Introducción
Un desafío común con el que me encontré mientras aprendizaje del procesamiento del lenguaje natural (PNL) – ¿Podemos construir modelos para idiomas distintos del inglés? La respuesta ha sido no durante bastante tiempo. Cada idioma tiene sus propios patrones gramaticales y matices lingüísticos. Y simplemente no hay muchos conjuntos de datos disponibles en otros idiomas.
Ahí es donde interviene la última biblioteca de PNL de Stanford: StanfordNLP.
Apenas pude contener mi emoción cuando leí las noticias la semana pasada. Los autores afirmaron que StanfordNLP podría admitir más de 53 lenguajes humanos. Sí, tuve que volver a verificar ese número.
Decidí comprobarlo yo mismo. Todavía no hay un tutorial oficial para la biblioteca, así que tuve la oportunidad de experimentar y jugar con él. Y descubrí que abre un mundo de posibilidades infinitas. StanfordNLP contiene modelos previamente entrenados para idiomas asiáticos raros como hindi, chino y japonés en sus escrituras originales.

La capacidad de trabajar con varios idiomas es una maravilla que todos los entusiastas de la PNL anhelan. En este artículo, analizaremos qué es StanfordNLP, por qué es tan importante, y luego activaremos Python para verlo en vivo en acción. También tomaremos un estudio de caso en hindi para mostrar cómo funciona StanfordNLP, ¡no querrá perderse eso!
Tabla de contenido
- ¿Qué es StanfordNLP y por qué debería usarlo?
- Configuración de StanfordNLP en Python
- Uso de StanfordNLP para realizar tareas básicas de PNL
- Implementación de StanfordNLP en hindi
- Uso de la API de CoreNLP para análisis de texto
¿Qué es StanfordNLP y por qué debería usarlo?
Aquí está la descripción de StanfordNLP por los propios autores:
StanfordNLP es la combinación del paquete de software utilizado por el equipo de Stanford en la tarea compartida CoNLL 2018 sobre análisis de dependencia universal y la interfaz oficial de Python del grupo para el Software Stanford CoreNLP.
¡Es demasiada información de una sola vez! Vamos a desglosarlo:
- CoNLL es una conferencia anual sobre el aprendizaje del lenguaje natural. Los equipos que representan a los institutos de investigación de todo el mundo tratan de resolver un PNL tarea basada
- Una de las tareas del año pasado fue «Análisis multilingüe de texto sin formato a dependencias universales». En términos simples, significa analizar datos de texto no estructurados de varios idiomas en anotaciones útiles de las dependencias universales.
- Universal Dependencies es un marco que mantiene la coherencia en las anotaciones. Estas anotaciones se generan para el texto independientemente del idioma que se esté analizando.
- La presentación de Stanford ocupó el primer lugar en 2017. Se perdieron la primera posición en 2018 debido a un error de software (terminó en el cuarto lugar)
StanfordNLP es una colección de modelos de última generación previamente entrenados. Estos modelos fueron utilizados por los investigadores en las competencias CoNLL 2017 y 2018. Todos los modelos se basan en PyTorch y se pueden entrenar y evaluar con sus propios datos anotados. ¡Impresionante!
 Adicionalmente, StanfordNLP también contiene un contenedor oficial de la popular biblioteca gigante de PNL: CoreNLP. Esto se había limitado de alguna manera al ecosistema de Java hasta ahora. Debería consultar este tutorial para obtener más información sobre CoreNLP y cómo funciona en Python.
Adicionalmente, StanfordNLP también contiene un contenedor oficial de la popular biblioteca gigante de PNL: CoreNLP. Esto se había limitado de alguna manera al ecosistema de Java hasta ahora. Debería consultar este tutorial para obtener más información sobre CoreNLP y cómo funciona en Python.
A continuación se presentan algunas razones más por las que debería consultar esta biblioteca:
- Implementación nativa de Python que requiere un esfuerzo mínimo para configurar
- Canalización de red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... completa para un análisis de texto sólido, que incluye:
- Tokenización
- Expansión de token de varias palabras (MWT)
- Lematización
- Etiquetado de partes del discurso (POS) y características morfológicas
- Análisis de dependencia
- Modelos neuronales previamente entrenados que admiten 53 lenguajes (humanos) presentados en 73 bancos de árboles
- Una interfaz Python estable y mantenida oficialmente para CoreNLP
¿Qué más podría pedir un entusiasta de la PNL? Ahora que tenemos una idea de lo que hace esta biblioteca, ¡demos una vuelta en Python!
