Introducción
El aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... está ganando fuerza rápidamente a medida que surgen más y más artículos de investigación de todo el mundo. Sin duda, estos documentos contienen una gran cantidad de información, pero a menudo pueden ser difíciles de analizar. Y para comprenderlos, es posible que tenga que revisar ese documento varias veces (¡y tal vez incluso otros documentos dependientes!).
Esta es realmente una tarea desalentadora para los no académicos como nosotros.

Personalmente, encuentro la tarea de revisar un artículo de investigación, interpretar el quid detrás de él e implementar el código como una habilidad importante que todo entusiasta y practicante del aprendizaje profundo debería poseer. La implementación práctica de ideas de investigación saca a relucir el proceso de pensamiento del autor y también ayuda a transformar esas ideas en aplicaciones de la industria del mundo real.
Entonces, en este artículo (y la siguiente serie de artículos) mi motivo para escribir es doble:
- Permita que los lectores se mantengan al día con la investigación de vanguardia dividiendo los artículos de aprendizaje profundo en conceptos comprensibles.
- Aprender a convertir ideas de investigación en código para mí mismo y animar a las personas a que lo hagan simultáneamente.
Este artículo asume que tiene un buen conocimiento de los conceptos básicos del aprendizaje profundo. En caso de que no lo necesite, o simplemente necesite un repaso, consulte primero los artículos a continuación y luego regrese aquí pronto:
Tabla de contenido
- Resumen del documento «Profundizar en las convoluciones»
- Objetivo del trabajo
- Detalles arquitectónicos propuestos
- Metodología de formación
- Implementación de GoogLeNet en Keras
Resumen del documento «Profundizar en las convoluciones»
Este artículo se centra en el papel «Profundizar con las convoluciones» de donde surgió la idea distintiva de la red de inicio. La red de inicio se consideró una vez una arquitectura (o modelo) de aprendizaje profundo de última generación para resolver problemas de detección y reconocimiento de imágenes.
Presentó un rendimiento revolucionario en el Desafío de reconocimiento visual ImageNet (en 2014), que es una plataforma de renombre para la evaluación comparativa de algoritmos de detección y reconocimiento de imágenes. Junto con esto, se inició una gran cantidad de investigaciones en la creación de nuevas arquitecturas de aprendizaje profundo con ideas innovadoras e impactantes.
Repasaremos las principales ideas y sugerencias propuestas en el documento mencionado anteriormente y trataremos de comprender las técnicas que contiene. En palabras del autor:
«En este artículo, nos centraremos en una arquitectura de red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... profunda eficiente para la visión por computadora, cuyo nombre en código es Inception, que deriva su nombre de (…) el famoso meme de Internet» necesitamos ir más profundo «.

Eso suena intrigante, ¿no? Bueno, ¡sigue leyendo entonces!
Objetivo del trabajo
Existe una forma simple pero poderosa de crear mejores modelos de aprendizaje profundo. Puede simplemente hacer un modelo más grande, ya sea en términos de profundidad, es decir, número de capas, o el número de neuronas en cada capa. Pero como puede imaginar, esto a menudo puede crear complicaciones:
- Cuanto más grande es el modelo, más propenso a sobreajustarse. Esto es particularmente notable cuando los datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... son pequeños.
- Aumentar la cantidad de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... significa que necesita aumentar sus recursos computacionales existentes
Una solución para esto, como sugiere el documento, es pasar a arquitecturas de red escasamente conectadas que reemplazarán las arquitecturas de red completamente conectadas, especialmente dentro de las capas convolucionales. Esta idea se puede conceptualizar en las siguientes imágenes:
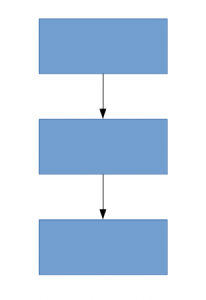
Arquitectura densamente conectada
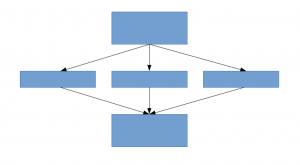
Arquitectura escasamente conectada
Este artículo propone una nueva idea de creación de arquitecturas profundas. Este enfoque le permite mantener el «presupuesto computacional», mientras aumenta la profundidad y el ancho de la red. ¡Suena demasiado bueno para ser verdad! Así es como se ve la idea conceptualizada:
Veamos la arquitectura propuesta con un poco más de detalle.
