Foto de Daddy Mohlala en Unsplash
Los datos son agua, purificarlos para hacerlos comestibles es una función del analista de datos: Kashish Rastogi
Tabla de contenido:
- Planteamiento del problema
- Descripción de datos
- Limpieza de texto con PNL
- Encontrar si el texto tiene: con espacio
- Limpieza de texto con biblioteca de preprocesador
- Análisis del sentimiento de los datos
- Visualización de datos
Estoy tomando los datos de twitter que están disponibles aquí en la plataforma DataPeaker.
Importación de bibliotecas
import pandas as pd import re import plotly.express as px import nltk import spacy
Estoy cargando un modelo espacioso pequeño. Hay 3 tamaños de modelos en los que puede descargar spacy (pequeño, mediano y grande) según sus requisitos.
nlp = spacy.load('en_core_web_sm')
Los datos se ven así
df = pd.read_csv(r'location of file') del df['id'] df.head(5)
Planteamiento del problema
El punto clave es encontrar el sentimiento de los datos de texto. El texto proporcionado es de clientes de varias firmas de tecnología que fabrican teléfonos, laptops, gadgets, etc. La tarea es identificar si los tweets tienen un sentimiento negativo, positivo o neutral hacia la empresa.
Descripción de datos
Etiqueta: La columna de etiqueta tiene 2 valores únicos 0 y 1.
Pío: Las columnas de tweets tienen el texto proporcionado por los clientes
Manipulación de datos
Encontrar la forma de los datos
Hay 2 columnas y 7920 filas.
df.shape
Clasificación de tweets
fig = px.pie(df, names=df.label, hole=0.7, title="Tweets Classification",
height=250, color_discrete_sequence=px.colors.qualitative.T10)
fig.update_layout(margin=dict(t=100, b=40, l=60, r=40),
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(size=25, color="#a5a7ab", family="Lato, sans-serif"),
font=dict(color="#8a8d93"),
)
Tómese un momento y observe los datos. ¿Que ves?

Fuente de la imagen: https://unsplash.com/photos/LDcC7aCWVlo
- No hay marcado para analizar, es texto sin formato (¡yaa!).
- Hay muchas cosas para filtrar como:
-
- El identificador de Twitter está enmascarado (@usuario), lo que no nos sirve de nada.
- Etiquetas
- Enlaces
- Caracteres especiales
- Vemos que el texto tiene valor numérico en ellos.
- Hay muchos errores tipográficos y contracciones en el texto.
- Hay muchos nombres de empresas (Sony, Apple).
- El texto no está en minúsculas
Limpiemos el texto
Encontrar si el texto tiene:
- Nombres de usuario de Twitter
- Etiquetas
- Valores numéricos
- Enlaces
Eliminando si el texto tiene:
- Nombre de usuario de Twitter porque no proporcionará ninguna información adicional en este momento, ya que por razones de seguridad, el nombre de usuario se cambió a nombres ficticios
- Las palabras hashtag no proporcionarán ningún significado útil al texto en el análisis de sentimientos.
- El enlace URL tampoco agregará información al texto.
- Eliminando
- Puntuación para obtener texto limpio
- Las palabras con una longitud inferior a 3 son seguras de eliminar del texto porque las palabras serán como (soy, soy, es) que no tienen ningún significado ni función específicos en el texto
- Las palabras vacías son siempre la mejor opción para eliminar
Eliminando Nombre de usuario del texto
Hacer una función para eliminar el nombre de usuario del texto con el simple encuentra todos() función de los pandas. Dónde vamos a seleccionar las palabras que comienzan con ‘@’.
def remove_pattern(input_txt):
r = re.findall(r"@(w+)", input_txt)
for i in r:
input_txt = re.sub(i, '', input_txt)
return input_txt
df['@_remove'] = np.vectorize(remove_pattern)(df['tweet'])
df['@_remove'][:3]

Hallazgo Etiquetas en el texto
Haciendo una función para extraer hashtags de texto con el simple encuentra todos() función de los pandas. Dónde vamos a seleccionar las palabras que comienzan con ‘#’ y almacenarlos en un marco de datos.
hashtags = []
def hashtag_extract(x):
# Loop over the words in the tweet
for i in x:
ht = re.findall(r"#(w+)", i)
hashtags.append(ht)
return hashtags

