Introducción
¿Alguna vez ha luchado por mejorar su rango en un hackathon de aprendizaje automático en DataHack o Kaggle? Has probado todos tus trucos y técnicas favoritas, pero tu puntuación se niega a ceder. ¡Estuve allí y es una experiencia bastante frustrante!
Esto es especialmente relevante durante sus primeros días en este campo. Tendemos a utilizar las técnicas familiares que hemos aprendido, como la regresión lineal, la regresión logística, etc. (dependiendo del enunciado del problema).
Y luego viene Bootstrap Sampling. Es un concepto poderoso que impulsó mi rango hacia los escalones superiores de estas tablas de clasificación de hackathon. ¡Y fue toda una experiencia de aprendizaje!

El muestreo de Bootstrap es una técnica que siento que todo científico de datos, aspirante o establecido, debe aprender.
Entonces, en este artículo, aprenderemos todo lo que necesita saber sobre el muestreo de arranque. Qué es, por qué es necesario, cómo funciona y dónde encaja en la imagen del aprendizaje automático. También implementaremos el muestreo de arranque en Python.
¿Qué es el muestreo de Bootstrap?
Aquí hay una definición formal de Bootstrap Sampling:
En estadística, Bootstrap Sampling es un método que implica la extracción de datos de muestra repetidamente con reemplazo de una fuente de datosUna "fuente de datos" se refiere a cualquier lugar o medio donde se puede obtener información. Estas fuentes pueden ser tanto primarias, como encuestas y experimentos, como secundarias, como bases de datos, artículos académicos o informes estadísticos. La elección adecuada de una fuente de datos es crucial para garantizar la validez y la fiabilidad de la información en investigaciones y análisis.... para estimar un parámetro de población.
Espera, eso es demasiado complejo. Analicemos y comprendamos los términos clave:
- Muestreo: Con respecto a las estadísticas, el muestreo es el proceso de seleccionar un subconjunto de elementos de una amplia colección de elementos (población) para estimar una determinada característica de toda la población.
- Muestreo con reemplazo: Significa que un punto de datos en una muestra extraída también puede reaparecer en futuras muestras extraídas.
- Estimación de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto....: Es un método de estimación de parámetros para la población utilizando muestras. Un parámetro es una característica medible asociada con una población. Por ejemplo, la altura promedio de los residentes en una ciudad, el recuento de glóbulos rojos, etc.
Con ese conocimiento, continúe y vuelva a leer la definición anterior. ¡Tendrá mucho más sentido ahora!
¿Por qué necesitamos el muestreo Bootstrap?
Esta es una pregunta fundamental con la que he visto lidiar a los entusiastas del aprendizaje automático. ¿Cuál es el punto de Bootstrap Sampling? ¿Dónde puedes usarlo? Permítanme tomar un ejemplo para explicar esto.
Digamos que queremos encontrar la altura media de todos los estudiantes de una escuela (que tiene una población total de 1000). Entonces, ¿cómo podemos realizar esta tarea?
Un método consiste en medir la altura de todos los estudiantes y luego calcular la altura media. He ilustrado este proceso a continuación:
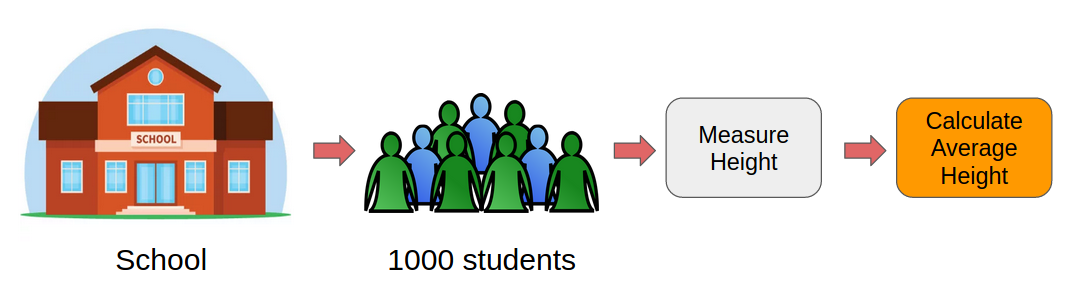
Sin embargo, esta sería una tarea tediosa. Solo piénselo, tendríamos que medir individualmente las alturas de 1,000 estudiantes y luego calcular la altura media. ¡Tardará días! Necesitamos un enfoque más inteligente aquí.
