Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung:
Technologie. Dieser Datensatz besteht aus handgeschriebenen Ziffern aus dem 0 al 9 und bietet eine Fahrbahn zum Testen von Bildverarbeitungssystemen. Este se considera el ‚programa hola mundo en Machine Learning‘ que involucra Deep Learning.
Die erforderlichen Schritte sind:
- Datensatz importieren
- Dividir el conjunto de datos en prueba y AusbildungTraining ist ein systematischer Prozess zur Verbesserung der Fähigkeiten, körperliche Kenntnisse oder Fähigkeiten. Es wird in verschiedenen Bereichen angewendet, wie Sport, Aus- und Weiterbildung. Zu einem effektiven Trainingsprogramm gehört auch die Zielplanung, Regelmäßiges Üben und Bewerten der Fortschritte. Anpassung an individuelle Bedürfnisse und Motivation sind Schlüsselfaktoren, um in jeder Disziplin erfolgreiche und nachhaltige Ergebnisse zu erzielen....
- Bau des Modells
- Trainiere das Modell
- Genauigkeit vorhersagen
1) Datensatzimport:
Um mit dem Code fortzufahren, wir brauchen den datensatz. Dann, wir betrachten verschiedene Quellen als Datensätze, FIA, kaggle, etc. Aber da wir Python mit seinen umfangreichen eingebauten Modulen verwenden, hat die MNIST-Daten im Modul keras.datasets. Deswegen, wir müssen die Daten nicht extern herunterladen und speichern.
von keras.datsets importieren mnist data = mnist.load_data()
Deswegen, aus dem keras.datasets-Modul importieren wir die mnist-Funktion, die den Datensatz enthält.
Später, der Datensatz wird mit der Funktion mnist.load_data in den variablen Daten gespeichert () was den Datensatz in variable Daten lädt.
Dann, Sehen wir uns den Datentyp an, den wir etwas ungewöhnlich finden, da er vom Tupeltyp ist. Wir wissen, dass der mnist-Datensatz Bilder von handgeschriebenen Ziffern enthält, in Form von Tupeln gespeichert.
Daten Typ(Daten)
2) Teilen Sie den Datensatz in trainieren und testen:
Wir unterteilen den Datensatz direkt in Train und Test. Dann, Dafür, wir initialisieren vier Variablen X_train, y_train, X_test, y_test, um den Zug zu beschädigen und die Daten auf die abhängigen bzw. unabhängigen Werte zu testen.
(X_Zug, y_train), (X_test, y_test) = Daten X_Zug[0].Form X_train.shape

Durch Drucken der Form jedes Bildes können wir feststellen, dass es eine Größe von . hat 28 × 28. Das heißt, das Bild hat 28 Pixel x 28 Pixel.
Jetzt, wir müssen so umformen, dass wir auf jedes Pixel des Bildes zugreifen können. La razón para acceder a cada píxel es que solo entonces podemos aplicar ideas de tiefes LernenTiefes Lernen, Eine Teildisziplin der Künstlichen Intelligenz, verlässt sich auf künstliche neuronale Netze, um große Datenmengen zu analysieren und zu verarbeiten. Diese Technik ermöglicht es Maschinen, Muster zu lernen und komplexe Aufgaben auszuführen, wie Spracherkennung und Computer Vision. Seine Fähigkeit, sich kontinuierlich zu verbessern, wenn mehr Daten zur Verfügung gestellt werden, macht es zu einem wichtigen Werkzeug in verschiedenen Branchen, von Gesundheit... y podemos asignar un código de color a cada píxel. Dann speichern wir das umgeformte Array in X_train, X_test bzw..
X_train = X_train.reshape((X_train.shape[0], 28*28)).astyp('float32')
X_test = X_test.reshape((X_test.shape[0], 28*28)).astyp('float32')
Wir kennen den RGB-Farbcode, bei dem verschiedene Werte verschiedene Farben erzeugen. Es ist auch schwierig, sich alle Farbkombinationen zu merken. Dann, beziehe dich darauf Verknüpfung um eine kurze Vorstellung von RGB-Farbcodes zu bekommen.
