Introducción
El comercio electrónico ha revolucionado la forma en que compramos. ¿Ese teléfono que ha estado ahorrando para comprar durante meses? Es solo una búsqueda y unos pocos clics de distancia. Los artículos se entregan en cuestión de días (¡a veces incluso al día siguiente!).
Para los minoristas en línea, no existen restricciones relacionadas con la gestión de inventario o la gestión del espacio. Pueden vender tantos productos diferentes como deseen. Las tiendas físicas pueden conservar solo un número limitado de productos debido al espacio limitado que tienen disponible.
Recuerdo cuando solía hacer pedidos de libros en mi librería local, y solía tardar más de una semana en llegar. ¡Parece una historia de la antigüedad ahora!

Fuente: http://www.yeebaplay.com.br
Pero las compras en línea tienen sus propias advertencias. Uno de los mayores desafíos es verificar la autenticidad de un producto. ¿Es tan bueno como se anuncia en el sitio de comercio electrónico? ¿Durará el producto más de un año? ¿Las opiniones de otros clientes son realmente ciertas o son publicidad engañosa? Estas son preguntas importantes que los clientes deben hacer antes de derrochar su dinero.
Este es un gran lugar para experimentar y aplicar técnicas de procesamiento del lenguaje natural (PNL). Este artículo lo ayudará a comprender la importancia de aprovechar las revisiones de productos en línea con la ayuda de Modelado de temas.
Consulte los artículos a continuación en caso de que necesite un repaso rápido sobre el modelado de temas:
Tabla de contenido
- Importancia de las revisiones en línea
- Planteamiento del problema
- ¿Por qué el modelado de temas para esta tarea?
- Implementación de Python
- Leer los datos
- Preprocesamiento de datos
- Construyendo un modelo LDA
- Visualización de temas
- Otros métodos para aprovechar las reseñas en línea
- ¿Que sigue?
Importancia de las revisiones en línea
Hace unos días, me lancé al comercio electrónico y compré un teléfono inteligente en línea. Estaba dentro de mi presupuesto y tenía una calificación decente de 4.5 sobre 5.

Desafortunadamente, resultó ser una mala decisión ya que la batería de respaldo estaba muy por debajo de la media. No revisé las reseñas del producto y tomé la decisión apresurada de comprarlo basándose únicamente en sus calificaciones. ¡Y sé que no soy el único que cometió este error!
Las calificaciones por sí solas no dan una imagen completa de los productos que deseamos comprar, como descubrí en mi detrimento. Por lo tanto, como medida de precaución, siempre recomiendo a las personas que lean las reseñas de un producto antes de decidir si comprarlo o no.
Pero entonces surge un problema interesante. ¿Qué pasa si el número de reseñas es de cientos o miles? Simplemente no es factible pasar por todas esas revisiones, ¿verdad? Y aquí es donde triunfa el procesamiento del lenguaje natural.
Establecer la declaración del problema
Una declaración de problema es la semilla de la que brota su análisis. Por lo tanto, es realmente importante tener un enunciado del problema sólido, claro y bien definido.

¿Cómo podemos analizar una gran cantidad de reseñas en línea utilizando el procesamiento del lenguaje natural (NLP)? Definamos este problema.
Las reseñas de productos en línea son una gran fuente de información para los consumidores. Desde el punto de vista de los vendedores, las reseñas en línea se pueden utilizar para evaluar los comentarios de los consumidores sobre los productos o servicios que venden. Sin embargo, dado que estas revisiones en línea son a menudo abrumadoras en términos de números e información, un sistema inteligente, capaz de encontrar información clave (temas) a partir de estas revisiones, será de gran ayuda tanto para los consumidores como para los vendedores. Este sistema tendrá dos propósitos:
- Permita que los consumidores extraigan rápidamente los temas clave cubiertos por las reseñas sin tener que pasar por todos ellos.
- Ayude a los vendedores / minoristas a obtener comentarios de los consumidores en forma de temas (extraídos de las reseñas de los consumidores)
Para resolver esta tarea, utilizaremos el concepto de Modelado de temas (LDA) en los datos de Amazon Automotive Review. Puedes descargarlo desde este Enlace. Se pueden encontrar conjuntos de datos similares para otras categorías de productos aquí.
