Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Visión general
La agrupación en clústeres de K-means es un algoritmo de aprendizaje automático no supervisado muy famoso y poderoso. Se utiliza para resolver muchos problemas complejos de aprendizaje automático sin supervisión. Antes de empezar, echemos un vistazo a los puntos que vamos a entender.
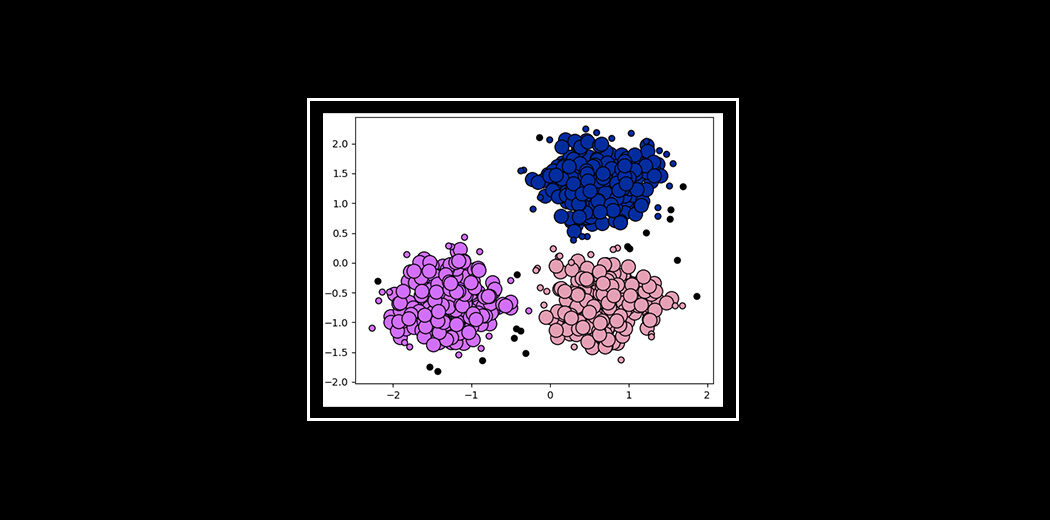
Tabla de contenido
- Introducción
- ¿Cómo funciona el algoritmo K-means?
- ¿Cómo elegir el valor de K?
- Método del codo.
- Método de silueta.
- Ventajas de k-means.
- Desventajas de k-means.
Introducción
Entendamos el algoritmo de agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo... de K-means con su definición simple.
Un algoritmo de agrupación de K-means intenta agrupar elementos similares en forma de agrupaciones. El número de grupos está representado por K.
Pongamos un ejemplo. Suponga que fue a una tienda de verduras a comprar algunas verduras. Allí verá diferentes tipos de verduras. Lo único que notará allí es que las verduras se organizarán en un grupo de sus tipos. Como todas las zanahorias se mantendrán en un solo lugar, las papas se mantendrán con sus tipos y así sucesivamente. Si nota aquí, entonces encontrará que están formando un grupo o grupo, donde cada una de las verduras se mantiene dentro de su tipo de grupo formando los grupos.
Ahora entenderemos esto con la ayuda de una hermosa figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.....
Ahora, mire las dos figuras anteriores. que observaste Hablemos de la primera figura. La primera figura muestra los datos antes de aplicar el algoritmo de agrupamiento de k-medias. Aquí las tres categorías diferentes están desordenadas. Cuando vea esos datos en el mundo real, no podrá averiguar las diferentes categorías.
Ahora, mire la segunda figura (figura 2). Esto muestra los datos después de aplicar el algoritmo de agrupamiento de K-means. puede ver que los tres elementos diferentes se clasifican en tres categorías diferentes que se denominan grupos.
¿Cómo funciona el algoritmo de agrupación en clústeres de K-medias?
La agrupación de k-means intenta agrupar tipos similares de elementos en forma de agrupaciones. Encuentra la similitud entre los elementos y los agrupa en grupos. El algoritmo de agrupación de K-means funciona en tres pasos. Veamos cuáles son estos tres pasos.
- Seleccione los valores de k.
- Inicialice los centroides.
- Seleccione el grupo y encuentre el promedio.
Entendamos los pasos anteriores con la ayuda de la figura porque una buena imagen es mejor que las miles de palabras.