Detalles arquitectónicos propuestos
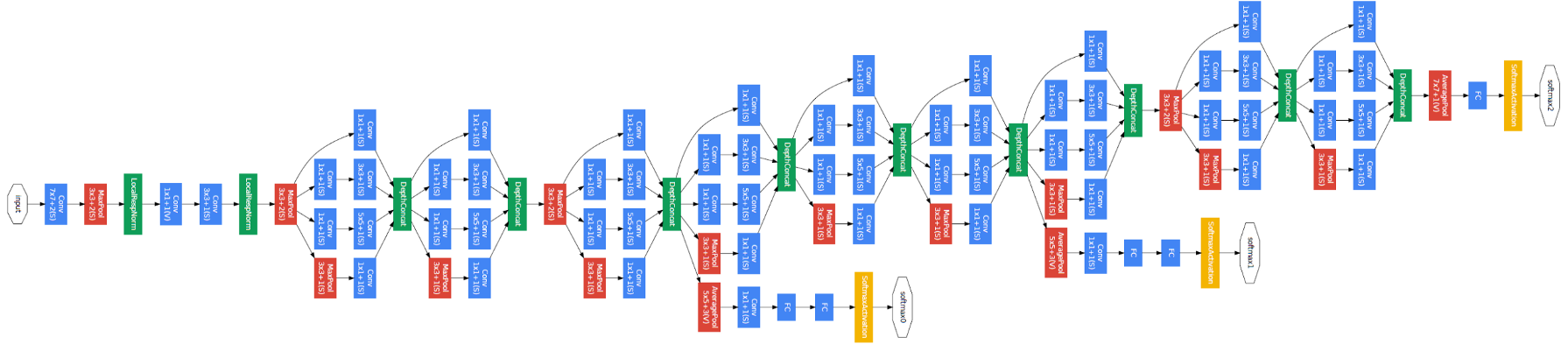
El documento propone un nuevo tipo de arquitectura: GoogLeNet o Inception v1. Es básicamente una red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... (CNN) que tiene 27 capas de profundidad.. A continuación se muestra el resumen del modelo:

Observe en la imagen de arriba que hay una capa llamada capa de inicio. Esta es en realidad la idea principal detrás del enfoque del documento. La capa inicial es el concepto central de una arquitectura escasamente conectada.
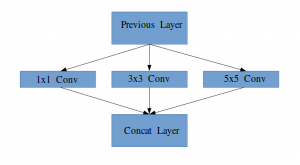
Idea de un módulo de inicio
Permítanme explicar con un poco más de detalle de qué se trata una capa de inicio. Tomando un extractoEl extracto es una sustancia obtenida mediante la concentración de compuestos de origen vegetal, animal o mineral. Se utiliza en diversas aplicaciones, como la industria alimentaria, farmacéutica y cosmética. Los extractos pueden presentarse en forma líquida, en polvo o como tinturas, y su producción implica técnicas como la maceración, la destilación o la extracción con solventes. Su uso permite aprovechar las propiedades beneficiosas de los ingredientes originales de manera más... del artículo:
«(Capa de inicio) es una combinación de todas esas capas (es decir, capa convolucionalLa capa convolucional, fundamental en las redes neuronales convolucionales (CNN), se utiliza principalmente para el procesamiento de datos con estructuras en forma de cuadrícula, como imágenes. Esta capa aplica filtros que extraen características relevantes, como bordes y texturas, permitiendo que el modelo reconozca patrones complejos. Su capacidad para reducir la dimensionalidad de los datos y mantener información esencial la convierte en una herramienta clave en tareas de visión por computadora... 1 × 1, capa convolucional 3 × 3, capa convolucional 5 × 5) con sus bancos de filtros de salida concatenados en un único vector de salida que forma la entrada del siguiente escenario.»
Junto con las capas mencionadas anteriormente, hay dos complementos principales en la capa de inicio original:
- Capa convolucional 1 × 1 antes de aplicar otra capa, que se utiliza principalmente para la reducción de dimensionalidad
- Una capa de agrupación máxima paralela, que proporciona otra opción a la capa de inicio
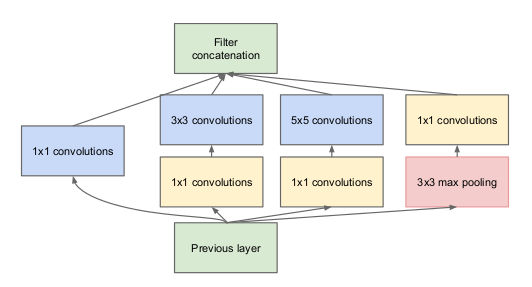
Capa de inicio
Para comprender la importancia de la estructura de la capa inicial, el autor recurre al principio de Hebbiano del aprendizaje humano. Esto dice que «las neuronas que se disparan juntas, se conectan juntas». El autor sugiere que Al crear una capa posterior en un modelo de aprendizaje profundo, se debe prestar atención a los aprendizajes de la capa anterior.
