Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
máquina. Está inspirado en el funcionamiento de un cerebro humano y, por lo tanto, es un conjunto de algoritmos de redes neuronales que intenta imitar el funcionamiento de un cerebro humano y aprender de las experiencias.
En este artículo, vamos a aprender cómo funciona una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... básica y cómo se mejora a sí misma para hacer las mejores predicciones.
Tabla de contenidos
- Redes neuronales y sus componentes
- Perceptrón y perceptrón multicapa
- Trabajo paso a paso de la red neuronal
- Propagación hacia atrás y cómo funciona
- Breve acerca de las funciones de activación
Redes neuronales artificiales y sus componentes
Redes neuronales es un sistema de aprendizaje computacional que utiliza una red de funciones para comprender y traducir una entrada de datos de una forma en una salida deseada, normalmente en otra forma. El concepto de red neuronal artificial se inspiró en la biología humana y la forma en que neuronas del cerebro humano funcionan juntos para comprender las entradas de los sentidos humanos.
En palabras simples, las redes neuronales son un conjunto de algoritmos que intenta reconocer los patrones, las relaciones y la información de los datos a través del proceso que se inspira y funciona como el cerebro / la biología humanos.
Componentes / Arquitectura de la red neuronal
Una red neuronal simple consta de tres componentes :
- Capa de entradaLa "capa de entrada" se refiere al nivel inicial en un proceso de análisis de datos o en arquitecturas de redes neuronales. Su función principal es recibir y procesar la información bruta antes de que esta sea transformada por capas posteriores. En el contexto de machine learning, una adecuada configuración de la capa de entrada es crucial para garantizar la efectividad del modelo y optimizar su rendimiento en tareas específicas....
- Capa oculta
- Capa de salidaLa "capa de salida" es un concepto utilizado en el ámbito de la tecnología de la información y el diseño de sistemas. Se refiere a la última capa de un modelo de software o arquitectura que se encarga de presentar los resultados al usuario final. Esta capa es crucial para la experiencia del usuario, ya que permite la interacción directa con el sistema y la visualización de datos procesados....

Fuente: Wikipedia
Capa de entrada: También conocidos como nodos de entrada, son las entradas / información del mundo exterior que se proporciona al modelo para aprender y extraer conclusiones. Los nodos de entrada pasan la información a la siguiente capa, es decir, capa oculta.
Capa oculta: La capa oculta es el conjunto de neuronas donde se realizan todos los cálculos sobre los datos de entrada. Puede haber cualquier cantidad de capas ocultas en una red neuronal. La red más simple consta de una sola capa oculta.
Capa de salida: La capa de salida es la salida / conclusiones del modelo derivadas de todos los cálculos realizados. Puede haber uno o varios nodos en la capa de salida. Si tenemos un problema de clasificación binaria, el nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... de salida es 1, pero en el caso de clasificación de clases múltiples, los nodos de salida pueden ser más de 1.
Perceptrón y perceptrón multicapa
Perceptrón es una forma simple de red neuronal y consta de una sola capa donde se realizan todos los cálculos matemáticos.
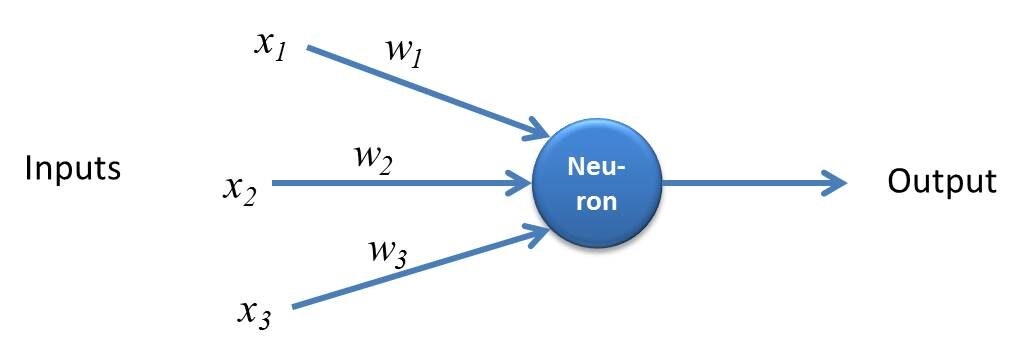
Fuente: kindsonthegenius.com
Mientras que, Perceptrón multicapa también conocido como Redes neuronales artificiales Consiste en más de una percepción que se agrupa para formar una red neuronal de múltiples capas.