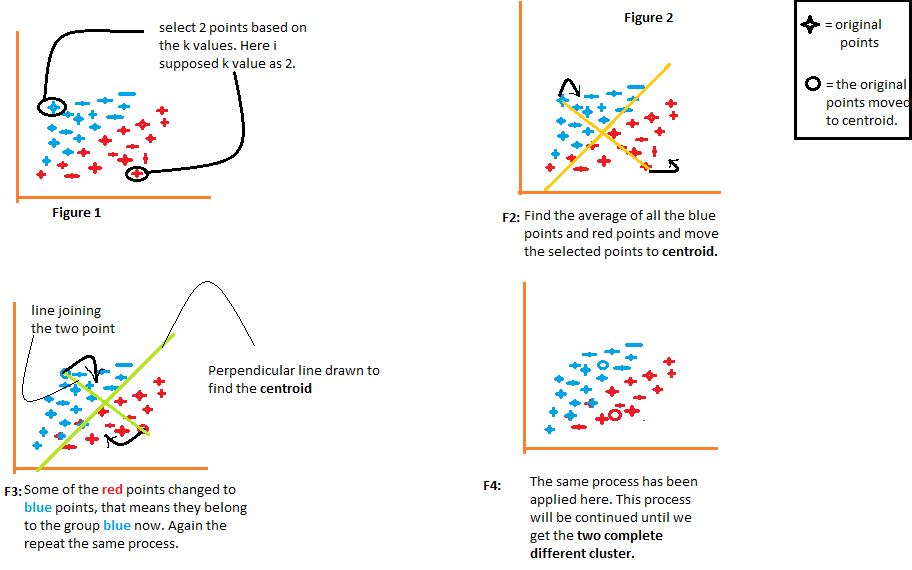
Entenderemos cada figura una a una.
- La figura 1 muestra la representación de datos de dos elementos diferentes. el primer elemento se ha mostrado en color azul y el segundo elemento se ha mostrado en color rojo. Aquí elijo el valor de K aleatoriamente como 2. Hay diferentes métodos mediante los cuales podemos elegir los valores de k correctos.
- En la figura 2, une los dos puntos seleccionados. Ahora, para averiguar el centroide, dibujaremos una línea perpendicular a esa línea. Los puntos se moverán a su centroide. Si observa allí, verá que algunos de los puntos rojos ahora se mueven a los puntos azules. Ahora, estos puntos pertenecen al grupo de elementos de color azul.
- El mismo proceso continuará en la figura 3. Uniremos los dos puntos y dibujaremos una línea perpendicular a eso y encontraremos el centroide. Ahora los dos puntos se moverán a su centroide y nuevamente algunos de los puntos rojos se convertirán en puntos azules.
- El mismo proceso está sucediendo en la figura 4. Este proceso continuará hasta que obtengamos dos grupos completamente diferentes de estos grupos.
NOTA: Tenga en cuenta que la agrupación de K-medias utiliza el método de distancia euclidiana para averiguar la distancia entre los puntos.
Encontrarás muchas explicaciones sobre la distancia euclidiana en Internet.
¿Cómo elegir el valor de K?
Una de las tareas más desafiantes de este algoritmo de agrupación es elegir los valores correctos de k. ¿Cuál debería ser el valor k correcto? ¿Cómo elegir el valor k? Encontremos la respuesta a estas preguntas. Si elige los valores de k al azar, puede que sea correcto o incorrecto. Si elige el valor incorrecto, afectará directamente el rendimiento de su modelo. Entonces, hay dos métodos mediante los cuales puede seleccionar el valor correcto de k.
- Método del codo.
- Método de silueta.
Ahora, entendamos ambos conceptos uno por uno en detalle.
Método del codo
El codo es uno de los métodos más famosos mediante el cual puede seleccionar el valor correcto de k y aumentar el rendimiento de su modelo. También realizamos el ajuste de hiperparámetros para elegir el mejor valor de k. Veamos cómo funciona este método del codo.
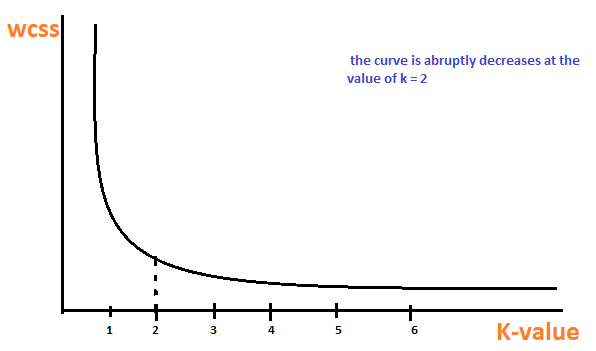
Es un método empírico para encontrar el mejor valor de k. recoge el rango de valores y toma el mejor de ellos. Calcula la suma del cuadrado de los puntos y calcula la distancia media.
