Para cada reclutamiento, las empresas sacan anuncios en línea, referencias y los revisan manualmente.
Las empresas suelen enviar miles de currículums por cada publicación.
Cuando las empresas recopilan hojas de vida a través de anuncios en línea, las clasifican de acuerdo con sus requisitos.
Después de recopilar los currículums, las empresas cierran los anuncios y los portales de solicitud en línea.
Luego, envían los currículums recopilados al equipo de contratación.
Se vuelve muy difícil para los equipos de contratación leer el currículum y seleccionar el currículum según el requisito, no hay problema si hay uno o dos currículums, pero es muy difícil revisar los currículums de 1000 y seleccionar el mejor.
Para solucionar este problema, hoy en este artículo leeremos y revisaremos el currículum usando el aprendizaje automático con Python para que podamos completar días de trabajo en pocos minutos.
2. ¿Qué es la evaluación del currículum vitae?
Elegir a las personas adecuadas para el trabajo es la mayor responsabilidad de todas las empresas, ya que elegir el grupo adecuado de personas puede acelerar el crecimiento empresarial de manera exponencial.
Analizaremos aquí un ejemplo de una empresa de este tipo, que conocemos como departamento de TI. Sabemos que el departamento de TI no está a la altura de los mercados en crecimiento.
Debido a muchos grandes proyectos con grandes empresas, su equipo no tiene tiempo para leer currículums y elegir el mejor currículum según sus requisitos.
Para resolver este tipo de problemas, la empresa siempre elige a un tercero cuyo trabajo es realizar el currículum según el requisito. Estas empresas se conocen con el nombre de Organización de Servicios de Contratación. Se trata de la pantalla de resumen de información.
El trabajo de seleccionar los mejores talentos, asignaciones, concursos de codificación en línea, entre muchos otros, también se conoce como pantalla de currículum.
Por falta de tiempo, las grandes empresas no tienen tiempo suficiente para abrir currículums, por lo que tienen que recurrir a la ayuda de cualquier otra empresa. Por lo que tienen que pagar dinero. Que es un problema muy serio.
Para resolver este problema, la empresa quiere iniciar el trabajo de la pantalla del currículum por sí misma utilizando un algoritmo de aprendizaje automático.
3. Reanudar el cribado mediante el aprendizaje automático
En esta sección, veremos la implementación paso a paso de Resume screening usando python.
3.1 Datos utilizados
Tenemos datos disponibles públicamente de Kaggle. Puede descargar los datos utilizando el siguiente enlace.
https://www.kaggle.com/gauravduttakiit/resume-dataset
3.2 Análisis de datos exploratorios
Echemos un vistazo rápido a los datos que tenemos.
resumeDataSet.head()

Solo hay dos columnas que tenemos en los datos. A continuación se muestra la definición de cada columna.
Categoría: Tipo de trabajo para el que se adapta el currículum vitae.
Reanudar: Currículum de candidatos
resumeDataSet.shape
Producción:
(962, 2)
Hay 962 observaciones que tenemos en los datos. Cada observación representa los detalles completos de cada candidato, por lo que tenemos 962 hojas de vida para la selección.
Veamos qué diferentes categorías tenemos en los datos.
