Este artículo fue publicado como parte del Blogatón de ciencia de datos.
af
INTRODUCCIÓN
Recopilar información a través de la web es web scraping, también conocido como Extracción de datos web y recolección web. Hoy en día, los datos son como el oxígeno para las empresas emergentes y autónomos que desean iniciar un negocio o un proyecto en cualquier ámbito. Suponga que desea encontrar el precio de un producto en un sitio web de comercio electrónico. Es fácil de encontrar, pero ahora digamos que tiene que hacer este ejercicio para miles de productos en varios sitios web de comercio electrónico. Haciéndolo manualmente; no es una buena opción en absoluto.
Conozca la herramienta
JavaScript es un lenguaje de programación popular y se ejecuta en cualquier navegador web.
NodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... JS es un intérprete y proporciona un entorno para JavaScript con algunas bibliotecas útiles específicas.
En resumen, Node JS agrega varias funcionalidades y características a JavaScript en términos de bibliotecas y lo hace más poderoso.

SesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... práctica
Vamos a entender el web scraping usando Node JS con un ejemplo. Suponga que desea analizar las fluctuaciones de precios de algunos productos en un sitio web de comercio electrónico. Ahora, debe enumerar todos los posibles factores de la causa y verificarlos con cada producto. De manera similar, cuando desee extraer datos, debe enumerar las etiquetas HTML principales y verificar la etiqueta HTML secundaria respectiva para extraer los datos repitiendo esta actividad.
Pasos necesarios para el web scraping
- Creando el archivo package.json
- Instale y llame a las bibliotecas necesarias
- Seleccione el sitio web y los datos necesarios para raspar
- Establezca la URL y verifique el código de respuesta
- Inspeccione y encuentre las etiquetas HTML adecuadas
- Incluya las etiquetas HTML en nuestro Código
- Verifique los datos extraídos
Estoy usando Visual Studio para ejecutar esta tarea.
Paso 1- Creando el archivo package.json
Para crear un package.json archivo, necesito ejecutar npm init y proporcione algunos detalles según sea necesario en la siguiente captura de pantalla.
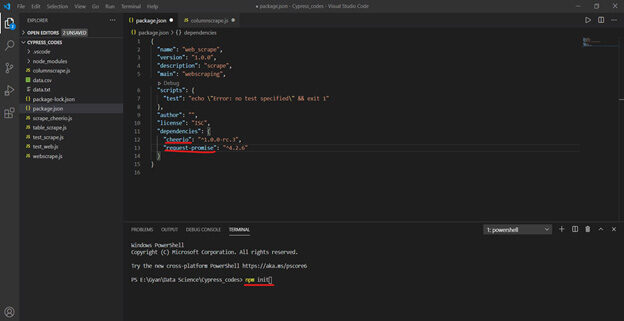
Crear package.json
Paso 2- Instale y llame a las bibliotecas necesarias
Necesita ejecutar los siguientes códigos para instalar estas bibliotecas.

Instalar bibliotecas
Una vez que las bibliotecas adecuadamente instalado, verá que estos mensajes se muestran.

registros después de que se instalen los paquetes
Llame a las bibliotecas requeridas:

Llamar a la biblioteca
Paso 3- Seleccione el sitio web y los datos necesarios para raspar.
Elegí este sitio web «https://www.bullion-rates.com/gold/INR/2007-1-history.htm”Y desea extraer datos de las tasas de oro junto con las fechas.
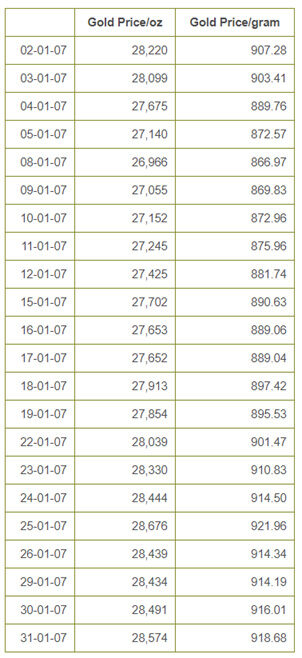
Datos que queremos raspar
Paso 4- Establezca la URL y verifique el código de respuesta
El código JS del nodo se ve así para pasar la URL y verificar el código de respuesta.

