Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Limpieza de datos es el proceso de analizar datos para encontrar valores incorrectos, corruptos y faltantes y eliminarlos para que sean adecuados para la entrada al análisis de datos y varios algoritmos de aprendizaje automático.
Es el paso principal y fundamental que se realiza antes de que se pueda realizar cualquier análisis de los datos. No hay reglas establecidas a seguir para la limpieza de datos. Depende totalmente de la calidad del conjunto de datos y del nivel de precisión a alcanzar.
Razones de la corrupción de datos:
- Los datos se recopilan de varias fuentes estructuradas y no estructuradas y luego se combinan, dando lugar a valores duplicados y mal etiquetados.
- Diferentes definiciones de diccionario de datos para datos almacenados en varias ubicaciones.
- Error de entrada manual / errores tipográficos.
- Capitalización incorrecta.
- Categorías / clases mal etiquetadas.
Calidad de los datos
La calidad de los datos es de suma importancia para el análisis. Hay varios criterios de calidad que deben comprobarse:

Atributos de calidad de datos
- Lo completo: Se define como el porcentaje de entradas que se completan en el conjunto de datos. El porcentaje de valores faltantes en el conjunto de datos es un buen indicador de la calidad del conjunto de datos.
- Precisión: Se define como la medida en que las entradas del conjunto de datos se acercan a sus valores reales.
- Uniformidad: Se define como la medida en que se especifican los datos utilizando la misma unidad de medida.
- Consistencia: Se define como la medida en que los datos son coherentes dentro del mismo conjunto de datos y en varios conjuntos de datos.
- Validez: Se define como la medida en que los datos se ajustan a las restricciones aplicadas por las reglas comerciales. Hay varias limitaciones:

Informe de perfil de datos
La creación de perfiles de datos es el proceso de explorar nuestros datos y encontrar información a partir de ellos. El informe de creación de perfiles de Pandas es la forma más rápida de extraer información completa sobre el conjunto de datos. El primer paso para la limpieza de datos es realizar un análisis de datos exploratorio.
Cómo utilizar la creación de perfiles de pandas:
Paso 1: El primer paso es instalar el paquete de creación de perfiles de pandas usando el comando pip:
pip install pandas-profilingPaso 2: Cargue el conjunto de datos usando pandas:
import pandas as pddf = pd.read_csv(r"C:UsersDellDesktopDatasethousing.csv")
Paso 3: Lea las primeras cinco filas:
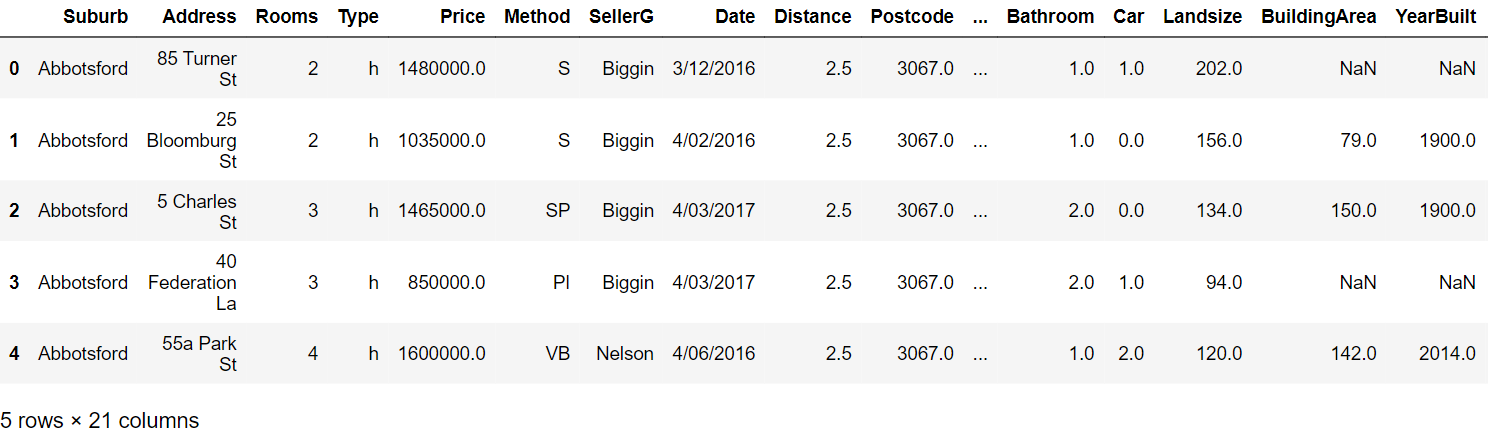
Paso 4: Genere el informe de creación de perfiles con los siguientes comandos:
from pandas_profiling import ProfileReportprof = ProfileReport(df)prof.to_file(output_file="output.html")
Informe de elaboración de perfiles:
El informe de elaboración de perfiles consta de cinco partes: descripción general, variables, interacciones, correlación y valores perdidos.