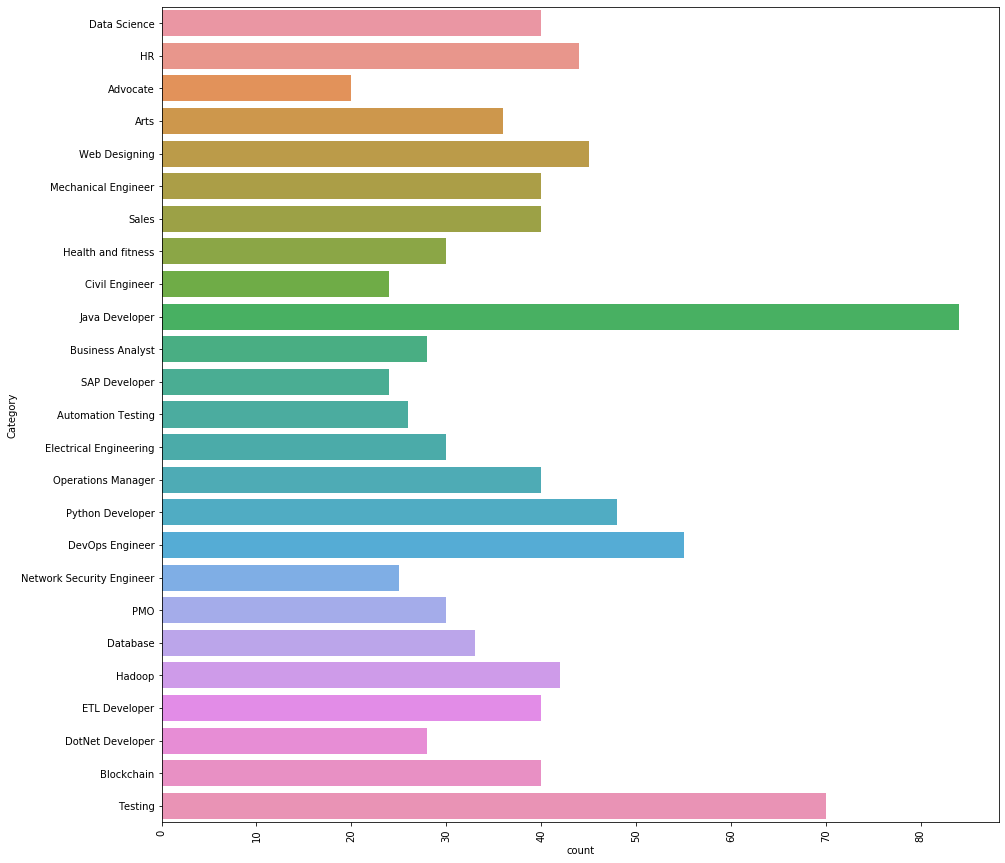
Hay 25 categorías diferentes que tenemos en los datos. Las 3 categorías de trabajo principales que tenemos en los datos son las siguientes.
Desarrollador Java, Testing y DevOps Engineer.
En lugar del recuento o la frecuencia, también podemos visualizar la distribución de categorías de trabajo en porcentaje como se muestra a continuación:
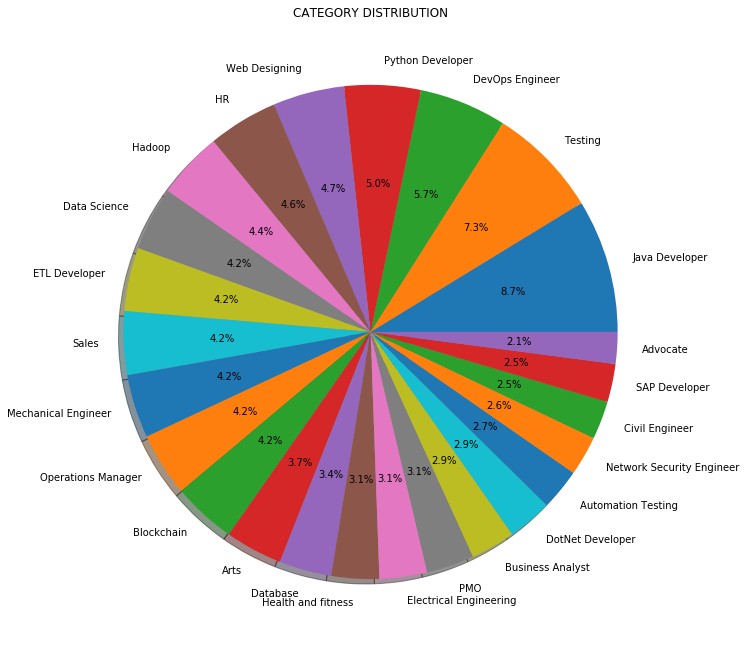
3.3 Preprocesamiento de datos
Paso 1: Limpiar la columna ‘Reanudar’
En este paso, eliminamos cualquier información innecesaria de los currículums como URL, hashtags y caracteres especiales.
