Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
El procesamiento del lenguaje natural (PNL) es un campo en el que convergen la inteligencia artificial y la lingüística. El objetivo es hacer que las computadoras comprendan el lenguaje del mundo real o el lenguaje natural para que puedan realizar tareas como respuesta a preguntas, traducción de idiomas y muchas más.
La PNL tiene muchas aplicaciones en diferentes campos.
1. La PNL permite el reconocimiento y la predicción de enfermedades basándose en historias clínicas electrónicas.
2. Se utiliza para obtener opiniones de los clientes.
3. Para ayudar a identificar noticias falsas.
4. Chatbots.
5. Monitoreo de redes sociales, etc.
¿Qué es el transformador?
La arquitectura del modelo Transformer fue presentada por Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser e Illia Polosukhin en su artículo “Attention Is All You Need”. [1]
El modelo Transformer extrae las características de cada palabra utilizando un mecanismo de auto atención para conocer la importancia de cada palabra en la oración. No se utilizan otras unidades recurrentes para extraer esta característica, son solo activaciones y sumas ponderadas, por lo que pueden ser muy eficientes y paralelizables.
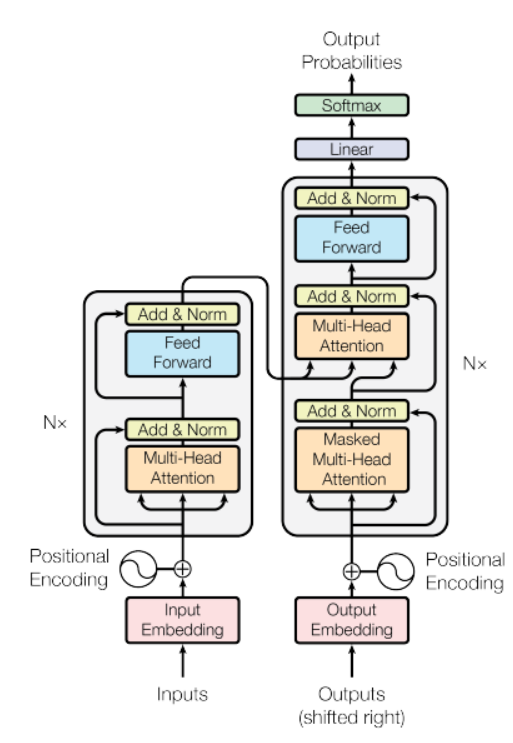
Fuente: documento «Atención es todo lo que necesita»
En la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... anterior, hay un modelo de codificador en el lado izquierdo y el descodificador en el derecho. Tanto el codificador como el decodificador contienen un bloque central de atención y una red de retroalimentación repetido N número de veces.
En la figura anterior, hay un modelo de codificador en el lado izquierdo y el descodificador en el derecho. Tanto el codificador como el decodificador contienen un bloque central de atención y una red de retroalimentación repetida N número de veces.
Tiene una pila de 6 codificadores y 6 decodificadores, el codificador contiene dos capas (subcapas), es decir, una capa de auto-atención de múltiples cabezales y una red de alimentación hacia adelante completamente conectada. El decodificador contiene tres capas (subcapas), una capa de auto-atención de múltiples cabezales, otra capa de auto-atención de múltiples cabezales para realizar la auto-atención sobre las salidas del codificador y una red de alimentación hacia adelante completamente conectada. Cada subcapa en Decoder y Encoder tiene una conexión residual con normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... de capa.
Comencemos a construir un modelo de traducción de idiomas
Aquí usaremos el conjunto de datos Multi30k. No se preocupe, el conjunto de datos se descargará con un fragmento de código.
