Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
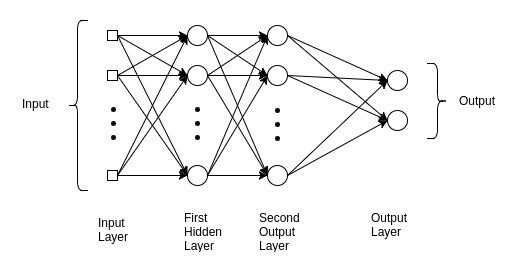
Comprender esta red nos ayuda a obtener información sobre las razones subyacentes en los modelos avanzados de Deep Learning. El perceptrón multicapa se usa comúnmente en problemas de regresión simple. Sin embargo, los MLP no son ideales para procesar patrones con datos secuenciales y multidimensionales.
🙄 Un perceptrón multicapa se esfuerza por recordar patrones en datos secuenciales, debido a esto, requiere una “gran” cantidad de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... para procesar datos multidimensionales.
MLP, CNN y RNN no hacen todo …
Gran parte de su éxito proviene de identificar su objetivo y la buena elección de algunos parámetros, como Función de pérdida, Optimizador, y Regularizador.
También disponemos de datos ajenos al entorno de formación. El papel del regularizador es garantizar que el modelo entrenado se generalice a nuevos datos.
Conjunto de datos MNIST
Supongamos que nuestro objetivo es crear una red para identificar números basados en dígitos escritos a mano. Por ejemplo, cuando la entrada a la red es una imagen de un número 8, la previsión correspondiente también debe ser 8.
🤷🏻♂️ Este es un trabajo básico de clasificación con redes neuronales.
Antes de analizar el modelo MLP, es esencial comprender el conjunto de datos del MNIST. Se utiliza para explicar y validar muchas teorías de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... porque las 70.000 imágenes que contiene son pequeñas pero suficientemente ricas en información;

MNIST es una colección de dígitos que van del 0 al 9. Tiene un conjunto de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... de 60.000 imágenes y 10.000 pruebas clasificadas en categorías.
Usar el conjunto de datos MNIST en TensorFlow es simple.
import numpy as np from tensorflow.keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
los mnist.load_data () El método es conveniente, ya que no es necesario cargar las 70.000 imágenes y sus etiquetas.
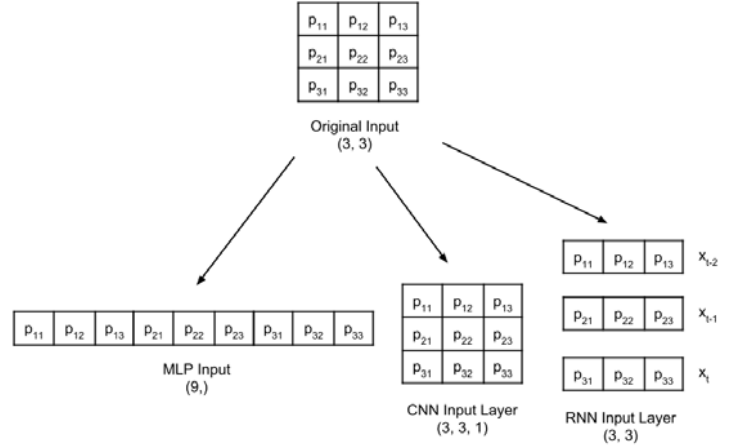
Antes de entrar en el clasificador de Perceptrón Multicapa, es fundamental tener en cuenta que, si bien los datos del MNIST constan de tensores bidimensionales, se deben remodelar, según el tipo de capa de entradaLa "capa de entrada" se refiere al nivel inicial en un proceso de análisis de datos o en arquitecturas de redes neuronales. Su función principal es recibir y procesar la información bruta antes de que esta sea transformada por capas posteriores. En el contexto de machine learning, una adecuada configuración de la capa de entrada es crucial para garantizar la efectividad del modelo y optimizar su rendimiento en tareas específicas.....
Se cambia la forma de una imagen en escala de grises de 3 × 3 para las capas de entrada MLP, CNN y RNN:
Las etiquetas tienen forma de dígitos, del 0 al 9.
num_labels = len(np.unique(y_train))
print("total de labels:t{}".format(num_labels))
print("labels:ttt{0}".format(np.unique(y_train)))
⚠️ Esta representación no es adecuada para la capa de pronóstico que genera probabilidad por clase. El formato más adecuado es one-hot, un vector de 10 dimensiones como todos los valores 0, excepto el índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de clase. Por ejemplo, si la etiqueta es 4, el vector equivalente es [0,0,0,0, 1, 0,0,0,0,0].
