Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Introducción
Básicamente formamos máquinas para que incluyan algún tipo de automatización en ellas. En el aprendizaje automático, utilizamos varios tipos de algoritmos para permitir que las máquinas aprendan las relaciones dentro de los datos proporcionados y hagan predicciones con ellos. Entonces, el tipo de predicción del modelo donde necesitamos la salida predicha es un valor numérico continuo, se llama problema de regresión.
El análisis de regresión gira en torno a algoritmos simples, que a menudo se utilizan en finanzas, inversiones y otros, y establece la relación entre una única variable dependiente que depende de varias independientes. Por ejemplo, predecir el precio de la vivienda o el salario de un empleado, etc., son los problemas de regresión más comunes.
Primero discutiremos los tipos de algoritmos de regresión en breve y luego pasaremos a un ejemplo. Estos algoritmos pueden ser tanto lineales como no lineales.
Algoritmos de ML lineal

Regresión lineal
Es un algoritmo de uso común y se puede importar desde la clase Regresión lineal. Se utiliza una única variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de entrada (la significativa) para predecir una o más variables de salida, asumiendo que la variable de entrada no está correlacionada entre sí. Se representa como:
y = b * x + c
donde variable dependiente de y, independiente de x, pendiente b de la línea de mejor ajuste que podría obtener una salida precisa y c – su intersección. A menos que haya una línea exacta que relacione las variables dependientes e independientes, podría haber una pérdida en la salida que se toma normalmente como el cuadrado de la diferencia entre la salida prevista y la real, es decir, la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y....
Cuando utiliza más de una variable independiente para obtener resultados, se denomina Regresión lineal múltiple. Este tipo de modelo asume que existe una relación lineal entre la característica dada y la salida, que es su limitación.
Regresión de crestas: la norma L2
Este es un tipo de algoritmo que es una extensión de una regresión lineal que intenta minimizar la pérdida, también usa datos de regresión múltiple. Sus coeficientes no se estiman por mínimos cuadrados ordinarios (MCO), sino por un estimadorEl "Estimador" es una herramienta estadística utilizada para inferir características de una población a partir de una muestra. Se basa en métodos matemáticos para proporcionar estimaciones precisas y confiables. Existen diferentes tipos de estimadores, como los insesgados y los consistentes, que se eligen según el contexto y el objetivo del estudio. Su correcto uso es fundamental en investigaciones científicas, encuestas y análisis de datos.... llamado cresta, que está sesgado y tiene una varianza menor que el estimador MCO, por lo que obtenemos una contracción en los coeficientes. Con este tipo de modelo, también podemos reducir la complejidad del modelo.
Aunque la contracción del coeficiente ocurre aquí, no se reducen completamente a cero. Por lo tanto, su modelo final aún lo incluirá todo.
Regresión de lazo: la norma L1
Es el operador de selección y contracción mínima absoluta. Esto penaliza la suma de valores absolutos de los coeficientes para minimizar el error de predicción. Hace que los coeficientes de regresión para algunas de las variables se reduzcan a cero. Se puede construir usando la clase LASSO. Una de las ventajas del lazo es su selección simultánea de funciones. Esto ayuda a minimizar la pérdida de predicción. Por otro lado, debemos tener en cuenta que lasso no puede hacer una selección de grupo, también selecciona características antes de saturarse.
Tanto el lazo como la cresta son métodos de regularizaciónLa regularización es un proceso administrativo que busca formalizar la situación de personas o entidades que operan fuera del marco legal. Este procedimiento es fundamental para garantizar derechos y deberes, así como para fomentar la inclusión social y económica. En muchos países, la regularización se aplica en contextos migratorios, laborales y fiscales, permitiendo a quienes se encuentran en situaciones irregulares acceder a beneficios y protegerse de posibles sanciones.....

