Einführung
Der Mensch gehört zu den kreativsten Spezies auf diesem Planeten. Von jeher, Kunst hat verschiedene Formen angenommen, von paläolithischen Höhlenmalereien bis hin zu moderner Kunst. Zum Beispiel, die Höhlenmalereien von Bhimbetka gaben viele Informationen über das Leben der Menschen damals. Die Entstehung der bildenden Kunst reicht bis in die Steinzeit zurück.
Jetzt, als Teil der vierten Generation der Revolution, der Kunst und Kreativität in verschiedenen Bereichen und Formen erlebt hat, hier kommen uns verschiedene Tools und Programmiersprachen zu Hilfe, um komplexe Geschäftsprobleme mit der Kunst der Visualisierung zu lösen.
Heutige Unternehmen verwenden verschiedene Visualisierungstechniken, um Daten zu verstehen und Erkenntnisse daraus zu gewinnen, um datengesteuerte Geschäftsentscheidungen zu treffen.. Heute gibt es viele Visualisierungstools wie Tableau, Power BI, Hingucker, Qlik Sense und viele mehr. Zu diesem Thema, Wir werden verschiedene Arten von Grafiken mit Python behandeln.
Der Bedarf an Datenvisualisierung
Daten machen mehr Sinn und sind leicht verständlich, wenn sie in einem einfachen, visualisierten Format präsentiert werden, da es für das menschliche Auge schwierig ist, das Muster zu entziffern, Trend und Saisonalität aus Rohdaten. Deswegen, Daten werden visualisiert, um zu verstehen, wie sich verschiedene Parameter verhalten.
Verschiedene Arten von Diagrammen und ihre Verwendung.
1. Balken- und Säulendiagramme
Es ist eines der einfachsten Diagramme, um zu verstehen, wie unser quantitatives Feld in verschiedenen Kategorien abschneidet. Wird verwendet für Vergleich.
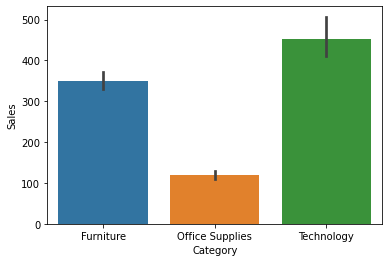
Im Säulendiagramm oben, Wir können sehen, dass der Verkauf von Technologie am höchsten und Büromaterial am niedrigsten ist.
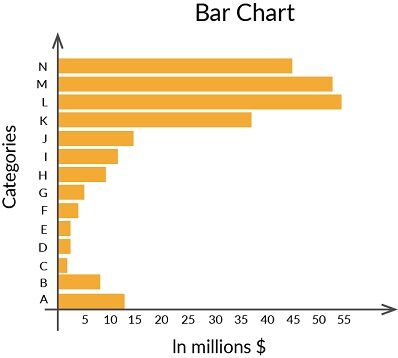
Das oben gezeigte Diagramm ist ein Balkendiagramm, das zeigt, welche L-Kategorien am besten abschneiden.
2. Streudiagramm und Blasendiagramm
Streu- und Blasendiagramme helfen uns zu verstehen, wie es geht Verbreitung im gesamten betrachteten Bereich. Kann verwendet werden, um Muster zu erkennen, das Vorhandensein von Ausreißern und die Beziehung zwischen den beiden Variablen.
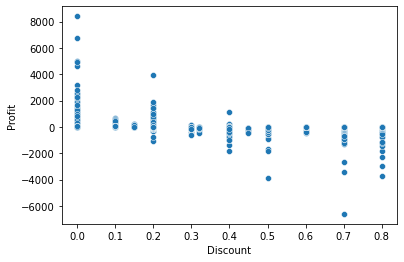
Wir können sehen, dass mit der Erhöhung der Rabatte die Gewinne sinken.
