Einführung
Viele Analysten missverstehen den Begriff „Impuls“ in der Datenwissenschaft verwendet. Lassen Sie mich Ihnen eine interessante Erklärung dieses Begriffs geben.. Momentum ermöglicht Machine-Learning-Modellen, ihre Vorhersagegenauigkeit zu verbessern.
Boost-Algorithmen sind einer der am weitesten verbreiteten Algorithmen bei Data-Science-Wettbewerben. Die Gewinner unserer neueste Hackathons stimmen zu, dass sie versuchen, den Algorithmus voranzutreiben, um die Genauigkeit ihrer Modelle zu verbessern.
In diesem Artikel, Ich werde ganz einfach erklären, wie der Boost-Algorithmus funktioniert. Ich habe auch die Python-Codes unten geteilt. Ich habe die einschüchternden mathematischen Ableitungen, die in Boosting verwendet werden, übersprungen. Denn das hätte mir nicht erlaubt, dieses Konzept in einfachen Worten zu erklären.
Lasst uns beginnen.

Was ist Boost?
Definition: Der Begriff „Impuls“ bezieht sich auf eine Familie von Algorithmen, die aus einem schwachen Schüler einen starken Schüler macht.
Lassen Sie uns diese Definition im Detail verstehen, indem wir ein Problem bei der Spam-Identifikation lösen:
Wie würden Sie eine E-Mail als SPAM einstufen oder nicht?? Wie jeder andere, Unser erster Ansatz wäre, die E-Mails zu identifizieren „Spam“ Ja „kein Spam“ anhand der folgenden Kriterien. Und:
- Die E-Mail enthält nur eine Bilddatei (Werbebild), sind SPAM
- E-Mail hat nur Link (S), sind SPAM
- Der Text der E-Mail besteht aus einem Satz wie „Sie haben einen Geldpreis von . gewonnen $ xxxxxx“, sind SPAM
- E-Mail von unserer offiziellen Domain „Analyticsvidhya.com„, Es ist kein SPAM
- E-Mail von bekannter Quelle, kein Spam
Vorher, hemos definido varias reglas para clasificar un correo electrónico en ‚Spam‘ Ö ‚kein Spam‘. Aber, Glauben Sie, dass diese Regeln einzeln stark genug sind, um eine E-Mail erfolgreich zu klassifizieren?? Nein.
Individuell, estas reglas no son lo suficientemente poderosas como para clasificar un correo electrónico en ‚Spam‘ Ö ‚kein Spam‘. Deswegen, diese regeln heißen schwacher Lerner.
Aus einem schwachen Schüler einen starken Schüler zu machen, Wir kombinieren die Vorhersage jedes schwachen Schülers mit Methoden wie:
• Durchschnitt verwenden / gewichteter Durchschnitt
• Bedenkt man, dass die Vorhersage eine höhere Stimme hat
Zum Beispiel: hoch, wir haben definiert 5 schwache Schüler. Von diesen 5, 3 se votan como ‚SPAM‘ Ja 2 se votan como ‚No es SPAM‘. In diesem Fall, standardmäßig, wir werden eine E-Mail als SPAM betrachten, weil wir eine höhere Stimmenzahl haben (3) zu ‚SPAM‘.
Wie funktionieren Impulsalgorithmen?
Wir wissen jetzt, dass Schwung einen schwachen Schüler verbindet, auch bekannt als Grundschüler, einen festen Herrscher bilden. Eine unmittelbare Frage, die sich in Ihrem Kopf stellen sollte, ist: ‚So fördern Sie die Identifizierung schwacher Regeln?‚
Um eine schwache Regel zu finden, Wir wenden grundlegende Lernalgorithmen an (ML) mit anderer Verteilung. Jedes Mal, wenn der Basislernalgorithmus angewendet wird, erzeugt eine neue schwache Vorhersageregel. Dies ist ein iterativer Prozess. Nach vielen Iterationen, der Impulsalgorithmus kombiniert diese schwachen Regeln zu einer einzigen starken Vorhersageregel.
Hier ist eine weitere Frage, die dich verfolgen könnte “.Wie wählen wir für jede Runde eine andere Verteilung?? ‚
So wählen Sie das richtige Layout, Das sind die nächsten Schritte:
Paso 1: Der Grundschüler nimmt alle Verteilungen und weist jeder Beobachtung das gleiche Gewicht oder die gleiche Aufmerksamkeit zu.
