Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
¡Bien! A todos nos encantan los pasteles. Si observa más profundamente el proceso de horneado, notará cómo la combinación adecuada de los diversos ingredientes y un agente de levadura inteligente, el polvo para hornear, puede decidir el aumento y la caída de su pastel.
«Hornear el pastel» puede parecer fuera de lugar en el artículo técnico, pero creo que es bastante identificable y una analogía deliciosa para comprender la importancia de EDA en el proceso de ciencia de datos.
Cuando Hornear el pastel es para Data Science PipelinePipeline es un término que se utiliza en diversos contextos, principalmente en tecnología y gestión de proyectos. Se refiere a un conjunto de procesos o etapas que permiten el flujo continuo de trabajo desde la concepción de una idea hasta su implementación final. En el ámbito del desarrollo de software, por ejemplo, un pipeline puede incluir la programación, pruebas y despliegue, garantizando así una mayor eficiencia y calidad en los..., entonces Clever Leavening Agent (polvo de hornear) es para Análisis de datos exploratorios.
Antes de que se te haga la boca agua por un pastel como el mío, entendamos.
¿Qué es exactamente el análisis de datos exploratorios?
El análisis exploratorio de datos es un enfoque para el análisis de datos que emplea una variedad de técnicas para:
- Obtenga intuición sobre los datos.
- Realice controles de cordura. (Para estar seguros de que los conocimientos que estamos extrayendo provienen en realidad del conjunto de datos correcto).
- Descubra dónde faltan datos.
- Compruebe si hay valores atípicos.
- Resume los datos.
Tomemos el famoso estudio de caso de «VENTAS DE VIERNES NEGROS» para comprender, ¿Por qué necesitamos EDA?

El problema central es comprender el comportamiento del cliente mediante la predicción del monto de la compra. Pero, ¿no es demasiado abstracto y te deja desconcertado sobre qué hacer con los datos, especialmente cuando tienes tantos productos diferentes con varias categorías?
Antes de seguir leyendo, piensa un poco en esta pregunta: ¿pondrías todos los ingredientes disponibles en la cocina como está en el horno para hornear el pastel?
Obviamente, ¡la respuesta es no! Antes de tomar el conjunto de datos completo como está en consideración para hornearlo en el modelo de aprendizaje automático, querrá
- Extraiga información importante
- Identificación de variables (si los datos contienen variables categóricas o numéricas o una combinación de ambas).
- El comportamiento de las variables (si las variables tienen valores de 0 a 10 o de 0 a 1 millón).
- Relación entre variables (cómo las variables dependen unas de otras).
-
Verificar la coherencia de los datos
- Para asegurar que todos los datos estén presentes. (Si hemos recopilado datos durante tres años, cualquier semana que falte puede ser un problema en etapas posteriores).
- ¿Hay algún valor faltante presente?
- ¿Hay valores atípicos en el conjunto de datos? (por ejemplo: una persona con 2000 años es definitivamente una anomalía)
- Ingeniería de funciones
- Ingeniería de características (para crear nuevas características a partir de las características sin procesar existentes en el conjunto de datos).
** EDA, en esencia, puede romper o hacer cualquier modelo de aprendizaje automático. **
Pasos en el análisis exploratorio de datos

Hay 5 pasos en EDA: ->
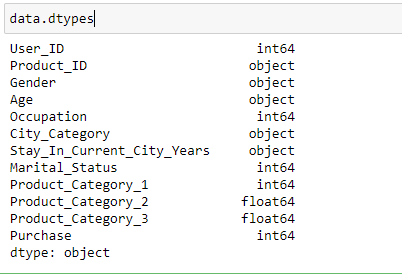
- Identificación de variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos....: En este paso, identificamos cada variable descubriendo su tipo. Según nuestras necesidades, podemos cambiar el tipo de datos de cualquier variable.

