Introducción
De vez en cuando, se desarrolla una biblioteca de Python que tiene el potencial de cambiar el panorama en el campo del aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud.... PyTorch es una de esas bibliotecas.
En las últimas semanas, he estado incursionando un poco en PyTorch. Me ha impresionado lo fácil que es comprenderlo. Entre los diversos marcos de aprendizaje profundo que he usado hasta la fecha, PyTorch ha sido el más flexible y sin esfuerzo de todos.
![]()
En este artículo, exploraremos PyTorch con un enfoque más práctico, cubriendo los conceptos básicos junto con un estudio de caso. También compararemos una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... construida desde cero tanto en numpy como en PyTorch para ver sus similitudes en la implementación.
¡Sigamos adelante!
Nota: este artículo asume que tiene un conocimiento básico del aprendizaje profundo. Si desea ponerse al día con el aprendizaje profundo, lea este artículo primero.
Además, si desea una explicación más detallada de PyTorch desde cero, comprender cómo funcionan los tensores, cómo puede realizar operaciones matemáticas y matriciales con PyTorch, le recomiendo que consulte Una guía para principiantes de PyTorch y cómo funciona desde cero.
Tabla de contenido
- Una descripción general de PyTorch
- Sumergirse en los tecnicismos
- Construyendo una red neuronal en Numpy vs.PyTorch
- Comparación con otras bibliotecas de aprendizaje profundo
- Estudio de caso: solución de un problema de reconocimiento de imágenes con PyTorch
Si prefiere abordar los siguientes conceptos en un formato estructurado, puede inscribirse en este curso gratuito en PyTorch y sígalos por capítulos.
Una descripción general de PyTorch
Los creadores de PyTorch dicen que tienen una filosofía: quieren ser imperativos. Esto significa que ejecutamos nuestro cálculo inmediatamente. Esto encaja perfectamente en la metodología de programación de Python, como no tenemos que esperar a que se escriba todo el código antes de saber si funciona o no. Podemos ejecutar fácilmente una parte del código e inspeccionarlo en tiempo real. Para mí, como depurador de redes neuronales, ¡esto es una bendición!
PyTorch es una biblioteca basada en Python creada para proporcionar flexibilidad como plataforma de desarrollo de aprendizaje profundo. El flujo de trabajo de PyTorch es lo más parecido a la biblioteca de computación científica de Python: numpy.
Ahora podría preguntar, ¿por qué usaríamos PyTorch para construir modelos de aprendizaje profundo? Puedo enumerar tres cosas que podrían ayudar a responder eso:
- API fácil de usar – Es tan simple como puede ser Python.
- Soporte de Python – Como se mencionó anteriormente, PyTorch se integra sin problemas con la pila de ciencia de datos de Python. Es tan similar a numpy que es posible que ni siquiera notes la diferencia.
- Gráficos de cálculo dinámico – En lugar de gráficos predefinidos con funcionalidades específicas, PyTorch proporciona un marco para que construyamos gráficos computacionales a medida que avanzamos, e incluso los cambiamos durante el tiempo de ejecución. Esto es valioso para situaciones en las que no sabemos cuánta memoria se necesitará para crear una red neuronal.
Algunas otras ventajas de usar PyTorch son su soporte multiGPU, cargadores de datos personalizados y preprocesadores simplificados.
Desde su lanzamiento a principios de enero de 2016, muchos investigadores lo han adoptado como una biblioteca de referencia debido a su facilidad para crear gráficos novedosos e incluso extremadamente complejos. Dicho esto, todavía queda algo de tiempo antes de que PyTorch sea adoptado por la mayoría de los profesionales de la ciencia de datos debido a su estado nuevo y «en construcción».
Sumergirse en los tecnicismos
Antes de sumergirnos en los detalles, veamos el flujo de trabajo de PyTorch.
PyTorch usa un paradigma imperativo / ansioso. Es decir, cada línea de código requerida para construir un gráfico define un componente de ese gráfico. Podemos realizar cálculos de forma independiente en estos componentes, incluso antes de que su gráfico esté completamente construido. Esto se denomina metodología de «definición por ejecución».