Pasando función y extrayendo hashtags ahora podemos visualizar cuántos hashtags hay en tweets positivos y negativos
# extracting hashtags from neg/pos tweets dff_0 = hashtag_extract(df['tweet'][df['label'] == 0]) dff_1 = hashtag_extract(df['tweet'][df['label'] == 1]) dff_all = hashtag_extract(df['tweet'][df['label']]) # unnesting list dff_0 = sum(dff_0,[]) dff_1 = sum(dff_1,[]) dff_all = sum(dff_all,[])
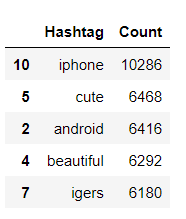
Contando los hashtags frecuentes utilizados cuando label = 0. FreqDist significa que nos dirá cuántas veces apareció esa palabra en todo el documento.
data_0 = nltk.FreqDist(dff_0)
data_0 = pd.DataFrame({'Hashtag': list(data_0.keys()),
'Count': list(data_0.values())}).sort_values(by='Count', ascending=False)
data_0[:5]
Si desea saber más sobre Plotly y cómo usarlo, visite este Blog. Cada gráfico está bien explicado con diferentes parámetros que debe tener en cuenta al trazar gráficos.
fig = px.bar(data_0[:30], x='Hashtag', y='Count', height=250,
title="Top 30 hashtags",
color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=False),
fig.update_xaxes(categoryorder="total descending")
fig.update_traces(hovertemplate=None)
fig.update_layout(margin=dict(t=100, b=0, l=60, r=40),
hovermode="x unified",
xaxis_tickangle=300,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(size=25, color="#a5a7ab", family="Lato, sans-serif"),
font=dict(color="#8a8d93")
)
Pasando texto
sentences = nlp(str(text))
Hallazgo nortevalores numéricos en el texto
spacy proporciona funciones como_num que indica si el texto tiene valores numéricos o no
for token in sentences:
if token.like_num:
text_num = token.text
print(text_num)
Hallazgo Enlace URL en el texto
spacy proporciona la función like_url que indica si el texto tiene un enlace URL en ellos o no
# find links
for token in sentences:
if token.like_url:
text_links = token.text
print(text_links)

Hay una biblioteca en Python que ayuda a limpiar el texto, puede encontrar la documentación. aquí
Actualmente, esta biblioteca admite limpieza, tokenización y análisis
- URLs
- Etiquetas
- Menciones
- Palabras reservadas (RT, FAV)
- Emojis
- Emoticonos
Importando biblioteca
!pip install tweet-preprocessor import preprocessor as p
Llamar a una función para limpiar el texto
def preprocess_tweet(row):
text = row['tweet']
text = p.clean(text)
return text
df['clean_tweet'] = df.apply(preprocess_tweet, axis=1) df[:6]

Como vemos, las columnas clean_tweet solo tienen texto, se eliminan todos los nombres de usuario, hashtag y enlaces URL
Algunos de los pasos para la limpieza siguen siendo como
- bajando todo el texto
- Eliminando puntuaciones
- Eliminar números
Código:
def preprocessing_text(text):
# Make lowercase
text = text.str.lower()
# Remove punctuation
text = text.str.replace('[^ws]', '', regex=True)
# Remove digits
text = text.str.replace('[d]+', '', regex=True)
return text
pd.set_option('max_colwidth', 500)
df['clean_tweet'] = preprocessing_text(df['clean_tweet'])
df['clean_tweet'][:5]