Wir wissen bereits, dass jedes Pixel seinen einzigartigen Farbcode hat und wir wissen auch, dass es einen Maximalwert von hat 255. Pararealisiertes maschinelles Lernen, Es ist wichtig, alle Werte von umzuwandeln 0 ein 255 für jedes Pixel auf einen Wertebereich von 0 ein 1. Der einfachste Weg ist, den Wert jedes Pixels durch zu teilen 255 um die Werte im Bereich von zu erhalten 0 ein 1.
X_Zug = X_Zug / 255 X_test = X_test / 255
Jetzt haben wir die Aufteilung der Daten in Test und Training abgeschlossen, sowie die Aufbereitung der Daten für die spätere Verwendung. Deswegen, jetzt können wir weiter zum Pass 3: Modellbau.
3) Trainiere das Modell:
Modellbau durchführen, wir müssen die benötigten Funktionen importieren, nämlich, sequentiell und dicht, um Deep Learning durchzuführen, die in der Keras-Bibliothek verfügbar ist.
Aber das ist nicht direkt verfügbar, por lo que debemos comprender este simple LiniendiagrammDas Liniendiagramm ist ein visuelles Werkzeug, das zur Darstellung von Daten im Zeitverlauf verwendet wird. Es besteht aus einer Reihe von Punkten, die durch Linien verbunden sind, die es Ihnen ermöglicht, Trends zu beobachten, Schwankungen und Muster in den Daten. Diese Art von Diagramm ist besonders nützlich in Bereichen wie der Wirtschaft, Meteorologie und wissenschaftliche Forschung, Dies erleichtert den Vergleich verschiedener Datensätze und die Identifizierung von Verhaltensweisen auf breiter Front..:
1) Schwer -> Modelle -> Sequentiell
2) Schwer -> Abdeckungen -> Denso
Sehen wir uns an, wie wir die Funktionen mit derselben Logik wie einen Python-Code importieren können.
von keras.models importieren Sequential aus keras.layers importieren dicht Modell = Sequentiell() model.add(Dicht(32, input_dim = 28 * 28, Aktivierung = 'neu lesen')) model.add(Dicht(64, Aktivierung = 'neu lesen')) model.add(Dicht(10, Aktivierung = 'softmax'))
Luego almacenamos la función en el modelo de VariableIn Statistik und Mathematik, ein "Variable" ist ein Symbol, das einen Wert darstellt, der sich ändern oder variieren kann. Es gibt verschiedene Arten von Variablen, und qualitativ, die nicht-numerische Eigenschaften beschreiben, und quantitative, numerische Größen darstellen. Variablen sind grundlegend in Experimenten und Studien, da sie die Analyse von Beziehungen und Mustern zwischen verschiedenen Elementen ermöglichen, das Verständnis komplexer Phänomene zu erleichtern...., da es einfach ist, jedes Mal auf die Funktion zuzugreifen, anstatt die Funktion jedes Mal einzugeben, Wir können die Variable verwenden und die Funktion aufrufen.
Später, convierta la imagen en un grupo denso de capas y apile cada capa una encima de la otra y usamos ‚Lebenslauf‘ como nuestra WeckfunktionDie Aktivierungsfunktion ist eine Schlüsselkomponente in neuronalen Netzen, da es den Output eines Neurons auf der Grundlage seiner Eingabe bestimmt. Sein Hauptzweck besteht darin, Nichtlinearitäten in das Modell einzuführen, Ermöglicht das Erlernen komplexer Muster in Daten. Es gibt verschiedene Aktivierungsfunktionen, wie das Sigmoid, ReLU und tanh, jedes mit besonderen Eigenschaften, die sich auf die Leistung des Modells in verschiedenen Anwendungen auswirken..... La explicación de ‚Lebenslauf‘ sprengt den Rahmen dieses Blogs. Um mehr darüber zu erfahren, du kannst dich beraten das.
Außerdem, apilamos algunas capas más con ‚softmax‘ als unsere Aktivierungsfunktion. Para obtener más información sobre la función ‚softmax‘, Sie können auf diesen Artikel verweisen, da es wieder den Rahmen dieses Blogs sprengt, da mein Hauptziel darin besteht, mit dem MNIST-Datensatz so genau wie möglich zu werden.