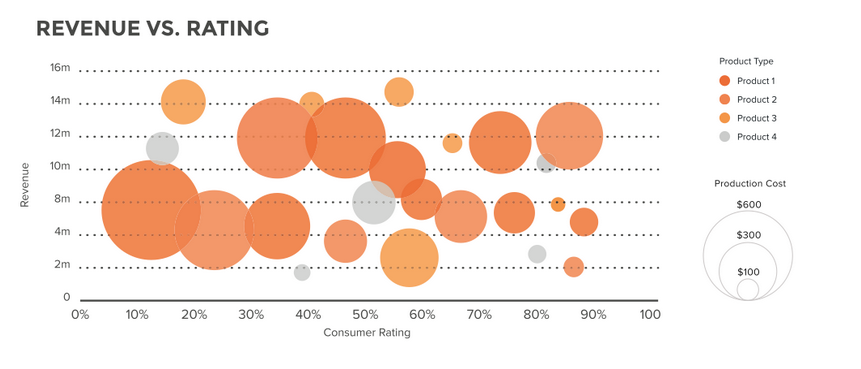
Das oben gezeigte Diagramm ist ein Blasendiagramm.
3. Liniendiagramm
Bevorzugt, wenn zeitabhängige Daten dargestellt werden müssen. Es eignet sich eher für die Analyse der Trend.
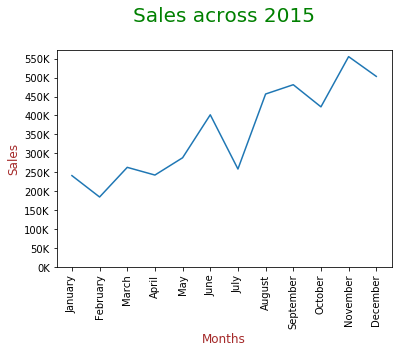
In der Grafik oben, Wir können sehen, dass die Verkäufe im Laufe der Monate steigen, aber im Juli gibt es einen plötzlichen Rückgang und die Verkäufe sind im November am höchsten.
4. Histogramm
Ein Histogramm ist ein Häufigkeitsdiagramm, das die Häufigkeit des Vorkommens eines Eintrags in einem Datensatz aufzeichnet.. Es ist nützlich, wenn Sie die Verteilung einer Serie.
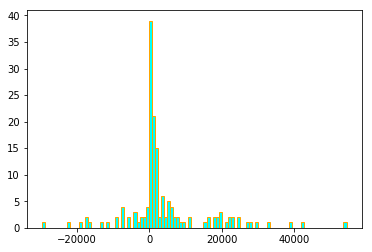
5. Box-Plot
Boxplots eignen sich gut zum Zusammenfassen Verbreitung Große Daten. Sie verwenden das Perzentil, um den Datenbereich zu unterteilen. Dies hilft uns, den Datenpunkt zu verstehen, der unter oder über einem ausgewählten Datenpunkt liegt. Es hilft uns dabei Ausreißer identifizieren in den Daten.
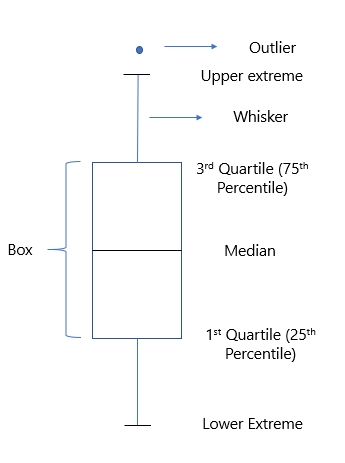
Der Boxplot teilt die kompletten Daten in drei Kategorien ein
* Medianwert: Teile die Daten in zwei gleiche Hälften
* IQR: liegt zwischen den Perzentilwerten 25 Ja 75.
* Atypische Werte: diese Daten unterscheiden sich erheblich und liegen außerhalb der Schnurrhaare.