fuente: Unsplash
Repasemos algunos ejemplos:
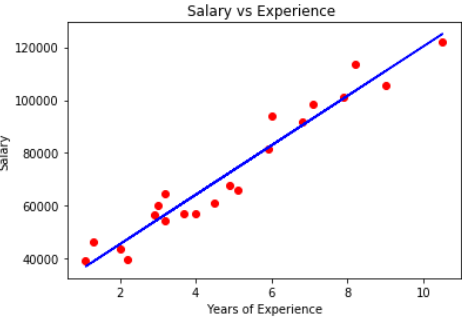
Supongamos un dato con años de experiencia y salario de diferentes empleados. Nuestro objetivo es crear un modelo que predice el salario del empleado basado en el año de experiencia. Dado que contiene una variable independiente y una dependiente, podemos usar la regresión lineal simple para este problema.
Algoritmos de AA no lineales
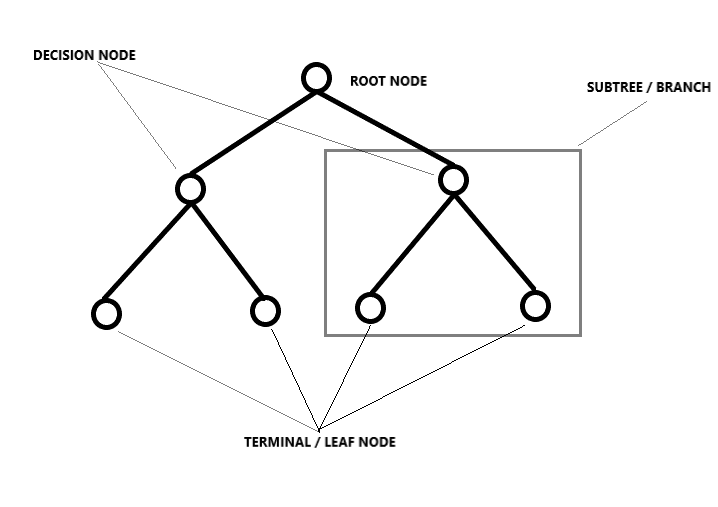
Regresión del árbol de decisión
Desglosa un conjunto de datos en subconjuntos cada vez más pequeños dividiéndolo, lo que da como resultado un árbol con nodos de decisión y nodos de hoja. Aquí la idea es trazar un valor para cualquier nuevo punto de datos que conecte el problema. El tipo de forma en que se lleva a cabo la división está determinada por los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... y el algoritmo, y la división se detiene cuando alcanza el número mínimo de información a agregar. Los árboles de decisión a menudo dan buenos resultados, pero incluso si se produce un ligero cambio en los datos, toda la estructura cambia, lo que significa que los modelos se vuelven inestables.
fuente: unsplash
Tomemos un caso de predicción del precio de la vivienda, dado un conjunto de 13 características y alrededor de 500 filas, aquí necesita predecir el precio de la vivienda. Dado que aquí tiene una cantidad considerable de muestras, debe optar por árboles u otros métodos para predecir valores.
Bosque aleatorio
La idea detrás de la regresión de bosque aleatorio es que, para encontrar el resultado, utiliza varios árboles de decisión. Los pasos involucrados en él son:
– Elija K puntos de datos aleatorios del conjunto de entrenamiento.
– Construya un árbol de decisiones asociado con estos puntos de datos
– Elija la cantidad de árboles que necesitamos construir y repita los pasos anteriores (proporcionados como argumento)
– Para un nuevo punto de datos, haga que cada uno de los árboles prediga valores de la variable dependiente para la entrada dada.
– Asignar el valor medio de los valores predichos a la salida final real.
Esto es similar a adivinar el número de bolas en una caja. Supongamos que anotamos aleatoriamente los valores de predicción dados por muchas personas y luego calculamos el promedio para tomar una decisión sobre el número de bolas en la caja. El bosque aleatorio es un modelo que usa múltiples árboles de decisión, lo cual sabemos, pero dado que tiene muchos árboles, también requiere mucho tiempo para entrenar y poder computacional, lo cual sigue siendo un inconveniente.