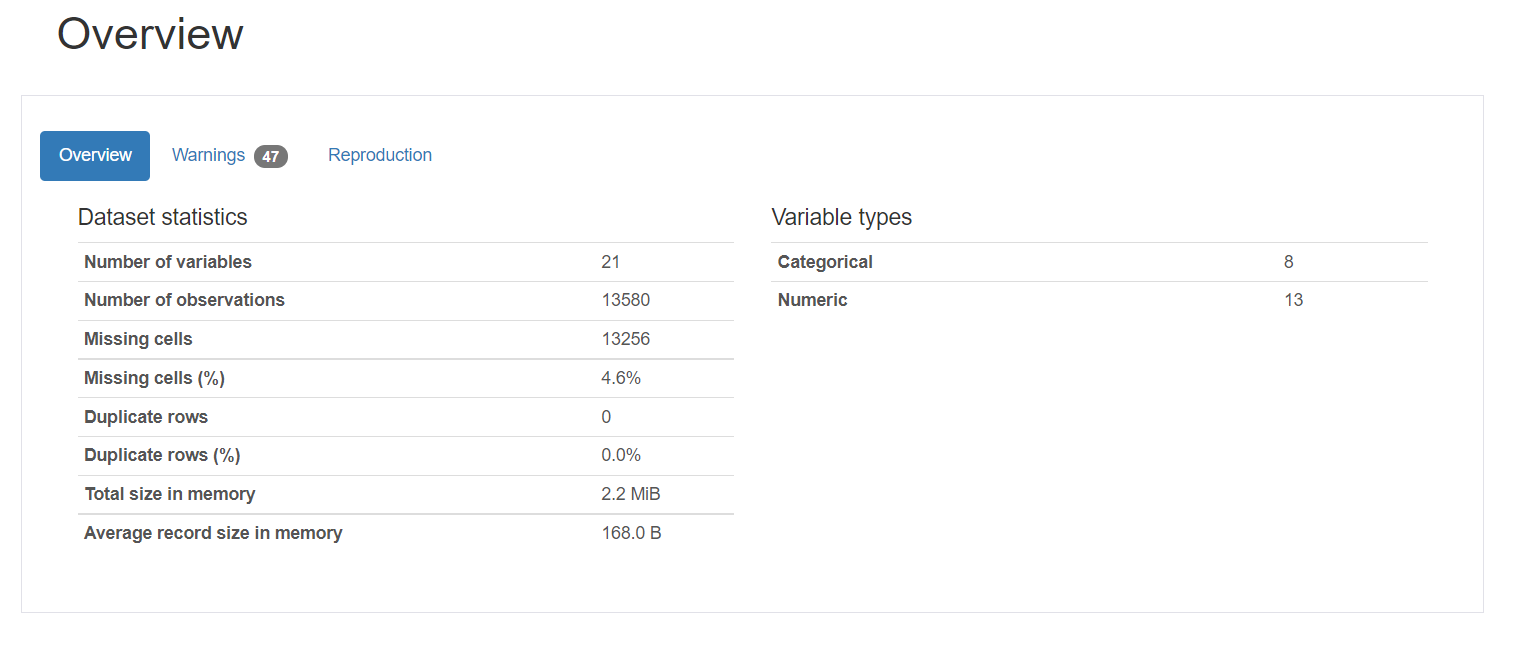
1. Descripción general proporciona las estadísticas generales sobre el número de variables, el número de observaciones, los valores perdidos, los duplicados y el número de variables categóricas y numéricas.