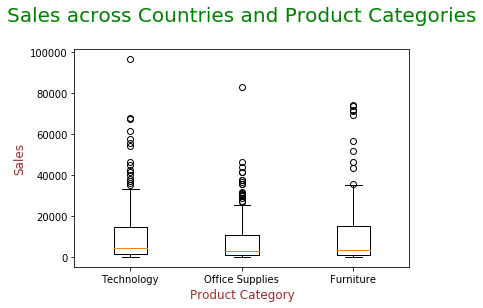
Die Kreise in der obigen Grafik zeigen das Vorhandensein von Ausreißern.
6. Unterpakete
Manchmal ist es besser zu verfolgen verschiedene Grundstücke auf dem gleichen Raster zu verstehen und vergleichen die Daten besser.
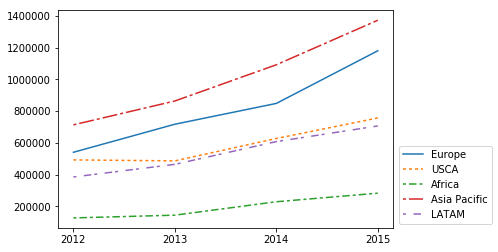
Hier sehen Sie, dass wir im Einzeldiagramm die Umsätze über einen bestimmten Zeitraum in verschiedenen Regionen nachvollziehen konnten.
7. Krapfen, Kreisdiagramme und gestapelte Säulendiagramme
Wenn wir die finden wollen Komposition der oben genannten Datengrafiken ist die beste.
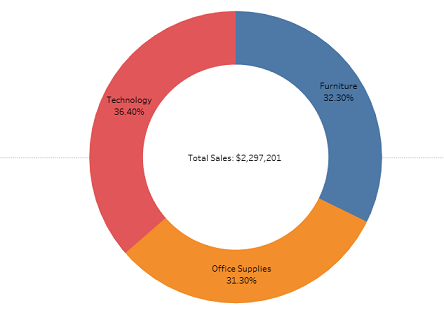
Das obige Donut-Diagramm zeigt die Umsatzzusammensetzung verschiedener Produktkategorien.
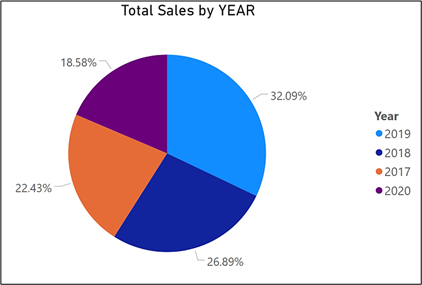
Das obige Tortendiagramm zeigt den Prozentsatz der Verkäufe in verschiedenen Jahren.
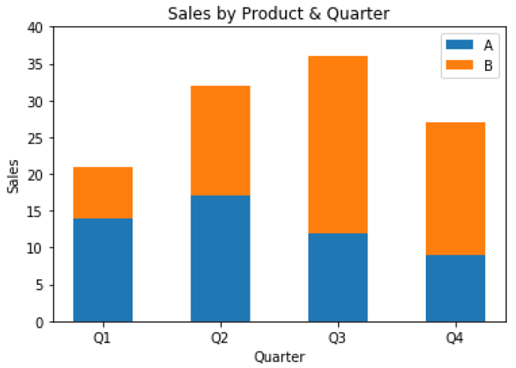
Das Säulendiagramm oben zeigt den Verkauf von zwei Produkten in verschiedenen Quartalen..
8. Heatmaps
Es ist die am meisten bevorzugte Grafik, wenn wir überprüfen möchten, ob es welche gibt. Korrelation zwischen Variablen.