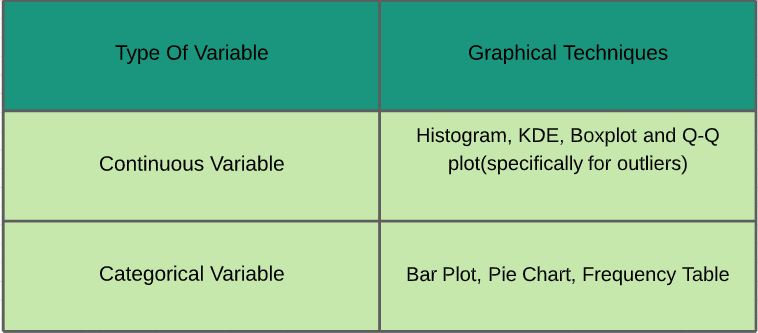
~ Las estadísticas juegan un papel importante en el análisis de datos. Es un conjunto de reglas y conceptos para el análisis e interpretación de los datos. Hay diferentes tipos de análisis que deben realizarse según los requisitos. ~ Estudiémoslos - Análisis univariado: En el análisis univariante, estudiamos las características individuales de cada característica / variable disponible en el conjunto de datos. Hay dos tipos de funciones: continuas y categóricas. En la imagen de abajo, he dado una hoja de trucos de varias técnicas gráficas que se pueden aplicar para analizarlas.

Variable continua:
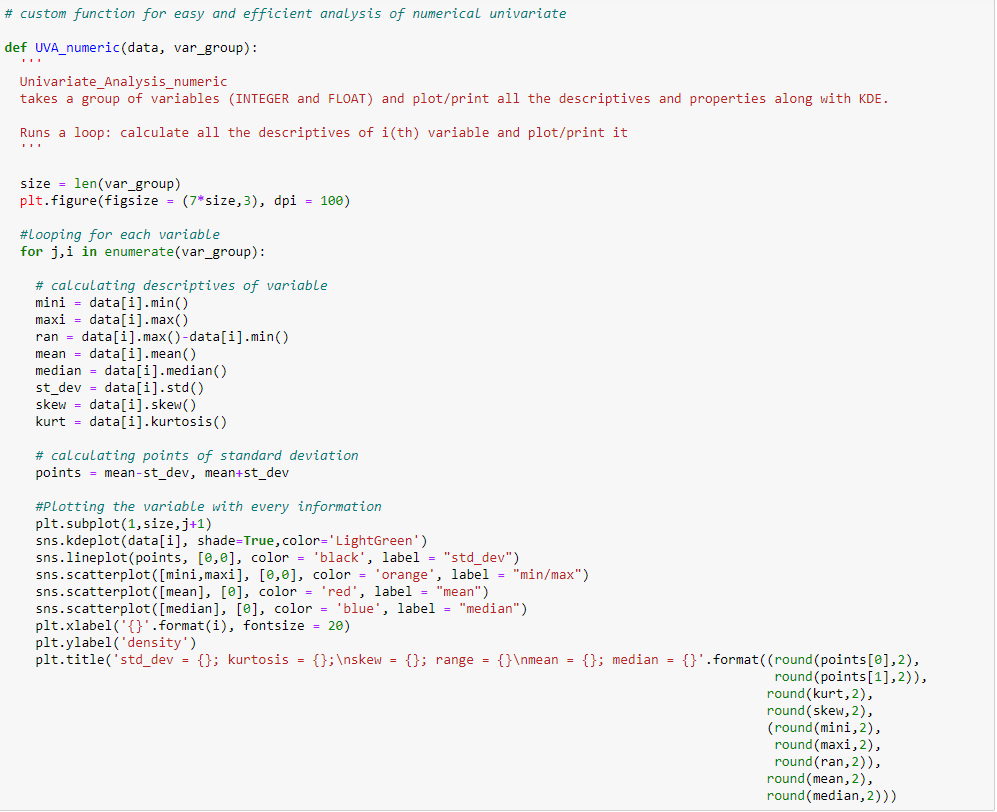
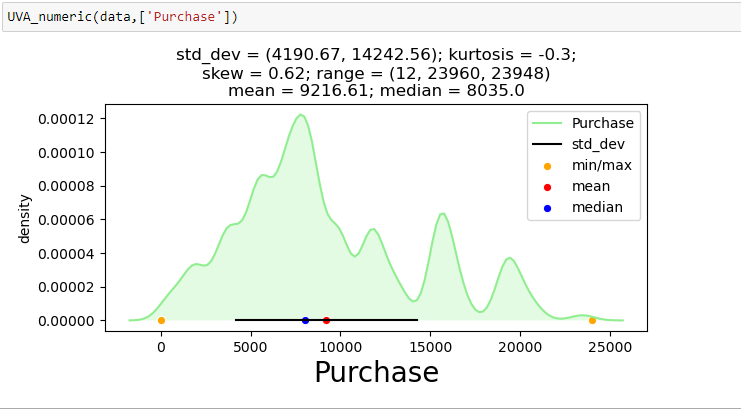
Para mostrar el análisis univariante en una de las variables continuas del conjunto de datos de venta de Black Friday: «Compra», he creado una función que toma datos como entrada y traza un gráfico de KDE que explica las características de la función.