Configuración de StanfordNLP en Python
Hay algunas cosas peculiares sobre la biblioteca que me dejaron perplejo al principio. Por ejemplo, necesitas Python 3.6.8 / 3.7.2 o más tarde para usar StanfordNLP. Para estar seguro, configuré un entorno separado en Anaconda para Python 3.7.1. Así es como puede hacerlo:
1. Abra el indicador de conda y escriba esto:
conda create -n stanfordnlp python=3.7.1
2. Ahora activa el entorno:
source activate stanfordnlp
3. Instale la biblioteca StanfordNLP:
pip install stanfordnlp
4. Necesitamos descargar el modelo específico de un idioma para trabajar con él. Inicie un shell de Python e importe StanfordNLP:
import stanfordnlp
luego descargue el modelo de idioma para inglés («en»):
stanfordnlp.download('en')
Esto puede llevar un tiempo dependiendo de su conexión a Internet. Estos modelos de idiomas son bastante grandes (el inglés es de 1,96 GB).
Un par de notas importantes
- StanfordNLP se basa en PyTorch 1.0.0. Podría fallar si tiene una versión anterior. A continuación, le indicamos cómo puede verificar la versión instalada en su máquina:
pip freeze | grep torch
que debería dar una salida como torch==1.0.0
- Intenté usar la biblioteca sin GPU en mi Lenovo Thinkpad E470 (8GB RAM, Intel Graphics). Recibí un error de memoria en Python bastante rápido. Por lo tanto, cambié a una máquina habilitada para GPU y le aconsejaría que hiciera lo mismo también. Puedes probar Google Colab que viene con soporte de GPU gratuito
¡Eso es todo! Vamos a sumergirnos en algunos procesos básicos de PNL de inmediato.
Uso de StanfordNLP para realizar tareas básicas de PNL
StanfordNLP viene con procesadores integrados para realizar cinco tareas básicas de PNL:
- Tokenización
- Expansión de token de varias palabras
- Lematización
- Partes del etiquetado del habla
- Análisis de dependencia
Comencemos por crear una canalización de texto:
nlp = stanfordnlp.Pipeline(processors = "tokenize,mwt,lemma,pos")
doc = nlp("""The prospects for Britain’s orderly withdrawal from the European Union on March 29 have receded further, even as MPs rallied to stop a no-deal scenario. An amendment to the draft bill on the termination of London’s membership of the bloc obliges Prime Minister Theresa May to renegotiate her withdrawal agreement with Brussels. A Tory backbencher’s proposal calls on the government to come up with alternatives to the Irish backstop, a central tenet of the deal Britain agreed with the rest of the EU.""")
los procesadores = «» El argumento se utiliza para especificar la tarea. Los cinco procesadores se toman de forma predeterminada si no se pasa ningún argumento. Aquí hay una descripción general rápida de los procesadores y lo que pueden hacer:

Veamos cada uno de ellos en acción.
Tokenización
Este proceso ocurre implícitamente una vez que se ejecuta el procesador Token. De hecho, es bastante rápido. Puedes echar un vistazo a los tokens usando print_tokens ():
doc.sentences[0].print_tokens()
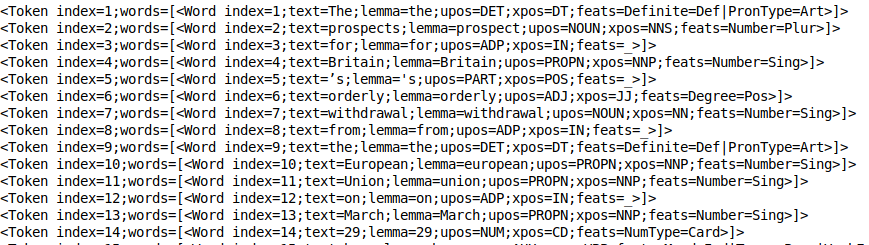
El objeto token contiene el índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... del token en la oración y una lista de objetos de palabra (en el caso de un token de varias palabras). Cada objeto de palabra contiene información útil, como el índice de la palabra, el lema del texto, la etiqueta pos (partes del discurso) y la etiqueta de hazaña (características morfológicas).