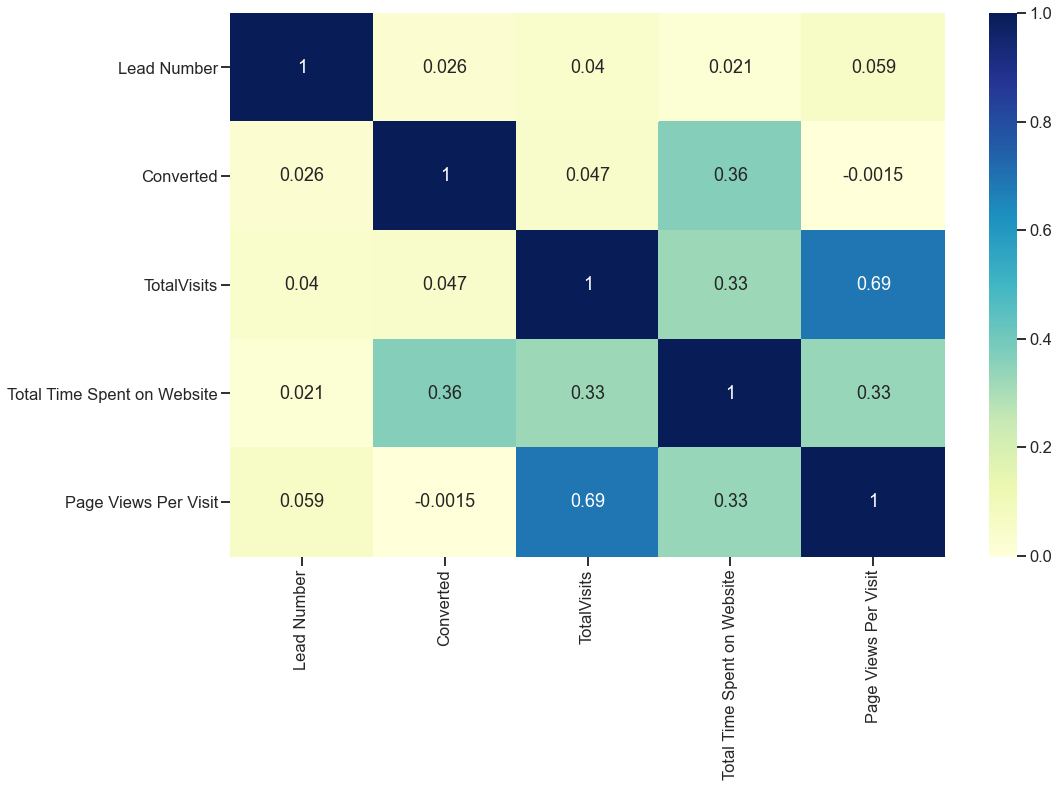
Hier zeigt der positive Wert einen positiven Zusammenhang und der negative Wert einen negativen Zusammenhang. Die Farbe zeigt die Intensität der Korrelation an, je dunkler die farbe, je höher die positive Korrelation und desto heller die Farbe, je größer die negative Korrelation.
Visualisierung mit Python verstehen
Python bietet mehrere Bibliotheken, um die Daten grafisch zu verstehen wie Matplotlib Ja Seaborn etc. Beginnen wir unsere Reise in die Welt der Visualisierung.
Anubhav ist ein produktbasiertes Unternehmen, das verschiedene Arten von Produkten verkauft. Sehen wir uns die Daten an, um Ihre Verkäufe über einen bestimmten Zeitraum zu ermitteln, welche Kategorie / Produktunterkategorie generiert den höchsten Umsatz, das Verhältnis des Gewinns zu einer Erhöhung des Rabatts.