def cleanResume(resumeText):
resumeText = re.sub('httpS+s*', ' ', resumeText) # remove URLs
resumeText = re.sub('RT|cc', ' ', resumeText) # remove RT and cc
resumeText = re.sub('#S+', '', resumeText) # remove hashtags
resumeText = re.sub('@S+', ' ', resumeText) # remove mentions
resumeText = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>[email protected][]^_`{|}~"""), ' ', resumeText) # remove punctuations
resumeText = re.sub(r'[^x00-x7f]',r' ', resumeText)
resumeText = re.sub('s+', ' ', resumeText) # remove extra whitespace
return resumeText
resumeDataSet['cleaned_resume'] = resumeDataSet.Resume.apply(lambda x: cleanResume(x))
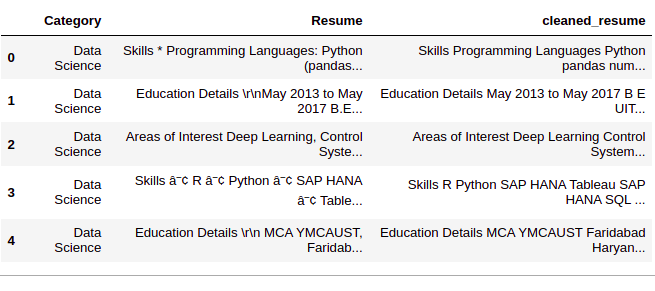
Paso 2: codificación de ‘Categoría’
Ahora, codificaremos la columna ‘Categoría’ usando LabelEncoding. Aunque la columna ‘Categoría’ son datos ‘Nominales’, estamos usando LabelEncong porque la columna ‘Categoría’ es nuestra columna ‘objetivo’. Al realizar LabelEncoding, cada categoría se convertirá en una clase y crearemos un modelo de clasificación multiclase.
var_mod = ['Category']
le = LabelEncoder()
for i in var_mod:
resumeDataSet[i] = le.fit_transform(resumeDataSet[i])
Paso 3: preprocesamiento de la columna ‘clean_resume’
Aquí preprocesaremos y convertiremos la columna ‘clean_resume’ en vectores. Hay muchas formas de hacerlo, como ‘Bolsa de palabras’, ‘Tf-Idf’, ‘Word2Vec’ y una combinación de estos métodos.
Usaremos el método ‘Tf-Idf’ para obtener los vectores en este enfoque.
requiredText = resumeDataSet['cleaned_resume'].values
requiredTarget = resumeDataSet['Category'].values
word_vectorizer = TfidfVectorizer(
sublinear_tf=True,
stop_words="english",
max_features=1500)
word_vectorizer.fit(requiredText)
WordFeatures = word_vectorizer.transform(requiredText)
Tenemos ‘WordFeatures’ como vectores y ‘requiredTarget’ y target después de este paso.
3.4 Construcción de modelos
Usaremos el método ‘One vs Rest’ con ‘KNeighborsClassifier’ para construir este modelo de clasificación multiclase.
Usaremos 80% de datos para entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y 20% de datos para validación. Dividamos los datos ahora en entrenamiento y conjunto de prueba.
X_train,X_test,y_train,y_test = train_test_split(WordFeatures,requiredTarget,random_state=0, test_size=0.2) print(X_train.shape) print(X_test.shape)
Producción:
(769, 1500) (193, 1500)
Como ahora tenemos datos de prueba y entrenamiento, construyamos el modelo.
clf = OneVsRestClassifier(KNeighborsClassifier()) clf.fit(X_train, y_train) prediction = clf.predict(X_test)
3.5 Resultados
Veamos los resultados que tenemos.
print('Accuracy of KNeighbors Classifier on training set: {:.2f}'.format(clf.score(X_train, y_train)))
print('Accuracy of KNeighbors Classifier on test set: {:.2f}'.format(clf.score(X_test, y_test)))
Producción:
Accuracy of KNeighbors Classifier on training set: 0.99 Accuracy of KNeighbors Classifier on test set: 0.99
Podemos ver que los resultados son asombrosos. Podemos clasificar cada categoría de un currículum determinado con un 99% de precisión.
También podemos consultar el informe de clasificación detallado para cada clase o categoría.
print(metrics.classification_report(y_test, prediction))
Producción:
precision recall f1-score support
0 1.00 1.00 1.00 3
1 1.00 1.00 1.00 3
2 1.00 0.80 0.89 5
3 1.00 1.00 1.00 9
4 1.00 1.00 1.00 6
5 0.83 1.00 0.91 5
6 1.00 1.00 1.00 9
7 1.00 1.00 1.00 7
8 1.00 0.91 0.95 11
9 1.00 1.00 1.00 9
10 1.00 1.00 1.00 8
11 0.90 1.00 0.95 9
12 1.00 1.00 1.00 5
13 1.00 1.00 1.00 9
14 1.00 1.00 1.00 7
15 1.00 1.00 1.00 19
16 1.00 1.00 1.00 3
17 1.00 1.00 1.00 4
18 1.00 1.00 1.00 5
19 1.00 1.00 1.00 6
20 1.00 1.00 1.00 11
21 1.00 1.00 1.00 4
22 1.00 1.00 1.00 13
23 1.00 1.00 1.00 15
24 1.00 1.00 1.00 8
accuracy 0.99 193
macro avg 0.99 0.99 0.99 193
weighted avg 0.99 0.99 0.99 193
Donde, 0, 1, 2…. son las categorías de trabajo. Obtenemos las etiquetas reales del codificador de etiquetas que usamos.