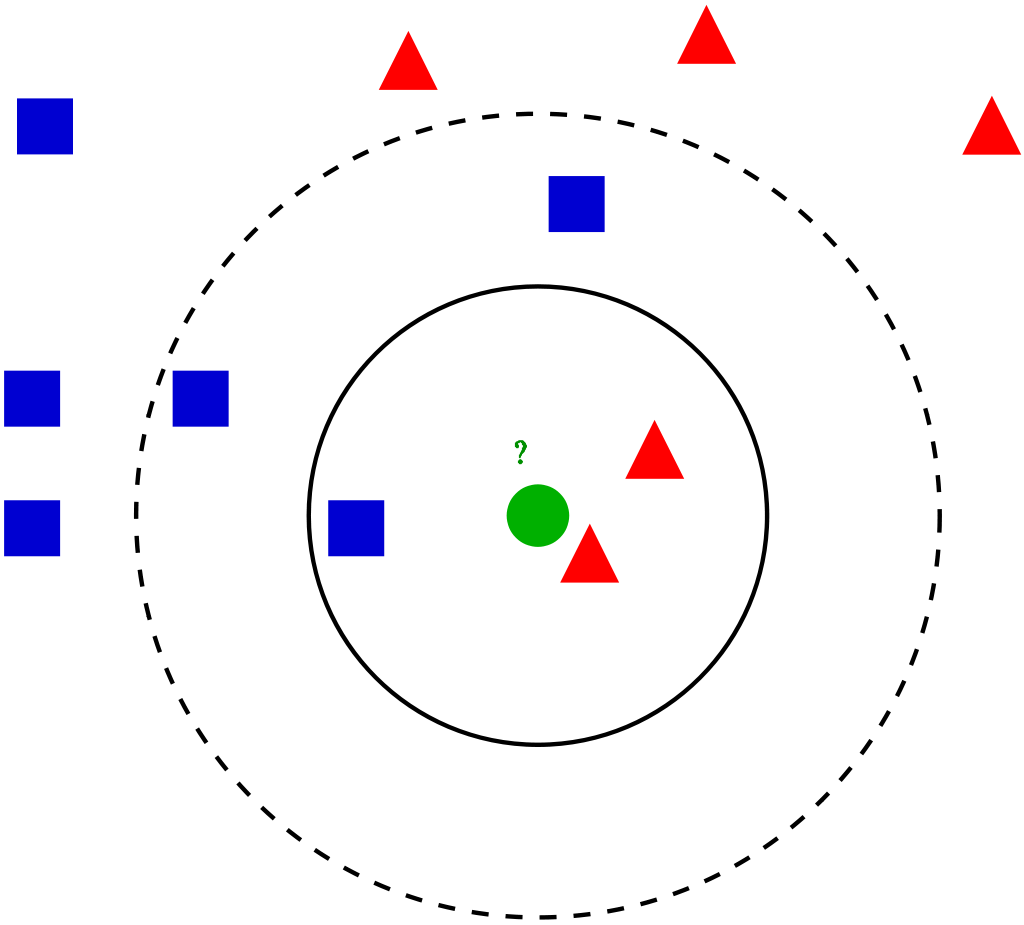
K Vecinos más cercanos (modelo KNN)
Se puede utilizar desde la clase KNearestNeighbors. Son simples y fáciles de implementar. Para una entrada introducida en el conjunto de datos, los K vecinos más cercanos ayudan a encontrar las k instancias más similares en el conjunto de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina..... Cualquiera de los valores promedio de la medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... de los vecinos se toma como valor para esa entrada.
fuente: unsplash
El método para encontrar el valor se puede dar como un argumento, cuyo valor predeterminado es «Minkowski», una combinación de distancias «euclidiana» y «manhattan».
Las predicciones pueden ser lentas cuando los datos son grandes y de mala calidad. Dado que la predicción debe tener en cuenta todos los puntos de datos, el modelo ocupará más espacio durante el entrenamiento.