1. Lassen Sie uns zuerst die relevanten Bibliotheken importieren.
numpy als np importieren Pandas als pd importieren import matplotlib.pyplot als plt import seaborn als sns
Importwarnungen
Warnungen.Filterwarnungen ('ignorieren')
2. Der nächste Schritt wäre, den Datensatz zu laden.
sales=pd.read_excel('Maven liefert Raw.xlsx',Skiprows = 3)
sales.head(2)
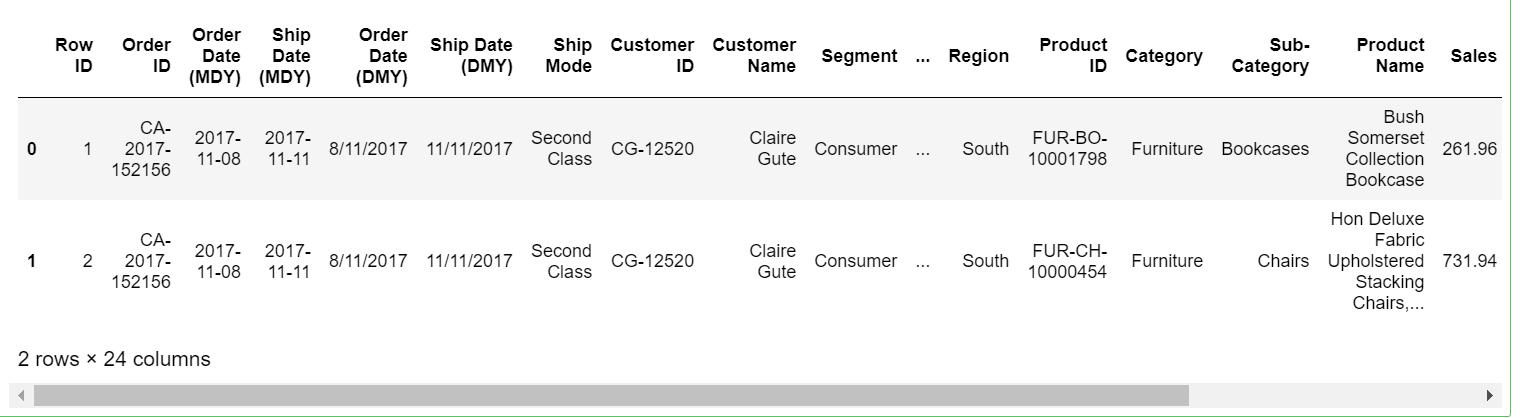
3. Den Datensatz mitnehmen, Lass uns die Daten untersuchen
# Überprüfen Sie die Anzahl der Zeilen und Spalten im Datenrahmen sales.shape
(9994, 24)
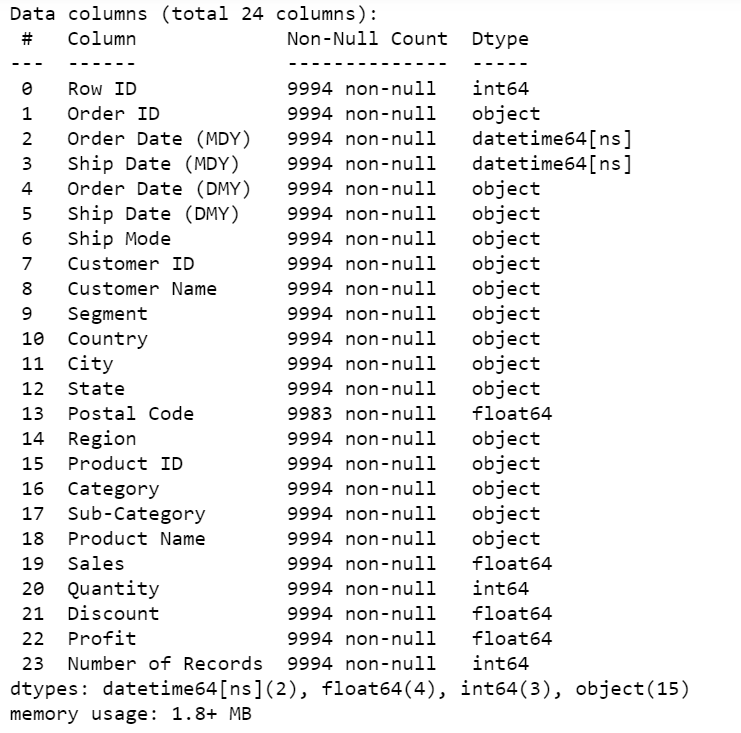
# Überprüfen Sie die spaltenweisen Informationen des Datenrahmens sales.info()
# Überprüfen Sie die Zusammenfassung für die numerischen Spalten sales.describe()
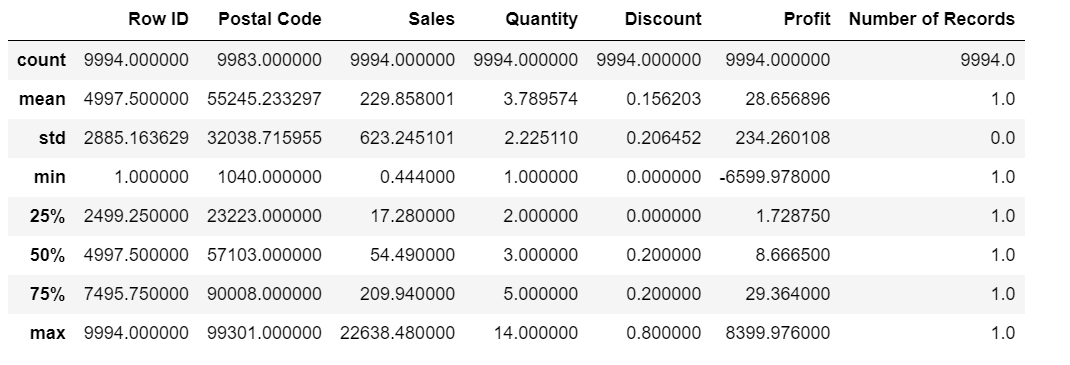
sales.spalten