Variable categórica
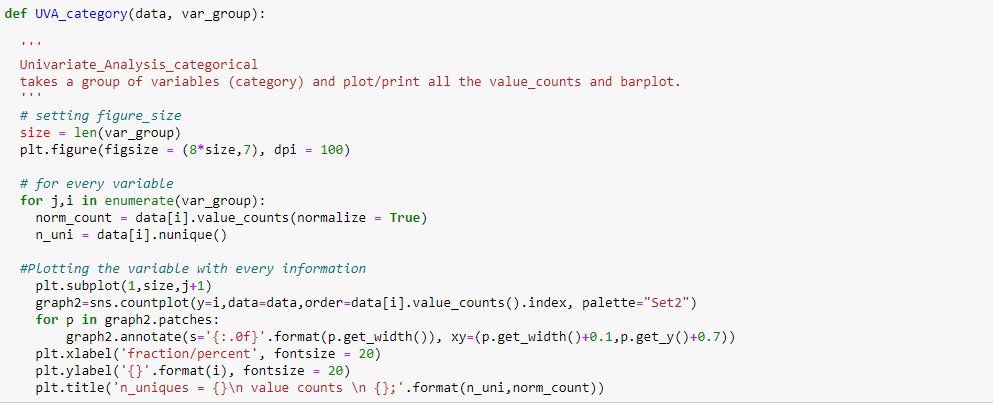
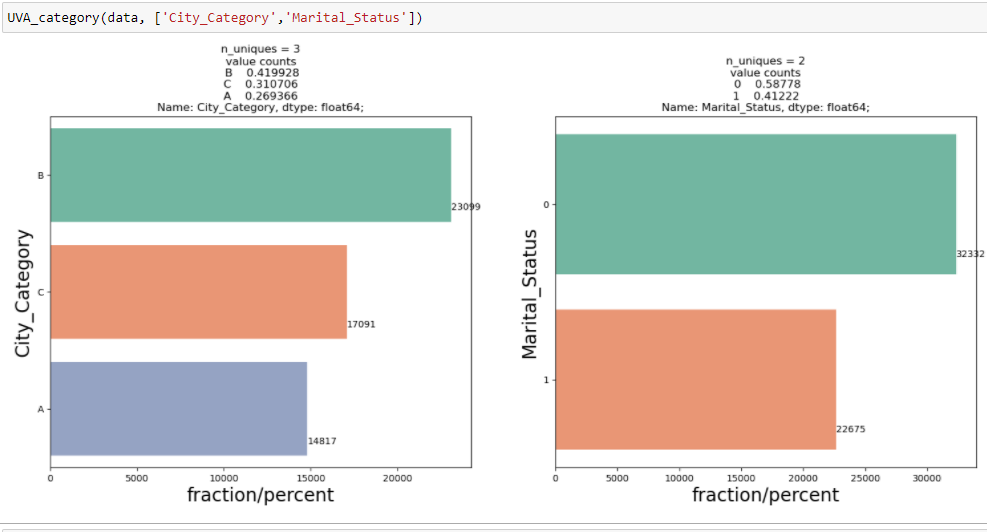
Para mostrar el análisis univariante en las variables categóricas del conjunto de datos de venta de Black Friday: `City_Category` y` Marital_Status`, he creado una función que toma datos y características como entrada que devuelve un gráfico de conteo que explica la frecuencia de las categorías en la característica.