En Deep Learning, los datos se almacenan en un tensorLos tensores son estructuras matemáticas que generalizan conceptos como scalars y vectores. Se utilizan en diversas disciplinas, incluyendo física, ingeniería y aprendizaje automático, para representar datos multidimensionales. Un tensor puede ser visualizado como una matriz de múltiples dimensiones, lo que permite modelar relaciones complejas entre diferentes variables. Su versatilidad y capacidad para manejar grandes volúmenes de información los convierten en herramientas fundamentales en el análisis y procesamiento de datos..... El término tensor se aplica a un tensor escalar (tensor 0D), vector (tensor 1D), matriz (tensor bidimensional) y tensor multidimensionalLos tensores multidimensionales son estructuras matemáticas que generalizan la noción de escalares, vectores y matrices a dimensiones superiores. Se utilizan ampliamente en campos como la física, la ingeniería y el aprendizaje automático, permitiendo representar y manipular datos complejos de manera eficiente. Su capacidad para almacenar información en múltiples dimensiones facilita el análisis y la modelización de fenómenos reales, contribuyendo a avances en diversas disciplinas científicas y tecnológicas.....
#converter em one-hot from tensorflow.keras.utils import to_categorical y_train = to_categorical(y_train) y_test = to_categorical(y_test)
Nuestro modelo es un MLP, por lo que sus entradas deben ser un tensor 1D. como tal, x_train y x_test deben transformarse en [60,000, 2828] y [10,000, 2828],
En suma, el tamaño de -1 significa permitir que la biblioteca calcule la dimensión correcta. En el caso de x_train, es 60.000.
image_size = x_train.shape[1]
input_size = image_size * image_size
print("x_train:t{}".format(x_train.shape))
print("x_test:tt{}n".format(x_test.shape))
x_train = np.reshape(x_train, [-1, input_size])
x_train = x_train.astype('float32') / 255
x_test = np.reshape(x_test, [-1, input_size])
x_test = x_test.astype('float32') / 255
print("x_train:t{}".format(x_train.shape))
print("x_test:tt{}".format(x_test.shape))
OUTPUT:
x_train: (60000, 28, 28) x_test: (10000, 28, 28) x_train: (60000, 784) x_test: (10000, 784)
Construyendo el modelo
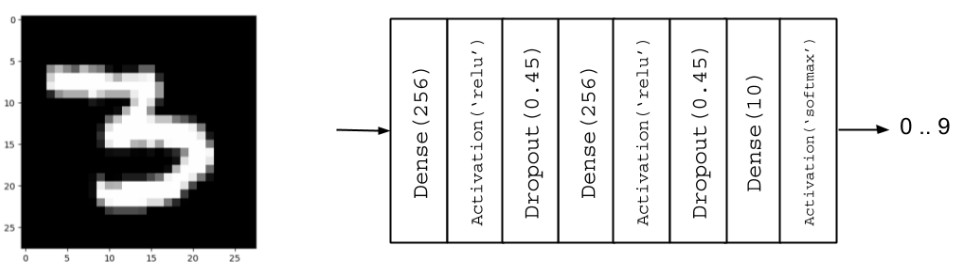
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout
# Parameters
batch_size = 128 # It is the sample size of inputs to be processed at each training stage.
hidden_units = 256
dropout = 0.45
# Nossa MLP com ReLU e Dropout
model = Sequential()
model.add(Dense(hidden_units, input_dim=input_size))
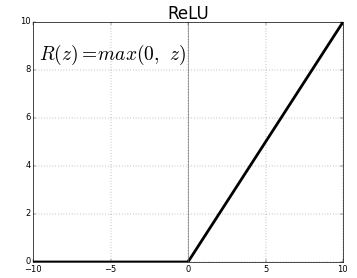
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(hidden_units))
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(num_labels))
Regularización
Una red neuronal tiende a memorizar sus datos de entrenamiento, especialmente si contiene capacidad más que suficiente. En este caso, la red falla catastróficamente cuando se somete a los datos de prueba.
Este es el caso clásico en el que la red no logra generalizar (OverfittingEl sobreajuste, o overfitting, es un fenómeno en el aprendizaje automático donde un modelo se ajusta demasiado a los datos de entrenamiento, capturando ruido y patrones irrelevantes. Esto resulta en un rendimiento deficiente en datos no vistos, ya que el modelo pierde capacidad de generalización. Para mitigar el sobreajuste, se pueden emplear técnicas como la regularización, la validación cruzada y la reducción de la complejidad del modelo.... / UnderfittingEl underfitting es un problema común en el aprendizaje automático que ocurre cuando un modelo es demasiado simple para capturar la complejidad de los datos. Esto se traduce en un rendimiento deficiente tanto en el conjunto de entrenamiento como en el de prueba. Las causas del underfitting pueden incluir un modelo inadecuado, características irrelevantes o insuficientes datos. Para solucionarlo, se puede optar por modelos más complejos o mejorar la calidad...). Para evitar esta tendencia, el modelo utiliza una capa reguladora. Abandonar.