¿Por qué debería utilizar el modelado de temas para esta tarea?
Como sugiere el nombre, el modelado de temas es un proceso para identificar automáticamente los temas presentes en un objeto de texto y derivar patrones ocultos exhibidos por un corpus de texto. Los modelos de tema son muy útiles para múltiples propósitos, que incluyen:
- Agrupación de documentos
- Organizar grandes bloques de datos textuales
- Recuperación de información de texto no estructurado
- Selección de características
Un buen modelo de tema, cuando se entrena en algún texto sobre el mercado de valores, debería resultar en temas como «oferta», «negociación», «dividendo», «intercambio», etc. La siguiente imagen ilustra cómo funciona un modelo de tema típico:

En nuestro caso, en lugar de documentos de texto, tenemos miles de reseñas de productos en línea para los artículos enumerados en la categoría ‘Automotriz’. Nuestro objetivo aquí es extraer un cierto número de grupos de palabras importantes de las reseñas. Estos grupos de palabras son básicamente los temas que ayudarían a determinar de qué están hablando realmente los consumidores en las reseñas.

Implementación de Python
En esta sección, activaremos nuestros cuadernos de Jupyter (¡o cualquier otro IDE que use para Python!). Aquí trabajaremos en la declaración del problema definida anteriormente para extraer temas útiles de nuestro conjunto de datos de revisiones en línea utilizando el concepto de asignación de Dirichlet latente (LDA).
Nota: Como mencioné en la introducción, recomiendo encarecidamente leer este artículo para comprender qué es LDA y cómo funciona.
Primero carguemos todas las bibliotecas necesarias:
import nltk
from nltk import FreqDist
nltk.download('stopwords') # run this one time
import pandas as pd
pd.set_option("display.max_colwidth", 200)
import numpy as np
import re
import spacy
import gensim
from gensim import corpora
# libraries for visualization
import pyLDAvis
import pyLDAvis.gensim
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Para importar los datos, primero extraiga los datos a su directorio de trabajo y luego use el read_json () función de los pandas para leerlo en un marco de datos de pandas.
df = pd.read_json('Automotive_5.json', lines=True)
df.head()

Como puede ver, los datos contienen las siguientes columnas:
- reviewerID – ID del revisor
- como en – ID del producto
- reviewerName – nombre del revisor
- servicial – calificación de utilidad de la revisión, por ejemplo, 2/3
- reviewText – texto de la reseña
- en general – calificación del producto
- resumen – resumen de la revisión
- unixReviewTime – hora de la revisión (hora unix)
- tiempo de revisión – hora de la revisión (sin procesar)
Para el alcance de nuestro análisis y este artículo, usaremos solo la columna de reseñas, es decir, reviewText.
Preprocesamiento de datos
El preprocesamiento y la limpieza de datos es un paso importante antes de cualquier tarea de minería de texto, en este paso, eliminaremos los signos de puntuación, las palabras vacías y normalizaremos las revisiones tanto como sea posible. Después de cada paso de preprocesamiento, es una buena práctica comprobar las palabras más frecuentes en los datos. Por lo tanto, definamos una función que trazaría un gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad.... de n palabras más frecuentes en los datos.
# function to plot most frequent terms
def freq_words(x, terms = 30):
all_words=" ".join([text for text in x])
all_words = all_words.split()
fdist = FreqDist(all_words)
words_df = pd.DataFrame({'word':list(fdist.keys()), 'count':list(fdist.values())})
# selecting top 20 most frequent words
d = words_df.nlargest(columns="count", n = terms)
plt.figure(figsize=(20,5))
ax = sns.barplot(data=d, x= "word", y = "count")
ax.set(ylabel="Count")
plt.show()
Probemos esta función y descubramos cuáles son las palabras más comunes en nuestro conjunto de datos de reseñas.