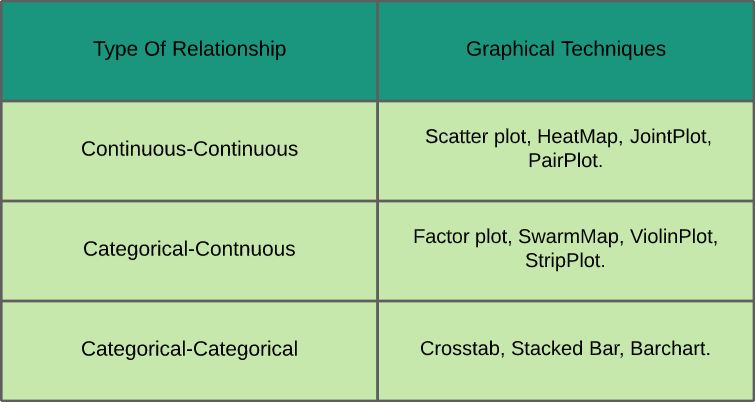
- Análisis bivariado: En el análisis bivariado, estudiamos la relación entre dos variables cualesquiera que pueden ser categóricas-continuas, categóricas-categóricas o continuas-continuas (como se muestra en la hoja de referencia que se muestra a continuación junto con las técnicas gráficas utilizadas para analizarlas).

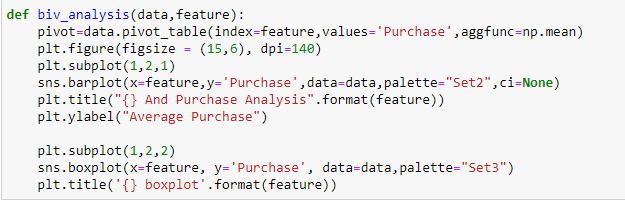
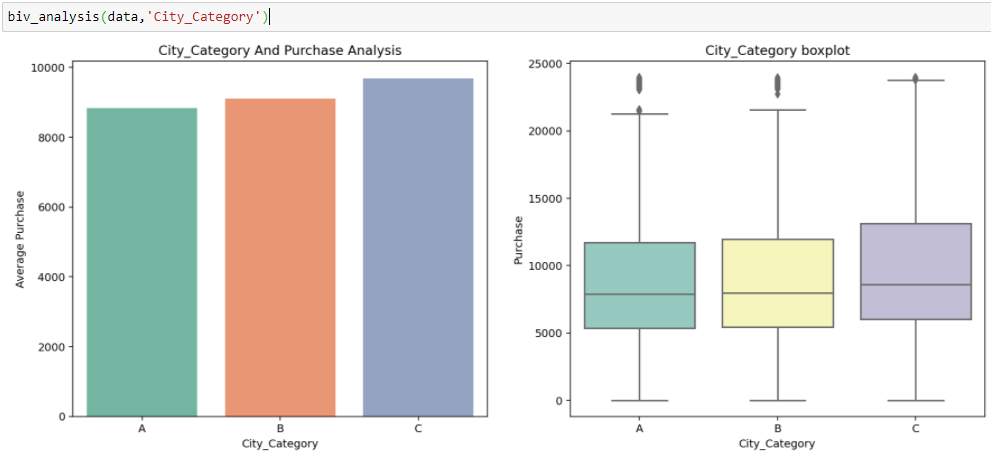
En Black Friday Sales, tenemos variables independientes categóricas y variables objetivo continuas, por lo que podemos hacer Análisis categórico-continuo para comprender la relación entre ellas.

Inferencia:
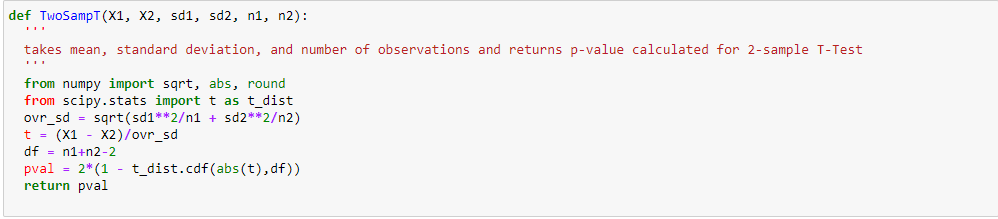
A partir de los dos análisis anteriores, hemos observado en el análisis univariante que un número de clientes es máximo en la categoría de ciudad B. Pero el análisis bivariado cuando se realiza entre `City_Category` y` Purchase` muestra una historia diferente de que la compra promedio es máxima de la categoría de ciudad C Por lo tanto, estas inferencias pueden darnos una mejor intuición sobre los datos, lo que a su vez ayuda a una mejor preparación de los datos y la ingeniería de características de las características.Es importante tener en cuenta que simplemente confiar en el análisis univariante y bivariado puede ser bastante engañoso, por lo que para verificar las inferencias extraídas de estos dos se puede validar con Prueba de hipótesis. Podemos hacer una prueba t, prueba de chi-cuadrado, Anova que nos permite cuantificar si dos muestras son significativamente similares o diferentes entre sí. Aquí he creado una función para analizar las relaciones continuas y categóricas que devuelven el valor de la estadística t.