Primero, la parte de procesamiento de datos usaremos el antorcha módulo de PyTorch. los antorcha tiene utilidades para crear conjuntos de datos que se pueden iterar fácilmente con el fin de crear un modelo de traducción de idiomas. El siguiente código descargará el conjunto de datos y también convertirá en token un texto sin procesar, construirá el vocabulario y convertirá tokens en un tensorLos tensores son estructuras matemáticas que generalizan conceptos como scalars y vectores. Se utilizan en diversas disciplinas, incluyendo física, ingeniería y aprendizaje automático, para representar datos multidimensionales. Un tensor puede ser visualizado como una matriz de múltiples dimensiones, lo que permite modelar relaciones complejas entre diferentes variables. Su versatilidad y capacidad para manejar grandes volúmenes de información los convierten en herramientas fundamentales en el análisis y procesamiento de datos.....
import math import torchtext import torch import torch.nn as nn from torchtext.data.utils import get_tokenizer from collections import Counter from torchtext.vocab import Vocab from torchtext.utils import download_from_url, extract_archive from torch.nn.utils.rnn import pad_sequence from torch.utils.data import DataLoader from torch import Tensor from torch.nn import (TransformerEncoder, TransformerDecoder,TransformerEncoderLayer, TransformerDecoderLayer) import io import time
url_base="https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/"
train_urls = ('train.de.gz', 'train.en.gz')
val_urls = ('val.de.gz', 'val.en.gz')
test_urls = ('test_2016_flickr.de.gz', 'test_2016_flickr.en.gz')
train_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in train_urls]
val_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in val_urls]
test_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in test_urls]
de_tokenizer = get_tokenizer('spacy', language="de_core_news_sm")
en_tokenizer = get_tokenizer('spacy', language="en_core_web_sm")
def build_vocab(filepath, tokenizer):
counter = Counter()
with io.open(filepath, encoding="utf8") as f:
for string_ in f:
counter.update(tokenizer(string_))
return Vocab(counter, specials=['<unk>', '<pad>', '<bos>', '<eos>'])
de_vocab = build_vocab(train_filepaths[0], de_tokenizer)
en_vocab = build_vocab(train_filepaths[1], en_tokenizer)
def data_process(filepaths):
raw_de_iter = iter(io.open(filepaths[0], encoding="utf8"))
raw_en_iter = iter(io.open(filepaths[1], encoding="utf8"))
data = []
for (raw_de, raw_en) in zip(raw_de_iter, raw_en_iter):
de_tensor_ = torch.tensor([de_vocab[token] for token in de_tokenizer(raw_de.rstrip("n"))],
dtype=torch.long)
en_tensor_ = torch.tensor([en_vocab[token] for token in en_tokenizer(raw_en.rstrip("n"))],
dtype=torch.long)
data.append((de_tensor_, en_tensor_))
return data
train_data = data_process(train_filepaths)
val_data = data_process(val_filepaths)
test_data = data_process(test_filepaths)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
PAD_IDX = de_vocab['<pad>']
BOS_IDX = de_vocab['<bos>']
EOS_IDX = de_vocab['<eos>']
Luego usaremos el módulo PyTorch DataLoader que combina un conjunto de datos y un muestreador, y nos permite iterar sobre el conjunto de datos dado. El DataLoader admite conjuntos de datos de estilo iterable y de mapa con carga de proceso único o multiproceso, también podemos personalizar el orden de carga y la fijación de memoria.
# DataLoader
def generate_batch(data_batch):
de_batch, en_batch = [], []
for (de_item, en_item) in data_batch:
de_batch.append(torch.cat([torch.tensor([BOS_IDX]), de_item, torch.tensor([EOS_IDX])], dim=0))
en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
de_batch = pad_sequence(de_batch, padding_value=PAD_IDX)
en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
return de_batch, en_batch
train_iter = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch) valid_iter = DataLoader(val_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch) test_iter = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch)
Entonces estamos diseñando el transformador. Aquí, el codificador procesa la secuencia de entrada propagándola a través de una serie de capas de red de atención de múltiples cabezales y alimentación anticipada. La salida de este codificador se denomina memoria a continuación y se alimenta al decodificador junto con los tensores de destino. El codificador y el decodificador se entrenan de un extremo a otro.