Aquí es donde entra en juego Bootstrap Sampling.
En lugar de medir las alturas de todos los estudiantes, podemos extraer una muestra aleatoria de 5 estudiantes y medir sus alturas. Repetiríamos este proceso 20 veces y luego promediaríamos los datos de estatura recopilados de 100 estudiantes (5 x 20). Esta altura media sería una estimación de la altura media de todos los alumnos de la escuela.
Bastante sencillo, ¿verdad? Esta es la idea básica de Bootstrap Sampling.
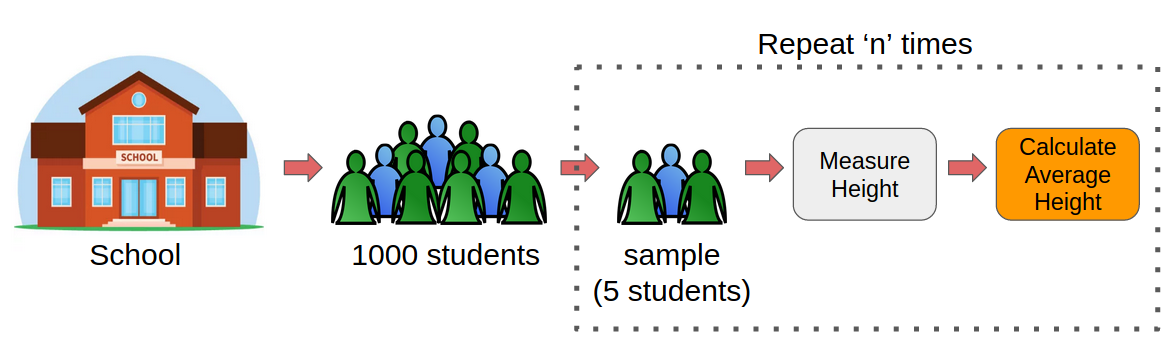
Por lo tanto, cuando tenemos que estimar un parámetro de una gran población, podemos tomar la ayuda de Bootstrap Sampling.
Muestreo Bootstrap en Machine Learning
El muestreo de bootstrap se usa en un algoritmo de conjunto de aprendizaje automático llamado agregación de bootstrap (también llamado empaquetado). Ayuda a evitar el sobreajuste y mejora la estabilidad de los algoritmos de aprendizaje automático.