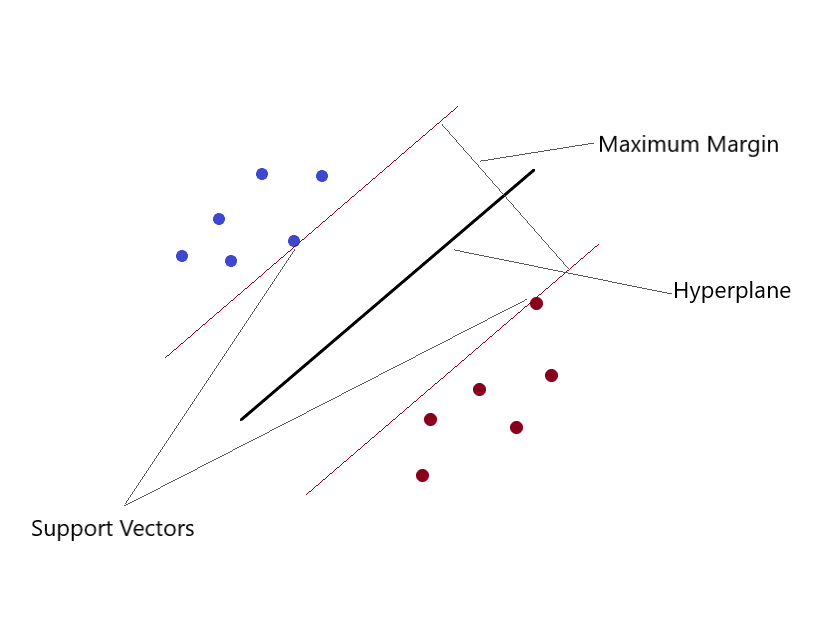
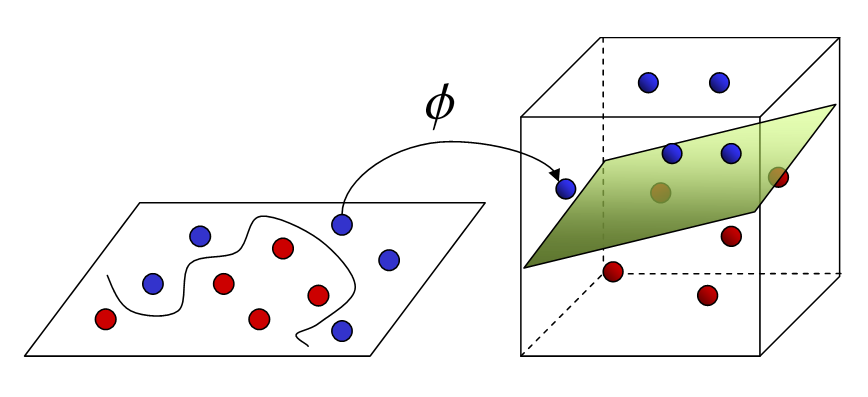
Máquinas de vectores de soporte (SVM)
Puede resolver problemas de regresión lineal y no lineal. Creamos un modelo SVM usando la clase SVR. en un espacio multidimensional, cuando tenemos más de una variable para determinar la salida, entonces cada uno de los puntos ya no es un punto como en 2D, sino que son vectores. El tipo más extremo de asignación de valores se puede realizar mediante este método. Separas clases y les das valores. La separación es por el concepto de Max-Margin (un hiperplano). Lo que debe tener en cuenta es que las SVM no son adecuadas para predecir valores para grandes conjuntos de entrenamiento. SVM falla cuando los datos tienen más ruido.
fuente: unsplash
fuente: unsplash
Si los datos de entrenamiento son mucho más grandes que el número de funciones, KNN es mejor que SVM. SVM supera a KNN cuando hay funciones más grandes y menos datos de entrenamiento.
Bueno, hemos llegado al final de este artículo, hemos discutido brevemente los tipos de algoritmos de regresión (teoría). Este es Surabhi, soy licenciado en tecnología. Echa un vistazo a mi Perfil de Linkedin y conéctese. Espero que hayas disfrutado leyendo esto. Gracias.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