Lematización
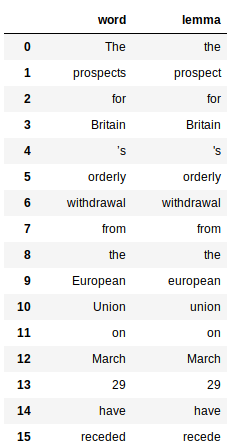
Esto implica el uso de la propiedad «lema» de las palabras generadas por el procesador de lemas. Aquí está el código para obtener el lema de todas las palabras:
Esto devuelve un pandas marco de datos para cada palabra y su lema respectivo:
Etiquetado de partes del habla (PoS)
El etiquetador de PoS es bastante rápido y funciona muy bien en todos los idiomas. Al igual que los lemas, las etiquetas PoS también son fáciles de extraer:
¿Observa el gran diccionario en el código anterior? Es solo un mapeo entre las etiquetas PoS y su significado. Esto ayuda a comprender mejor la estructura sintáctica de nuestro documento.
La salida sería un marco de datos con tres columnas: palabra, pos y exp (explicación). La columna de explicación nos brinda la mayor cantidad de información sobre el texto (y, por lo tanto, es bastante útil).
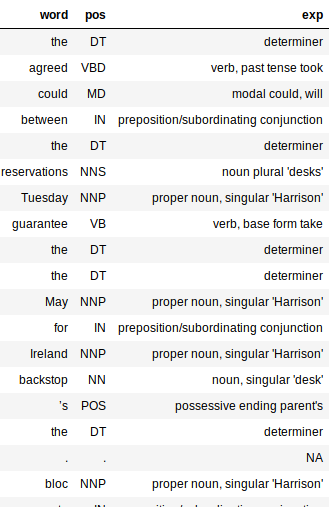
Agregar la columna de explicación hace que sea mucho más fácil evaluar qué tan preciso es nuestro procesador. Me gusta el hecho de que el etiquetador sea preciso para la mayoría de las palabras. Incluso capta el tiempo de una palabra y si está en forma básica o plural.
Extracción de dependencias
La extracción de dependencias es otra característica lista para usar de StanfordNLP. Simplemente puedes llamar print_dependencies () en una oración para obtener las relaciones de dependencia para todas sus palabras:
doc.sentences[0].print_dependencies()

La biblioteca calcula todo lo anterior durante una sola ejecución de la canalización. Esto apenas le llevará unos minutos en una máquina habilitada para GPU.
Ahora hemos descubierto una forma de realizar el procesamiento de texto básico con StanfordNLP. ¡Es hora de aprovechar el hecho de que podemos hacer lo mismo para otros 51 idiomas!
Implementación de StanfordNLP en hindi
StanfordNLP realmente se destaca por su rendimiento y soporte de análisis de texto multilingüe. Profundicemos en este último aspecto.
Procesamiento de texto en hindi (escritura devanagari)
Primero, tenemos que descargar el modelo de idioma hindi (¡comparativamente más pequeño!):
stanfordnlp.download('hi')
Ahora, tome un fragmento de texto en hindi como nuestro documento de texto:
hindi_doc = nlp("""केंद्र की मोदी सरकार ने शुक्रवार को अपना अंतरिम बजट पेश किया. कार्यवाहक वित्त मंत्री पीयूष गोयल ने अपने बजट में किसान, मजदूर, करदाता, महिला वर्ग समेत हर किसी के लिए बंपर ऐलान किए. हालांकि, बजट के बाद भी टैक्स को लेकर काफी कन्फ्यूजन बना रहा. केंद्र सरकार के इस अंतरिम बजट क्या खास रहा और किसको क्या मिला, आसान भाषा में यहां समझें""")
Esto debería ser suficiente para generar todas las etiquetas. Revisemos las etiquetas para hindi:
extract_pos(hindi_doc)
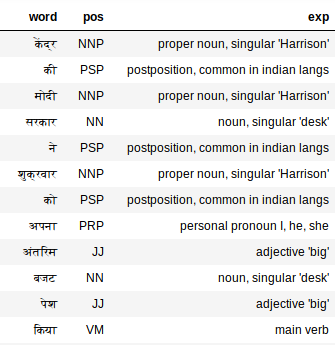
El etiquetador de PoS también funciona sorprendentemente bien en el texto hindi. Mira «अपना», por ejemplo. El etiquetador de PoS lo etiqueta como un pronombre, yo, él, ella, que es exacto.
