Introducción
R es uno de los lenguajes de programación más famosos para el análisis estadístico y la computación. Debido a que proporciona una gran cantidad de funciones, los investigadores y científicos de datos lo utilizan para ciencia de datos y aprendizaje automático. Algunas de estas características incluyen bibliotecas de visualización interactivas, rápidas y de código abierto, ejecución de código sin compilador, buena comunidad y muchas más.
Una de las principales razones por las que se está volviendo muy famoso es la gran cantidad de paquetes R para proyectos de ciencia de datos, aprendizaje automático e inteligencia artificial. Al usar estos paquetes, se pueden desarrollar modelos predictivos de manera fácil y eficiente. Este blog enumera los 10 paquetes R principales que debe conocer en 2021 para ciencia de datos y aprendizaje automático.

Tabla de contenido
- Dplyr
- ggplot2
- KernLab
- Explorador de datos
- Signo de intercalación
- randomForest
- Brillante
- mboost
- Plotly
- SuperML
Dplyr
Es uno de los paquetes R más utilizados para tareas de ciencia de datos y aprendizaje automático. Este paquete está escrito por Hadley Wickham. Se utiliza para resolver tareas de manipulación de datos. Tiene un conjunto de funciones para la manipulación de datos. También se denomina gramática de manipulación de datos. Tiene un conjunto de verbos que nos ayudan a resolver las tareas de manipulación de datos más desafiantes como mutar (), seleccionar (), filtrar (), resumir (), organizar ().
Para instalar este paquete, use el siguiente código:
install.packages('dplyr')


Para obtener más información, consulte el siguiente enlace: Introducción a dplyr
ggplot2
Uno de los paquetes R más populares y ampliamente utilizados para la visualización de datos y el análisis exploratorio de datos. Puede crear visualizaciones de datos interactivas con este paquete. Proporciona una amplia gama de bonitas tramas que se ocupan de los detalles minuciosos y dibujan leyendas. Este paquete funciona bajo una gramática profunda llamada «Gramática de gráficos». Proporciona una amplia gama de gráficos como gráficos de dispersión y gráficos de burbujas. Los diagramas de fluctuación son gráficos, histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas...., diagramas de densidad, diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos...., diagramas de violín, dendrogramas y muchos más.
Para instalar este paquete, use el siguiente código:
install.packages('gglpot2')
A continuación se muestran algunos ejemplos de parcelas que utilizan este paquete:
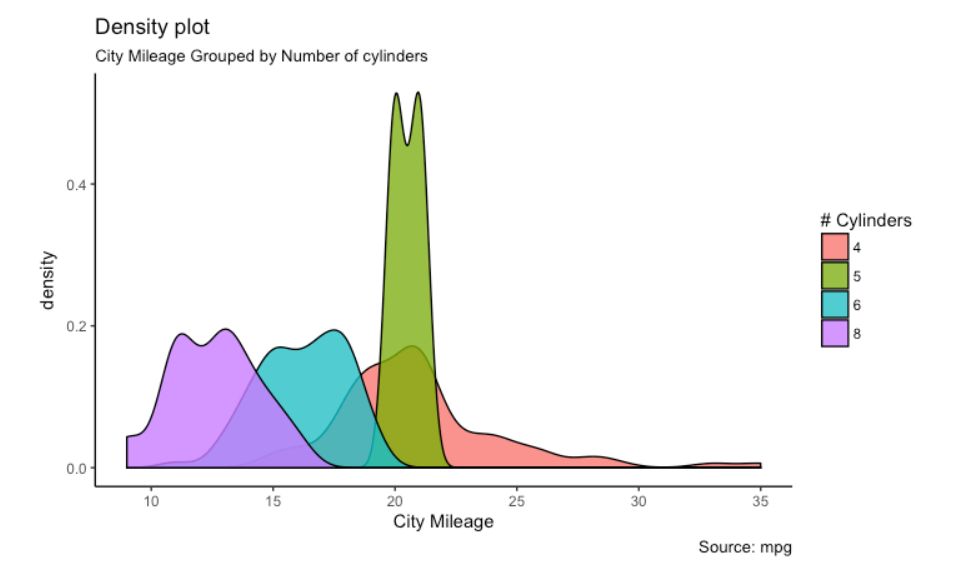

Para obtener más información, consulte el siguiente enlace: ggplot2
KernLab
Este paquete también se denomina laboratorio de aprendizaje automático basado en kernel. Este paquete se utiliza para regresión, clasificación, reducción de dimensionalidad, detección de anomalías, agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo.... Si desea utilizar algoritmos que impliquen un enfoque basado en el kernel, puede usarlo como SVM, algoritmo de clasificación, análisis de características del kernel y muchos más. Es ampliamente utilizado para implementaciones de SVM. Tiene una amplia gama de funciones de kernel, como para la función de kernel polinomial, podemos usar polydot (), la función de kernel tangente hiperbólica para tanhdot (), etc.