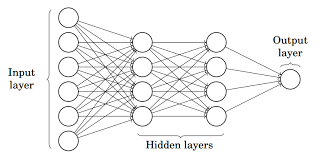
Fuente: Medio
En la imagen de arriba, la red neuronal artificial consta de cuatro capas interconectadas entre sí:
- Una capa de entrada, con 6 nodos de entrada.
- Capa 1 oculta, con 4 nodos ocultos / 4 perceptrones
- Capa oculta 2, con 4 nodos ocultos
- Capa de salida con 1 nodo de salida
Paso a paso Working de la red neuronal artificial
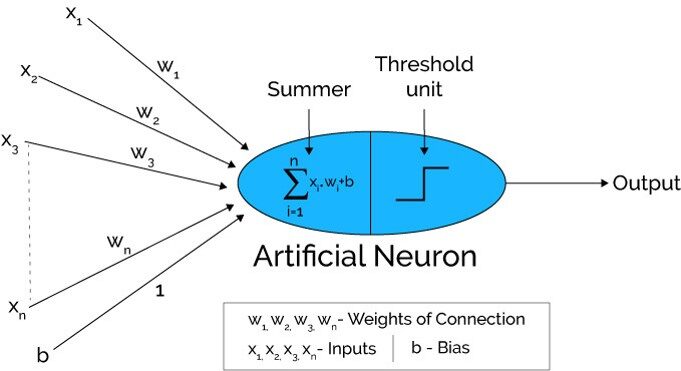
Fuente: Xenonstack.com
-
En el primer paso Las unidades de entrada se pasan, es decir, los datos se pasan con algunos pesos adjuntos a la capa oculta.. Podemos tener cualquier cantidad de capas ocultas. En la imagen de arriba, las entradas x1,X2,X3,….Xnorte esta pasado.
-
Cada capa oculta consta de neuronas. Todas las entradas están conectadas a cada neurona.
-
Después de transmitir las entradas, todo el cálculo se realiza en la capa oculta (Óvalo azul en la imagen)
El cálculo realizado en capas ocultas se realiza en dos pasos que son los siguientes :
-
En primer lugar, todas las entradas se multiplican por sus pesos. El peso es el gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... o coeficiente de cada variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos..... Muestra la fuerza de la entrada particular. Después de asignar los pesos, se agrega una variable de sesgo. Parcialidad es una constante que ayuda al modelo a encajar de la mejor manera posible.
Z1 = W1*En1 + W2*En2 + W3*En3 + W4*En4 + W5*En5 + b
W1, W2, W3, W4, W5 son los pesos asignados a las entradas In1, En2, En3, En4, En5, y b es el sesgo.
- Luego, en el segundo paso, el La función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones.... se aplica a la ecuación lineal Z1. La función de activación es una transformación no lineal que se aplica a la entrada antes de enviarla a la siguiente capa de neuronas. La importancia de la función de activación es inculcar la no linealidad en el modelo.
Hay varias funciones de activación que se enumerarán en la siguiente sección.
-
Todo el proceso descrito en el punto 3 se realiza en cada capa oculta. Después de pasar por cada capa oculta, pasamos a la última capa, es decir, nuestra capa de salida que nos da la salida final.
El proceso explicado anteriormente se conoce como propagación de reenvío.
-
Después de obtener las predicciones de la capa de salida, se calcula el error, es decir, la diferencia entre la salida real y la prevista.
Si el error es grande, entonces se toman los pasos para minimizar el error y con el mismo propósito, Se realiza la propagación hacia atrás.
¿Qué es la propagación hacia atrás y cómo funciona?
La propagación inversa es el proceso de actualizar y encontrar los valores óptimos de pesos o coeficientes que ayuda al modelo a minimizar el error, es decir, la diferencia entre los valores reales y predichos.
Pero aquí está la pregunta: ¿Cómo se actualizan los pesos y se calculan los nuevos pesos?
Los pesos se actualizan con la ayuda de optimizadores.. Los optimizadores son los métodos / formulaciones matemáticas para cambiar los atributos de las redes neuronales, es decir, los pesos para minimizar el error.
