Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Obtener datos completos y de alto rendimiento no siempre es el caso en Machine Learning. Mientras trabaja en cualquier declaración de problema del mundo real o intenta construir cualquier tipo de proyecto como Machine Learning Practioner, necesita los datos.
Para satisfacer la necesidad de datos la mayor parte del tiempo, es necesario obtener datos de la API y, si el sitio web no proporciona la API, la única opción que queda es Web Scraping.
En este tutorial, aprenderemos cómo puede usar API, extraer datos y guardarlos en forma de marco de datos.

Tabla de contenido
- Obteniendo datos de una API
-
- Que es API
- Importancia de usar API
- Cómo obtener una API
- Código práctico para extraer datos de la API
- Obteniendo datos usando bases de datos SQL
- EndNote
Obteniendo datos de una API
Que es API
API significa Interfaz de programación de aplicaciones. API básicamente funciona como una interfaz entre la comunicación de dos software. Ahora entendamos ¿Cómo?
Importancia de usar API
Considere un ejemplo, si tenemos que reservar un boleto de tren, entonces tenemos múltiples opciones como el sitio web de IRCTC, Yatra, hacer mi viaje, etc. Ahora, todas estas son organizaciones diferentes, y supongamos que hemos reservado el asiento número 15 del vagón B15, si alguien visita e intenta reservar el mismo asiento desde un software diferente, ¿se reservará o no? Se mostrará como reservado.
Aunque se trata de empresas diferentes, software diferente, son capaces de compartir esta información. Por lo tanto, el intercambio de información ocurre entre múltiples sitios web a través de API, por eso las API son importantes.
Cada organización brinda servicios en múltiples sistemas operativos como ios, android, que están integrados con una sola base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos..... Por lo tanto, también utilizan API para obtener datos de la base de datos a múltiples aplicaciones.
Ahora entendamos prácticamente cómo obtener datos usando un marco de datos usando Python.
¿Cómo obtener una API?
Usaremos el sitio web oficial de TMDB, que proporciona diferentes API para obtener diferentes tipos de datos. vamos a obtener datos de películas mejor calificados en nuestro marco de datos. Para obtener los datos, debe pasar la API.
Visita el Sitio TMDB y regístrese e inicie sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... con su cuenta de Google. Después de eso, en la sección de su perfil, visite la configuración. En el panelUn panel es un grupo de expertos que se reúne para discutir y analizar un tema específico. Estos foros son comunes en conferencias, seminarios y debates públicos, donde los participantes comparten sus conocimientos y perspectivas. Los paneles pueden abordar diversas áreas, desde la ciencia hasta la política, y su objetivo es fomentar el intercambio de ideas y la reflexión crítica entre los asistentes.... de configuración de la izquierda, en la opción del último segundo, puede encontrar una opción como API, simplemente haga clic en ella y genere su API.
Use la clave API para obtener datos de películas mejor calificadas
Ahora que tiene su propia clave de API, visite el sitio de desarrolladores de API de TMDB que puede ver en la sección de API en la parte superior. Haga clic en Películas y la visita obtiene la mejor calificación Ahora, en la ventana de la mejor calificación, visite la opción Probar ahora, donde puede ver en el lado derecho del botón enviar solicitud, tiene un enlace a las películas mejor calificadas.
https://api.themoviedb.org/3/movie/top_rated?api_key=<<api_key>>&language=en-US&page=1
Copie el enlace y, en lugar de la clave de API, pegue la clave de API que ha generado y abra el enlace, podrá ver los datos similares a JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software....
Ahora, para comprender estos datos, existen varias herramientas como el visor JSON. Si lo desea, puede abrirlo y pegar el código en el visor. Es un diccionario y la información requerida sobre películas está presente en la clave de resultados.
Los datos totales están presentes en 428 páginas y el número total de películas es 8551. Por lo tanto, tenemos que crear un marco de datos que tendrá 8551 filas y los campos que extraeremos son id, título de la película, fecha de lanzamiento, descripción general, popularidad, voto. promedio, recuento de votos. Por lo tanto, el marco de datos que recibiremos tendrá la forma 8551 * 7.
Código práctico para obtener datos de la API
Abra su Jupyter Notebook para escribir el código y extraer los datos en el marco de datos. Instale la biblioteca de pandas y solicitudes si no tiene usando el comando pip
pip install pandas pip install requests
Ahora defina su clave de API en el enlace y haga una solicitud al sitio web de TMDB para extraer datos y guardar la respuesta en una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.....
api_key = your API key
link = "https://api.themoviedb.org/3/movie/top_rated?api_key=<<api_key>>&language=en-US&page=1"
response = requests.get(link)
No olvide mencionar su clave API en el enlace. Y después de ejecutar el código anterior, si imprime la respuesta, puede ver la respuesta en 200, lo que significa que todo está funcionando bien y obtuvo los datos en forma de JSON.