2. La información de la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... proporciona información detallada sobre los valores distintos, los valores perdidos, la media, la medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos...., etc. Aquí se muestran las estadísticas sobre una variable categórica y una variable numérica:
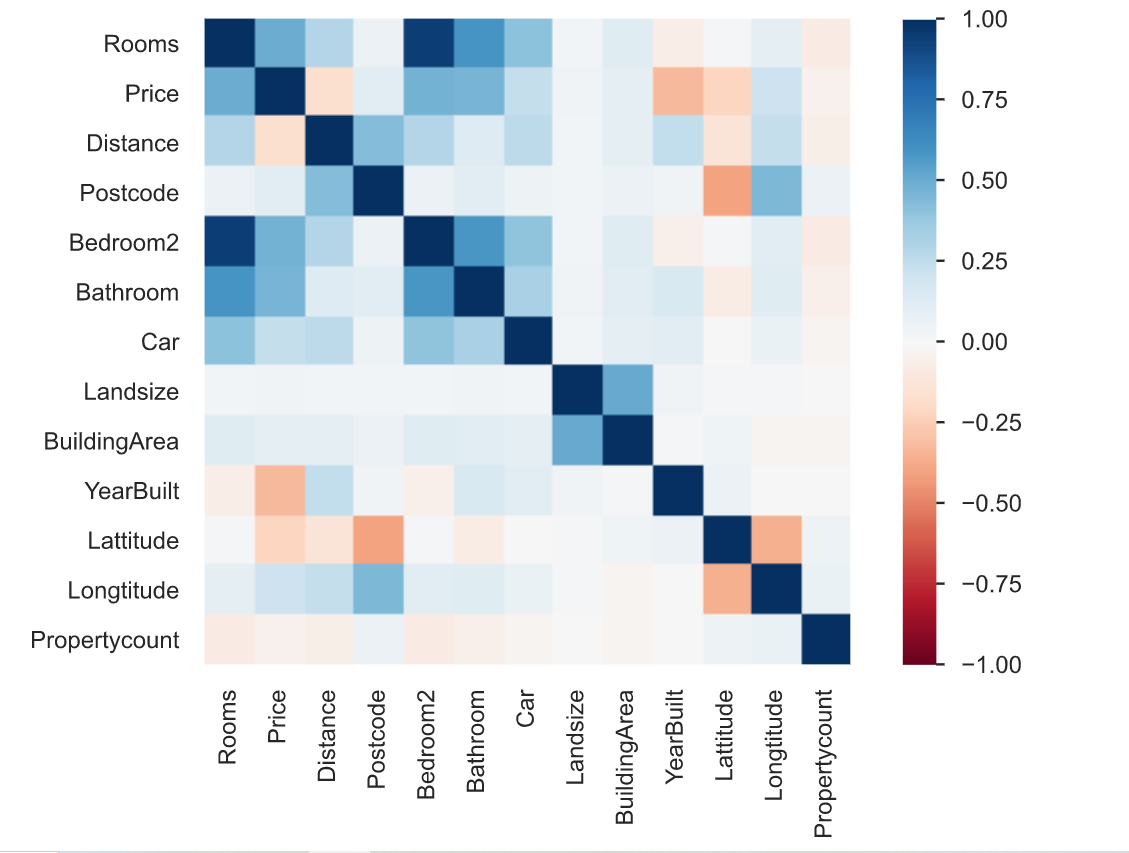
3. La correlación se define como el grado en que dos variables están relacionadas entre sí. El informe de elaboración de perfiles describe la correlación de diferentes variables entre sí en forma de mapa de calor.
Interacciones: esta parte del informe muestra las interacciones de las variables entre sí. Puede seleccionar cualquier variable en los ejes respectivos.
