Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Imagínese entrar en una librería para comprar un libro sobre economía mundial y no poder averiguar la sección de la tienda que tiene este libro, asumiendo que la librería simplemente ha apilado todo tipo de libros. Entonces te das cuenta de lo importante que es dividir la librería en diferentes secciones según el tipo de libro.
El modelado de temas es similar a dividir una librería en función del contenido de los libros, ya que se refiere al proceso de descubrir temas en un corpus de texto y anotar los documentos en función de los temas identificados.
Cuando necesite segmentar, comprender y resumir una gran colección de documentos, el modelado de temas puede resultar útil.
Modelado de temas usando LDA:
La asignación de Dirichlet latente (LDA) es una de las formas de implementar el modelado de temas. Es un modelo probabilístico generativo en el que se supone que cada documento consta de una proporción diferente de temas.
¿Cómo funciona el algoritmo LDA?
Los siguientes pasos se realizan en LDA para asignar temas a cada uno de los documentos:
1) Para cada documento, inicialice aleatoriamente cada palabra a un tema entre los K temas donde K es el número de temas predefinidos.
2) Para cada documento d:
Para cada palabra w en el documento, calcule:
- P (tema t | documento d): Proporción de palabras en el documento d que se asignan al tema t
- P (palabra w | tema t): Proporción de asignaciones al tema t en todos los documentos de palabras que provienen de w
3) Reasignar el tema T ‘a la palabra w con probabilidad p (t’ | d) * p (w | t ‘) considerando todas las demás palabras y sus asignaciones de temas
El último paso se repite varias veces hasta que alcanzamos un estado estable en el que las asignaciones de temas no cambian más. La proporción de temas para cada documento se determina a partir de estas asignaciones de temas.
Ejemplo ilustrativo de LDA:
Digamos que tenemos los siguientes 4 documentos como corpus y deseamos realizar un modelado de temas sobre estos documentos.
Documento 1: Vemos muchos videos en YouTube.
Documento 2: Los videos de YouTube son muy informativos.
Documento 3: Leer un blog técnico me hace entender las cosas fácilmente.
Documento 4: Prefiero los blogs a los videos de YouTube.
El modelado LDA nos ayuda a descubrir temas en el corpus anterior y a asignar mezclas de temas para cada uno de los documentos. Como ejemplo, el modelo podría generar algo como se indica a continuación:
Tema 1: 40% videos, 60% YouTube
Tema 2: 95% blogs, 5% YouTube
Los documentos 1 y 2 pertenecerían entonces al 100% al Tema 1. El Documento 3 pertenecería al 100% al Tema 2. El Documento 4 pertenecería al 80% al Tema 2 y el 20% al Tema 1.
Esta asignación de temas a documentos se realiza mediante el modelado LDA siguiendo los pasos que comentamos en la sección anterior. Apliquemos ahora LDA a algunos datos de texto y analicemos los resultados reales en Python.
Modelado de temas usando LDA en Python:
Hemos tomado los datos de ‘Amazon Fine Food Reviews’ de Kaggle (https://www.kaggle.com/snap/amazon-fine-food-reviews) aquí para ilustrar cómo podemos implementar el modelado de temas usando LDA en Python.
Leyendo los datos:
Comenzamos importando la biblioteca de Pandas para leer el CSV y guardarlo en un marco de datos.
import pandas as pd rev = pd.read_csv(r"Reviews.csv") rev.head()
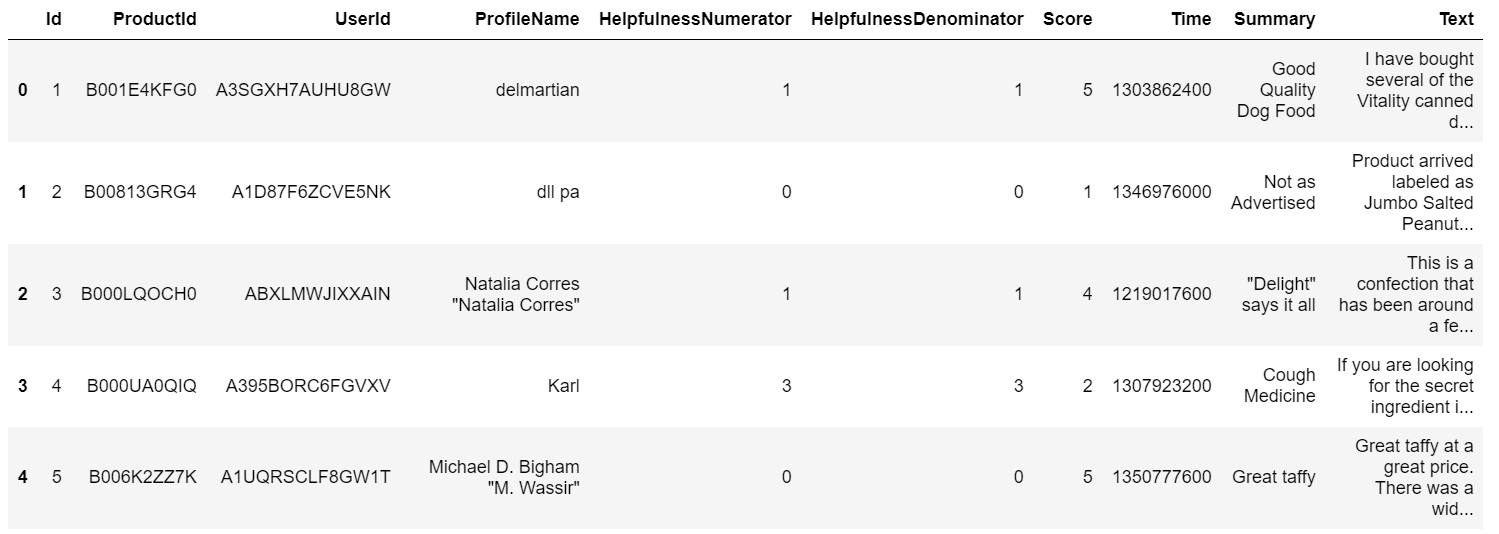
Estamos interesados en realizar un modelado de temas para la columna ‘Texto’ en este conjunto de datos.