Propagación hacia atrás con pendiente descendente
Gradient Descent es uno de los optimizadores que ayuda a calcular los nuevos pesos. Entendamos paso a paso cómo Gradient Descent optimiza la función de costo.
En la imagen de abajo, la curva es nuestra curva de función de costo y nuestro objetivo es minimizar el error de tal manera que Jmin es decir, se alcanzan los mínimos globales.
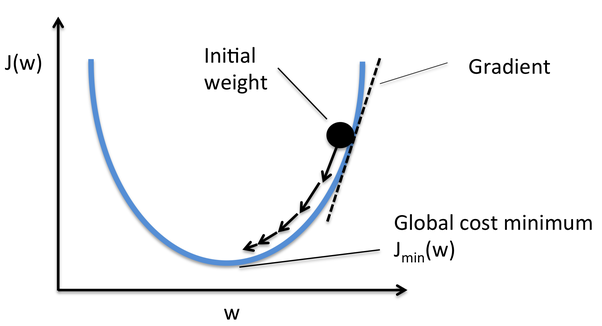
Fuente: Quora
Pasos para alcanzar los mínimos globales:
-
Primero, los pesos se inicializan aleatoriamente es decir, el valor aleatorio del peso y las intersecciones se asignan al modelo mientras que la propagación hacia adelante y los errores se calculan después de todo el cálculo. (Como se discutió anteriormente)
-
Entonces el el gradiente se calcula, es decir, derivada del error con ponderaciones actuales
-
Luego, los nuevos pesos se calculan utilizando la fórmula siguiente, donde a es la tasa de aprendizaje que es el parámetro también conocido como tamaño de paso para controlar la velocidad o los pasos de la retropropagación. Proporciona un control adicional sobre qué tan rápido queremos movernos en la curva para alcanzar los mínimos globales.
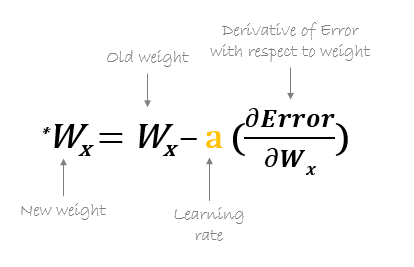
Fuente: hmkcode.com
4.Este proceso de calcular los nuevos pesos, luego los errores de los nuevos pesos y luego la actualización de los pesos. continúa hasta que alcanzamos los mínimos globales y la pérdida se minimiza.
Un punto a tener en cuenta aquí es que la tasa de aprendizaje, es decir, a en nuestra actualización de peso La ecuación debe elegirse sabiamente. La tasa de aprendizaje es la cantidad de cambio o el tamaño del paso que se toma para alcanzar los mínimos globales. No debe ser muy pequeño ya que llevará tiempo converger, así como no debe ser muy grande que no alcanza los mínimos globales en absoluto. Por tanto, la tasa de aprendizaje es el hiperparámetro que tenemos que elegir en función del modelo.
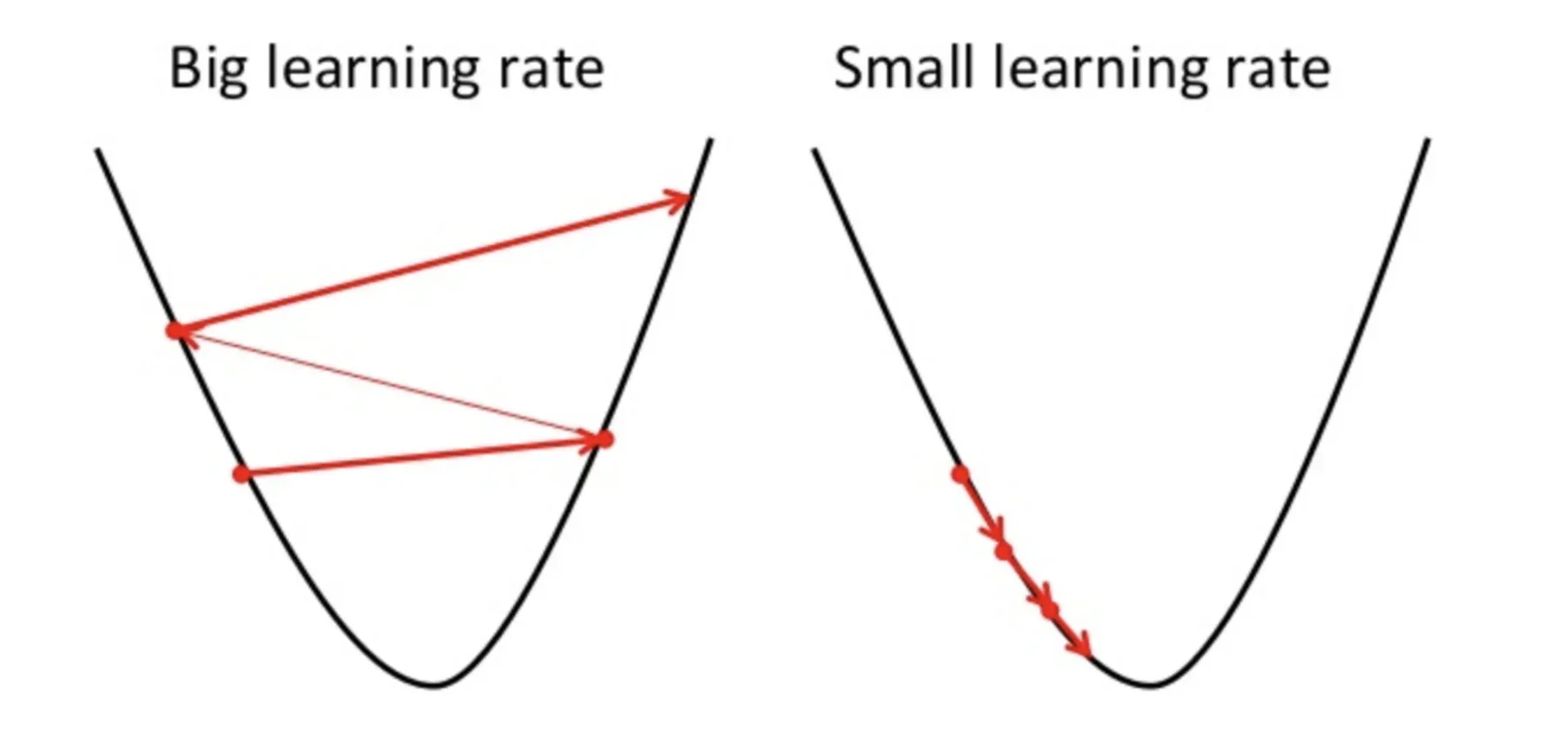
