Visión general
- Comprenda el significado de particionar y agrupar en HiveHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información.... en detalle.
- Veremos, cómo crear particiones y cubos en el Hive.
Introducción
Es posible que haya visto una enciclopedia en la biblioteca de su escuela o universidad. Es un conjunto de libros que te darán información sobre casi cualquier cosa. ¿Sabes qué es lo mejor de la enciclopedia?

Sí, lo adivinaste correctamente. Las palabras están ordenadas alfabéticamente. Por ejemplo, tiene una palabra en mente «Pirámides». Irás directamente a recoger el libro con el título “P”. No tiene que buscar eso en otros libros. ¿Te imaginas lo difícil que sería la tarea de buscar un solo libro si estuvieran almacenados sin ningún orden?
Aquí, almacenar las palabras alfabéticamente representa la indexación, pero el uso de una ubicación diferente para las palabras que comienzan con el mismo carácter se conoce como agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo....
Hay tipos similares de técnicas de almacenamiento, como particiones y agrupaciones, en Apache Hive para que podamos obtener resultados más rápidos para las consultas de búsqueda. En este artículo, veremos qué es la partición y el agrupamiento, y cuándo usar cuál.
Tabla de contenido
- ¿Qué es el particionamiento?
- ¿Cuándo utilizar el particionamiento?
- ¿Qué es el agrupamiento?
- ¿Cuándo usar el agrupamiento?
¿Qué es el particionamiento?
Apache Hive nos permite organizar la tabla en múltiples particiones donde podemos agrupar el mismo tipo de datos. Se utiliza para distribuir la carga horizontalmente. Entendamos con un ejemplo:
Supongamos que tenemos que crear una tabla en la colmena que contiene los detalles del producto para una empresa de comercio electrónico de moda. Tiene las siguientes columnas:
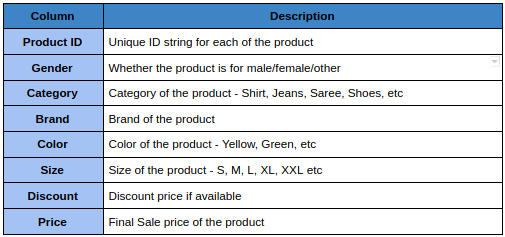