Später, schließlich kompilieren wir das vollständige Modell und verwenden Kreuzentropie como nuestra Verlust-FunktionDie Verlustfunktion ist ein grundlegendes Werkzeug des maschinellen Lernens, das die Diskrepanz zwischen Modellvorhersagen und tatsächlichen Werten quantifiziert. Ziel ist es, den Trainingsprozess zu steuern, indem dieser Unterschied minimiert wird, Dadurch kann das Modell effektiver lernen. Es gibt verschiedene Arten von Verlustfunktionen, wie z. B. mittlerer quadratischer Fehler und Kreuzentropie, jeder für unterschiedliche Aufgaben geeignet und..., um die Nutzung unseres Modells zu optimieren Adam als unser Optimierer und wir verwenden Präzision als Metriken, um unser Modell zu bewerten.
Für einen Überblick über unser Modell, wir gebrauchen ‚Modell.Zusammenfassung ()‘, die kurze Details zu unserem Modell enthält.
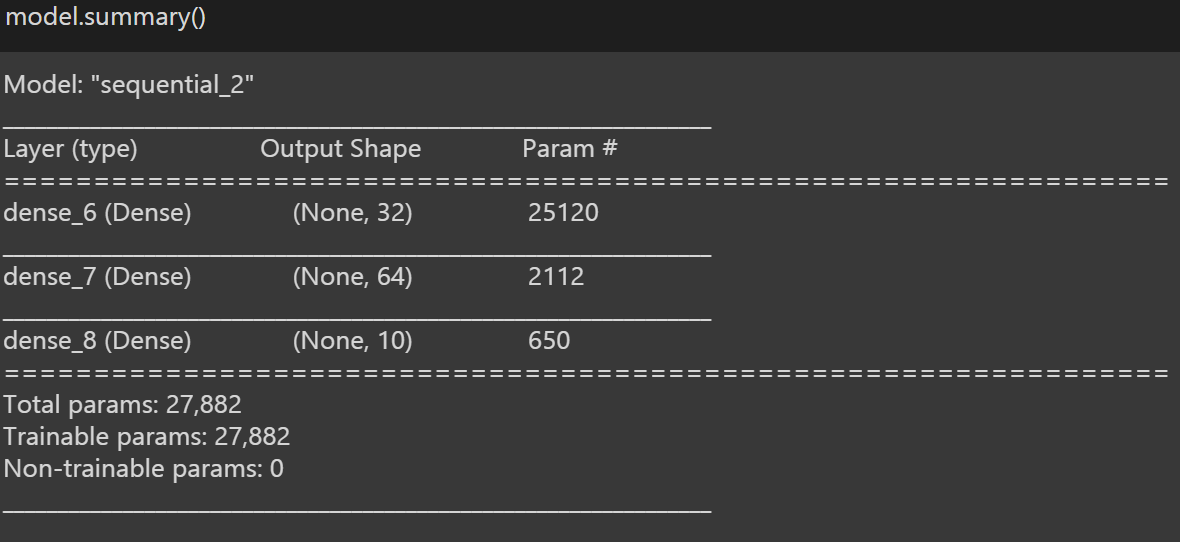
Jetzt können wir zum Pass übergehen 4: Trainiere das Modell.
4) Trainiere das Modell:
Dies ist der vorletzte Schritt, in dem wir das Modell mit einer einzigen Codezeile trainieren. Dann, Dafür, Wir verwenden die .fit-Funktion () die die Menge der Züge der abhängigen Variablen und der unabhängigen und abhängigen Variablen als Input nimmt, und Epochen setzen = 10, und setze batch_size als 100.
Zugset => X_Zug; y_train
Epochen => Una época significa entrenar la rotes neuronalesNeuronale Netze sind Rechenmodelle, die von der Funktionsweise des menschlichen Gehirns inspiriert sind. Sie nutzen Strukturen, die als künstliche Neuronen bekannt sind, um Daten zu verarbeiten und daraus zu lernen. Diese Netze sind grundlegend im Bereich der künstlichen Intelligenz, Dies ermöglicht erhebliche Fortschritte bei Aufgaben wie der Bilderkennung, Verarbeitung natürlicher Sprache und Vorhersage von Zeitreihen, unter anderen. Ihre Fähigkeit, komplexe Muster zu erlernen, macht sie zu mächtigen Werkzeugen.. con todos los datos de entrenamiento para un ciclo. Eine Epoche besteht aus einer oder mehreren Chargen, wobei wir einen Teil des Datensatzes verwenden, um das neuronale Netz zu trainieren. Das heißt, wir schicken das Modell ins Training 10 Mal, um eine hohe Präzision zu erreichen. Sie können auch die Anzahl der Epochen basierend auf der Leistung des Modells ändern.
