El desafío de hacer que las máquinas entiendan el texto
«El lenguaje es un medio de comunicación maravilloso»
Tú y yo hubiéramos entendido esa frase en una fracción de segundo. Pero las máquinas simplemente no pueden procesar datos de texto en forma cruda. Necesitan que descompongamos el texto en un formato numérico que la máquina pueda leer fácilmente (la idea detrás Procesamiento natural del lenguaje!).
Aquí es donde entran en juego los conceptos de Bag-of-Words (BoW) y TF-IDF. Tanto BoW como TF-IDF son técnicas que nos ayudan a convertir frases de texto en vectores numéricos.
Hablaré de Bag-of-Words y TF-IDF en este artículo. Usaremos un ejemplo intuitivo y general para comprender cada concepto en detalle.
¿Es nuevo en el procesamiento del lenguaje natural (NLP)? Tenemos los cursos perfectos para que comiences:
Tomemos un ejemplo para comprender la bolsa de palabras (BoW) y TF-IDF
Tomaré un ejemplo popular para explicar Bag-of-Words (BoW) y TF-DF en este artículo.
A todos nos encanta ver películas (en distintos grados). Suelo mirar siempre las críticas de una película antes de comprometerme a verla. ¡Sé que muchos de ustedes hacen lo mismo! Entonces, usaré este ejemplo aquí.

Aquí hay una muestra de reseñas sobre una película de terror en particular:
- Revisión 1: esta película es muy aterradora y larga
- Revisión 2: esta película no da miedo y es lenta
- Revisión 3: esta película es espeluznante y buena
Puede ver que hay algunas críticas contrastantes sobre la película, así como la duración y el ritmo de la película. Imagínese mirar miles de reseñas como estas. Claramente, hay muchas ideas interesantes que podemos extraer de ellas y desarrollarlas para evaluar qué tan bien se desempeñó la película.
Sin embargo, como vimos anteriormente, no podemos simplemente dar estas oraciones a un modelo de aprendizaje automático y pedirle que nos diga si una revisión fue positiva o negativa. Necesitamos realizar ciertos pasos de preprocesamiento de texto.
Bag-of-Words y TF-IDF son dos ejemplos de cómo hacer esto. Entendamos en detalle.
Crear vectores a partir de texto
¿Puedes pensar en algunas técnicas que podríamos usar para vectorizar una oración al principio? Los requisitos básicos serían:
- No debería resultar en una matriz dispersa ya que las matrices dispersas resultan en un alto costo de cálculo
- Deberíamos poder retener la mayor parte de la información lingüística presente en la oración.
La incrustación de palabras es una de esas técnicas en las que podemos representar el texto mediante vectores. Las formas más populares de incrustaciones de palabras son:
- BoW, que significa Bolsa de palabras
- TF-IDF, que significa Frecuencia de término-Frecuencia de documento inversa
Ahora, veamos cómo podemos representar las reseñas de películas anteriores como incrustaciones y prepararlas para un modelo de aprendizaje automático.
Modelo de bolsa de palabras (BoW)
El modelo Bag of Words (BoW) es la forma más simple de representación de texto en números. Al igual que el término en sí, podemos representar una oración como un vector de bolsa de palabras (una cadena de números).
Recordemos los tres tipos de reseñas de películas que vimos anteriormente:
- Revisión 1: esta película es muy aterradora y larga
- Revisión 2: esta película no da miedo y es lenta
- Revisión 3: esta película es espeluznante y buena
Primero construiremos un vocabulario a partir de todas las palabras únicas en las tres revisiones anteriores. El vocabulario consta de estas 11 palabras: ‘Esta’, ‘película’, ‘es’, ‘muy’, ‘aterrador’, ‘y’, ‘largo’, ‘no’, ‘lento’, ‘espeluznante’, ‘bueno ‘.