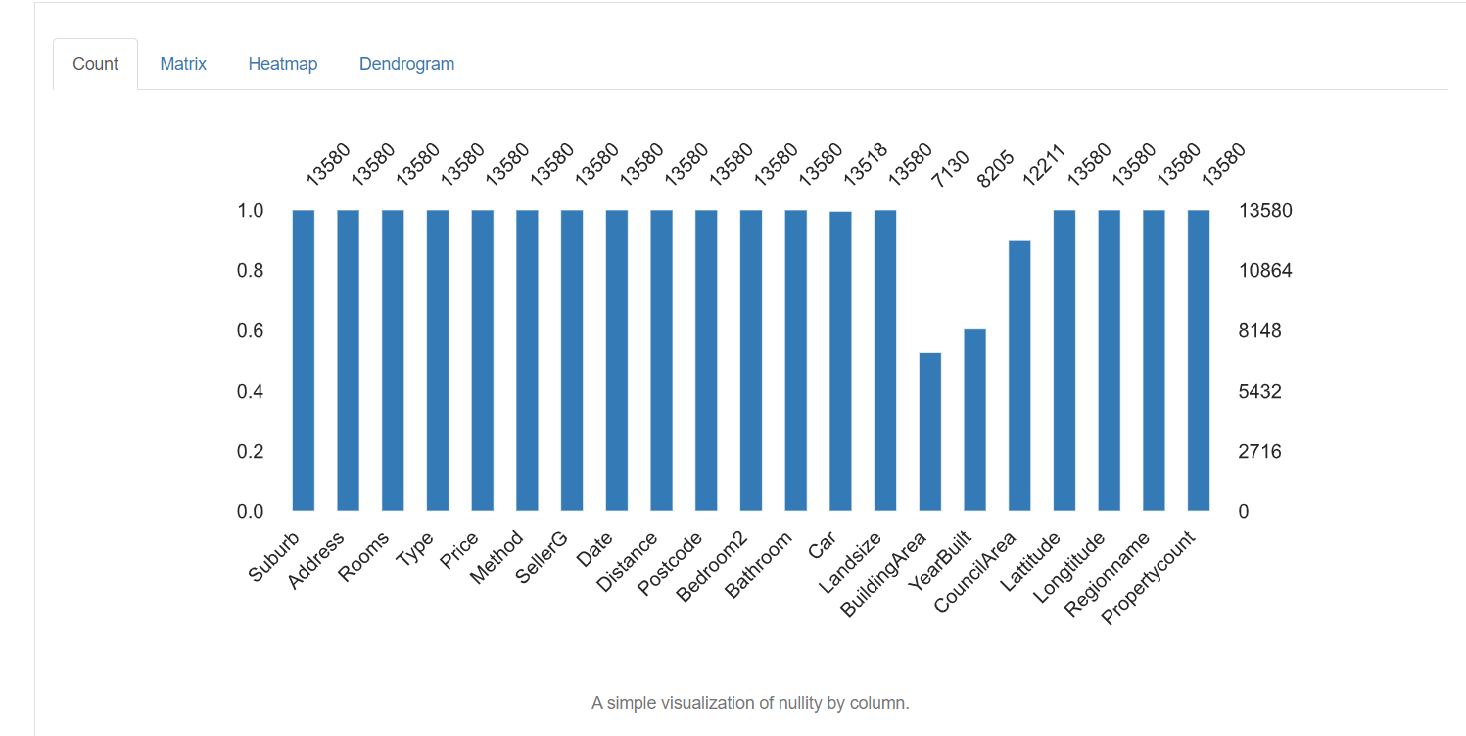
5. Valores perdidos: representa el número de valores perdidos en cada columna.
Técnicas de limpieza de datos
Ahora tenemos un conocimiento detallado sobre los datos faltantes, los valores incorrectos y las categorías mal etiquetadas del conjunto de datos. Ahora veremos algunas de las técnicas utilizadas para limpiar datos. Depende totalmente de la calidad del conjunto de datos, los resultados que se obtendrán de cómo maneja sus datos. Algunas de las técnicas son las siguientes:
Manejo de valores perdidos:
Manejar los valores perdidos es el paso más importante de la limpieza de datos. La primera pregunta que debe hacerse es ¿por qué faltan los datos? ¿Falta solo porque el operador de entrada de datos no lo registró o se dejó vacío intencionalmente? También puede revisar la documentación para encontrar el motivo del mismo.