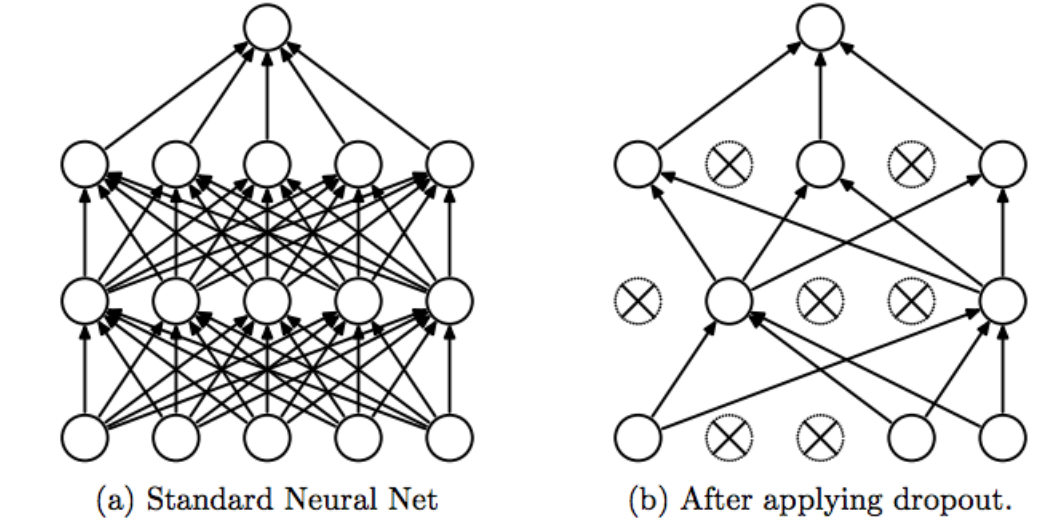
La idea de Dropout es simple. Dada una tasa de descarte (en nuestro modelo, establecemos = 0,45), la capa elimina aleatoriamente esta fracción de unidades.
Por ejemplo, si la primera capa tiene 256 unidades, después de que se aplica el abandono (0.45), solo (1 – 0.45) * 255 = 140 unidades participarán en la siguiente capa
La deserción hace que las redes neuronales sean más robustas para los datos de entrada imprevistos, porque la red está entrenada para predecir correctamente, incluso si algunas unidades están ausentes.
⚠️ El abandono solo participa en «jugar» 🤷🏻♂️ durante el entrenamiento.
Activación
La capa de salidaLa "capa de salida" es un concepto utilizado en el ámbito de la tecnología de la información y el diseño de sistemas. Se refiere a la última capa de un modelo de software o arquitectura que se encarga de presentar los resultados al usuario final. Esta capa es crucial para la experiencia del usuario, ya que permite la interacción directa con el sistema y la visualización de datos procesados.... tiene 10 unidades, seguidas de una función de activación softmax. Las 10 unidades corresponden a las 10 posibles etiquetas, clases o categorías.
La activación de softmax se puede expresar matemáticamente, de acuerdo con la siguiente ecuación:
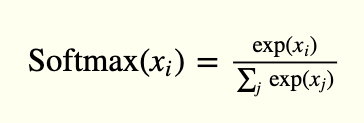
model.add(Activation('softmax'))
model.summary()
OUTPUT:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 256) 200960 _________________________________________________________________ activation (Activation) (None, 256) 0 _________________________________________________________________ dropout (Dropout) (None, 256) 0 _________________________________________________________________ dense_1 (Dense) (None, 256) 65792 _________________________________________________________________ activation_1 (Activation) (None, 256) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_2 (Dense) (None, 10) 2570 _________________________________________________________________ activation_2 (Activation) (None, 10) 0 ================================================================= Total params: 269,322 Trainable params: 269,322 Non-trainable params: 0 _________________________________________________________________
Visualización de modelos
Mejoramiento
El propósito de la Optimización es minimizar la función de pérdida. La idea es que si la pérdida se reduce a un nivel aceptable, el modelo aprendió indirectamente la función que asigna las entradas a las salidas. Las métricas de rendimiento se utilizan para determinar si su modelo ha aprendido.
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=['accuracy'])
-
- Categorical_crossentropy, se utiliza para one-hot
- La precisión es una buena métrica para las tareas de clasificación.
- Adam es un algoritmo de optimizaciónUn algoritmo de optimización es un conjunto de reglas y procedimientos diseñados para encontrar la mejor solución a un problema específico, maximizando o minimizando una función objetivo. Estos algoritmos son fundamentales en diversas áreas, como la ingeniería, la economía y la inteligencia artificial, donde se busca mejorar la eficiencia y reducir costos. Existen múltiples enfoques, incluyendo algoritmos genéticos, programación lineal y métodos de optimización combinatoria.... que se puede utilizar en lugar del procedimiento clásico de descenso de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... estocástico
📌 Dado nuestro conjunto de entrenamiento, la elección de la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y..., el optimizador y el regularizador, podemos comenzar a entrenar nuestro modelo.
model.fit(x_train, y_train, epochs=20, batch_size=batch_size)
OUTPUT:
Epoch 1/20 469/469 [==============================] - 1s 3ms/step - loss: 0.4230 - accuracy: 0.8690
....
Epoch 20/20 469/469 [==============================] - 2s 4ms/step - loss: 0.0515 - accuracy: 0.9835
Evaluación
En este punto, nuestro modelo de clasificador de dígitos MNIST está completo. Su evaluación de desempeño será el siguiente paso para determinar si el modelo entrenado presentará una solución subóptima
_, acc = model.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=0)
print("nAccuracy: %.1f%%n" % (100.0 * acc))
OUTPUT:
Accuracy: 98.4%
continuará…