Paso 2: Wenn Vorhersagefehler durch den ersten Basislernalgorithmus auftreten, dann achten wir mehr auf Beobachtungen, die einen Vorhersagefehler haben. Später, wir wenden den folgenden Basislernalgorithmus an.
Paso 3: Schritt wiederholen 2 bis das Limit des Basislernalgorithmus erreicht ist oder eine höhere Genauigkeit erreicht ist.
Schließlich, kombiniert die Ergebnisse des schwachen Schülers und schafft einen starken Schüler, der letztendlich die Vorhersagekraft des Modells verbessert. Der Impuls wird mehr Aufmerksamkeit auf Beispiele geschenkt, die aufgrund der oben genannten schwachen Regeln falsch klassifiziert sind oder höhere Fehler aufweisen.
Arten von Impulsalgorithmen
Die zugrunde liegende Engine, die zum Antreiben von Algorithmen verwendet wird, kann alles sein. Es kann ein Stempel der Entscheidung sein, ein Sortieralgorithmus, der die Margen maximiert, etc. Es gibt viele Boost-Algorithmen, die andere Arten von Motoren verwenden, Was:
- AdaBoost (Es gibtptive ZunahmeGespenstisch)
- Steigung des Gradientenbaums
- XGBoost
In diesem Artikel, Wir werden uns auf AdaBoost und Gradient Boosting konzentrieren, gefolgt von ihren jeweiligen Python-Codes und wir werden uns im nächsten Artikel auf XGboost konzentrieren.
Algorithmus-Augmentation: AdaBoost
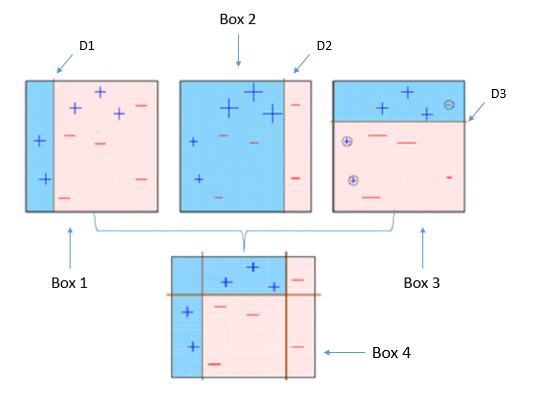
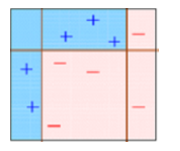
Dieses Diagramm erklärt treffend Ada-boost. Lass uns genau verstehen:
Kasten 1: Sie können sehen, dass wir jedem Datenpunkt gleiche Gewichte zugewiesen und einen Entscheidungsstumpf angewendet haben, um sie zu klassifizieren als + (Plus) Ö – (weniger). Der Entscheidungsstumpf (D1) hat auf der linken Seite eine vertikale Linie erzeugt, um die Datenpunkte zu klassifizieren. Wir sehen das, diese vertikale Linie hat fälschlicherweise drei vorhergesagt + (Plus) Was – (weniger). In diesem Fall, wir werden diesen dreien höhere Gewichte zuweisen + (Plus) und wir werden einen weiteren Entscheidungsstumpf anwenden.
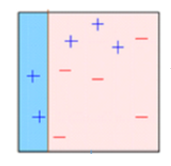
Kasten 2: Hier, Sie können sehen, dass die Größe von drei + (Plus) falsch vorhergesagt ist höher im Vergleich zu den anderen Datenpunkten. In diesem Fall, der zweite entscheidungsstumpf (D2) werde versuchen, sie richtig vorherzusagen. Jetzt, eine vertikale Linie (D2) auf der rechten Seite dieser Tabelle haben Sie drei richtig klassifiziert + (Plus) falsch klassifiziert. Aber wieder, hat Fehlklassifizierungsfehler verursacht. Diesmal mit drei – (weniger). Nochmal, wir werden drei stärker gewichten – (weniger) und wir werden einen weiteren Entscheidungsstumpf anwenden.