Supongamos, por ejemplo, que una capa de nuestro modelo de aprendizaje profundo ha aprendido a centrarse en partes individuales de un rostro. La siguiente capa de la red probablemente se centraría en la cara general de la imagen para identificar los diferentes objetos presentes allí. Ahora, para hacer esto, la capa debe tener los tamaños de filtro apropiados para detectar diferentes objetos.
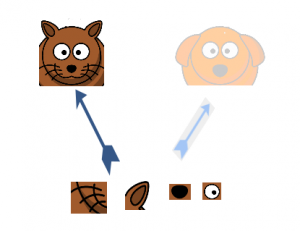
Aquí es donde la capa inicial pasa a primer plano. Permite que las capas internas seleccionen y elijan qué tamaño de filtro será relevante para conocer la información requerida. Entonces, incluso si el tamaño de la cara en la imagen es diferente (como se ve en las imágenes a continuación), la capa funciona en consecuencia para reconocer la cara. Para la primera imagen, probablemente necesitaría un tamaño de filtro más alto, mientras que tomaría uno más bajo para la segunda imagen.

La arquitectura general, con todas las especificaciones, se ve así:
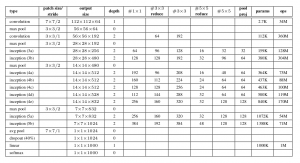
Metodología de formación
Tenga en cuenta que esta arquitectura surgió en gran parte debido a que los autores participaron en un desafío de detección y reconocimiento de imágenes. Por lo tanto, hay bastantes «campanas y silbidos» que han explicado en el documento. Éstos incluyen:
- El hardware que usaron para entrenar a los modelos.
- La técnica de aumento de datos para crear el conjunto de datos de entrenamiento.
- Los hiperparámetros de la red neuronal, como la técnica de optimización y el programa de tasas de aprendizaje.
- Formación auxiliar necesaria para entrenar el modelo.
- Técnicas de ensamble que usaron para construir la presentación final.
Entre estos, la formación auxiliar realizada por los autores es bastante interesante y novedosa por naturaleza. Así que nos centraremos en eso por ahora. Los detalles del resto de técnicas se pueden tomar del propio artículo, o en la implementación que veremos a continuación.
Para evitar que la parte media de la red “desaparezca”, los autores introdujeron dos clasificadores auxiliares (los recuadros de color púrpura en la imagen). Básicamente, aplicaron softmax a las salidas de dos de los módulos de inicio y calcularon una pérdida auxiliar sobre las mismas etiquetas. La función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y... total es una suma ponderada de la pérdida auxiliar y la pérdida real. El valor de peso utilizado en el papel fue 0,3 por cada pérdida auxiliar.
Implementación de GoogLeNet en Keras
Ahora que ha entendido la arquitectura de GoogLeNet y la intuición detrás de ella, ¡es hora de encender Python e implementar nuestros aprendizajes usando Keras! Usaremos el conjunto de datos CIFAR-10 para este propósito.

CIFAR-10 es un conjunto de datos de clasificación de imágenes popular. Consta de 60.000 imágenes de 10 clases (cada clase se representa como una fila en la imagen de arriba). El conjunto de datos se divide en 50.000 imágenes de entrenamiento y 10.000 imágenes de prueba.
Tenga en cuenta que debe tener instaladas las bibliotecas necesarias para implementar el código que veremos en esta sección. Esto incluye Keras y TensorFlow (como back-end para Keras). Puede consultar el guía de instalación oficial en caso de que no tenga Keras ya instalado en su máquina.