Ahora podemos tomar cada una de estas palabras y marcar su aparición en las tres reseñas de películas anteriores con 1 y 0. Esto nos dará 3 vectores para 3 revisiones:
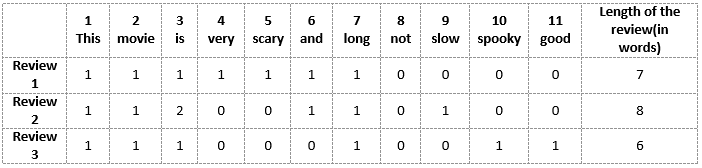
Vector de revisión 1: [1 1 1 1 1 1 1 0 0 0 0]
Vector de revisión 2: [1 1 2 0 0 1 1 0 1 0 0]
Vector de revisión 3: [1 1 1 0 0 0 1 0 0 1 1]
Y esa es la idea central detrás del modelo Bag of Words (BoW).
Inconvenientes de usar un modelo de bolsa de palabras (BoW)
En el ejemplo anterior, podemos tener vectores de longitud 11. Sin embargo, comenzamos a enfrentar problemas cuando encontramos nuevas oraciones:
- Si las nuevas oraciones contienen nuevas palabras, entonces el tamaño de nuestro vocabulario aumentaría y, por lo tanto, la longitud de los vectores también aumentaría.
- Además, los vectores también contendrían muchos ceros, lo que resultaría en una matriz escasa (que es lo que nos gustaría evitar)
- No retenemos información sobre la gramática de las oraciones ni sobre el orden de las palabras en el texto.
Término Frecuencia-Frecuencia inversa de documentos (TF-IDF)
Primero pongamos una definición formal en torno a TF-IDF. Así es como lo expresa Wikipedia:
«La frecuencia de los términos, la frecuencia inversa de los documentos, es una estadística numérica que pretende reflejar la importancia de una palabra para un documento en una colección o corpus».
Frecuencia de término (TF)
Primero entendamos Término frecuente (TF). Es una medida de la frecuencia con la que aparece un término, t, en un documento, d:
![]()
Aquí, en el numerador, n es el número de veces que aparece el término «t» en el documento «d». Por lo tanto, cada documento y término tendría su propio valor de TF.
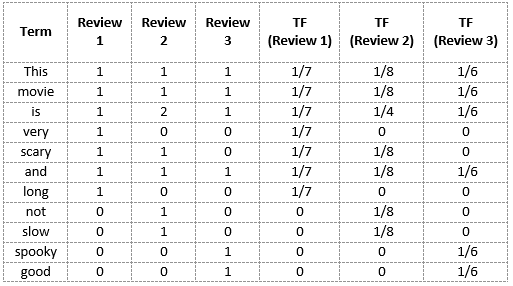
De nuevo usaremos el mismo vocabulario que habíamos construido en el modelo Bag-of-Words para mostrar cómo calcular el TF para la Revisión # 2:
Revisión 2: esta película no da miedo y es lenta
Aquí,
- Vocabulario: ‘Esta’, ‘película’, ‘es’, ‘muy’, ‘aterradora’, ‘y’, ‘larga’, ‘no’, ‘lenta’, ‘espeluznante’, ‘buena’
- Número de palabras en la Revisión 2 = 8
- TF para la palabra ‘esto’ = (número de veces que aparece ‘esto’ en la revisión 2) / (número de términos en la revisión 2) = 1/8
Similar,
- TF (‘película’) = 1/8
- TF (‘es’) = 2/8 = 1/4
- TF (‘muy’) = 0/8 = 0
- TF (‘aterrador’) = 1/8
- TF (‘y’) = 1/8
- TF (‘largo’) = 0/8 = 0
- TF (‘no’) = 1/8
- TF (‘lento’) = 1/8
- TF (‘espeluznante’) = 0/8 = 0
- TF (‘bueno’) = 0/8 = 0
Podemos calcular las frecuencias de términos para todos los términos y todas las revisiones de esta manera:
Frecuencia de documento inversa (IDF)
IDF es una medida de la importancia de un término. Necesitamos el valor IDF porque calcular solo el TF por sí solo no es suficiente para comprender la importancia de las palabras:
![]()
Podemos calcular los valores de IDF para todas las palabras de la Revisión 2:
IDF (‘esto’) = log (número de documentos / número de documentos que contienen la palabra ‘esto’) = log (3/3) = log (1) = 0
Similar,
- IDF (‘película’,) = log (3/3) = 0
- IDF (‘es’) = log (3/3) = 0
- IDF (‘no’) = log (3/1) = log (3) = 0.48
- IDF (‘aterrador’) = log (3/2) = 0.18
- IDF (‘y’) = log (3/3) = 0
- IDF (‘lento’) = log (3/1) = 0.48
Podemos calcular los valores IDF para cada palabra de esta manera. Por lo tanto, los valores de IDF para todo el vocabulario serían:
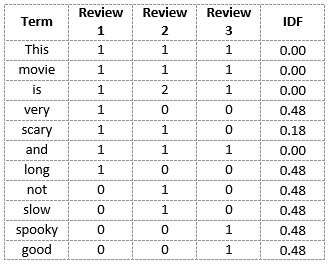
Por tanto, vemos que palabras como “es”, “esto”, “y”, etc., se reducen a 0 y tienen poca importancia; mientras que palabras como “aterrador”, “largo”, “bueno”, etc. son palabras con más importancia y por lo tanto tienen mayor valor.
