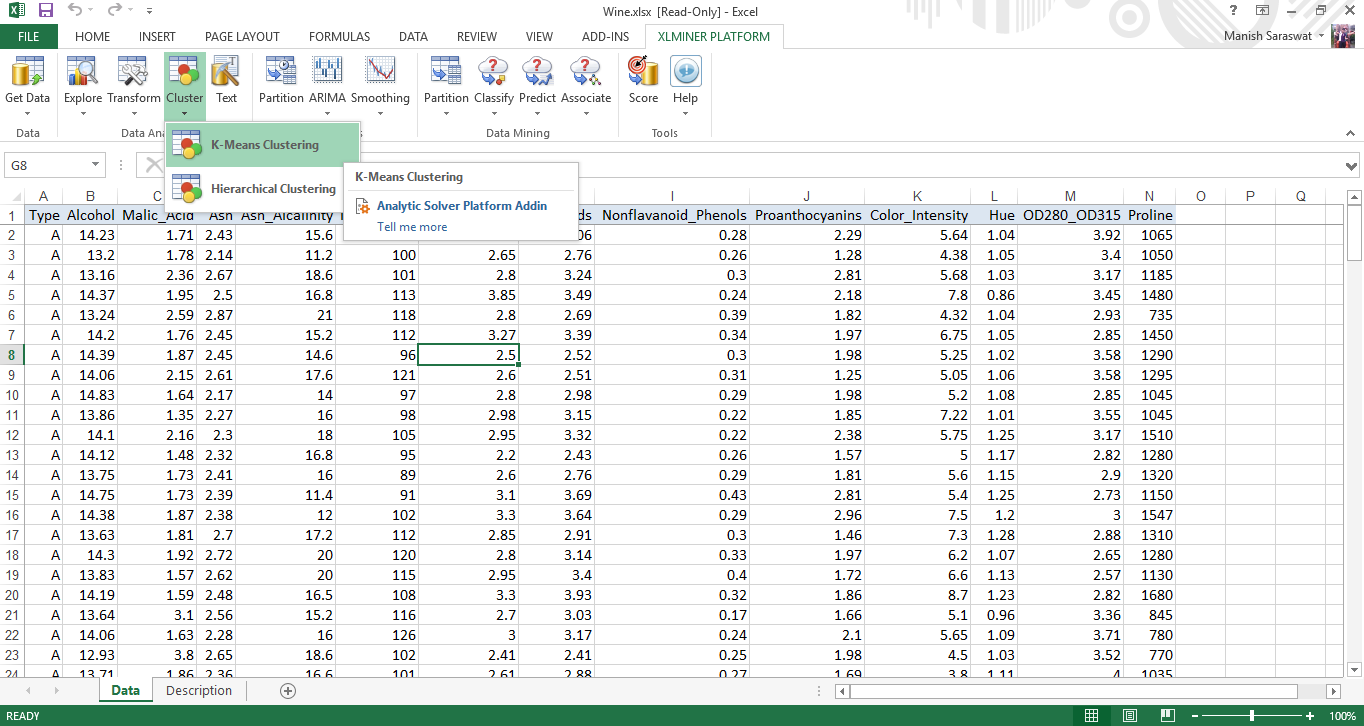
2. Haga clic en cualquier celda del conjunto de datos. Luego, haga clic en clustering de k-means.
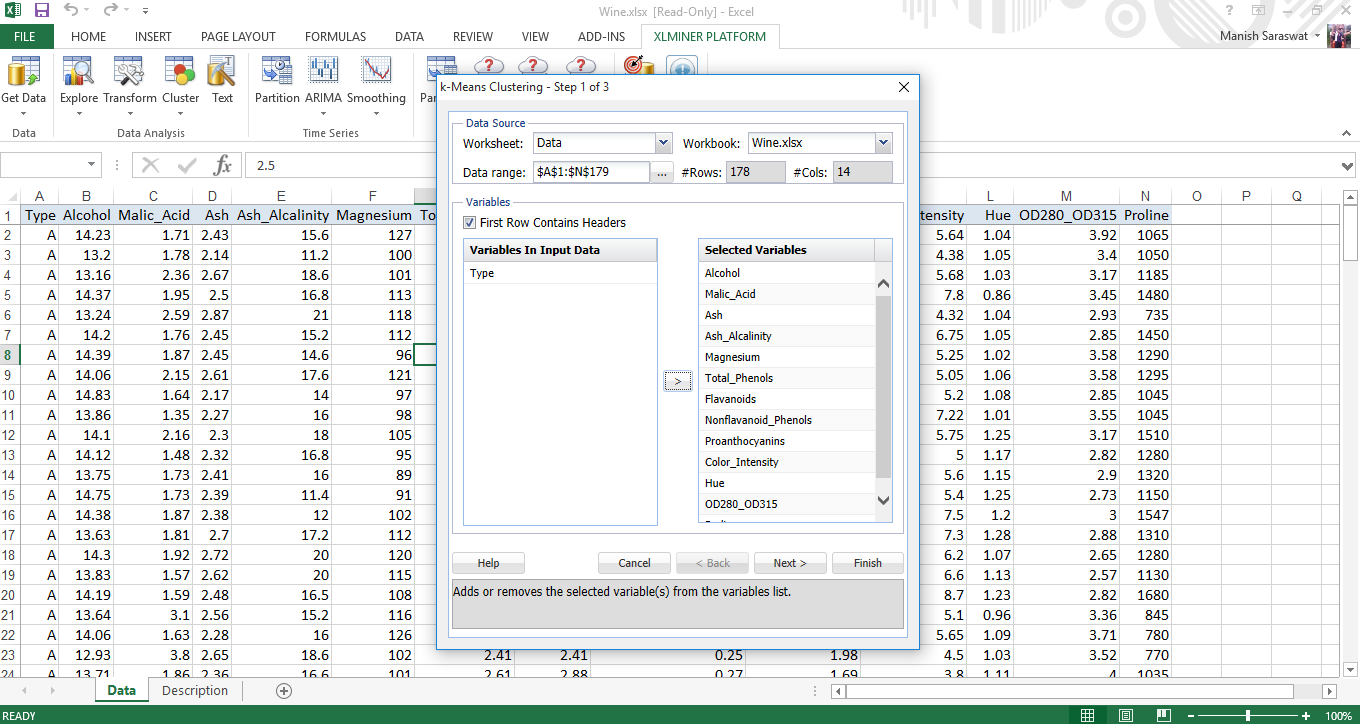
3. Tipo es la variable de salida. Por lo tanto, seleccionaremos todas las variables excepto Type para usarlas en la agrupación. Haga clic en Siguiente.
4. Tomemos el número de conglomerados como 8. Porque, con un gran número de conglomerados, la suma del error al cuadrado (SSE) sigue siendo pequeña. SSE se define como la suma de la distancia al cuadrado entre cada miembro del grupo y su centroide. Puede establecer cualquier valor de ky evaluar la salida de cada uno para comprobar cuál es el mejor. Establecer un valor aleatorio para decir 5, permitirá que este algoritmo construya el modelo desde cualquier punto aleatorio. Con esto, XLMiner generará 5 conjuntos de clústeres y generará el resultado del mejor clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo..... Deje los valores predeterminados para descansar y haga clic en Siguiente.
