Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Einführung
Big Data bezeichnet eine Kombination aus strukturierten und unstrukturierten Daten, die in Petabyte oder Exabyte gemessen werden können. Wie gewöhnlich, Wir verwenden 3V, um die 3V von Big Data zu charakterisieren, nämlich, die Datenmenge, die Vielfalt der Datentypen und die Geschwindigkeit, mit der sie verarbeitet werden.
Diese drei Eigenschaften erschweren die Verwaltung von Big Data. Deswegen, Big Data ist investitionsintensiv auf einer großen Menge an Serverspeicher, ausgereifte Analysemaschinen und Data-Mining-Methoden. METROJede Organisation findet dies sowohl technisch als auch finanziell umständlich und, Daher, du denkst darüber nach, wie du es erreichen kannst Ähnliche Ergebnisse können mit viel weniger Aufwand erzielt werden.. Deswegen, versuchen aus Big Data kleine Daten zu machen., bestehend aus nutzbaren Datenblöcken. La siguiente Abbildung"Abbildung" ist ein Begriff, der in verschiedenen Zusammenhängen verwendet wird, Von der Kunst zur Anatomie. Im künstlerischen Bereich, bezieht sich auf die Darstellung menschlicher oder tierischer Formen in Skulpturen und Gemälden. In der Anatomie, bezeichnet die Form und Struktur des Körpers. Was ist mehr, in der Mathematik, "Abbildung" Es hängt mit geometrischen Formen zusammen. Seine Vielseitigkeit macht es zu einem grundlegenden Konzept in mehreren Disziplinen.... [1] einen Vergleich anzeigen.
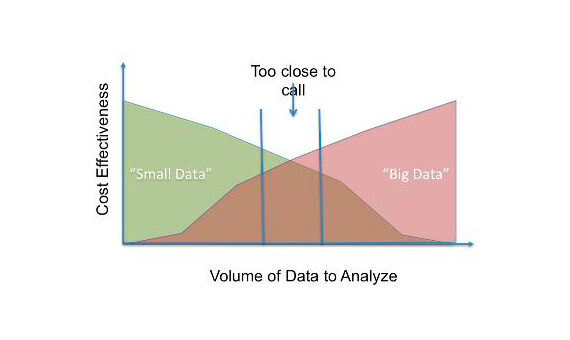
Versuchen wir, eine einfache statistische Technik zu erkunden, die verwendet werden kann, um aus Big Data ein verwertbares Stück Daten zu erstellen. Die Probe, was im Grunde eine Teilmenge der Bevölkerung ist, sollte so gewählt werden, dass die Bevölkerung angemessen repräsentiert wird. Dies kann durch statistische Tests sichergestellt werden.
Einführung in die Reservoir-Probenahme
La idea clave detrás del muestreo de reservorios es crear un ‚reservorio‘ aus einem großen Ozean von Daten. Sea ‚n‘ el tamaño de la población y ‚n‘ Die Größe der Stichprobe. Jedes Element der Grundgesamtheit hat die gleiche Wahrscheinlichkeit, in der Stichprobe vorhanden zu sein, und diese Wahrscheinlichkeit ist (n / n). Mit dieser Schlüsselidee, wir müssen eine Unterstichprobe erstellen. Es ist zu beachten, dass wenn wir ein Muster erstellen, Verteilungen müssen nicht nur in Zeilen, sondern auch in Spalten identisch sein.
Wie gewöhnlich, wir konzentrieren uns nur auf die reihen, aber es ist auch wichtig, die Verteilung der Spalten beizubehalten. Las columnas son las características de las que aprende el algoritmo de AusbildungTraining ist ein systematischer Prozess zur Verbesserung der Fähigkeiten, körperliche Kenntnisse oder Fähigkeiten. Es wird in verschiedenen Bereichen angewendet, wie Sport, Aus- und Weiterbildung. Zu einem effektiven Trainingsprogramm gehört auch die Zielplanung, Regelmäßiges Üben und Bewerten der Fortschritte. Anpassung an individuelle Bedürfnisse und Motivation sind Schlüsselfaktoren, um in jeder Disziplin erfolgreiche und nachhaltige Ergebnisse zu erzielen..... Deswegen, Außerdem müssen wir für jedes Feature statistische Tests durchführen, um sicherzustellen, dass die Verteilung identisch ist.