freq_words(df['reviewText'])
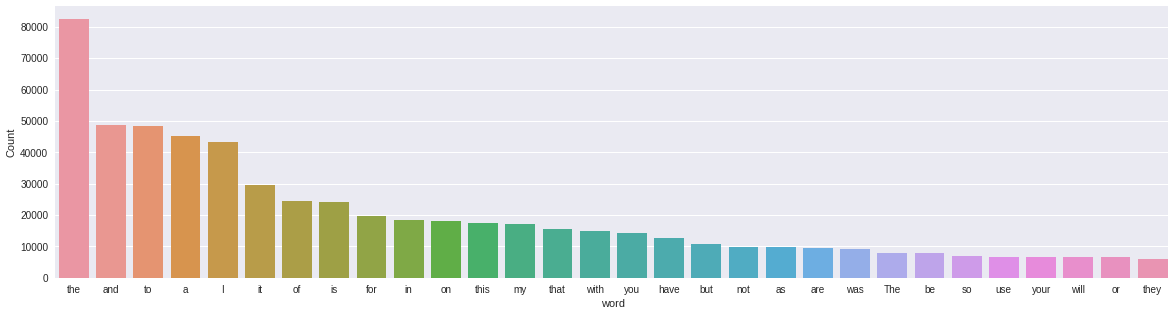
Las palabras más comunes son «el», «y», «para», etc. Estas palabras no son tan importantes para nuestra tarea y no cuentan ninguna historia. Tenemos que deshacernos de este tipo de palabras. Antes de eso, eliminemos las puntuaciones y los números de nuestros datos de texto.
# remove unwanted characters, numbers and symbols
df['reviewText'] = df['reviewText'].str.replace("[^a-zA-Z#]", " ")
Intentemos eliminar las palabras vacías y las palabras cortas (<2 letras) de las revisiones.
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
# function to remove stopwords def remove_stopwords(rev): rev_new = " ".join([i for i in rev if i not in stop_words]) return rev_new # remove short words (length < 3) df['reviewText'] = df['reviewText'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>2])) # remove stopwords from the text reviews = [remove_stopwords(r.split()) for r in df['reviewText']] # make entire text lowercase reviews = [r.lower() for r in reviews]
Tracemos de nuevo las palabras más frecuentes y veamos si han salido las palabras más significativas.
freq_words(reviews, 35)
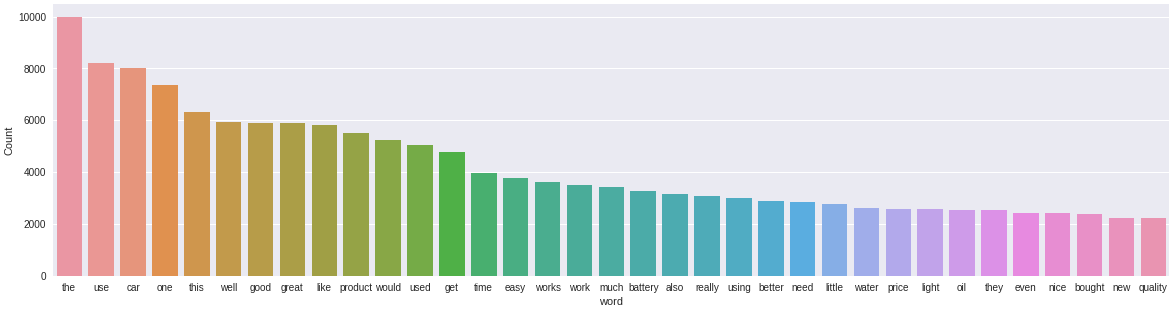
Podemos ver algunas mejoras aquí. Han surgido términos como «batería», «precio», «producto», «aceite», que son bastante relevantes para la categoría Automotriz. Sin embargo, todavía tenemos términos neutrales como ‘el’, ‘esto’, ‘mucho’, ‘ellos’ que no son tan relevantes.
Para eliminar aún más el ruido del texto, podemos usar la lematización de la biblioteca spaCy. Reduce cualquier palabra dada a su forma básica, reduciendo así múltiples formas de una palabra a una sola palabra.