5. Deje los valores por defecto. Haga clic en Finalizar
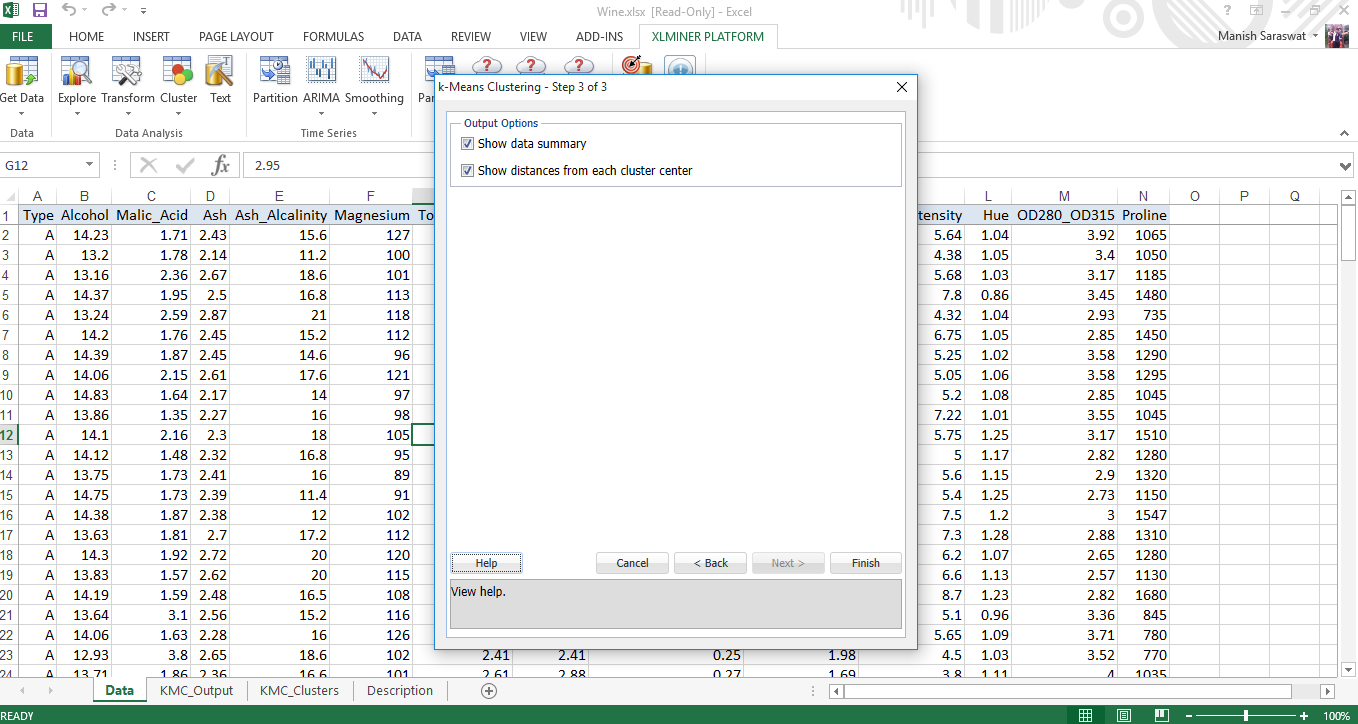
6. Aquí está su modelo de agrupamiento. Consulte nuestras diversas métricas de evaluación para determinar la precisión de este modelo.
Resumen de inicios aleatorios: Esta tabla determina el mejor comienzo con la distancia más baja de suma de cuadrados. En este caso (# 1) es el mejor comienzo. Una vez que se determina el mejor comienzo, la salida restante del modelo se genera utilizando el mejor comienzo como punto de partida.
Centros de clúster: Aquí encontrará dos cajas. El cuadro inferior muestra la distancia entre el centroide de los conglomerados. Cuanto mayor sea la distancia, diferente será la naturaleza de los grupos. Por ejemplo, la diferencia entre el grupo 4 y el grupo 8 es 1176,59. Esto sugiere que estos grupos son muy diferentes. El cuadro superior muestra los valores de las variables en los centros de los conglomerados.
Resumen de datos: Representa la distancia promedio de observaciones desde el centro de un grupo. Podemos inferir que el conglomerado 2 tiene la distancia promedio más baja desde su centroide y el conglomerado 6 tiene la más alta.