Pasar URL y obtener código de respuesta
Paso 5- Inspeccione y encuentre las etiquetas HTML adecuadas
Es bastante fácil encontrar las etiquetas HTML adecuadas en las que están presentes sus datos.
Para ver las etiquetas HTML; haga clic derecho y seleccione la opción inspeccionar.
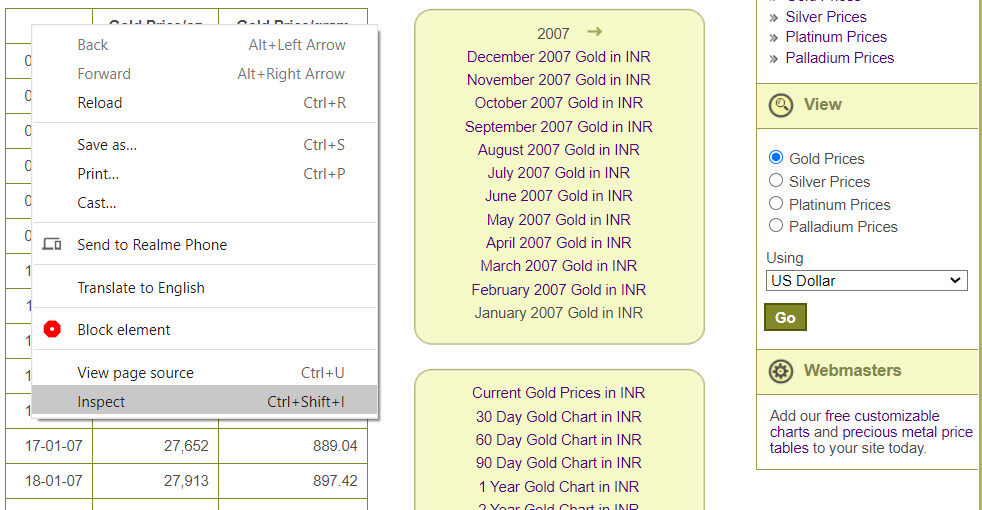
Inspeccionar las etiquetas HTML
Seleccione las etiquetas HTML adecuadas: –
Si te diste cuenta están Tres columnas en nuestra tabla, por lo que nuestra etiqueta HTML para la fila de la tabla sería «HeaderRow» & todos los nombres de las columnas están presentes con la etiqueta “Th” (encabezado de la tabla).
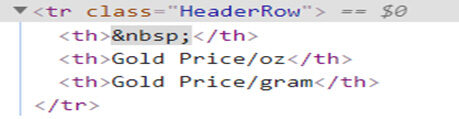
Y para cada uno fila de la tabla («tr») nuestros datos residen en «DataRow ” Etiqueta HTML
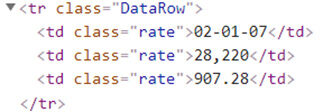
Ahora, necesito que todas las etiquetas HTML residan en «HeaderRow«Y necesito encontrar todos los»th«Etiquetas HTML y finalmente iterar»DataRow”Etiqueta HTML para obtener todos los datos que contiene.
Paso 6- Incluya las etiquetas HTML en nuestro Código
Después de incluir las etiquetas HTML, nuestro código será: –
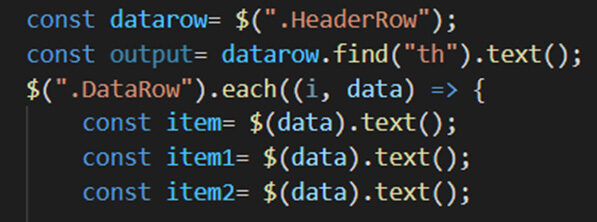
Fragmento de código
Paso 7- Verifique los datos raspados
Imprima los datos, por lo que el código para esto es como: –

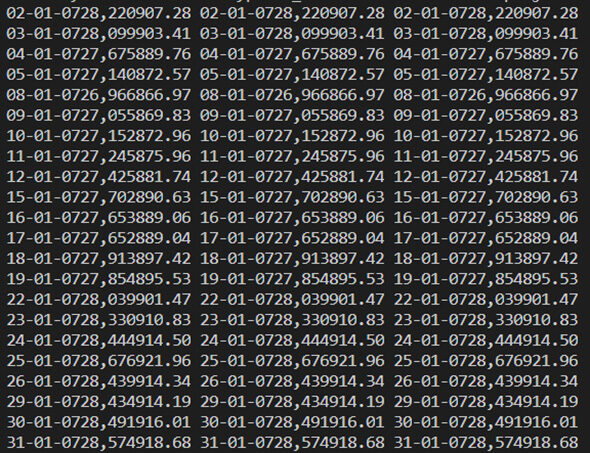
Nuestros datos raspados
Si pasa a un nivel más granular de etiquetas HTML y las itera en consecuencia, obtendrá datos más precisos.
Eso es todo sobre raspado web y cómo obtener datos de calidad poco común como el oro.
Conclusión
Traté de explicar Web Scraping usando Node JS de una manera precisa. Espero que esto te ayude.
Encuentra el código completo en
Si tiene alguna pregunta sobre el código o el web scraping en general, comuníquese conmigo en
Vgyaan’s – Linkedin
Nos volveremos a encontrar con algo nuevo.
Hasta entonces,
Codificación feliz ..!