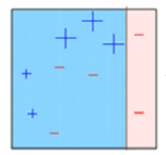
Kasten 3: Hier, drei – (weniger) höhere Gewichte erhalten. Ein Entscheidungsstumpf wird aufgebracht (D3) diese falsch klassifizierten Beobachtungen richtig vorherzusagen. Diesmal wird eine horizontale Linie erzeugt, um zu klassifizieren + (Plus) Ja – (weniger) basierend auf einem höheren Gewicht falsch klassifizierter Beobachtungen.
Kasten 4: Hier, wir haben D1 . kombiniert, D2 und D3, um eine starke Vorhersage zu bilden, die im Vergleich zu einem einzelnen schwachen Schüler eine komplexe Regel hat. Sie können sehen, dass dieser Algorithmus diese Beobachtungen im Vergleich zu jedem einzelnen schwachen Schüler ziemlich gut klassifiziert hat..
AdaBoost (Es gibtptive Zunahmeing): Es funktioniert mit einer ähnlichen Methode wie oben beschrieben. Se ajusta a una secuencia de estudiantes débiles en diferentes datos de AusbildungTraining ist ein systematischer Prozess zur Verbesserung der Fähigkeiten, körperliche Kenntnisse oder Fähigkeiten. Es wird in verschiedenen Bereichen angewendet, wie Sport, Aus- und Weiterbildung. Zu einem effektiven Trainingsprogramm gehört auch die Zielplanung, Regelmäßiges Üben und Bewerten der Fortschritte. Anpassung an individuelle Bedürfnisse und Motivation sind Schlüsselfaktoren, um in jeder Disziplin erfolgreiche und nachhaltige Ergebnisse zu erzielen.... ponderados. Beginnen Sie mit der Vorhersage des ursprünglichen Datensatzes und geben Sie jeder Beobachtung das gleiche Gewicht. Wenn die Vorhersage mit dem ersten Schüler falsch ist, dann erhalten falsch vorhergesagte Beobachtungen ein höheres Gewicht. Ein iterativer Prozess sein, setzt das Hinzufügen von Lernenden fort, bis ein Limit für die Anzahl der Modelle oder die Genauigkeit erreicht ist.
Hauptsächlich, wir verwenden Entscheidungsstempel mit AdaBoost. Aber wir können jeden maschinellen Lernalgorithmus als Basislerner verwenden, wenn er die Gewichtung im Trainingsdatensatz akzeptiert. Wir können AdaBoost-Algorithmen für Klassifizierungs- und Regressionsprobleme verwenden.
Sie können auf den Artikel verweisen „Wie man mit maschinellem Lernen schlau wird: AdaBoost“ um die AdaBoost-Algorithmen genauer zu verstehen.
Python-Code
Hier ist ein Live-Encoding-Fenster, um Ihnen den Einstieg zu erleichtern. Sie können die Codes ausführen und das Ergebnis in diesem Fenster abrufen:
Puede ajustar los ParameterDas "Parameter" sind Variablen oder Kriterien, die zur Definition von, ein Phänomen oder System zu messen oder zu bewerten. In verschiedenen Bereichen wie z.B. Statistik, Informatik und naturwissenschaftliche Forschung, Parameter sind entscheidend für die Etablierung von Normen und Standards, die die Datenanalyse und -interpretation leiten. Ihre richtige Auswahl und Handhabung sind entscheidend, um genaue und relevante Ergebnisse in jeder Studie oder jedem Projekt zu erhalten.... para optimizar el rendimiento de los algoritmos, Ich habe unten die wichtigsten Parameter für das Tuning erwähnt:
- n_Schätzer: Kontrollieren Sie die Anzahl der schwachen Schüler.
- Lernrate:CKontrollieren Sie den Beitrag schwacher Schüler in der endgültigen Kombination. Es gibt einen Kompromiss zwischen Lernrate Ja n_Schätzer.
- base_estimaters: Hilft bei der Angabe verschiedener Algorithmen für maschinelles Lernen.
Sie können auch grundlegende Schülerparameter anpassen, um ihre Leistung zu optimieren.