Los datos que queremos están en resultados clave, así que intente imprimir la clave de resultados.
response.json()["results"]
Para crear el marco de datos de las columnas requeridas, podemos usar el marco de datos de pandas y obtendrá el marco de datos de 20 filas que tiene las mejores películas de la página 1.
data = pd.DataFrame(response.json()["results"])[['id','title','overview','popularity','release_date','vote_average','vote_count']]
Queremos los datos de las 428 páginas completas, por lo que colocaremos el código en el bucle for y solicitaremos el sitio web una y otra vez a diferentes páginas y cada vez obtendremos 20 filas y siete columnas.
for i in range(1, 429):
response = requests.get("https://api.themoviedb.org/3/movie/top_rated?api_key=<api_key>&language=en-US&page={}".format(i))
temp_df = pd.DataFrame(response.json()["results"])[['id','title','overview','popularity','release_date','vote_average','vote_count']]
data.append(temp_df, ignore_index=False)
Por lo tanto, obtuvimos el marco de datos completo con 8551 filas. hemos formateado un número de página para solicitar una página diferente cada vez. Y mencione su clave API en el enlace eliminando la etiqueta HTML. Tardará al menos 2 minutos en ejecutarse. El marco de datos que obtuvimos se ve así.
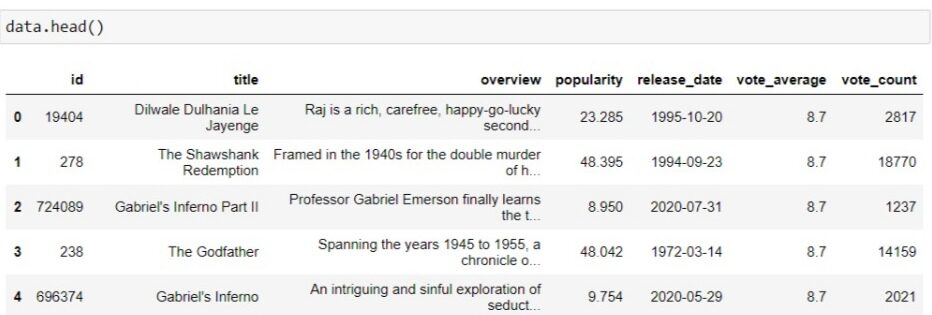
Guarde los datos en un archivo CSV para que pueda usarlo para analizar, procesar y crear un proyecto sobre él.
Obtener datos de una base de datos SQL
Trabajar con bases de datos SQL es sencillo con Python. Python proporciona varias bibliotecas para conectarse a la base de datos y leer las consultas SQL y extraer los datos de la tabla SQL a Pandas Dataframe.
Para fines de demostración, estamos utilizando un conjunto de datos de población de distritos y ciudades del mundo cargados en Kaggle en formato de consultas SQL. Puede acceder al conjunto de datos desde aquí.
Descargue el archivo y cárguelo en su base de datos local. Puede utilizar MySQL, XAMPP, SQLite o cualquier base de datos de su elección. TODA la base de datos ofrece una opción de importación, simplemente haga clic en ella, seleccione el archivo descargado y cárguelo.
Ahora estamos listos para conectar Python a la base de datos y extraer los datos SQL en Pandas Dataframe. Para realizar una conexión, instale la biblioteca de conectores MySQL.
!pip install mysql.connector
Después de instalar, importe las bibliotecas necesarias y oriente la conexión a la base de datos mediante el método de conexión.
import numpy as np import pandas as pd import mysql.connector conn = mysql.connector.connect(host="localhost", user="root", password="", database="World")
Después de conectarnos con la base de datos con éxito, podemos consultar una base de datos y extraer datos en un marco de datos.
city_data = pd.read_sql_query("SELECT * FROM city", conn)
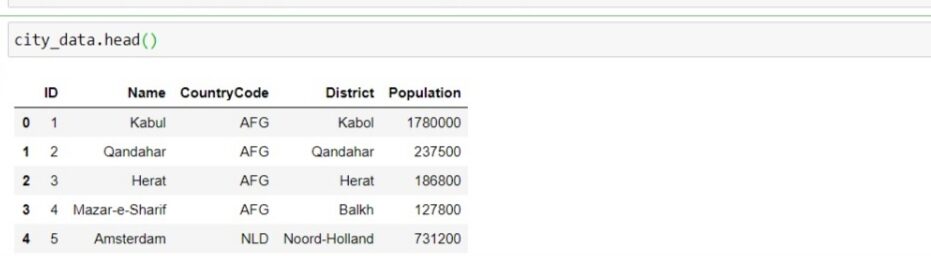
Por lo tanto, hemos extraído datos al marco de datos con éxito y es fácil trabajar con bases de datos con la ayuda de Python. También puede extraer datos filtrando con consultas SQL.
EndNote
Espero que haya sido un artículo increíble que le sirva para aprender a extraer datos de diferentes fuentes. La obtención de datos con la ayuda de API es utilizada principalmente por Data Scientist para recopilar datos del gran y vasto conjunto de datos para tener un mejor análisis y mejorar el rendimiento del modelo.
Como principiante, la mayoría de las veces obtiene el archivo de datos preciso, pero este no es el caso todo el tiempo, debe traer los datos de diferentes fuentes que serán ruidosas y trabajar en ellos para tomar mejores decisiones comerciales.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