Ahora, el primer filtro que usa la mayoría de los clientes es Género, luego seleccionan categorías como Camisa, su tamaño y color. Veamos cómo crear las particiones para este ejemplo.
CREATE TABLE products ( product_id string,
brand string,
size string,
discount float,
price float )
PARTITIONED BY (gender string,
category string,
color string);
Ahora, la colmena almacenará los datos en la estructura del directorio como:
/user/hive/warehouse/mytable/gender=male/category=shoes/color=black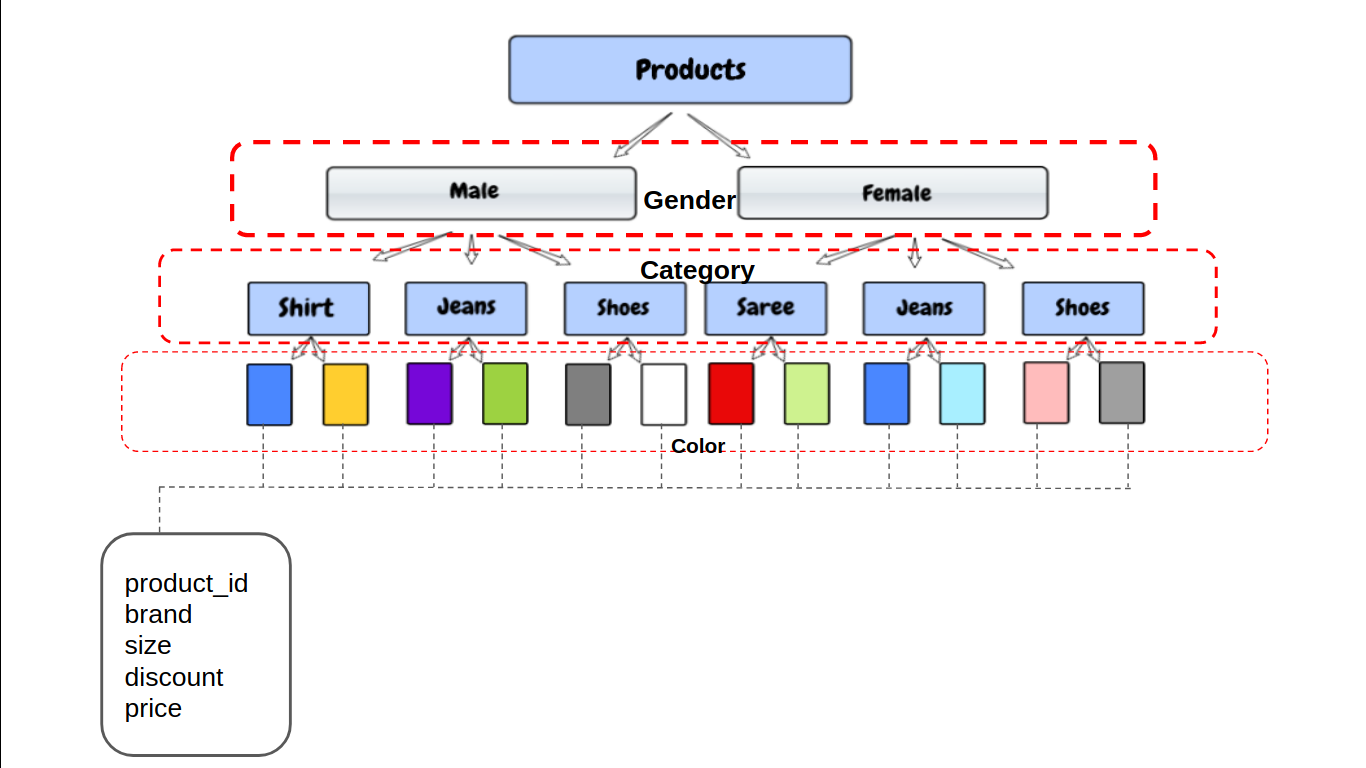
La partición de los datos nos brinda beneficios de rendimiento y también nos ayuda a organizar los datos. Ahora, veamos cuándo usar la partición en la colmena.
¿Cuándo utilizar el particionamiento?
- Cuando la columna con una consulta de búsqueda alta tiene una cardinalidad baja. Por ejemplo, si crea una partición con el nombre del país, se creará un máximo de 195 particiones y la colmena podrá administrar esta cantidad de directorios.
- Por otro lado, no cree particiones en las columnas con cardinalidad muy alta. Por ejemplo, ID de producto, marca de tiempo y precio porque creará millones de directorios que serán imposibles de administrar para la colmena.
- Es efectivo cuando el volumen de datos en cada partición no es muy alto. Por ejemplo, si tiene los datos de la aerolínea y desea calcular el número total de vuelos en un día. En ese caso, el resultado tomará más tiempo para calcular sobre la partición «Dubai», ya que tiene uno de los aeropuertos más activos del mundo, mientras que para un país como «Albania» devolverá los resultados más rápido.
¿Qué es el agrupamiento?
En el ejemplo anterior, sabemos que no podemos crear una partición sobre el precio de la columna porque su tipo de datos es flotante y hay un número infinito de precios únicos posibles.
Hive tendrá que generar un directorio separado para cada uno de los precios únicos y sería muy difícil para Hive administrarlos. En lugar de esto, podemos definir manualmente el número de depósitos que queremos para dichas columnas.