Ahora que nos hemos ocupado de los requisitos previos, finalmente podemos comenzar a codificar la teoría que cubrimos en las secciones anteriores. Lo primero que debemos hacer es importar todas las bibliotecas y módulos necesarios que usaremos a lo largo del código.
import keras
from keras.layers.core import Layer
import keras.backend as K
import tensorflow as tf
from keras.datasets import cifar10
from keras.models import Model
from keras.layers import Conv2D, MaxPool2D,
Dropout, Dense, Input, concatenate,
GlobalAveragePooling2D, AveragePooling2D,
Flatten
import cv2
import numpy as np
from keras.datasets import cifar10
from keras import backend as K
from keras.utils import np_utils
import math
from keras.optimizers import SGD
from keras.callbacks import LearningRateScheduler
Luego cargaremos el conjunto de datos y realizaremos algunos pasos de preprocesamiento. Esta es una tarea crítica antes de que se entrene el modelo de aprendizaje profundo.
num_classes = 10
def load_cifar10_data(img_rows, img_cols):
# Load cifar10 training and validation sets
(X_train, Y_train), (X_valid, Y_valid) = cifar10.load_data()
# Resize training images
X_train = np.array([cv2.resize(img, (img_rows,img_cols)) for img in X_train[:,:,:,:]])
X_valid = np.array([cv2.resize(img, (img_rows,img_cols)) for img in X_valid[:,:,:,:]])
# Transform targets to keras compatible format
Y_train = np_utils.to_categorical(Y_train, num_classes)
Y_valid = np_utils.to_categorical(Y_valid, num_classes)
X_train = X_train.astype('float32')
X_valid = X_valid.astype('float32')
# preprocess data
X_train = X_train / 255.0
X_valid = X_valid / 255.0
return X_train, Y_train, X_valid, Y_valid
X_train, y_train, X_test, y_test = load_cifar10_data(224, 224)
Ahora, definiremos nuestra arquitectura de aprendizaje profundo. Definiremos rápidamente una función para hacer esto, que, cuando se le da la información necesaria, nos devuelve toda la capa de inicio.
def inception_module(x,
filters_1x1,
filters_3x3_reduce,
filters_3x3,
filters_5x5_reduce,
filters_5x5,
filters_pool_proj,
name=None):
conv_1x1 = Conv2D(filters_1x1, (1, 1), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filters_3x3_reduce, (1, 1), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filters_3x3, (3, 3), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_3x3)
conv_5x5 = Conv2D(filters_5x5_reduce, (1, 1), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_5x5 = Conv2D(filters_5x5, (5, 5), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_5x5)
pool_proj = MaxPool2D((3, 3), strides=(1, 1), padding='same')(x)
pool_proj = Conv2D(filters_pool_proj, (1, 1), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(pool_proj)
output = concatenate([conv_1x1, conv_3x3, conv_5x5, pool_proj], axis=3, name=name)
return output
Luego crearemos la arquitectura GoogLeNet, como se menciona en el documento.
kernel_init = keras.initializers.glorot_uniform()
bias_init = keras.initializers.Constant(value=0.2)
input_layer = Input(shape=(224, 224, 3))
x = Conv2D(64, (7, 7), padding='same', strides=(2, 2), activation='relu', name='conv_1_7x7/2', kernel_initializer=kernel_init, bias_initializer=bias_init)(input_layer)
x = MaxPool2D((3, 3), padding='same', strides=(2, 2), name='max_pool_1_3x3/2')(x)
x = Conv2D(64, (1, 1), padding='same', strides=(1, 1), activation='relu', name='conv_2a_3x3/1')(x)
x = Conv2D(192, (3, 3), padding='same', strides=(1, 1), activation='relu', name='conv_2b_3x3/1')(x)
x = MaxPool2D((3, 3), padding='same', strides=(2, 2), name='max_pool_2_3x3/2')(x)
x = inception_module(x,
filters_1x1=64,
filters_3x3_reduce=96,
filters_3x3=128,
filters_5x5_reduce=16,
filters_5x5=32,
filters_pool_proj=32,
name='inception_3a')
x = inception_module(x,
filters_1x1=128,
filters_3x3_reduce=128,
filters_3x3=192,
filters_5x5_reduce=32,
filters_5x5=96,
filters_pool_proj=64,
name='inception_3b')
x = MaxPool2D((3, 3), padding='same', strides=(2, 2), name='max_pool_3_3x3/2')(x)
x = inception_module(x,
filters_1x1=192,
filters_3x3_reduce=96,
filters_3x3=208,
filters_5x5_reduce=16,
filters_5x5=48,
filters_pool_proj=64,
name='inception_4a')
x1 = AveragePooling2D((5, 5), strides=3)(x)