4. Jetzt, da wir die verfügbaren Daten besser verstehen, lass uns sie visualisieren, um sie besser zu verstehen.
– Zuerst, Kategoriezusammensetzung mit % des Umsatzes erkunden.
sales.groupby(['Kategorie'])['Der Umsatz'].Summe().Handlung(kind='Kuchen',autopct="%1.2F%%")
plt.titel("Umsatz% einer anderen Kategorie")
plt.ylabel(" ")
plt.zeigen();
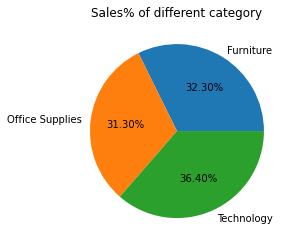
Wir sehen, dass die Technologie im Vergleich zu anderen Kategorien besser funktioniert.
– Es gibt viele Unterkategorien innerhalb der Daten, ermöglicht Ihnen zu sehen, wie die verschiedenen Unterkategorien abschneiden.
plt.figur(Feigengröße=(10,3)) sales.groupby(['Unterkategorie'])['Der Umsatz'].Summe().sort_values(aufsteigend=Falsch).Handlung(kind='bar',Farbe="Meeresgrün") plt.zeigen();
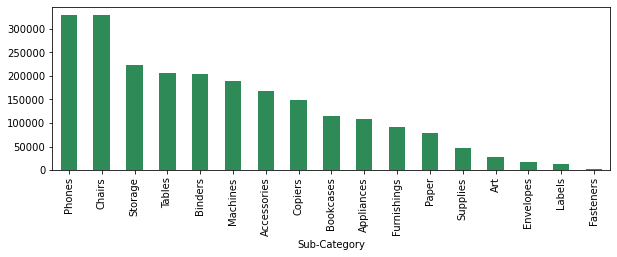
Wir können sehen, dass die Telefonverkäufe am höchsten sind, gefolgt von Stühlen und so weiter.