Tenemos nuestro texto limpio, eliminemos las palabras vacías.
¿Qué son las palabras vacías? ¿Es necesario eliminar las palabras vacías?
Las palabras vacías son las palabras más comunes en cualquier lenguaje natural. Las palabras vacías son como yo, soy, tú, cuándo, etc., no agregan ninguna información adicional al texto.
No es necesario eliminar las palabras vacías cada vez que depende del caso de estudio, aquí estamos encontrando el sentimiento del texto, por lo que no necesitamos detener las palabras.
from nltk.corpus import stopwords
# Remove stop words
stop = stopwords.words('english')
df['clean_tweet'] = df['clean_tweet'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
df['clean_tweet'][:5]
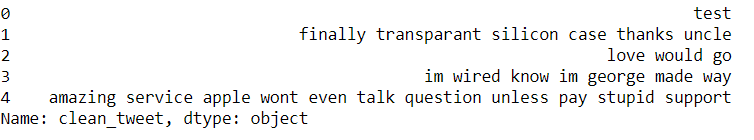
Después de implementar todos los pasos obtuvimos nuestro texto limpio. Ahora, ¿qué hacer con el texto?
- ¿Podemos averiguar qué palabras se utilizan con frecuencia?
- ¿Qué palabras se usan más negativamente / positivamente en el texto?
Tokenizar palabras y calcular la frecuencia y el recuento de palabras y almacenarlas en un marco de datos.
Una distribución de frecuencia registra el número de veces que se ha producido cada palabra. Por ejemplo, una nueva palabra se ha utilizado con frecuencia en datos completos seguida de otras palabras iPhone, teléfono, etc.
a = df['clean_tweet'].str.cat(sep=' ')
words = nltk.tokenize.word_tokenize(a)
word_dist = nltk.FreqDist(words)
dff = pd.DataFrame(word_dist.most_common(),
columns=['Word', 'Frequency'])
dff['Word_Count'] = dff.Word.apply(len)
dff[:5]
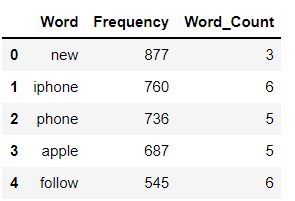
fig = px.histogram(dff[:20], x='Word', y='Frequency', height=300,
title="Most common 20 words in tweets", color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=False),
fig.update_xaxes(categoryorder="total descending")
fig.update_traces(hovertemplate=None)
fig.update_layout(margin=dict(t=100, b=0, l=70, r=40),
hovermode="x unified",
xaxis_tickangle=360,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(size=25, color="#a5a7ab", family="Lato, sans-serif"),
font=dict(color="#8a8d93"),
)
fig = px.bar(dff.tail(10), x='Word', y='Frequency', height=300,
title="Least common 10 words in tweets", color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=False),
fig.update_xaxes(categoryorder="total descending")
fig.update_traces(hovertemplate=None)
fig.update_layout(margin=dict(t=100, b=0, l=70, r=40),
hovermode="x unified",
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(size=25, color="#a5a7ab", family="Lato, sans-serif"),
font=dict(color="#8a8d93"),
)
fig = px.bar(a, height=300, title="Frequency of words in tweets",
color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=False),
fig.update_xaxes(categoryorder="total descending")
fig.update_traces(hovertemplate=None)
fig.update_layout(margin=dict(t=100, b=0, l=70, r=40), showlegend=False,
hovermode="x unified",
xaxis_tickangle=360,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(size=25, color="#a5a7ab", family="Lato, sans-serif"),
font=dict(color="#8a8d93"),
)
Análisis de los sentimientos
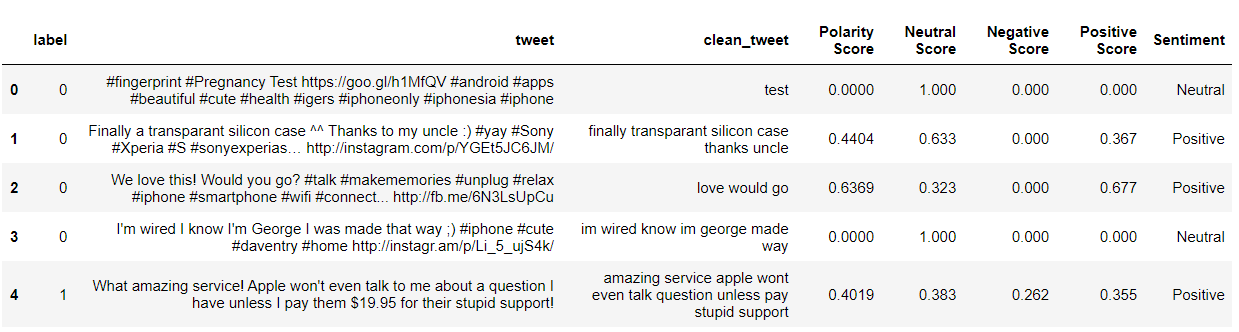
from nltk.sentiment.vader import SentimentIntensityAnalyzer from nltk.sentiment.util import * #Sentiment Analysis SIA = SentimentIntensityAnalyzer() df["clean_tweet"]= df["clean_tweet"].astype(str) # Applying Model, Variable Creation df['Polarity Score']=df["clean_tweet"].apply(lambda x:SIA.polarity_scores(x)['compound']) df['Neutral Score']=df["clean_tweet"].apply(lambda x:SIA.polarity_scores(x)['neu']) df['Negative Score']=df["clean_tweet"].apply(lambda x:SIA.polarity_scores(x)['neg']) df['Positive Score']=df["clean_tweet"].apply(lambda x:SIA.polarity_scores(x)['pos']) # Converting 0 to 1 Decimal Score to a Categorical Variable df['Sentiment']='' df.loc[df['Polarity Score']>0,'Sentiment']='Positive' df.loc[df['Polarity Score']==0,'Sentiment']='Neutral' df.loc[df['Polarity Score']<0,'Sentiment']='Negative' df[:5]
Clasificación de tweets basada en sentimiento
fig_pie = px.pie(df, names="Sentiment", title="Tweets Classifictaion", height=250,
hole=0.7, color_discrete_sequence=px.colors.qualitative.T10)
fig_pie.update_traces(textfont=dict(color="#fff"))
fig_pie.update_layout(margin=dict(t=80, b=30, l=70, r=40),
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(size=25, color="#a5a7ab", family="Lato, sans-serif"),
font=dict(color="#8a8d93"),
legend=dict(orientation="h", yanchor="bottom", y=1, xanchor="right", x=0.8)
)
Conclusión:
Vimos cómo limpiar datos de texto cuando tenemos un nombre de usuario de Twitter, hashtag, enlaces URL, dígitos e hicimos análisis de opinión sobre datos de texto.
Vimos cómo encontrar si el texto tiene enlaces URL o dígitos en ellos con la ayuda de spacy.
Sobre el Autor:
Puedes conectarme
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