Para instalar este paquete, use el siguiente código:
install.packages('kernlab')
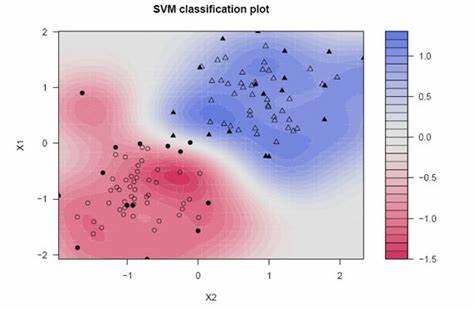
Para obtener más información, consulte el siguiente enlace: Paquete kernlab
Explorador de datos
Este paquete R es uno de los más fáciles de usar para ciencia de datos y aprendizaje automático. Este paquete se centra principalmente en tres objetivos:
- Análisis exploratorio de datos
- Ingeniería de funciones
- Informe de datos
Este paquete automatizó el análisis de datos exploratorios para tareas de análisis y modelado predictivo al visualizar cada característica presente en nuestro conjunto de datos.
Para instalar este paquete, use el siguiente código:
install.packages('DataExplorer')
Para encontrar una descripción general amplia de nuestro conjunto de datos, podemos usar el siguiente código:
introduce(data)
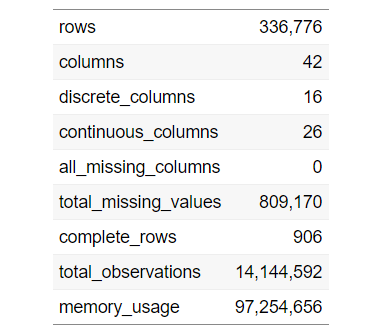
Para visualizar la tabla anterior, use el siguiente código:
plot_intro(data)
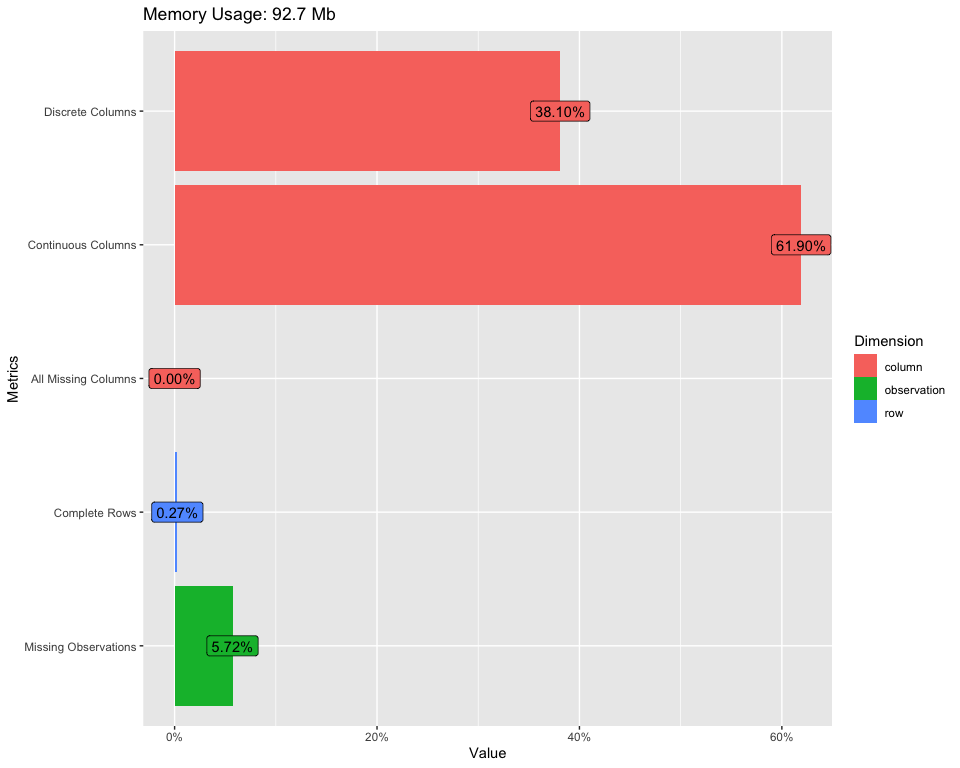
Para obtener más información, consulte el siguiente enlace: Introducción a DataExplorer
Signo de intercalación
Esto también se llama entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... de clasificación y regresión. Es uno de los mejores paquetes para tareas de ciencia de datos y aprendizaje automático. Contiene un conjunto de funciones que se utilizan para crear modelos predictivos. Tiene otras funcionalidades, así como selección de características, división de datos, preprocesamiento de datos, ajuste de modelos, importancia de características y muchas más.