Der Algorithmus ist wie folgt: Inicialice el yacimiento con los primeros ‚n‘ elementos de la población de tamaño ‚n‘. Dann lesen Sie jede Zeile in Ihrem Datensatz (ich> n). In jeder Iteration, Berechnung (n / ich). Reemplazamos los elementos del reservorio del siguiente conjunto de ‚n‘ Items mit allmählich abnehmender Wahrscheinlichkeit.
R[ich] = S[ich]
für i = n+1 bis N:
j = U ~ [1, ich]
wenn ich <= n:
R[J] = S[ich]
Statistische Tests
Wie ich bereits erwähnte, wir müssen sicherstellen, dass alle Spalten (Merkmale) des Reservoirs sind identisch auf die Bevölkerung verteilt. Wir werden den Kolmogorov-Smirnov-Test für kontinuierliche Merkmale und den Pearson-Chi-Quadrat-Test für kategoriale Merkmale verwenden..
Der Kolmogorov-Smirnov-Test wird verwendet, um zu überprüfen, ob die kumulativen Verteilungsfunktionen (CDF) der Grundgesamtheit und der Stichprobe sind gleich. Wir vergleichen die CDF der Bevölkerung F_N (x) mit der Probe F_n (x).
fnx
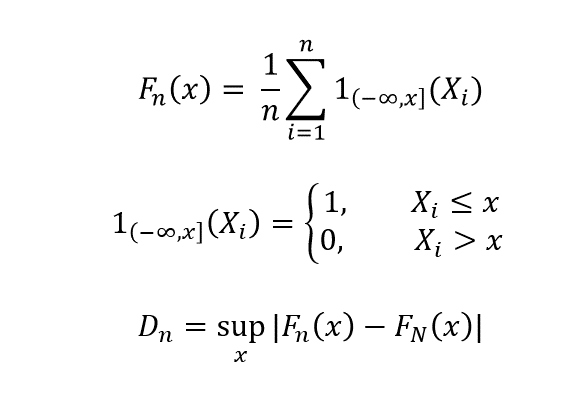
Als n -> n, D_n -> 0, wenn die Verteilungen identisch sind. Dieser Test sollte für alle Merkmale des Datensatzes durchgeführt werden, die kontinuierlich sind.
Für kategoriale Merkmale, Wir können den Chi-Quadrat-Test nach Pearson durchführen. Sea O_i el número de observaciones de la categoría ‚ich‘ und ne die anzahl der proben. Sea E_i el recuento esperado de la categoría ‚ich‘. Entonzen E_i = N p_i, donde p_i es la probabilidad de pertenecer a la categoría ‚ich‘. Dann ist der Chi-Quadrat-Wert durch die folgende Beziehung gegeben:
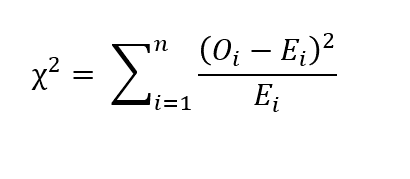
Wenn Chi-Quadrat = 0, das heißt die beobachteten Werte und die erwarteten Werte sind gleich. Wenn der p-Wert des statistischen Tests größer als das Signifikanzniveau ist, wir sagen, dass die Stichprobe statistisch signifikant ist.
Abschließende Anmerkungen
Die Probenahme von Reservoirs kann verwendet werden, um aus Big Data ein nützliches Datenelement zu erstellen, solange die beiden Tests, Kolmogorov-Smirnov und Pearsons Chi-Quadrat, erfolgreich sein. Aktuelle Gerüchte sind, Natürlich, Große Daten. Zentralisierte Modelle wie Big-Data-Architekturen haben große Schwierigkeiten. Dinge zu dezentralisieren und, Daher, Arbeit modular machen, wir müssen kleine Bits von nützlichen Daten erstellen und dann aussagekräftige Informationen daraus erhalten. Ich denke, dass mehr Anstrengungen in diese Richtung unternommen werden sollten, anstatt in Architektur zu investieren, um Big Data zu unterstützen.
Verweise
1. https://www.bbvaopenmind.com/en/technology/digital-world/small-data-vs-big-data-back-to-the-basics/