Importando las bibliotecas necesarias:
Necesitaremos importar la biblioteca NLTK ya que usaremos la lematización para el preprocesamiento. Además, también eliminaríamos las palabras vacías antes de realizar el LDA. Para realizar el modelado de temas, necesitamos convertir nuestra columna de texto a una forma vectorizada y por lo tanto importamos el TfidfVectorizer.
import nltk
from nltk.corpus import stopwords #stopwords
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
stop_words=set(nltk.corpus.stopwords.words('english'))
Procesamiento previo del texto:
Aplicaremos lematización a las palabras para que se usen las palabras raíz de todas las palabras derivadas. Además, se eliminan las palabras vacías y se utilizan palabras con longitudes superiores a 3.
def clean_text(headline): le=WordNetLemmatizer() word_tokens=word_tokenize(headline) tokens=[le.lemmatize(w) for w in word_tokens if w not in stop_words and len(w)>3] cleaned_text=" ".join(tokens) return cleaned_text rev['cleaned_text']=rev['Text'].apply(clean_text)
Vectorización TFIDF en la columna de texto:
La realización de una vectorización TFIDF en la columna de texto nos proporciona una matriz de términos del documento sobre la que podemos realizar el modelado del tema. TFIDF se refiere a Frecuencia de Término Frecuencia Inversa de Documentos, ya que esta vectorización compara la cantidad de veces que una palabra aparece en un documento con la cantidad de documentos que la contienen.
vect =TfidfVectorizer(stop_words=stop_words,max_features=1000) vect_text=vect.fit_transform(rev['cleaned_text'])
LDA en el texto vectorizado:
Los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... que le hemos dado al modelo LDA, como se muestra a continuación, incluyen el número de temas, el método de aprendizaje (que es la forma en que el algoritmo actualiza las asignaciones de los temas a los documentos), el número máximo de iteraciones a realizar. out y el estado aleatorio. Los parámetros que le hemos dado al modelo LDA, como se muestra a continuación, incluyen el número de temas, el método de aprendizaje (que es la forma en que el algoritmo actualiza las asignaciones de los temas a los documentos), el número máximo de iteraciones a realizar. out y el estado aleatorio.
from sklearn.decomposition import LatentDirichletAllocation lda_model=LatentDirichletAllocation(n_components=10, learning_method='online',random_state=42,max_iter=1) lda_top=lda_model.fit_transform(vect_text)
Comprobando los resultados:
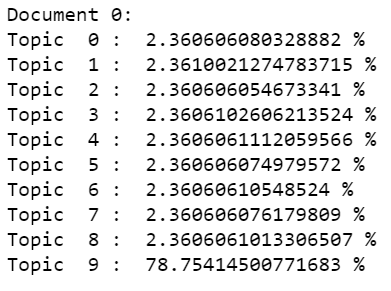
Podemos comprobar la proporción de temas que se han asignado al primer documento utilizando las líneas de código que se indican a continuación.
print("Document 0: ")
for i,topic in enumerate(lda_top[0]):
print("Topic ",i,": ",topic*100,"%")
Analizando los temas:
Veamos cuáles son las palabras principales que componen los temas. Esto nos daría una visión de lo que define cada uno de estos temas.
vocab = vect.get_feature_names()
for i, comp in enumerate(lda_model.components_):
vocab_comp = zip(vocab, comp)
sorted_words = sorted(vocab_comp, key= lambda x:x[1], reverse=True)[:10]
print("Topic "+str(i)+": ")
for t in sorted_words:
print(t[0],end=" ")
print("n")

Además de LDA, se pueden aprovechar otros algoritmos para realizar el modelado de temas. La indexación semántica latente (LSI), la factorización matricial no negativa son algunos de los otros algoritmos que se pueden intentar para realizar el modelado de temas. Todos estos algoritmos, como LDA, implican la extracción de características de las matrices de términos del documento y la generación de un grupo de términos que se diferencian entre sí, que eventualmente conducen a la creación de temas. Estos temas pueden ayudar a evaluar los temas principales de un corpus y, por lo tanto, a organizar grandes colecciones de datos textuales.
sobre el autor
Nibedita
completó su maestría en Ingeniería Química de IIT Kharagpur en 2014 y
actualmente trabaja como consultor senior en AbsolutData Analytics. En su
capacidad actual, trabaja en la creación de soluciones basadas en IA / ML para clientes de
una variedad de industrias.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