Impulsalgorithmus: Steigung erhöhen
En el aumento de SteigungGradient ist ein Begriff, der in verschiedenen Bereichen verwendet wird, wie Mathematik und Informatik, um eine kontinuierliche Variation von Werten zu beschreiben. In Mathematik, bezieht sich auf die Änderungsrate einer Funktion, während des Studiums im Grafikdesign, Gilt für den Farbübergang. Dieses Konzept ist unerlässlich, um Phänomene wie die Optimierung von Algorithmen und die visuelle Darstellung von Daten zu verstehen, ermöglicht eine bessere Interpretation und Analyse in..., viele Modelle nacheinander trainieren. Cada nuevo modelo minimiza gradualmente la Verlust-FunktionDie Verlustfunktion ist ein grundlegendes Werkzeug des maschinellen Lernens, das die Diskrepanz zwischen Modellvorhersagen und tatsächlichen Werten quantifiziert. Ziel ist es, den Trainingsprozess zu steuern, indem dieser Unterschied minimiert wird, Dadurch kann das Modell effektiver lernen. Es gibt verschiedene Arten von Verlustfunktionen, wie z. B. mittlerer quadratischer Fehler und Kreuzentropie, jeder für unterschiedliche Aufgaben geeignet und... (y = ax + B + e, e erfordert besondere Aufmerksamkeit, da es sich um einen Fehlerterm handelt) des gesamten Systems mit Gradientenabstieg Methode. El procedimiento de aprendizaje se ajustó consecutivamente a nuevos modelos para proporcionar una estimación más precisa de la VariableIn Statistik und Mathematik, ein "Variable" ist ein Symbol, das einen Wert darstellt, der sich ändern oder variieren kann. Es gibt verschiedene Arten von Variablen, und qualitativ, die nicht-numerische Eigenschaften beschreiben, und quantitative, numerische Größen darstellen. Variablen sind grundlegend in Experimenten und Studien, da sie die Analyse von Beziehungen und Mustern zwischen verschiedenen Elementen ermöglichen, das Verständnis komplexer Phänomene zu erleichtern.... de respuesta.
Die Hauptidee hinter diesem Algorithmus besteht darin, neue Basisstudenten zu bilden, die mit dem negativen Gradienten der Verlustfunktion zum Maximum korreliert werden können, mit dem ganzen Set verbunden. Sie können auf den Artikel verweisen „Lerne den Gradientenerhöhungsalgorithmus“ um dieses Konzept anhand eines Beispiels zu verstehen.
In der Python-Sklearn-Bibliothek, usamos Gradient Tree Boosting oder GBRT. Es ist eine Verallgemeinerung des Impulses auf beliebige differenzierbare Verlustfunktionen. Kann sowohl für Regressions- als auch für Klassifikationsprobleme verwendet werden.
Python-Code
von sklearn.ensemble import GradientBoostingClassifier #Zur Klassifizierung von sklearn.ensemble import GradientBoostingRegressor #Für Regression
clf = GradientBoostingClassifier(n_Schätzer=100, Lernrate=1.0, maximale Tiefe=1) clf.fit(X_Zug, y_train)
- n_Schätzer: Kontrollieren Sie die Anzahl der schwachen Schüler.
- Lernrate:CKontrollieren Sie den Beitrag schwacher Schüler in der endgültigen Kombination. Es gibt einen Kompromiss zwischen Lernrate Ja n_Schätzer.
- Maximale Tiefe: maximale Tiefe einzelner Regressionsschätzer. Maximale Tiefe begrenzt die Anzahl der Knoten im Baum. Passen Sie diesen Parameter für die beste Leistung an; der beste Wert hängt vom Zusammenspiel der Eingangsvariablen ab.
Sie können die Verlustfunktion für eine bessere Leistung anpassen.
Schlussbemerkung
In diesem Artikel, Wir analysieren die Dynamik, eine der Ensemble-Modellierungsmethoden zur Verbesserung der Vorhersagekraft. Hier, Wir haben die Wissenschaft hinter dem Impuls und seine zwei Arten diskutiert: AdaBoost und Gradient Boost. Wir studieren auch ihre jeweiligen Python-Codes.
In meinem nächsten Artikel, Ich werde über eine andere Art von Boost-Algorithmen sprechen, die heute ein Geheimtipp für den Gewinn von „XGBoost“-Data-Science-Wettbewerben ist.
Findest du diesen Artikel hilfreich? Teile deine Meinung / Gedanken im Kommentarbereich unten.