Uso de la API de CoreNLP para análisis de texto
CoreNLP es un juego de herramientas de PNL de grado industrial probado en el tiempo que es conocido por su rendimiento y precisión. StanfordNLP ha sido declarado como una interfaz oficial de Python para CoreNLP. Esa es una GRAN victoria para esta biblioteca.
Ha habido esfuerzos antes para crear paquetes de envoltura de Python para CoreNLP, pero nada supera a una implementación oficial de los propios autores. Esto significa que la biblioteca verá actualizaciones y mejoras periódicas.
StanfordNLP necesita tres líneas de código para comenzar a utilizar la sofisticada API de CoreNLP. Literalmente, ¡solo tres líneas de código para configurarlo!
1. Descargue el paquete CoreNLP. Abra su terminal Linux y escriba el siguiente comando:
wget http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip
2. Descomprima el paquete descargado:
unzip stanford-corenlp-full-2018-10-05.zip
3. Inicie el servidor CoreNLP:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000
Nota: CoreNLP requiere Java8 para ejecutarse. Asegúrese de tener JDK y JRE 1.8.x instalados.
Ahora, asegúrese de que StanfordNLP sepa dónde está presente CoreNLP. Para eso, debe exportar $ CORENLP_HOME como la ubicación de su carpeta. En mi caso, esta carpeta estaba en el hogar en sí mismo para que mi camino sea como
export CORENLP_HOME=stanford-corenlp-full-2018-10-05/
Una vez realizados los pasos anteriores, puede iniciar el servidor y realizar solicitudes en código Python. A continuación se muestra un ejemplo completo de cómo iniciar un servidor, realizar solicitudes y acceder a los datos del objeto devuelto.
una. Configuración de CoreNLPClient
B. Análisis de dependencias y POS
C. Reconocimiento de entidades nombradas y cadenas de co-referencia
Los ejemplos anteriores apenas arañan la superficie de lo que CoreNLP puede hacer y, sin embargo, es muy interesante, pudimos lograr desde tareas básicas de PNL como el etiquetado de partes del habla hasta cosas como el reconocimiento de entidades nombradas, la extracción de cadenas de co-referencia y la búsqueda de quién escribió qué. en una oración en unas pocas líneas de código Python.
Lo que más me gusta aquí es la facilidad de uso y la mayor accesibilidad que esto trae cuando se trata de usar CoreNLP en Python.
Mis pensamientos sobre el uso de StanfordNLP – Pros y contras
Explorar una biblioteca recién lanzada fue sin duda un desafío. ¡Apenas hay documentación sobre StanfordNLP! Sin embargo, fue una experiencia de aprendizaje bastante agradable.
Algunas cosas que me emocionan con respecto al futuro de StanfordNLP:
- Su soporte listo para usar para múltiples idiomas
- El hecho de que será una interfaz oficial de Python para CoreNLP. Esto significa que solo mejorará la funcionalidad y la facilidad de uso en el futuro.
- Es bastante rápido (salvo la enorme huella de memoria)
- Configuración sencilla en Python
Sin embargo, hay algunas grietas que resolver. A continuación se muestran mis pensamientos sobre las áreas en las que StanfordNLP podría mejorar:
- El tamaño de los modelos de idioma es demasiado grande (el inglés es de 1,9 GB, el chino ~ 1,8 GB)
- La biblioteca requiere mucho código para producir funciones. Compare eso con NLTK, donde puede escribir rápidamente un prototipo; esto podría no ser posible para StanfordNLP
- Actualmente faltan funciones de visualización. Es útil tenerlo para funciones como el análisis de dependencias. StanfordNLP se queda corto aquí en comparación con bibliotecas como SpaCy
Asegúrate de revisar Documentación oficial de StanfordNLP.
Notas finales
Todavía hay una función que aún no he probado. StanfordNLP le permite entrenar modelos en sus propios datos anotados usando incrustaciones de Word2Vec / FastText. Me gustaría explorarlo en el futuro y ver qué tan efectiva es esa funcionalidad. Actualizaré el artículo cuando la biblioteca madure un poco.
Claramente, StanfordNLP se encuentra en la etapa beta. Solo mejorará a partir de aquí, por lo que este es un buen momento para comenzar a usarlo: obtenga una ventaja sobre todos los demás.
Por ahora, el hecho de que estos asombrosos kits de herramientas (CoreNLP) estén llegando al ecosistema de Python y los gigantes de la investigación como Stanford estén haciendo un esfuerzo para abrir su software en código abierto, soy optimista sobre el futuro.