 En Análisis Univariado observamos que existe una diferencia significativa entre el número de clientes casados y no casados. De la prueba t, obtenemos el valor de la estadística t 0.89, que es mayor que el nivel de significancia, es decir, 0.05, lo que muestra que no hay una diferencia significativa entre la compra promedio de solteros y casados.
En Análisis Univariado observamos que existe una diferencia significativa entre el número de clientes casados y no casados. De la prueba t, obtenemos el valor de la estadística t 0.89, que es mayor que el nivel de significancia, es decir, 0.05, lo que muestra que no hay una diferencia significativa entre la compra promedio de solteros y casados. - Tratamiento de valor perdido : La razón principal de este paso es averiguar si hay alguna razón específica por la que faltan estos valores y cómo los tratamos. Porque si no los tratamos, pueden interferir con el patrón que se ejecuta en los datos, lo que a su vez puede degradar el rendimiento del modelo. Algunas de las formas en que se pueden tratar los valores perdidos son: – Rellenarlos con media, medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos...., modo y puede utilizar imputers.
- Eliminación de valores atípicos : Es esencial que comprendamos la presencia de valores atípicos, ya que algunos de los modelos predictivos son sensibles a ellos y debemos tratarlos en consecuencia.

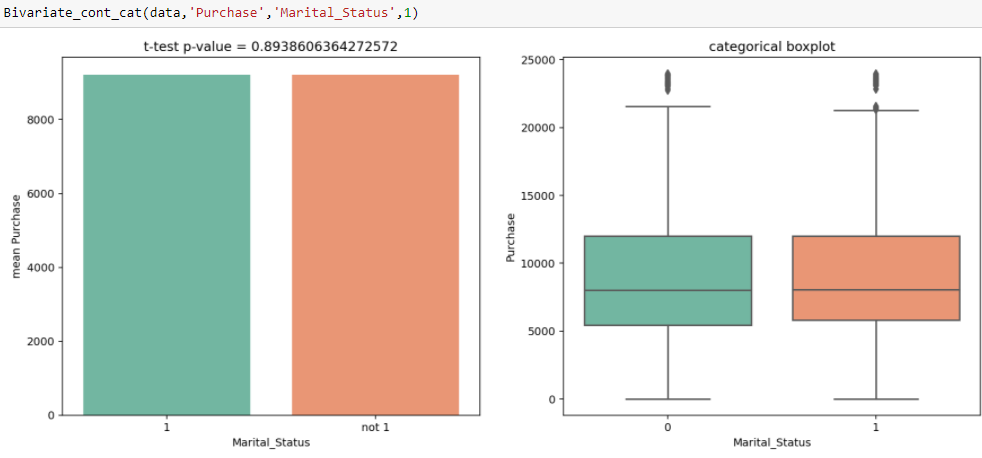 En Análisis Univariado observamos que existe una diferencia significativa entre el número de clientes casados y no casados. De la prueba t, obtenemos el valor de la estadística t 0.89, que es mayor que el nivel de significancia, es decir, 0.05, lo que muestra que no hay una diferencia significativa entre la compra promedio de solteros y casados.
En Análisis Univariado observamos que existe una diferencia significativa entre el número de clientes casados y no casados. De la prueba t, obtenemos el valor de la estadística t 0.89, que es mayor que el nivel de significancia, es decir, 0.05, lo que muestra que no hay una diferencia significativa entre la compra promedio de solteros y casados.Notas finales
En este artículo, he discutido brevemente la importancia de EDA en la canalización de la ciencia de datos y los pasos que están involucrados en un análisis adecuado. También he mostrado cómo un análisis incorrecto o incompleto puede ser bastante engañoso y puede afectar considerablemente el rendimiento de los modelos de aprendizaje automático.
«Si no tostas tus datos, eres solo otra persona con una opinión»;)