Hay diferentes formas de manejar estos valores perdidos:
1. Eliminar los valores perdidos: La forma más fácil de manejarlos es simplemente eliminar todas las filas que contienen valores faltantes. Si no desea averiguar por qué faltan los valores y solo tiene un pequeño porcentaje de valores perdidos, puede eliminarlos usando el siguiente comando:
Sin embargo, no es aconsejable porque todos los datos son importantes y tienen una gran importancia para los resultados generales. Por lo general, el porcentaje de entradas que faltan en una columna en particular es alto. Así que dejarlo no es una buena opción.
2. Imputación: La imputación es el proceso de reemplazar los valores nulos / perdidos por algún valor. Para las columnas numéricas, una opción es reemplazar cada entrada que falta en la columna con el valor medio o el valor mediano. Otra opción podría ser generar números aleatorios entre un rango de valores adecuados para la columna. El rango podría estar entre la desviación media y estándar de la columna. Simplemente puede importar un imputador del paquete scikit-learn y realizar la imputación de la siguiente manera:
from sklearn.impute import SimpleImputer
#Imputation
my_imputer = SimpleImputer()
imputed_df = pd.DataFrame(my_imputer.fit_transform(df))Manejo de duplicados:
Las filas duplicadas ocurren generalmente cuando los datos se combinan de múltiples fuentes. A veces se replica. Un problema común es cuando los usuarios tienen el mismo número de identidad o el formulario se ha enviado dos veces.
La solución a estas tuplas duplicadas es simplemente eliminarlas. Puede utilizar la función unique () para averiguar los valores únicos presentes en la columna y luego decidir qué valores deben eliminarse.
Codificación:
La codificación de caracteres se define como el conjunto de reglas definidas para el mapeo uno a uno de cadenas de bytes binarios sin procesar a cadenas de texto legibles por humanos. Hay varias codificaciones disponibles: ASCII, utf-8, US-ASCII, utf-16, utf-32, etc.
Puede observar que algunos de los campos de caracteres de texto tienen patrones irregulares e irreconocibles. Esto se debe a que utf-8 es la codificación de Python predeterminada. Todo el código está en utf-8. Por lo tanto, cuando los datos provienen de múltiples fuentes estructuradas y no estructuradas y se guardan en un lugar común, se observan patrones irregulares en el texto.
La solución al problema anterior es averiguar primero la codificación de caracteres del archivo con la ayuda del módulo chardet en Python de la siguiente manera:
import chardetwith open("C:/Users/Desktop/Dataset/housing.csv",'rb') as rawdata:result = chardet.detect(rawdata.read(10000))# check what the character encoding might beprint(result)
Después de encontrar el tipo de codificación, si es diferente de utf-8, guarde el archivo usando la codificación «utf-8» usando el siguiente comando.
df.to_csv("C:/Users/Desktop/Dataset/housing.csv")Escalado y normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos....
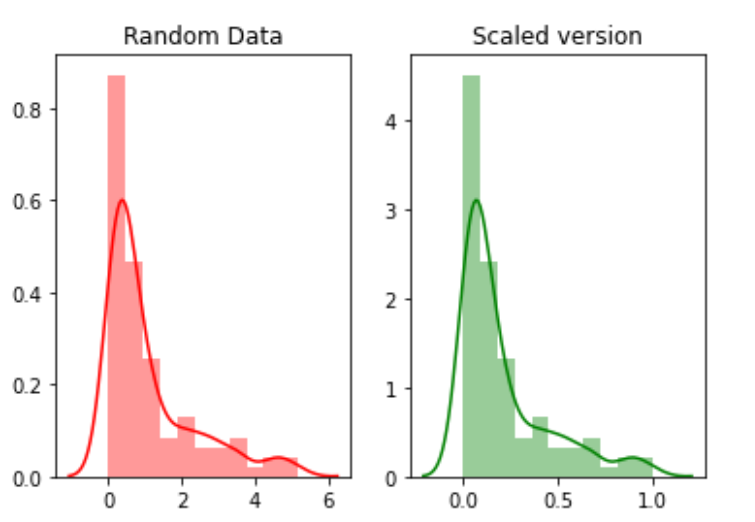
La escala se refiere a transformar el rango de datos y cambiarlo a algún otro rango de valores. Esto es beneficioso cuando queremos comparar diferentes atributos sobre la misma base. Un ejemplo útil podría ser la conversión de moneda.
Por ejemplo, crearemos 100 puntos aleatorios a partir de una distribución exponencial y luego los trazaremos. Finalmente, los convertiremos a una versión escalada usando el paquete python mlxtend.
# for min_max scalingfrom mlxtend.preprocessing import minmax_scaling# plotting packagesimport seaborn as snsimport matplotlib.pyplot as plt
Ahora escalando los valores:
random_data = np.random.exponential(size=100)# mix-max scale the data between 0 and 1scaled_version = minmax_scaling(random_data, columns=[0])
Finalmente, graficando las dos versiones.
La normalización se refiere a cambiar la distribución de los datos para que pueda representar una curva de campana donde los valores del atributo se distribuyen por igual en la media. El valor de la media y la mediana es el mismo. Este tipo de distribución también se denomina distribución gaussiana. Es necesario para aquellos algoritmos de aprendizaje automático que asumen que los datos se distribuyen normalmente.
Ahora, normalizaremos los datos usando la función boxcox:
from scipy import statsnormalized_data = stats.boxcox(random_data)# plot both together to comparefig,ax=plt.subplots(1,2)sns.distplot(random_data, ax=ax[0],color="pink")ax[0].set_title("Random Data")sns.distplot(normalized_data[0], ax=ax[1],color="purple")ax[1].set_title("Normalized data")
Manejo de fechas
El campo de fecha es un atributo importante que debe manejarse durante la limpieza de datos. Hay varios formatos diferentes en los que se pueden ingresar datos en el conjunto de datos. Por lo tanto, estandarizar la columna de la fecha es una tarea crítica. Algunas personas pueden haber tratado la fecha como una columna de cadena, otras como una columna DateTime. Cuando el conjunto de datos se combina de diferentes fuentes, esto puede crear un problema para el análisis.
La solución es encontrar primero el tipo de columna de fecha usando el siguiente comando.
df['Date'].dtype
Si el tipo de columna es diferente a DateTime, conviértalo a DateTime usando el siguiente comando:
import datetimedf['Date_parsed'] = pd.to_datetime(df['Date'], format="%m/%d/%y")
Manejo de problemas de entrada de datos inconsistentes
Hay una gran cantidad de entradas inconsistentes que no se pueden encontrar manualmente o mediante cálculos directos. Por ejemplo, si la misma entrada está escrita en mayúsculas o minúsculas o una mezcla de mayúsculas y minúsculas. Entonces, dicha entrada debe estandarizarse en toda la columna.
Una solución es convertir todas las entradas de una columna a minúsculas y recortar el espacio extra de cada entrada. Esto se puede revertir más tarde una vez que se complete el análisis.
# convert to lower casedf['ReginonName'] = df['ReginonName'].str.lower()# remove trailing white spacesdf['ReginonName'] = df['ReginonName'].str.strip()
Otra solución es utilizar la coincidencia aproximada para encontrar qué cadenas de la columna están más cercanas entre sí y luego reemplazar todas esas entradas con un umbral particular con la entrada principal.
En primer lugar, descubriremos los nombres únicos de las regiones:
region = df['Regionname'].unique()Luego calculamos los puntajes usando la coincidencia aproximada:
import fuzzywuzzyfromfuzzywuzzy import processregions=fuzzywuzzy.process.extract("WesternVictoria",region,limit=10,scorer=fuzzywuzy.fuzz.token_sort_ratio)

Validando el proceso.
Una vez que haya finalizado el proceso de limpieza de datos, es importante verificar y validar que los cambios que ha realizado no hayan obstaculizado las restricciones impuestas al conjunto de datos.
Y finalmente, … no hace falta decir,
¡Gracias por leer!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