Losgröße => Batchgröße ist ein Begriff aus dem maschinellen Lernen und bezieht sich auf die Anzahl der Trainingsbeispiele, die in einer Iteration verwendet werden. Dann, Grundsätzlich, wir senden 100 Bilder als Batch pro Iteration zu trainieren.
Sehen wir uns den Kodierungsteil an.
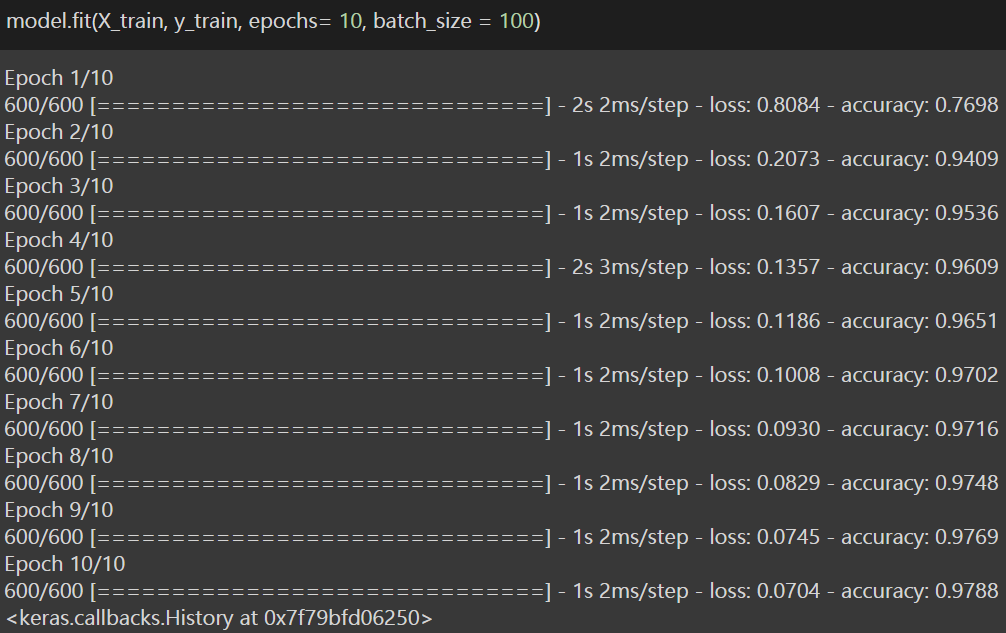
Deswegen, nach dem Training des Modells, wir haben eine genauigkeit von erreicht 97,88% für Trainingsdatensatz. Jetzt ist es an der Zeit zu sehen, wie das Modell im Testset funktioniert und ob wir die erforderliche Genauigkeit erreicht haben. Deswegen, jetzt gehen wir zum letzten schritt oder schritt 5: Genauigkeit vorhersagen.
5) Vorhersagegenauigkeit:
Dann, um herauszufinden, wie gut das Modell auf dem Testdatensatz funktioniert, Ich verwende die Scores-Variable, um den Wert zu speichern und verwende die .evaluate-Funktion () die die Testmenge der abhängigen und unabhängigen Variablen als Eingabe verwendet. Dies berechnet den Verlust und die Genauigkeit des Modells im Testsatz. Wie wir auf Präzision setzen, wir drucken nur die präzision.

Schließlich, wir haben das ergebnis erreicht und garantieren eine genauigkeit von mehr als 96% im Test-Set, was sehr bemerkenswert ist, und das Blogmotiv ist erreicht. Ich habe den Link zu geschrieben Laptop für ihre referenz (Leser).
Bitte, kontaktiere mich gerne durch Linkedin ebenso gut wie. Und danke fürs Lesen des Blogs.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