En el ensacado, se extrae un cierto número de subconjuntos del mismo tamaño de un conjunto de datos con reemplazo. Luego, se aplica un algoritmo de aprendizaje automático a cada uno de estos subconjuntos y las salidas se ensamblan como se ilustra a continuación:
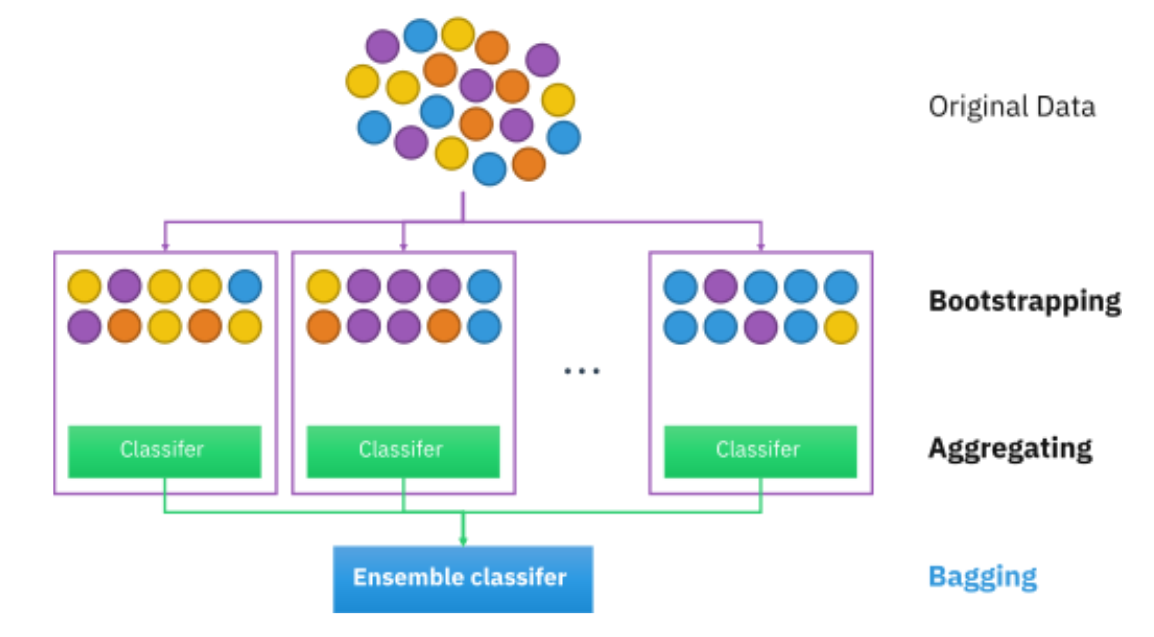
Puede leer y saber más sobre el aprendizaje en conjunto aquí:
Implementar el muestreo de Bootstrap en Python
Es hora de poner a prueba nuestro aprendizaje e implementar el concepto de Bootstrap Sampling en Python.
En esta sección, intentaremos estimar la media de la población con la ayuda del muestreo bootstrap. Importemos las bibliotecas necesarias:
A continuación, crearemos una distribución (población) gaussiana de 10,000 elementos con la media poblacional de 500:
Producción: 500.00889503613934
Ahora, extraeremos 40 muestras de tamaño 5 de la distribución (población) y calcularemos la media para cada muestra:
Comprobemos el promedio de los valores medios de las 40 muestras:
np.mean(sample_mean)
Producción: 500.024133172629
¡Resulta estar bastante cerca de la media de la población! Es por eso que Bootstrap Sampling es una técnica tan útil en estadística y aprendizaje automático.
Resumiendo lo que hemos aprendido
En este artículo, aprendimos sobre la utilidad de Bootstrap Sampling en estadísticas y aprendizaje automático. También lo implementamos en Python y verificamos su efectividad.
Estos son algunos de los beneficios clave del bootstrapping:
- El parámetro estimado por muestreo bootstrap es comparable al parámetro de población real
- Dado que solo necesitamos algunas muestras para el arranque, el requisito de cálculo es muy inferior
- En Random Forest, el tamaño de muestra de bootstrap de incluso el 20% da un rendimiento bastante bueno como se muestra a continuación:
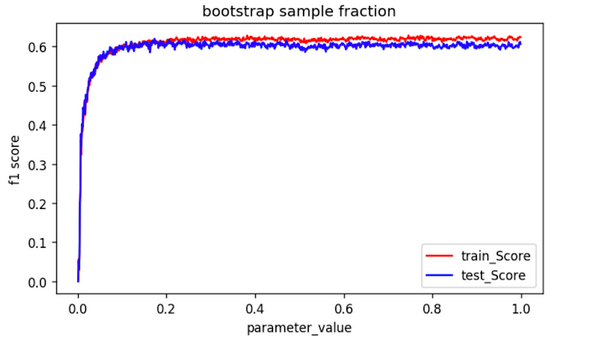
El rendimiento del modelo alcanza el máximo cuando los datos proporcionados son menos de 0,2 fracción del conjunto de datos original.