!python -m spacy download en # one time run
nlp = spacy.load('en', disable=['parser', 'ner'])
def lemmatization(texts, tags=['NOUN', 'ADJ']): # filter noun and adjective
output = []
for sent in texts:
doc = nlp(" ".join(sent))
output.append([token.lemma_ for token in doc if token.pos_ in tags])
return output
Tokenicemos las revisiones y luego lematicemos las revisiones tokenizadas.
tokenized_reviews = pd.Series(reviews).apply(lambda x: x.split()) print(tokenized_reviews[1])
['these', 'long', 'cables', 'work', 'fine', 'truck', 'quality', 'seems', 'little', 'shabby', 'side', 'for', 'money', 'expecting', 'dollar', 'snap', 'jumper', 'cables', 'seem', 'like', 'would', 'see', 'chinese', 'knock', 'shop', 'like', 'harbor', 'freight', 'bucks']
reviews_2 = lemmatization(tokenized_reviews) print(reviews_2[1]) # print lemmatized review
['long', 'cable', 'fine', 'truck', 'quality', 'little', 'shabby', 'side', 'money', 'dollar', 'jumper', 'cable', 'chinese', 'shop', 'harbor', 'freight', 'buck']
Como puede ver, no solo hemos lematizado las palabras, sino que también hemos filtrado solo sustantivos y adjetivos. Eliminemos los token de las reseñas lematizadas y tracemos las palabras más comunes.
reviews_3 = []
for i in range(len(reviews_2)):
reviews_3.append(' '.join(reviews_2[i]))
df['reviews'] = reviews_3
freq_words(df['reviews'], 35)
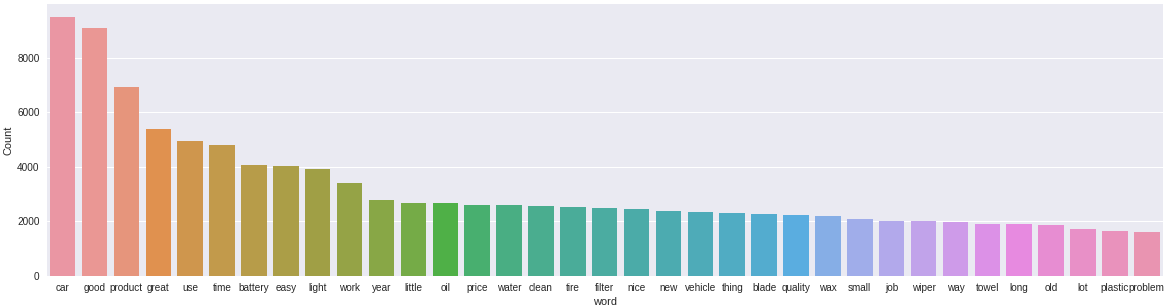
Parece que ahora los términos más frecuentes en nuestros datos son relevantes. Ahora podemos seguir adelante y comenzar a construir nuestro modelo de tema.
Construyendo un modelo LDA
Comenzaremos creando el diccionario de términos de nuestro corpus, donde a cada término único se le asigna un índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas....
dictionary = corpora.Dictionary(reviews_2)
Luego, convertiremos la lista de revisiones (reviews_2) en una Matriz de términos del documento utilizando el diccionario preparado anteriormente.
doc_term_matrix = [dictionary.doc2bow(rev) for rev in reviews_2]
# Creating the object for LDA model using gensim library LDA = gensim.models.ldamodel.LdaModel # Build LDA model lda_model = LDA(corpus=doc_term_matrix, id2word=dictionary, num_topics=7, random_state=100, chunksize=1000, passes=50)
El código anterior tomará un tiempo. Tenga en cuenta que he especificado el número de temas como 7 para este modelo utilizando el num_topics parámetro. Puede especificar cualquier número de temas utilizando el mismo parámetro.