# transformer
class Seq2SeqTransformer(nn.Module):
def __init__(self, num_encoder_layers: int, num_decoder_layers: int,
emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
dim_feedforward:int = 512, dropout:float = 0.1):
super(Seq2SeqTransformer, self).__init__()
encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
self.generator = nn.Linear(emb_size, tgt_vocab_size)
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
def forward(self, src: Tensor, trg: Tensor, src_mask: Tensor,
tgt_mask: Tensor, src_padding_mask: Tensor,
tgt_padding_mask: Tensor, memory_key_padding_mask: Tensor):
src_emb = self.positional_encoding(self.src_tok_emb(src))
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
outs = self.transformer_decoder(tgt_emb, memory, tgt_mask, None,
tgt_padding_mask, memory_key_padding_mask)
return self.generator(outs)
def encode(self, src: Tensor, src_mask: Tensor):
return self.transformer_encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
return self.transformer_decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memory,
tgt_mask)
El texto que se convierte en tokens se representa mediante incrustaciones de tokens. La función de codificación posicional se agrega a la incrustación del token para que podamos obtener las nociones de orden de las palabras.
class PositionalEncoding(nn.Module):
def __init__(self, emb_size: int, dropout, maxlen: int = 5000):
super(PositionalEncoding, self).__init__()
den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
pos_embedding = torch.zeros((maxlen, emb_size))
pos_embedding[:, 0::2] = torch.sin(pos * den)
pos_embedding[:, 1::2] = torch.cos(pos * den)
pos_embedding = pos_embedding.unsqueeze(-2)
self.dropout = nn.Dropout(dropout)
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
return self.dropout(token_embedding +
self.pos_embedding[:token_embedding.size(0),:])
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size: int, emb_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens: Tensor):
return self.embedding(tokens.long()) * math.sqrt(self.emb_size)
Aquí, en el código a continuación, se crea una máscara de palabra subsiguiente para evitar que una palabra de destino preste atención a sus palabras subsiguientes. Aquí también se crean las máscaras, para enmascarar tokens de relleno de origen y destino.
def generate_square_subsequent_mask(sz):
mask = (torch.triu(torch.ones((sz, sz), device=DEVICE)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def create_mask(src, tgt):
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
src_mask = torch.zeros((src_seq_len, src_seq_len), device=DEVICE).type(torch.bool)
src_padding_mask = (src == PAD_IDX).transpose(0, 1)
tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
Luego defina los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... del modelo y cree una instancia del modelo.
SRC_VOCAB_SIZE = len(de_vocab)
TGT_VOCAB_SIZE = len(en_vocab)
EMB_SIZE = 512
NHEAD = 8
FFN_HID_DIM = 512
BATCH_SIZE = 128
NUM_ENCODER_LAYERS = 3
NUM_DECODER_LAYERS = 3
NUM_EPOCHS = 50
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS,
EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE,
FFN_HID_DIM)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
transformer = transformer.to(device)
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.Adam(
transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9
)
Defina dos funciones diferentes, es decir, para la formación y la evaluación.
def train_epoch(model, train_iter, optimizer):
model.train()
losses = 0
for idx, (src, tgt) in enumerate(train_iter):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
optimizer.zero_grad()
tgt_out = tgt[1:, :]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
loss.backward()
optimizer.step()
losses += loss.item()
torch.save(model, PATH)
return losses / len(train_iter)
def evaluate(model, val_iter):
model.eval()
losses = 0
for idx, (src, tgt) in (enumerate(valid_iter)):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:, :]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
losses += loss.item()
return losses / len(val_iter)
Ahora entrenando el modelo.
for epoch in range(1, NUM_EPOCHS+1):
start_time = time.time()
train_loss = train_epoch(transformer, train_iter, optimizer)
end_time = time.time()
val_loss = evaluate(transformer, valid_iter)
print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, Val loss: {val_loss:.3f}, "
f"Epoch time = {(end_time - start_time):.3f}s"))
Este modelo se entrena usando arquitectura de transformador de tal manera que entrena más rápido y además converge a una menor pérdida de validación en comparación con otros modelos RNN.
def greedy_decode(model, src, src_mask, max_len, start_symbol):
src = src.to(device)
src_mask = src_mask.to(device)
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(device)
for i in range(max_len-1):
memory = memory.to(device)
memory_mask = torch.zeros(ys.shape[0], memory.shape[0]).to(device).type(torch.bool)
tgt_mask = (generate_square_subsequent_mask(ys.size(0))
.type(torch.bool)).to(device)
out = model.decode(ys, memory, tgt_mask)
out = out.transpose(0, 1)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.item()
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
if next_word == EOS_IDX:
break
return ys
def translate(model, src, src_vocab, tgt_vocab, src_tokenizer):
model.eval()
tokens = [BOS_IDX] + [src_vocab.stoi[tok] for tok in src_tokenizer(src)] + [EOS_IDX]
num_tokens = len(tokens)
src = (torch.LongTensor(tokens).reshape(num_tokens, 1))
src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
tgt_tokens = greedy_decode(model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).flatten()
return " ".join([tgt_vocab.itos[tok] for tok in tgt_tokens]).replace("<bos>", "").replace("<eos>", "")
Ahora, probemos nuestro modelo de traducción.
output = translate(transformer, "Eine Gruppe von Menschen steht vor einem Iglu .", de_vocab, en_vocab, de_tokenizer) print(output)
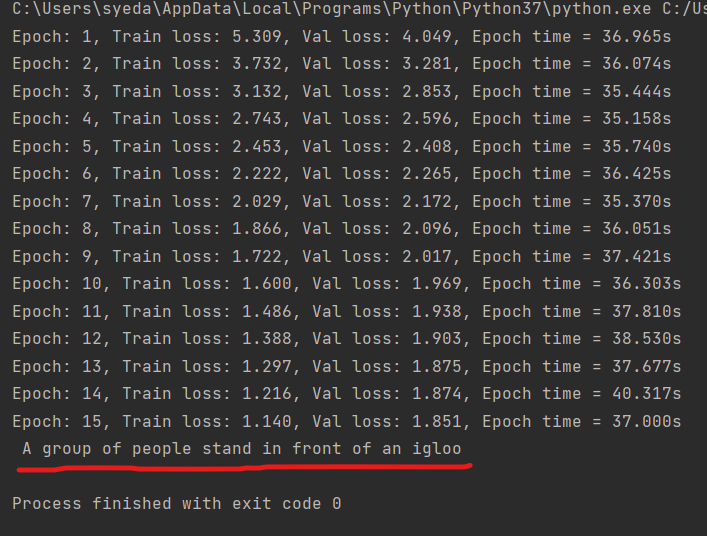
Por encima de la línea roja está el resultado del modelo de traducción. También puede compararlo con el traductor de Google.
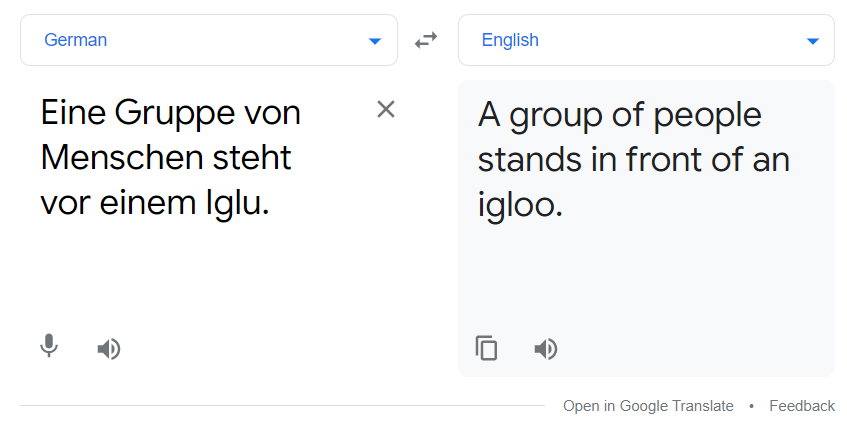
La traducción anterior y la salida de nuestro modelo coincidieron. El modelo no es el mejor, pero aún funciona hasta cierto punto.
Referencia
[1]. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser e Illia Polosukhin: atención es todo lo que necesita, diciembre de 2017, DOI: https://arxiv.org/pdf/1706.03762.pdf
También para obtener más información, consulte https://pytorch.org/tutorials/
Gracias
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