Fuente: http://pytorch.org/about/
Instalar PyTorch es bastante fácil. Puede seguir los pasos mencionados en el documentos oficiales y ejecute el comando según las especificaciones de su sistema. Por ejemplo, este fue el comando que usé en función de las opciones que elegí:
conda install pytorch torchvision cuda91 -c pytorch
Los principales elementos que debemos conocer al comenzar con PyTorch son:
- Tensores PyTorch
- Operaciones matemáticas
- Módulo de autogrado
- Módulo Optim y
- módulo nn
A continuación, echaremos un vistazo a cada uno de ellos con cierto detalle.
Tensores PyTorch
Los tensores no son más que matrices multidimensionales. Los tensores en PyTorch son similares a los ndarrays de numpy, con la adición de que los tensores también se pueden usar en una GPU. Compatible con PyTorch varios tipos de tensores. Si está familiarizado con otros marcos de aprendizaje profundo, también debe haber encontrado tensores en TensorFlow. De hecho, también puede implementar las siguientes tareas en Tensorflow y hacer su propia comparación entre PyTorch y TensorFlow.
Puede definir una matriz unidimensional simple como se muestra a continuación:
# import pytorch import torch # define a tensor torch.FloatTensor([2])
2 [torch.FloatTensor of size 1]
Operaciones matemáticas
Al igual que con numpy, es muy importante que una biblioteca de computación científica tenga implementaciones eficientes de funciones matemáticas. PyTorch le ofrece una interfaz similar, con más de 200 operaciones matemáticas puedes usar.
A continuación se muestra un ejemplo de una operación de suma simple en PyTorch:
a = torch.FloatTensor([2]) b = torch.FloatTensor([3]) a + b
5 [torch.FloatTensor of size 1]
¿No parece esto un enfoque de Python quinesencial? También podemos realizar varias operaciones matriciales en los tensores PyTorch que definimos. Por ejemplo, transpondremos una matriz bidimensional:
matrix = torch.randn(3, 3) matrix 0.7162 1.0152 1.1525 -0.3503 -0.9452 -1.0861 -0.1093 -0.0927 -0.0476 [torch.FloatTensor of size 3x3] matrix.t() 0.7162 -0.3503 -0.1093 1.0152 -0.9452 -0.0927 1.1525 -1.0861 -0.0476 [torch.FloatTensor of size 3x3]
Módulo de autogrado
PyTorch utiliza una técnica llamada diferenciación automática. Es decir, tenemos una grabadora que registra las operaciones que hemos realizado y luego las reproduce hacia atrás para calcular nuestros gradientes. Esta técnica es especialmente poderosa cuando se construyen redes neuronales, ya que ahorramos tiempo en una época al calcular la diferenciación de los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... en la pasada directa.
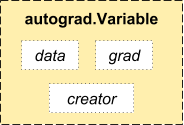
Fuente: http://pytorch.org/about/
from torch.autograd import Variable x = Variable(train_x) y = Variable(train_y, requires_grad=False)
Módulo optim
torch.optim es un módulo que implementa varios algoritmos de optimización utilizados para construir redes neuronales. La mayoría de los métodos más utilizados ya son compatibles, por lo que no tenemos que crearlos desde cero (¡a menos que lo desee!).
A continuación se muestra el código para usar un optimizador de Adam:
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
módulo nn
PyTorch autograd facilita la definición de gráficos computacionales y la toma de gradientes, pero el autograd sin formato puede ser un nivel demasiado bajo para definir redes neuronales complejas. Aquí es donde el módulo nn puede ayudar.
El paquete nn define un conjunto de módulos, que podemos considerar como una capa de red neuronal que produce una salida a partir de la entrada y puede tener algunos pesos entrenables.
Puede considerar un módulo nn como el keras de PyTorch!
import torch # define model model = torch.nn.Sequential( torch.nn.Linear(input_num_units, hidden_num_units), torch.nn.ReLU(), torch.nn.Linear(hidden_num_units, output_num_units), ) loss_fn = torch.nn.CrossEntropyLoss()
Ahora que conoce los componentes básicos de PyTorch, puede construir fácilmente su propia red neuronal desde cero. ¡Síguelo si quieres saber cómo!