Imprimamos los temas que ha aprendido nuestro modelo LDA.
lda_model.print_topics()
[(0, '0.030*"car" + 0.026*"oil" + 0.020*"filter" + 0.018*"engine" + 0.016*"device" + 0.013*"code" + 0.012*"vehicle" + 0.011*"app" + 0.011*"change" + 0.008*"bosch"'), (1, '0.017*"easy" + 0.014*"install" + 0.014*"door" + 0.013*"tape" + 0.013*"jeep" + 0.011*"front" + 0.011*"mat" + 0.010*"side" + 0.010*"headlight" + 0.008*"fit"'), (2, '0.054*"blade" + 0.045*"wiper" + 0.019*"windshield" + 0.014*"rain" + 0.012*"snow" + 0.012*"good" + 0.011*"year" + 0.011*"old" + 0.011*"car" + 0.009*"time"'), (3, '0.044*"car" + 0.024*"towel" + 0.020*"product" + 0.018*"clean" + 0.017*"good" + 0.016*"wax" + 0.014*"water" + 0.013*"use" + 0.011*"time" + 0.011*"wash"'), (4, '0.051*"light" + 0.039*"battery" + 0.021*"bulb" + 0.019*"power" + 0.018*"car" + 0.014*"bright" + 0.013*"unit" + 0.011*"charger" + 0.010*"phone" + 0.010*"charge"'), (5, '0.022*"tire" + 0.015*"hose" + 0.013*"use" + 0.012*"good" + 0.010*"easy" + 0.010*"pressure" + 0.009*"small" + 0.009*"trailer" + 0.008*"nice" + 0.008*"water"'), (6, '0.048*"product" + 0.038*"good" + 0.027*"price" + 0.020*"great" + 0.020*"leather" + 0.019*"quality" + 0.010*"work" + 0.010*"review" + 0.009*"amazon" + 0.009*"worth"')]
El cuarto tema Tema 3 tiene términos como «toalla», «limpiar», «cera», «agua», lo que indica que el tema está muy relacionado con el lavado de coches. Similar, Tema 6 parece tener que ver con el valor general del producto, ya que tiene términos como «precio», «calidad» y «valor».
Visualización de temas
Para visualizar nuestros temas en un espacio bidimensional usaremos el biblioteca pyLDAvis. Esta visualización es de naturaleza interactiva y muestra temas junto con las palabras más relevantes.
# Visualize the topics pyLDAvis.enable_notebook() vis = pyLDAvis.gensim.prepare(lda_model, doc_term_matrix, dictionary) vis

El código completo está disponible aquí.
Otros métodos para aprovechar las revisiones en línea
Además del modelado de temas, existen muchos otros métodos de PNL que se utilizan para analizar y comprender las reseñas en línea. Algunos de ellos se enumeran a continuación:
- Resumen de texto: Resuma las revisiones en un párrafo o en algunas viñetas.
- Reconocimiento de entidad: Extraiga entidades de las reseñas e identifique qué productos son más populares (o impopulares) entre los consumidores.
- Identificar tendencias emergentes: Según la marca de tiempo de las revisiones, se pueden identificar temas o entidades nuevos y emergentes. Nos permitiría descubrir qué productos se están volviendo populares y cuáles están perdiendo su control en el mercado.
- Análisis de los sentimientos: Para los minoristas, comprender el sentimiento de las reseñas puede ser útil para mejorar sus productos y servicios.
¿Que sigue?
La recuperación de información nos ahorra el trabajo de revisar las revisiones de productos una por una. Nos da una idea clara de lo que otros consumidores están hablando sobre el producto.
Sin embargo, no nos dice si las críticas son positivas, neutrales o negativas. Esto se convierte en una extensión del problema de la recuperación de información donde no solo tenemos que extraer los temas, sino también determinar el sentimiento. Esta es una tarea interesante que cubriremos en el próximo artículo.
Notas finales
El modelado de temas es una de las técnicas de PNL más populares con varias aplicaciones del mundo real, como reducción de dimensionalidad, resumen de texto, motor de recomendaciones, etc. El propósito de este artículo era demostrar la aplicación de LDA en un texto sin formato generado por la multitud. datos. Le animo a implementar el código en otros conjuntos de datos y compartir sus hallazgos.
Si tiene alguna sugerencia, duda o cualquier otra cosa que desee compartir con respecto al modelado de temas, no dude en utilizar la sección de comentarios a continuación.
Si está buscando ingresar al campo del procesamiento del lenguaje natural, entonces tenemos un curso de video diseñado para usted que cubre preprocesamiento de texto, modelado de temas, reconocimiento de entidades nombradas, aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... para PNL y muchos más temas.