Ahora podemos calcular la puntuación TF-IDF para cada palabra del corpus. Las palabras con una puntuación más alta son más importantes y las que tienen una puntuación más baja son menos importantes:
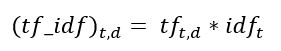
Ahora podemos calcular la puntuación TF-IDF para cada palabra en la Revisión 2:
TF-IDF (‘esto’, Revisión 2) = TF (‘esto’, Revisión 2) * IDF (‘esto’) = 1/8 * 0 = 0
Similar,
- TF-IDF (‘película’, Revisión 2) = 1/8 * 0 = 0
- TF-IDF (‘es’, Revisión 2) = 1/4 * 0 = 0
- TF-IDF (‘no’, Revisión 2) = 1/8 * 0.48 = 0.06
- TF-IDF (‘aterrador’, Revisión 2) = 1/8 * 0.18 = 0.023
- TF-IDF (‘y’, Revisión 2) = 1/8 * 0 = 0
- TF-IDF (‘lento’, Revisión 2) = 1/8 * 0.48 = 0.06
Del mismo modo, podemos calcular las puntuaciones TF-IDF para todas las palabras con respecto a todas las reseñas:
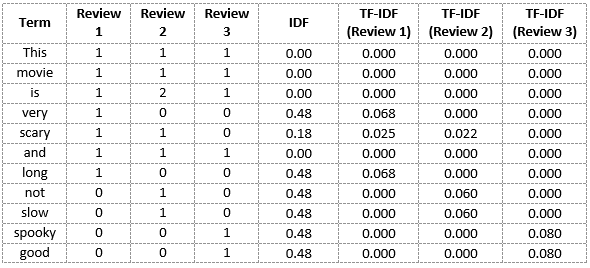
Ahora hemos obtenido las puntuaciones TF-IDF para nuestro vocabulario. TF-IDF también proporciona valores más grandes para palabras menos frecuentes y es alto cuando los valores de IDF y TF son altos, es decir, la palabra es rara en todos los documentos combinados pero frecuente en un solo documento.
Notas finales
Permítanme resumir lo que hemos cubierto en el artículo:
- Bag of Words simplemente crea un conjunto de vectores que contienen el recuento de apariciones de palabras en el documento (revisiones), mientras que el modelo TF-IDF contiene información sobre las palabras más importantes y las menos importantes también.
- Los vectores de Bag of Words son fáciles de interpretar. Sin embargo, TF-IDF suele funcionar mejor en modelos de aprendizaje automático.
Si bien tanto Bag-of-Words como TF-IDF han sido populares en su propio sentido, todavía quedaba un vacío en lo que respecta a la comprensión del contexto de las palabras. Detectar la similitud entre las palabras ‘espeluznante’ y ‘aterrador’, o traducir nuestros documentos dados a otro idioma, requiere mucha más información en los documentos.
Aquí es donde entran en juego las técnicas de incrustación de palabras como Word2Vec, Continuous Bag of Words (CBOW), Skipgram, etc. Puede encontrar una guía detallada de dichas técnicas aquí:





