Introducción
¿Qué es la limpieza de datos? La eliminación de registros nulos, la eliminación de columnas innecesarias, el tratamiento de valores perdidos, la rectificación de valores no deseados o valores atípicos, la reestructuración de los datos para editarlos a un formato más legible, etc., se conoce como limpieza de datos.

Uno de los ejemplos de limpieza de datos más comunes es su aplicación en almacenes de datos. Un almacén de datos almacena una gama de datos de numerosas fuentes y los optimiza para su análisis antes de que se pueda llevar a cabo cualquier ajuste de modelo.
La limpieza de datos no es solo eliminar la información existente para agregar la nueva información, sino hallar una manera de maximizar la precisión de un conjunto de datos sin renunciar necesariamente la información existente. Los diferentes tipos de datos requerirán diferentes tipos de limpieza, pero recuerde siempre que el enfoque correcto es el factor decisivo.
Después de limpiar los datos, se volverá consistente con otros conjuntos de datos similares en el sistema.. Veamos los pasos para limpiar los datos;
Borrar registros nulos / duplicados
Si en una fila en particular falta una cantidad significativa de datos, entonces sería mejor borrar esa fila, puesto que no agregaría ningún valor a nuestro modelo. puede imputar el valor; proporcionar un sustituto apropiado para los datos faltantes. Además recuerde siempre borrar los valores duplicados / redundantes de su conjunto de datos, puesto que podrían resultar en un sesgo en su modelo.
A modo de ejemplo, consideremos el conjunto de datos del estudiante con los siguientes registros.
| nombre | puntaje | Dirección | altura | peso |
| A | 56 | Ir a | 165 | 56 |
| B | 45 | Bombay | 3 | sesenta y cinco |
| C | 87 | Delhi | 170 | 58 |
| D | ||||
| mi | 99 | Mysore | 167 | 60 |
Como vemos que corresponde al nombre del estudiante «D», falta la mayoría de los datos, por eso, descartamos esa fila en particular.
student_df.dropna() # drops rows with 1 or more Nan value
#producción
| nombre | puntaje | Dirección | altura | peso |
| A | 56 | Ir a | 165 | 56 |
| B | 45 | Bombay | 3 | sesenta y cinco |
| C | 87 | Delhi | 170 | 58 |
| mi | 99 | Mysore | 167 | 60 |
Borrar columnas innecesarias
Cuando recibimos los datos de las partes interesadas, de forma general es enorme. Puede haber un registro de datos que podría no agregar ningún valor a nuestro modelo. Es mejor borrar estos datos, puesto que lo haría con recursos valiosos como la memoria y el tiempo de procesamiento.
A modo de ejemplo, al observar el desempeño de los estudiantes en una prueba, el peso o la altura de los estudiantes no disponen nada que aportar al modelo.
student_df.drop(['height','weight'], axis = 1,inplace=True) #Drops Height column form the dataframe
#Producción
| nombre | puntaje | Dirección |
| A | 56 | Ir a |
| B | 45 | Bombay |
| C | 87 | Delhi |
| mi | 99 | Mysore |
Cambiar el nombre de las columnas
Siempre es mejor cambiar el nombre de las columnas y formatearlas al formato más legible que puedan comprender tanto el científico de datos como la compañía. A modo de ejemplo, en el conjunto de datos de los estudiantes, cambiar el nombre de la columna «nombre» como «Sudent_Name» hace que tenga sentido.
student_df.rename(columns={'name': 'Student_Name'}, inplace=True) #renames name column to Student_Name
#Producción
| Nombre del estudiante | puntaje | Dirección |
| A | 56 | Ir a |
| B | 45 | Bombay |
| C | 87 | Delhi |
| mi | 99 | Mysore |
Tratar los valores perdidos
Hay muchas alternativas para cuidar los valores perdidos en un conjunto de datos. Depende del científico de datos y del conjunto de datos en mano seleccionar el método más apropiado. Los métodos más utilizados son la imputación del conjunto de datos con media, medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... o moda. La eliminación de esos registros particulares con uno o más valores faltantes y, en algunos casos, la creación de algoritmos de aprendizaje automático como la regresión lineal y K vecino más cercano además se utiliza para tratar los valores faltantes.
| Nombre del estudiante | puntaje | Dirección |
| A | 56 | Ir a |
| B | 45 | Bombay |
| C | Delhi | |
| mi | 99 | Mysore |
Student_df['col_name'].fillna((Student_df['col_name'].mean()), inplace=True) # Na values in col_name is replaced with mean
#Producción
| Nombre del estudiante | puntaje | Dirección |
| A | 96 | Ir a |
| B | 45 | Bombay |
| C | 66 | Delhi |
| mi | 99 | Mysore |
Detección de valores atípicos
Los valores atípicos se pueden considerar como ruido en el conjunto de datos. Puede haber varios motivos para los valores atípicos, como error de entrada de datos, error manual, error experimental, etc.
A modo de ejemplo, en el siguiente ejemplo, el puntaje del estudiante «B» se ingresa 130, lo cual claramente no es correcto.
| Nombre del estudiante | puntaje | Dirección | altura | peso |
| A | 56 | Ir a | 165 | 56 |
| B | 45 | Bombay | 3 | sesenta y cinco |
| C | 66 | Delhi | 170 | 58 |
| mi | 99 | Mysore | 167 | 60 |
Trazar la altura en un diagrama de caja da el siguiente resultado
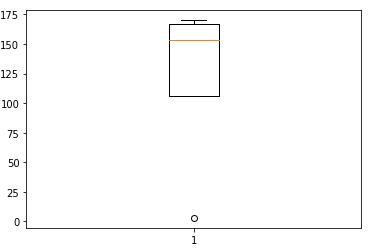
No todos los valores extremos son valores atípicos, algunos además pueden conducir a descubrimientos interesantes, pero ese es un tema para otro día. Se pueden utilizar pruebas como la prueba de puntuación Z, el diagrama de caja o simplemente trazar los datos en el gráfico revelará los valores atípicos.
Reformar / reestructurar los datos
La mayoría de los datos comerciales proporcionados al científico de datos no están en el formato más legible. Es nuestro trabajo remodelar los datos y llevarlos al formato que se pueda usar para el análisis. A modo de ejemplo, creando una nueva variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... a partir de las variables existentes o combinando 2 o más variables.
Notas al pie
Ciertamente, existen numerosas ventajas de trabajar con datos limpios, pocas de las cuales son la precisión mejorada de los modelos, una mejor toma de decisiones por parte de las partes interesadas, la facilidad de implementación del modelo y el ajuste de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto...., ahorro de tiempo y recursos, y muchas más. Recuerde siempre limpiar los datos como el primer y más importante paso antes de ajustar cualquier modelo.
Referencias
https://www.geeksforgeeks.org/
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