Fuente: Educative.io
Para conocer las matemáticas detalladas y la regla de la cadena de retropropagación, consulte el adjunto tutorial.
Breve acerca de las funciones de activación
Funciones de activación se adjuntan a cada neurona y son ecuaciones matemáticas que determinan si una neurona debe activarse o no en función de si la entrada de la neurona es relevante para la predicción del modelo o no. El propósito de la función de activación es introducir la no linealidad en los datos.
Varios tipos de funciones de activación son:
- Función de activación sigmoidea
- Función de activación de TanH / Tangente hiperbólica
- Función de unidad lineal rectificada (ReLULa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Definida como ( f(x) = max(0, x) ), ReLU permite que las neuronas se activen solo cuando la entrada es positiva, lo que contribuye a mitigar el problema del desvanecimiento del gradiente. Su uso ha demostrado mejorar el rendimiento en diversas tareas de aprendizaje profundo, haciendo de ReLU una opción...)
- ReLU con fugas
- Softmax
Consulte este blog para obtener una explicación detallada de las funciones de activación.
Notas finales
Aquí concluyo mi explicación paso a paso de la primera Red Neural de Aprendizaje ProfundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... que es ANA. Traté de explicar el proceso de Reenvío de propagación y Retropropagación de la manera más simple posible. Espero que haya valido la pena leer este artículo 🙂
Por favor, siéntete libre de conectarte conmigo en LinkedIn y comparta sus valiosos aportes. Por favor, consulte mis otros artículos aquí.
Sobre el Autor
Soy Deepanshi Dhingra, actualmente trabajo como investigador de ciencia de datos y poseo conocimientos de análisis, análisis de datos exploratorios, aprendizaje automático y aprendizaje profundo.
Los medios que se muestran en este artículo sobre la red neuronal artificial no son propiedad de DataPeaker y se utilizan a discreción del autor.