Para instalar este paquete, use el siguiente código:
install.packages('caret')
Para obtener más información, consulte el siguiente enlace: Caret del paquete
randomForest
Random Forest es uno de los paquetes más populares de R para el aprendizaje automático. Este paquete se utiliza para crear bosques aleatorios en R. Se puede utilizar tanto para tareas de clasificación como de regresión. También podemos usarlo para entrenar valores perdidos y valores atípicos. Este paquete utiliza el algoritmo de bosque aleatorio de Breiman para construir árboles de decisión.
Para encontrar una descripción general amplia de nuestro conjunto de datos, podemos usar el siguiente código:
install.packages('randomForest')
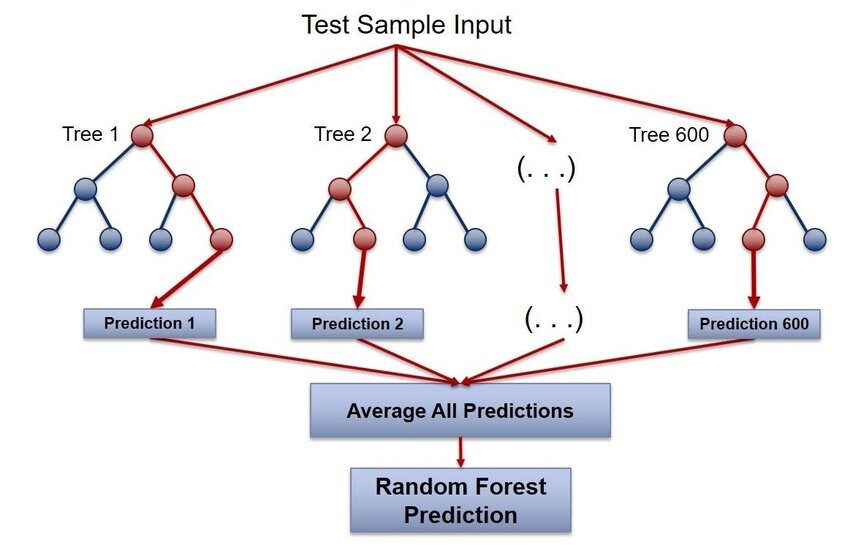
Para obtener más información, consulte el siguiente enlace: Bosque aleatorio
Brillante

Es un paquete R que se utiliza para crear una aplicación web interactiva para la ciencia de datos. Nos ayuda a crear aplicaciones web R sin mucho esfuerzo. Shiny crea aplicaciones web que se implementan en la web utilizando su servidor o los servicios de alojamiento de R shiny. Las características de R shiny incluyen crear una aplicación con menos conocimiento de herramientas web, proporciona visualizaciones en vivo, funciones de renderizado y muchas más.