Construyendo una red neuronal en Numpy vs.PyTorch
He mencionado anteriormente que PyTorch y Numpy son muy similares. Veamos por qué. En esta sección, veremos una implementación de una red neuronal simple para resolver un problema de clasificación binaria (puede leer este artículo para obtener una explicación detallada).
## Neural network in numpy
import numpy as np
#Input array
X=np.array([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Output
y=np.array([[1],[1],[0]])
#Sigmoid Function
def sigmoid (x):
return 1/(1 + np.exp(-x))
#Derivative of Sigmoid Function
def derivatives_sigmoid(x):
return x * (1 - x)
#Variable initialization
epoch=5000 #Setting training iterations
lr=0.1 #Setting learning rate
inputlayer_neurons = X.shape[1] #number of features in data set
hiddenlayer_neurons = 3 #number of hidden layers neurons
output_neurons = 1 #number of neurons at output layer
#weight and bias initialization
wh=np.random.uniform(size=(inputlayer_neurons,hiddenlayer_neurons))
bh=np.random.uniform(size=(1,hiddenlayer_neurons))
wout=np.random.uniform(size=(hiddenlayer_neurons,output_neurons))
bout=np.random.uniform(size=(1,output_neurons))
for i in range(epoch):
#Forward Propogation
hidden_layer_input1=np.dot(X,wh)
hidden_layer_input=hidden_layer_input1 + bh
hiddenlayer_activations = sigmoid(hidden_layer_input)
output_layer_input1=np.dot(hiddenlayer_activations,wout)
output_layer_input= output_layer_input1+ bout
output = sigmoid(output_layer_input)
#Backpropagation
E = y-output
slope_output_layer = derivatives_sigmoid(output)
slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
d_output = E * slope_output_layer
Error_at_hidden_layer = d_output.dot(wout.T)
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout += hiddenlayer_activations.T.dot(d_output) *lr
bout += np.sum(d_output, axis=0,keepdims=True) *lr
wh += X.T.dot(d_hiddenlayer) *lr
bh += np.sum(d_hiddenlayer, axis=0,keepdims=True) *lr
print('actual :n', y, 'n')
print('predicted :n', output)
Ahora, intente detectar la diferencia en una implementación súper simple del mismo en PyTorch (las diferencias se mencionan en negrita en el siguiente código).
## neural network in pytorch import torch #Input array X = torch.Tensor([[1,0,1,0],[1,0,1,1],[0,1,0,1]]) #Output y = torch.Tensor([[1],[1],[0]]) #Sigmoid Function def sigmoid (x): return 1/(1 + torch.exp(-x)) #Derivative of Sigmoid Function def derivatives_sigmoid(x): return x * (1 - x) #VariableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... initialization epoch=5000 #Setting training iterations lr=0.1 #Setting learning rate inputlayer_neurons = X.shape[1] #number of features in data set hiddenlayer_neurons = 3 #number of hidden layers neurons output_neurons = 1 #number of neurons at output layer #weight and bias initialization wh=torch.randn(inputlayer_neurons, hiddenlayer_neurons).type(torch.FloatTensor) bh=torch.randn(1, hiddenlayer_neurons).type(torch.FloatTensor) wout=torch.randn(hiddenlayer_neurons, output_neurons) bout=torch.randn(1, output_neurons) for i in range(epochEpoch es una plataforma que ofrece herramientas para la creación y gestión de contenido digital. Su enfoque se centra en facilitar la producción de multimedia, permitiendo a los usuarios colaborar y compartir información de manera eficiente. Con una interfaz intuitiva, Epoch se ha convertido en una opción popular entre profesionales y empresas que buscan optimizar su flujo de trabajo en la era digital. Su versatilidad la hace adecuada para diversas...): #Forward Propogation hidden_layer_input1 = torch.mm(X, wh) hidden_layer_input = hidden_layer_input1 + bh hidden_layer_activations = sigmoid(hidden_layer_input) output_layer_input1 = torch.mm(hidden_layer_activations, wout) output_layer_input = output_layer_input1 + bout output = sigmoid(output_layer_input1) #Backpropagation E = y-output slope_output_layer = derivatives_sigmoid(output) slope_hidden_layer = derivatives_sigmoid(hidden_layer_activations) d_output = E * slope_output_layer Error_at_hidden_layer = torch.mm(d_output, wout.t()) d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer wout += torch.mm(hidden_layer_activations.t(), d_output) *lr bout += d_output.sum() *lr wh += torch.mm(X.t(), d_hiddenlayer) *lr bh += d_output.sum() *lr print('actual :n', y, 'n') print('predicted :n', output)
Comparación con otras bibliotecas de aprendizaje profundo
En uno guión de evaluación comparativa, se ha demostrado con éxito que PyTorch supera a todas las demás bibliotecas importantes de aprendizaje profundo en el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... de una red de memoria a largo y corto plazo (LSTM) al tener la medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... de tiempo más baja por época (consulte la imagen a continuación).

Las API para la carga de datos están bien diseñadas en PyTorch. Las interfaces se especifican en un conjunto de datos, un muestreador y un cargador de datos.
Al comparar las herramientas para la carga de datos en TensorFlow (lectores, colas, etc.), encontré PyTorchLos módulos de carga de datos son bastante fáciles de usar. Además, PyTorch es perfecto cuando intentamos construir una red neuronal, por lo que no tenemos que depender de bibliotecas de alto nivel de terceros como keras.
Por otro lado, todavía no recomendaría usar PyTorch para la implementación. PyTorch aún no ha evolucionado. Como han dicho los desarrolladores de PyTorch, “Lo que estamos viendo es que los usuarios primero crean un modelo de PyTorch. Cuando están listos para implementar su modelo en producción, simplemente lo convierten en un modelo Caffe 2 y luego lo envían a una plataforma móvil u otra ”.
Estudio de caso: resolución de un problema de reconocimiento de imágenes en PyTorch
Para familiarizarse con PyTorch, resolveremos el problema de práctica de aprendizaje profundo de DataPeaker: Identificar los dígitos. Echemos un vistazo a nuestra declaración de problema:
Nuestro problema es un problema de reconocimiento de imágenes, para identificar dígitos de una imagen dada de 28 x 28. Tenemos un subconjunto de imágenes para entrenamiento y el resto para probar nuestro modelo.
Primero, descargue el tren y los archivos de prueba. El conjunto de datos contiene un archivo comprimido de todas las imágenes y tanto train.csv como test.csv tienen el nombre de las imágenes de prueba y de tren correspondientes. Las características adicionales no se proporcionan en los conjuntos de datos, solo las imágenes sin procesar se proporcionan en formato ‘.png’.
Vamos a empezar:
PASO 0: Preparándose
a) Importar todas las bibliotecas necesarias
# import modules %pylab inline import os import numpy as np import pandas as pd from scipy.misc import imread from sklearn.metrics import accuracy_score
b) Establezcamos un valor semilla, para que podamos controlar la aleatoriedad de nuestros modelos
# To stop potential randomness seed = 128 rng = np.random.RandomState(seed)
c) El primer paso es establecer rutas de directorio, ¡para su custodia!
root_dir = os.path.abspath('.')
data_dir = os.path.join(root_dir, 'data')
# check for existence
os.path.exists(root_dir), os.path.exists(data_dir)
PASO 1: Carga de datos y preprocesamiento
a) Ahora leamos nuestros conjuntos de datos. Estos están en formatos .csv y tienen un nombre de archivo junto con las etiquetas correspondientes.
# load dataset train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv')) test = pd.read_csv(os.path.join(data_dir, 'Test.csv')) sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv')) train.head()
| nombre del archivo | etiqueta | |
|---|---|---|
| 0 | 0.png | 4 |
| 1 | 1.png | 9 |
| 2 | 2.png | 1 |
| 3 | 3.png | 7 |
| 4 | 4.png | 3 |
b) ¡Veamos cómo se ven nuestros datos! Leemos nuestra imagen y la mostramos.