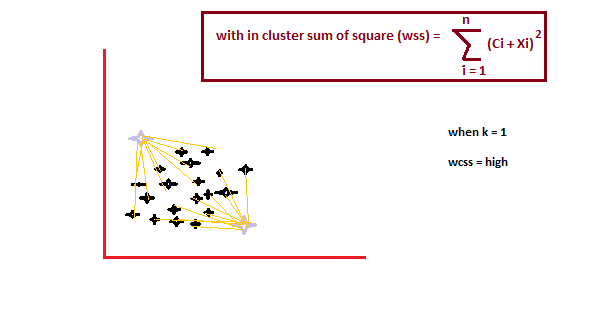
Cuando el valor de k es 1, la suma del cuadrado dentro del grupo será alta. A medida que aumenta el valor de k, la suma del valor cuadrado dentro del grupo disminuirá.
Finalmente, trazaremos un gráfico entre los valores k y la suma del cuadrado dentro del grupo para obtener el valor k. Examinaremos el gráfico cuidadosamente. En algún momento, nuestro gráfico disminuirá abruptamente. Ese punto se considerará como un valor de k.
Método de silueta
El método de la silueta es algo diferente. El método del codo también toma el rango de los valores k y dibuja el gráfico de silueta. Calcula el coeficiente de silueta de cada punto. Calcula la distancia promedio de puntos dentro de su grupo a (I) y la distancia promedio de los puntos a su siguiente grupo más cercano llamado b (I).

Nota: La a (i) el valor debe ser menor que el b (I) valor, que es ai << bi.
Ahora, tenemos los valores de a (i) y b (i). calcularemos el coeficiente de silueta usando la siguiente fórmula.
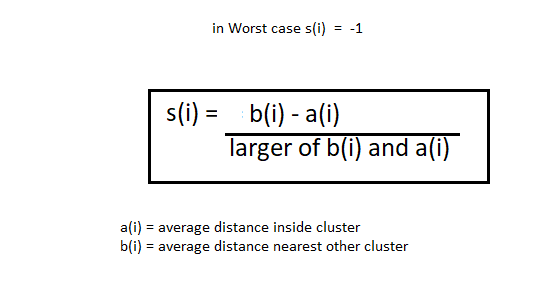
Ahora, podemos calcular el coeficiente de silueta de todos los puntos en los grupos y trazar el gráfico de silueta. Este gráfico también será útil para detectar los valores atípicos. La trama de la silueta está entre -1 a 1.
Tenga en cuenta que para el coeficiente de silueta igual a -1 es el peor de los casos.
Observe la gráfica y verifique cuál de los valores de k está más cerca de 1.
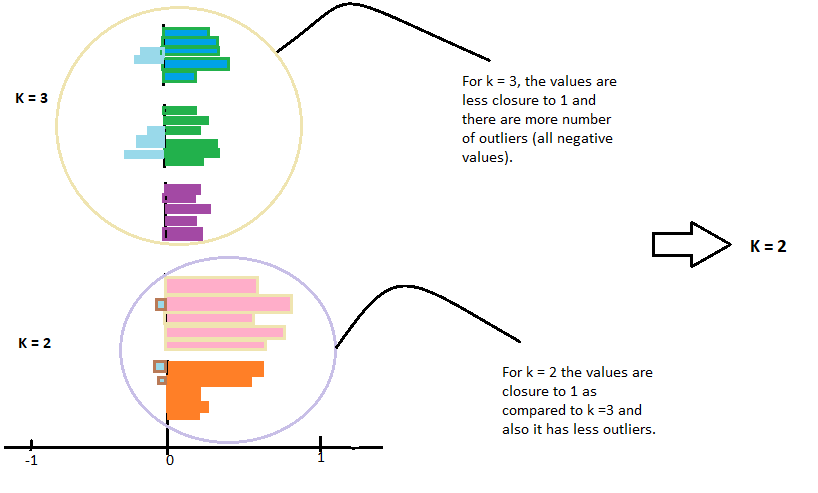
Además, verifique el gráfico que tiene menos valores atípicos, lo que significa un valor menos negativo. Luego elija ese valor de k para que su modelo lo sintonice.
Ventajas de K-means
- Es muy sencillo de implementar.
- Es escalable a un gran conjunto de datos y también más rápido a grandes conjuntos de datos.
- adapta los nuevos ejemplos con mucha frecuencia.
- Generalización de clusters para diferentes formas y tamaños.
Desventajas de K-means
- Es sensible a los valores atípicos.
- Elegir los valores k manualmente es un trabajo difícil.
- A medida que aumenta el número de dimensiones, su escalabilidad disminuye.