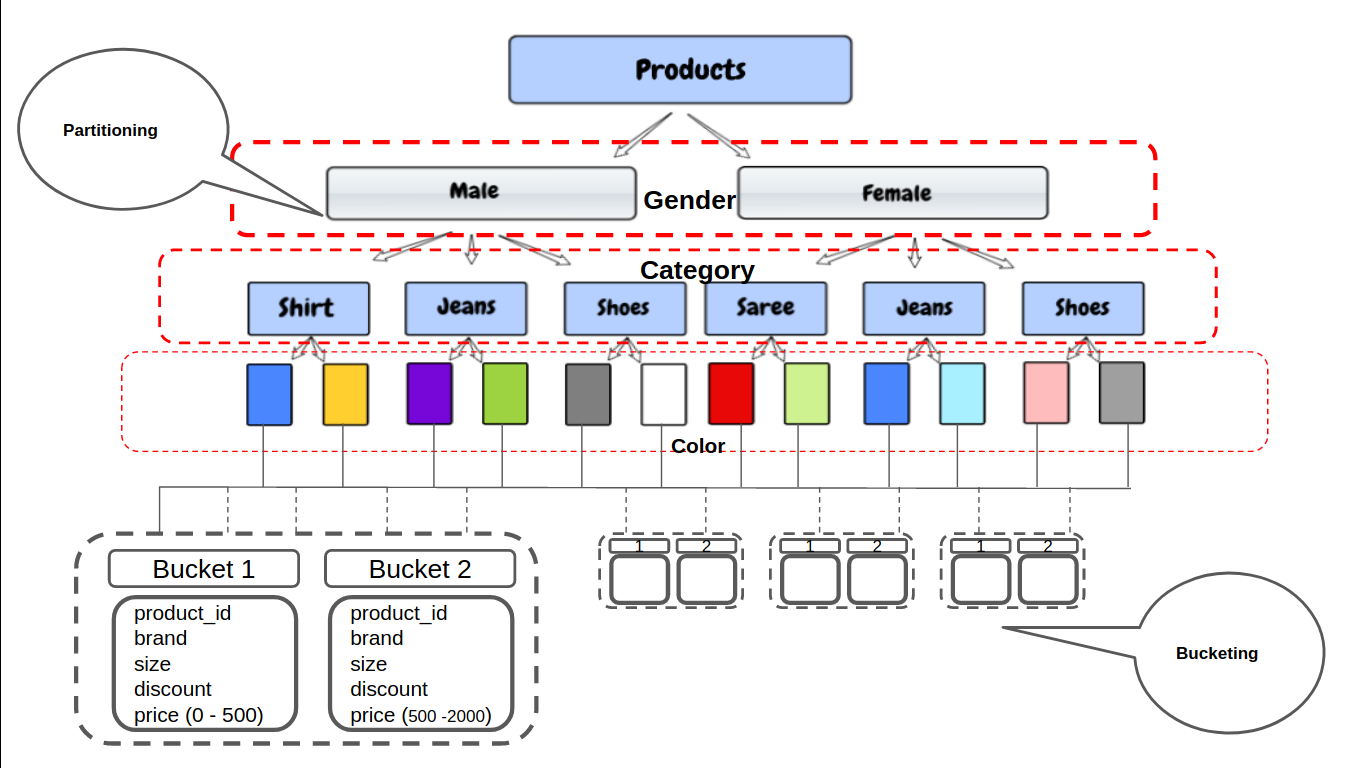
En el agrupamiento, las particiones se pueden subdividir en grupos según la función hash de una columna. Proporciona una estructura adicional a los datos que se pueden utilizar para consultas más eficientes.
CREATE TABLE products ( product_id string,
brand string,
size string,
discount float,
price float )
PARTITIONED BY (gender string,
category string,
color string)
CLUSTERED BY (price) INTO 50 BUCKETS;
Ahora, solo se crearán 50 depósitos sin importar cuántos valores únicos haya en la columna de precios. Por ejemplo, en el primer cubo, todos los productos con un precio [ 0 – 500 ] irán, y en el próximo grupo de productos con un precio [ 500 – 200 ] etcétera.
¿Cuándo usar el agrupamiento?
- No podemos dividir en una columna con una cardinalidad muy alta. Demasiadas particiones darán como resultado varios archivos Hadoop, lo que aumentará la carga en el mismo nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos...., ya que tiene que transportar los metadatos de cada una de las particiones.
- Si algunas combinaciones del lado del mapa están involucradas en sus consultas, las tablas agrupadas son una buena opción. La unión del lado del mapa es un proceso en el que dos tablas se unen utilizando la función de mapa solo sin ninguna función reducida. Le recomiendo que lea este artículo para comprender mejor las combinaciones del lado del mapa: El lado del mapa se une en Hive
Notas finales
En este artículo, hemos visto qué es la partición y el agrupamiento, cómo crearlos y cuáles son sus pros y sus contras.
Le recomiendo encarecidamente que consulte los siguientes recursos para obtener más información sobre Apache Hive:
Si tiene alguna pregunta relacionada con este artículo, hágamelo saber en la sección de comentarios a continuación.