# print an image
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(filepath, flatten=True)
pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()

d) Para una manipulación de datos más fácil, almacenemos todas nuestras imágenes como matrices numpy
# load images to create train and test set
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
train_x = np.stack(temp)
train_x /= 255.0
train_x = train_x.reshape(-1, 784).astype('float32')
temp = []
for img_name in test.filename:
image_path = os.path.join(data_dir, 'Train', 'Images', 'test', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
test_x = np.stack(temp)
test_x /= 255.0
test_x = test_x.reshape(-1, 784).astype('float32')
train_y = train.label.values
e) Como se trata de un problema típico de AA, para probar el correcto funcionamiento de nuestro modelo creamos un conjunto de validación. Tomemos un tamaño de división de 70:30 para el conjunto de trenes frente al conjunto de validación
# create validation set split_size = int(train_x.shape[0]*0.7) train_x, val_x = train_x[:split_size], train_x[split_size:] train_y, val_y = train_y[:split_size], train_y[split_size:]
PASO 2: Construcción de modelos
a) ¡Ahora viene la parte principal! Definamos nuestra arquitectura de red neuronal. Definimos una red neuronal con 3 capas de entrada, oculta y salida. El número de neuronas en entrada y salida es fijo, ya que la entrada es nuestra imagen de 28 x 28 y la salida es un vector de 10 x 1 que representa la clase. Tomamos 50 neuronas en la capa oculta. Aquí usamos Adán como nuestros algoritmos de optimización, que es una variante eficiente del algoritmo Gradient Descent.
import torch from torch.autograd import Variable
# number of neurons in each layer input_num_units = 28*28 hidden_num_units = 500 output_num_units = 10 # set remaining variables epochs = 5 batch_size = 128 learning_rate = 0.001
b) Es hora de entrenar nuestro modelo
# define model model = torch.nn.Sequential( torch.nn.Linear(input_num_units, hidden_num_units), torch.nn.ReLU(), torch.nn.Linear(hidden_num_units, output_num_units), ) loss_fn = torch.nn.CrossEntropyLoss() # define optimization algorithm optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
## helper functions
# preprocess a batch of dataset
def preproc(unclean_batch_x):
"""Convert values to range 0-1"""
temp_batch = unclean_batch_x / unclean_batch_x.max()
return temp_batch
# create a batch
def batch_creator(batch_size):
dataset_name="train"
dataset_length = train_x.shape[0]
batch_mask = rng.choice(dataset_length, batch_size)
batch_x = eval(dataset_name + '_x')[batch_mask]
batch_x = preproc(batch_x)
if dataset_name == 'train':
batch_y = eval(dataset_name).ix[batch_mask, 'label'].values
return batch_x, batch_y
# train network
total_batch = int(train.shape[0]/batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
# create batch
batch_x, batch_y = batch_creator(batch_size)
# pass that batch for training
x, y = Variable(torch.from_numpy(batch_x)), Variable(torch.from_numpy(batch_y), requires_grad=False)
pred = model(x)
# get loss
loss = loss_fn(pred, y)
# perform backpropagation
loss.backward()
optimizer.step()
avg_cost += loss.data[0]/total_batch
print(epoch, avg_cost)
# get training accuracy x, y = Variable(torch.from_numpy(preproc(train_x))), Variable(torch.from_numpy(train_y), requires_grad=False) pred = model(x) final_pred = np.argmax(pred.data.numpy(), axis=1) accuracy_score(train_y, final_pred)
# get validation accuracy x, y = Variable(torch.from_numpy(preproc(val_x))), Variable(torch.from_numpy(val_y), requires_grad=False) pred = model(x) final_pred = np.argmax(pred.data.numpy(), axis=1) accuracy_score(val_y, final_pred)
La puntuación de entrenamiento resulta ser:
0.8779008746355685
mientras que la puntuación de validación es:
0.867482993197279
¡Esta es una puntuación bastante impresionante, especialmente cuando hemos entrenado una red neuronal muy simple durante solo cinco épocas!
Notas finales
Espero que este artículo le haya dado una idea de cómo el marco de PyTorch puede cambiar la perspectiva de la construcción de modelos de aprendizaje profundo. En este artículo, acabamos de arañar la superficie. Para profundizar, puedes leer la documentación y tutoriales en la propia página oficial de PyTorch.
En los próximos artículos, aplicaré PyTorch para el análisis de audio e intentaremos crear modelos de aprendizaje profundo para el procesamiento del habla. ¡Manténganse al tanto!
¿Ha utilizado PyTorch para crear una aplicación o en alguno de sus proyectos de ciencia de datos? Déjame saber abajo en los comentarios.