– Der Verkauf in verschiedenen Regionen wird unterschiedlich sein. Wir werden sehen
sales.groupby(['Region'])['Der Umsatz'].Summe().sort_values(aufsteigend=Falsch).Handlung(kind='bar',Farbe="Meeresgrün") plt.zeigen();
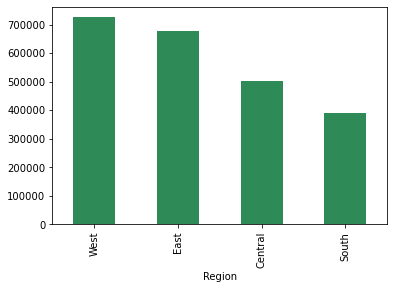
Die Verkäufe in der Westregion sind hoch und die Südregion ist die niedrigste.
– Schauen wir uns nun an, wie die Regionen in Bezug auf die Gewinne abschneiden.
sales.groupby(['Region'])['Profitieren'].Summe().sort_values(aufsteigend=Falsch).Handlung(kind='bar',Farbe="Meeresgrün") plt.zeigen();
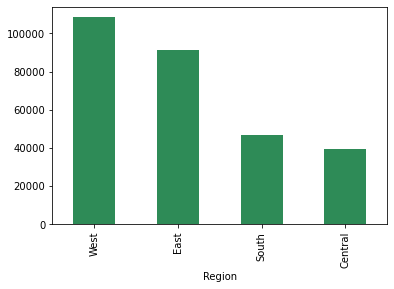
Die umsatzschwächste südliche Region schneidet besser ab als die zentrale Region.
– Heatmaps geben uns ein besseres Verständnis dafür, wie verschiedene Variablen miteinander korrelieren.
plt.figur(Feigengröße = (10, 5)) sns.heatmap(sales.corr(),annot=Wahr,cmap="Sommer") plt.zeigen()
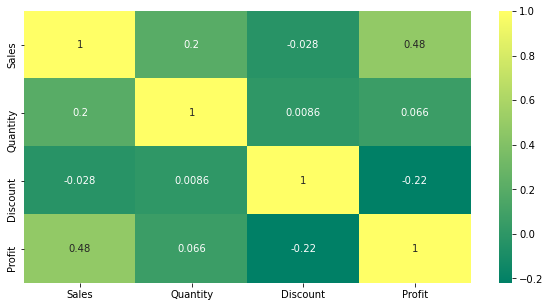
Rabatte sind eindeutig negativ mit dem Ergebnis korreliert.
– Lassen Sie uns herausfinden, wie der Gewinn durch erhöhte Rabatte beeinflusst wird.
sns.streudiagramm(x = 'Rabatt', y='Gewinn', Daten = Umsatz ,Farbe="Meeresgrün") plt.zeigen;
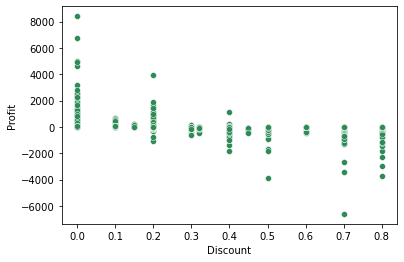
Wir können sehen, dass mit der Erhöhung des Rabatts auch die Einnahmen sinken.
– Der Verkauf ist nicht konstant, erhöhen oder verringern basierend auf verschiedenen Faktoren. Mal sehen, wie sich die Verkäufe in den verschiedenen Monaten entwickeln.
sales.groupby(['Monat'])['Der Umsatz'].Summe().Handlung(kind='line',Farbe="Meeresgrün")
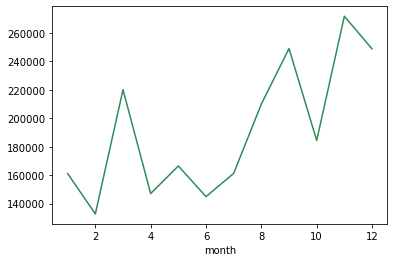
Wie bereits erwähnt, zeigt ein Muster mit den höchsten Verkäufen im Monat November und den niedrigsten Verkäufen im Monat Februar.