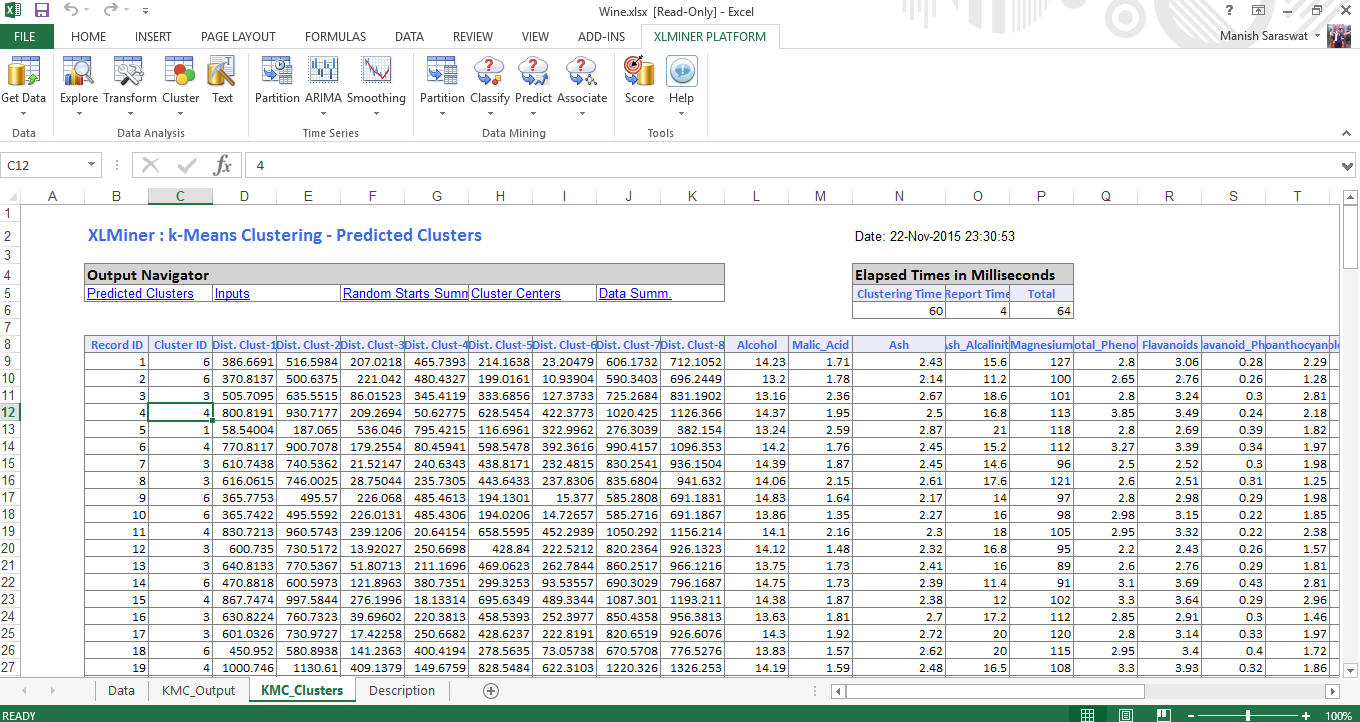
7. Haga clic en la hoja KMC_Clusters. Aquí encontrará los grupos predichos. Verifique el ID de registro 1. Se ha clasificado en el grupo 6. Porque la distancia de esta observación es mínima al grupo 6. De manera similar, todas las demás observaciones se han clasificado sobre la base de su grupo más cercano.
Notas finales
Escribí este tutorial solo para comenzar con el aprendizaje automático en Excel. Una vez que comprenda estos algoritmos, puede usarlos fácilmente en R, Python o cualquier otro lenguaje de programación. Dado que muchos de nosotros hemos trabajado en Excel en algún momento, no sería difícil entender estos conceptos en Excel. Si se queda atascado, puede consultar la opción de ayuda en XLMiner Ribbon. La documentación es útil y fácil de entender.
Ahora que conoce los pasos, le sugiero que dedique tiempo a interpretar el modelo y lo repita para obtener el mejor ajuste. Excel puede ralentizarse con conjuntos de datos grandes, por lo que debe trabajar con conjuntos de datos pequeños para ahorrar tiempo en el aprendizaje.
¿Le resultó útil este artículo? ¿Ha trabajado alguna vez en XLMiner? Me encantaría escuchar sus experiencias y sugerencias en la sección de comentarios a continuación.