x1 = Conv2D(128, (1, 1), padding='same', activation='relu')(x1)
x1 = Flatten()(x1)
x1 = Dense(1024, activation='relu')(x1)
x1 = Dropout(0.7)(x1)
x1 = Dense(10, activation='softmax', name='auxilliary_output_1')(x1)
x = inception_module(x,
filters_1x1=160,
filters_3x3_reduce=112,
filters_3x3=224,
filters_5x5_reduce=24,
filters_5x5=64,
filters_pool_proj=64,
name='inception_4b')
x = inception_module(x,
filters_1x1=128,
filters_3x3_reduce=128,
filters_3x3=256,
filters_5x5_reduce=24,
filters_5x5=64,
filters_pool_proj=64,
name='inception_4c')
x = inception_module(x,
filters_1x1=112,
filters_3x3_reduce=144,
filters_3x3=288,
filters_5x5_reduce=32,
filters_5x5=64,
filters_pool_proj=64,
name='inception_4d')
x2 = AveragePooling2D((5, 5), strides=3)(x)
x2 = Conv2D(128, (1, 1), padding='same', activation='relu')(x2)
x2 = Flatten()(x2)
x2 = Dense(1024, activation='relu')(x2)
x2 = Dropout(0.7)(x2)
x2 = Dense(10, activation='softmax', name='auxilliary_output_2')(x2)
x = inception_module(x,
filters_1x1=256,
filters_3x3_reduce=160,
filters_3x3=320,
filters_5x5_reduce=32,
filters_5x5=128,
filters_pool_proj=128,
name='inception_4e')
x = MaxPool2D((3, 3), padding='same', strides=(2, 2), name='max_pool_4_3x3/2')(x)
x = inception_module(x,
filters_1x1=256,
filters_3x3_reduce=160,
filters_3x3=320,
filters_5x5_reduce=32,
filters_5x5=128,
filters_pool_proj=128,
name='inception_5a')
x = inception_module(x,
filters_1x1=384,
filters_3x3_reduce=192,
filters_3x3=384,
filters_5x5_reduce=48,
filters_5x5=128,
filters_pool_proj=128,
name='inception_5b')
x = GlobalAveragePooling2D(name='avg_pool_5_3x3/1')(x)
x = Dropout(0.4)(x)
x = Dense(10, activation='softmax', name='output')(x)
model = Model(input_layer, [x, x1, x2], name='inception_v1')
Resumamos nuestro modelo para comprobar si nuestro trabajo hasta ahora ha ido bien.
El modelo se ve bien, como puede medir a partir de la salida anterior. Podemos agregar algunos toques finales antes de entrenar nuestro modelo. Definiremos lo siguiente:
- Función de pérdida para cada capa de salidaLa "capa de salida" es un concepto utilizado en el ámbito de la tecnología de la información y el diseño de sistemas. Se refiere a la última capa de un modelo de software o arquitectura que se encarga de presentar los resultados al usuario final. Esta capa es crucial para la experiencia del usuario, ya que permite la interacción directa con el sistema y la visualización de datos procesados....
- Peso asignado a esa capa de salida
- Función de optimización, que se modifica para incluir una disminución de peso después de cada 8 épocas.
- Métrica de evaluación
epochs = 25
initial_lrate = 0.01
def decay(epoch, steps=100):
initial_lrate = 0.01
drop = 0.96
epochs_drop = 8
lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
sgd = SGD(lr=initial_lrate, momentum=0.9, nesterov=False)
lr_sc = LearningRateScheduler(decay, verbose=1)
model.compile(loss=['categorical_crossentropy', 'categorical_crossentropy', 'categorical_crossentropy'], loss_weights=[1, 0.3, 0.3], optimizer=sgd, metrics=['accuracy'])
¡Nuestro modelo ya está listo! Pruébelo para comprobar cómo funciona.
history = model.fit(X_train, [y_train, y_train, y_train], validation_data=(X_test, [y_test, y_test, y_test]), epochs=epochs, batch_size=256, callbacks=[lr_sc])
A continuación se muestra el resultado que obtuve al entrenar el modelo:
Nuestro modelo dio una impresionante precisión del 80% + en el conjunto de validación, lo que demuestra que realmente vale la pena comprobar esta arquitectura de modelo.
Notas finales
Este fue un artículo realmente agradable de escribir y espero que lo haya encontrado igualmente útil. Inception v1 fue el punto focal de este artículo, en el que expliqué el meollo de la cuestión de este marco y demostré cómo implementarlo desde cero en Keras.
En los próximos artículos, me centraré en los avances en las arquitecturas Inception. Estos avances se detallaron en artículos posteriores, a saber, Inception v2, Inception v3, etc. Y sí, son tan intrigantes como sugiere el nombre, ¡así que estad atentos!
Si tiene alguna sugerencia / comentario relacionado con el artículo, publíquelo en la sección de comentarios a continuación.