le.classes_
Producción:
['Advocate', 'Arts', 'Automation Testing', 'Blockchain','Business Analyst', 'Civil Engineer', 'Data Science', 'Database','DevOps Engineer', 'DotNet Developer', 'ETL Developer','Electrical Engineering', 'HR', 'Hadoop', 'Health and fitness','Java Developer', 'Mechanical Engineer','Network Security Engineer', 'Operations Manager', 'PMO','Python Developer', 'SAP Developer', 'Sales', 'Testing','Web Designing']
Aquí ‘Abogado’ es la clase 0, ‘Artes’ es la clase 1, y así sucesivamente …
4. Código
Aquí puedes ver la implementación completa….
#Loading Libraries
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.gridspec import GridSpec
import re
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from scipy.sparse import hstack
from sklearn.multiclass import OneVsRestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
#Loading Data
resumeDataSet = pd.read_csv('../input/ResumeScreeningDataSet.csv' ,encoding='utf-8')
#EDA
plt.figure(figsize=(15,15))
plt.xticks(rotation=90)
sns.countplot(y="Category", data=resumeDataSet)
plt.savefig('../output/jobcategory_details.png')
#Pie-chart
targetCounts = resumeDataSet['Category'].value_counts().reset_index()['Category']
targetLabels = resumeDataSet['Category'].value_counts().reset_index()['index']
# Make square figures and axes
plt.figure(1, figsize=(25,25))
the_grid = GridSpec(2, 2)
plt.subplot(the_grid[0, 1], aspect=1, title="CATEGORY DISTRIBUTION")
source_pie = plt.pie(targetCounts, labels=targetLabels, autopct="%1.1f%%", shadow=True, )
plt.savefig('../output/category_dist.png')
#Data Preprocessing
def cleanResume(resumeText):
resumeText = re.sub('httpS+s*', ' ', resumeText) # remove URLs
resumeText = re.sub('RT|cc', ' ', resumeText) # remove RT and cc
resumeText = re.sub('#S+', '', resumeText) # remove hashtags
resumeText = re.sub('@S+', ' ', resumeText) # remove mentions
resumeText = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>[email protected][]^_`{|}~"""), ' ', resumeText) # remove punctuations
resumeText = re.sub(r'[^x00-x7f]',r' ', resumeText)
resumeText = re.sub('s+', ' ', resumeText) # remove extra whitespace
return resumeText
resumeDataSet['cleaned_resume'] = resumeDataSet.Resume.apply(lambda x: cleanResume(x))
var_mod = ['Category']
le = LabelEncoder()
for i in var_mod:
resumeDataSet[i] = le.fit_transform(resumeDataSet[i])
requiredText = resumeDataSet['cleaned_resume'].values
requiredTarget = resumeDataSet['Category'].values
word_vectorizer = TfidfVectorizer(
sublinear_tf=True,
stop_words="english",
max_features=1500)
word_vectorizer.fit(requiredText)
WordFeatures = word_vectorizer.transform(requiredText)
#Model Building X_train,X_test,y_train,y_test = train_test_split(WordFeatures,requiredTarget,random_state=0, test_size=0.2) print(X_train.shape) print(X_test.shape) clf = OneVsRestClassifier(KNeighborsClassifier()) clf.fit(X_train, y_train) prediction = clf.predict(X_test)
#Results
print('Accuracy of KNeighbors Classifier on training set: {:.2f}'.format(clf.score(X_train, y_train)))
print('Accuracy of KNeighbors Classifier on test set: {:.2f}'.format(clf.score(X_test, y_test)))
print("n Classification report for classifier %s:n%sn" % (clf, metrics.classification_report(y_test, prediction)))
5. Conclusión
En este artículo, aprendimos cómo se pueden aplicar el aprendizaje automático y el procesamiento del lenguaje natural para mejorar nuestra vida diaria a través del ejemplo de la detección de currículum vítae. Acabamos de clasificar casi 1000 currículums en pocos minutos en sus respectivas categorías con un 99% de precisión.
Comuníquese en la sección de comentarios si tiene alguna pregunta.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