Ejemplo de aplicación web con shiny:
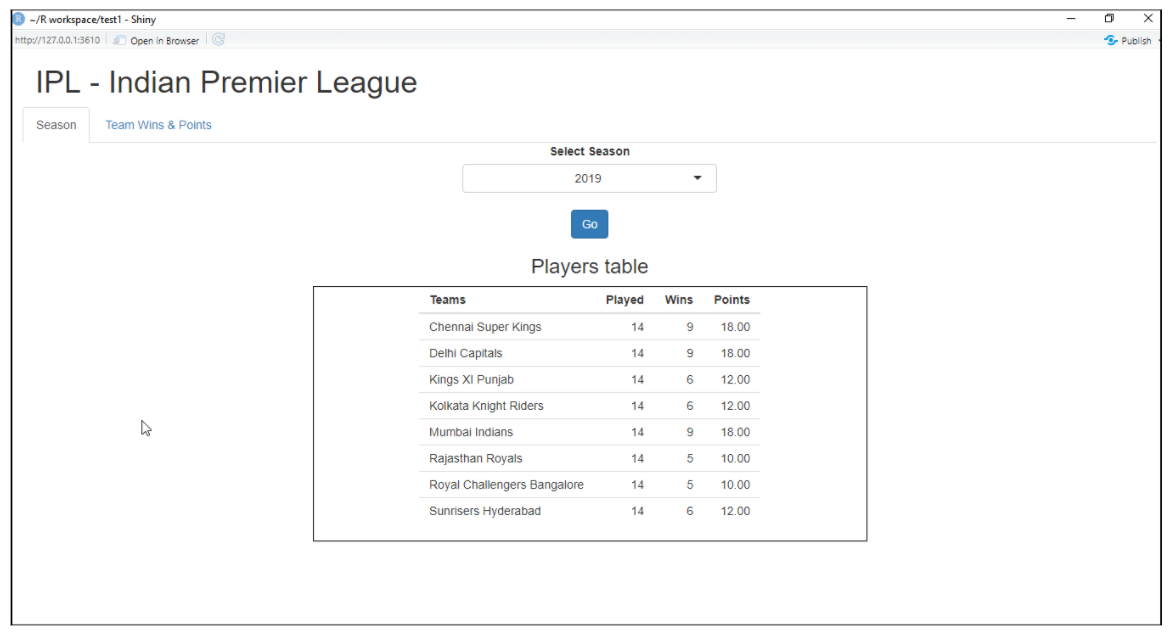
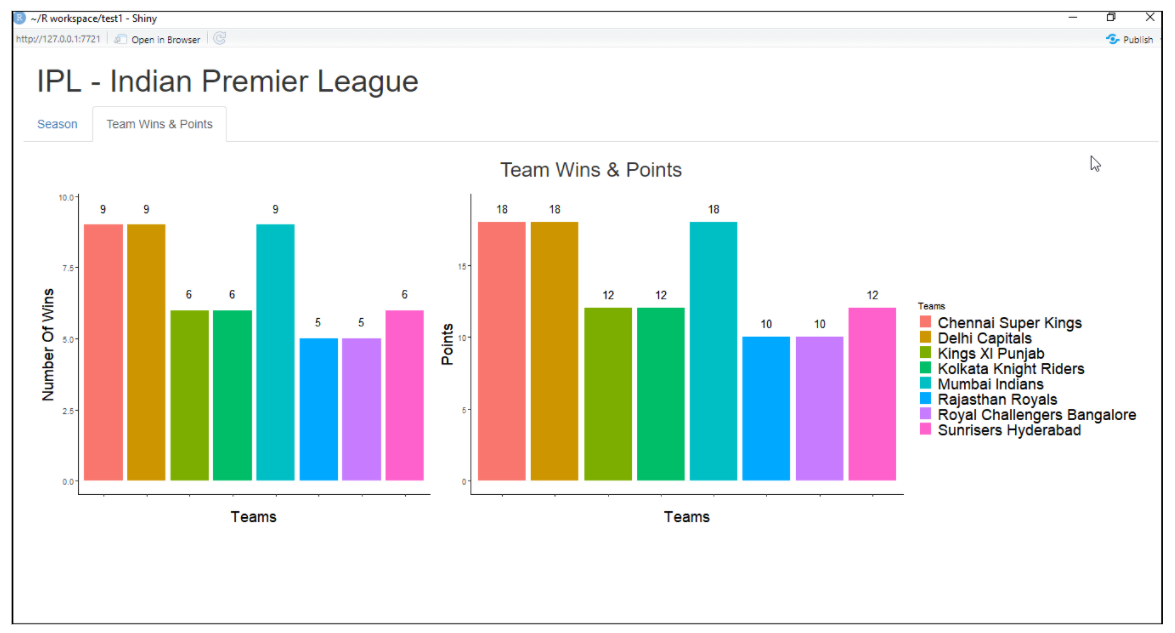
Para obtener más información, consulte el siguiente enlace: Brillante
mboost
Este paquete se utiliza en ciencia de datos para paquetes de impulso basados en modelos y tiene un algoritmo funcional de descenso de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... para optimizar los árboles de decisión. También proporciona un modelo de interacción para datos potencialmente de alta dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y....
Para instalar este paquete, use el siguiente código:
install.packages('mboost')
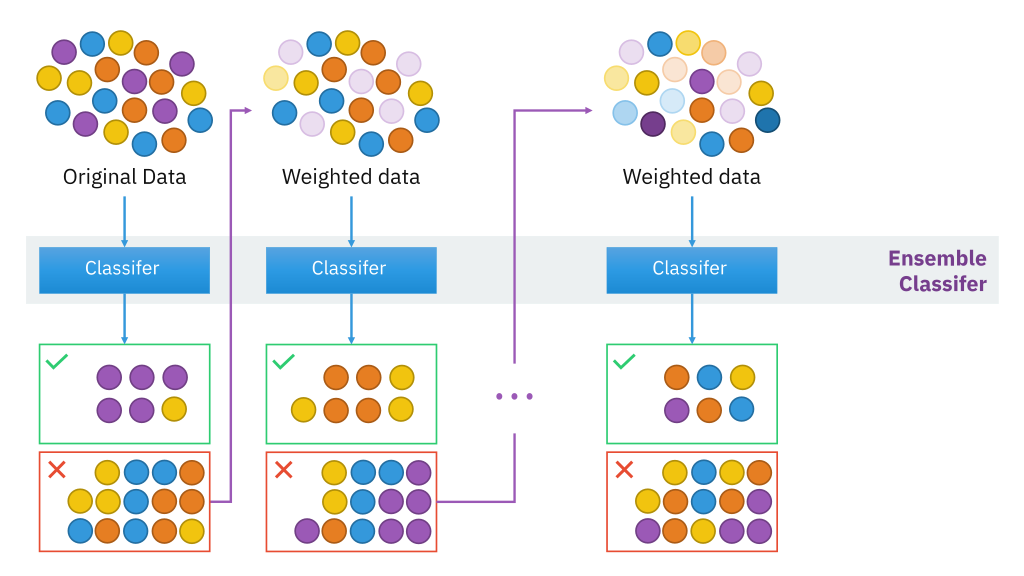
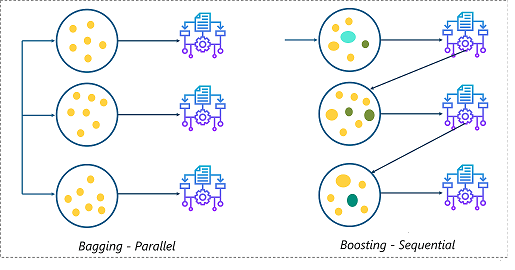
Para obtener más información, consulte el siguiente enlace: mboost
Plotly
Es una biblioteca de gráficos que crea gráficos interactivos. Es una interfaz de alto nivel para plotly.js, basada en d3.js. Proporciona una interfaz de usuario fácil de usar para generar elegantes gráficos interactivos D3. Estos gráficos interactivos brindan muchas funcionalidades, como la capacidad de acercar y alejar los gráficos, pasar el cursor sobre un punto para obtener información adicional, filtrar datos y mucho más.