– Es ist nicht notwendig, dass auch bei hohen Umsätzen, Die Einnahmen werden ein ähnliches Muster aufweisen. Mal sehen, wie sich die Einnahmen im Laufe der Zeit ändern. Dies kann auf den Verkauf von reduzierten Produkten zurückzuführen sein, wie im Streudiagramm zu sehen.
sales.groupby(['Monat'])['Profitieren'].Summe().Handlung(kind='line',Farbe="Meeresgrün")
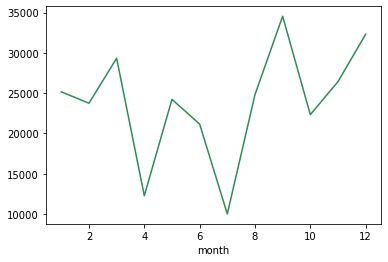
Wir können sehen, dass die Vorteile im September hoch und im Juli niedriger sind.
– Der Umsatz kann im Laufe des Jahres ein steigendes oder fallendes Muster aufweisen.
sales.groupby(['Jahr'])['Der Umsatz'].Summe().Handlung(kind='line',Farbe="Meeresgrün") plt.xticks([2015,2016,2017,2018]) plt.zeigen()
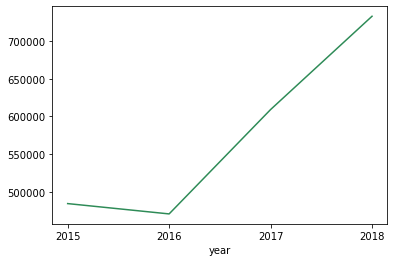
Wir sehen, dass der Umsatz im Jahr rückläufig ist 2016 wie es in all den Jahren wächst.
Aus einem Datensatz, Wir konnten verstehen, dass Telefone den Großteil des Umsatzes generierten und dass die Region West den höchsten Umsatz und Gewinn beisteuerte. Über eine gewisse Zeitspanne, Umsatz gestiegen, aber mit der Erhöhung des Rabatts, das Ergebnis zeigte einen rückläufigen Trend. Wir haben gesehen, dass es bestimmte Monate gab, in denen höhere Umsätze und Gewinne verzeichnet wurden.
Deswegen, Wir können sagen, dass die Visualisierung viel spricht, Sie werden immer eine Geschichte zu erzählen haben, die Unternehmen hilft, datengesteuerte Entscheidungen zu treffen.
Fazit
In diesem Artikel, Wir haben über verschiedene Arten von Diagrammen und deren Verwendung gesprochen. Wir beschäftigen uns mit einem Datensatz, um zu verstehen, wie man Python-Bibliotheken verwendet, um die Daten zu visualisieren und sie zu verstehen. Deswegen, Das können wir durch Visualisierung sagen, Es ist einfach, ein verstecktes Muster oder einen Trend in den Daten zu entschlüsseln. Mit einigen Beispielen, wir haben gesehen, dass die Grafiken beim Vergleich helfen und, das wichtigste, sie sind leicht zu verstehen.
Abschließende Anmerkungen
Danke fürs Lesen!!!
Ich hoffe, Ihnen hat die Lektüre des Artikels gefallen und Sie haben Ihr Wissen über verschiedene Arten von Diagrammen und deren Verwendung erweitert..
Wenn ich nichts erwähnt habe oder wenn du deine Gedanken teilen möchtest, Fühlen Sie sich frei, unten im Kommentarbereich zu kommentieren.
Über den Autor
Sruthi ER
Ich bin ein Data Science-Enthusiast mit Interesse an Datenanalyse und Visualisierung, und ich strebe derzeit eine IIIT-Bangalore Data Science Postgraduate-Zertifizierung an. Ich komme aus einer Karriere im Bauingenieurwesen mit 4 langjährige Erfahrung in der Baubranche.
Zögern Sie nicht, mich unter zu kontaktieren Linkedin
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