Proporciona un ejemplo de gráficos como diagramas de dispersión, diagramas de líneas, diagramas de barras, carritos circulares, diagramas de burbujas, diagramas de caja, histogramas, barras de error, diagramas de violín y mucho más.
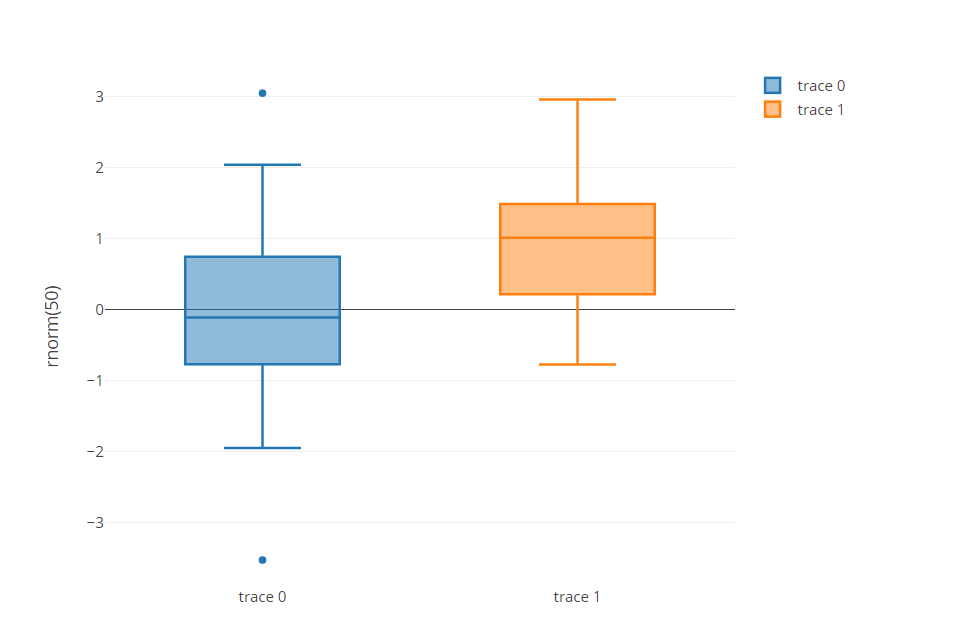
Para obtener más información, consulte el siguiente enlace: Plotly
SuperML
Superml es uno de los famosos paquetes de R para AI que brinda una interfaz estándar a los clientes que utilizan los dialectos de programación Python y R para construir modelos de AI. Este paquete esencialmente brinda los aspectos más destacados de Scikit Learn y predice la interfaz para preparar modelos de IA en R. Además de construir modelos de IA, existen funcionalidades convenientes para realizar ingeniería de funciones.
Para instalar este paquete, use el siguiente código:
install.packages('superml')
Para obtener más información, consulte el siguiente enlace: SuperML
Gracias por leer este artículo y por tu paciencia. Déjame en la sección de comentarios sobre comentarios. Comparta este artículo, me dará la motivación para escribir más blogs para la comunidad de ciencia de datos.
Gracias por leer esto. Si te gusta este artículo, compártelo con tus amigos. En caso de cualquier sugerencia / duda, comente a continuación.
Identificación de correo: [email protected]
Sígueme en LinkedIn: LinkedIn
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





