Dieser Artikel wurde im Rahmen der Data Science Blogathon
GitHub ist eine der beliebtesten Plattformen für Quellcodeverwaltung und Versionskontrolle. Es ist auch eine der größten Social-Media-Sites für Programmierer. Softwareentwickler nutzen es, um Recruitern und Einstellungsmanagern ihre Fähigkeiten zu präsentieren. Beim Parsen von Repositorys auf GitHub, können wir wertvolle Informationen wie das Nutzerverhalten erhalten, Was macht ein Repository beliebt oder welche Technologien sind heute bei Entwicklern im Trend?, und vieles mehr.
Den vollständigen Code, der im Artikel verwendet wird, finden Sie hier.
Ich habe benutzt das ‘GitHub-Repositorys 2020’ Kaggle-Datensatz, da es neuer ist.
Implementierung
gehen git Dies begann mit dem Importieren der erforderlichen Bibliotheken und dem Einlesen der Eingabedaten,
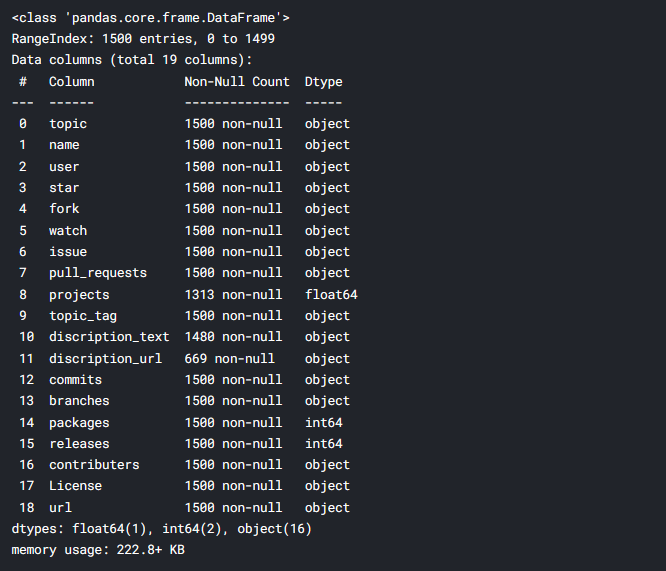
Der Datensatz enthält 19 Säulen, von denen ich gewählt habe 11 Spalten basierend auf den gängigsten GitHub-Terminologien und solchen, die für den Kontext dieser Diskussion relevant sind. Sie können sehen, dass sich in den Spaltennamen Tippfehler befinden, Ich habe sie der Übersichtlichkeit halber umbenannt.
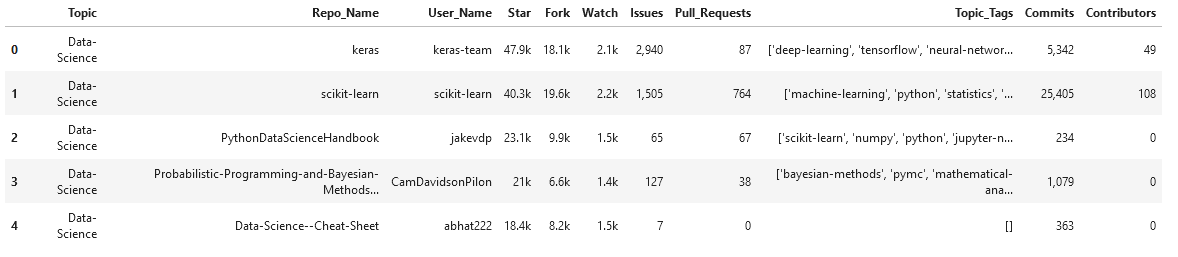
Eine kurze Zusammenfassung über die Spalten der Daten,
- Thema – Ein Tag, das das Repository-Feld oder die Domäne beschreibt.
- Repo_Name – Repository-Name (Kurzname des Repositorys)
- Nutzername – Name des Repository-Eigentümers
- Stern – Anzahl der Sterne, die ein Repository erhalten hat
- Gabel – Wie oft ein Repository gegabelt wurde
- Aussehen – Anzahl der Benutzer, die das Repository anzeigen
- Fragen – Anzahl offener Probleme
- Pull_Requests – Insgesamt generierte Pull-Requests
- Thema_Tags – Liste der Themen-Tags, die vom Benutzer zu diesem Repository hinzugefügt wurden
- Kompromisse – Gesamtzahl der getätigten Bestätigungen
- Mitarbeiter – Anzahl der Personen, die zum Repository beitragen
Finde heraus wie Stern, Gabel, Ja Aussehen die Spalten enthalten 'Kansas Tausende bezeichnen, Also lass sie uns in Vielfache von umwandeln 1000. Was ist mehr, Ersetzen der ‘,’(Kommas) des Fragen Ja Kompromisse Säulen.
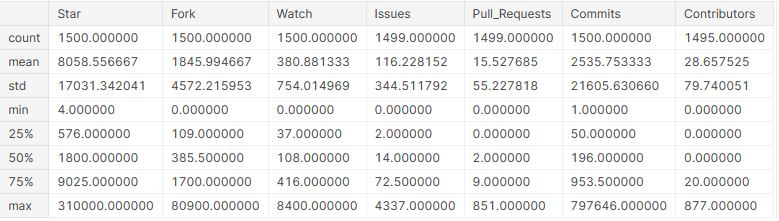
Jetzt, da die Spalten numerisch sind, wir können grundlegende statistische Informationen von ihnen erhalten.
# grundlegende statistische Details zu den Spalten anzeigen github_df.describe()
1. Analyse der wichtigsten Repositories nach ihrer Popularität
Was macht ein GitHub-Repository beliebt?? Diese Frage kann beantwortet werden mit 3 Metriken: Stern, Uhr und Gabel.
- Stern: wenn ein Benutzer Ihr Repository mag oder etwas Wertschätzung zeigen möchte, markiert es mit einem Stern.
- Betrachten: wenn ein Benutzer über alle Aktivitäten in einem Repository benachrichtigt werden möchte, sieht es.
- Gabel: wenn ein Benutzer eine Kopie des Repositorys möchte oder einen Beitrag leisten möchte, die Gabel.
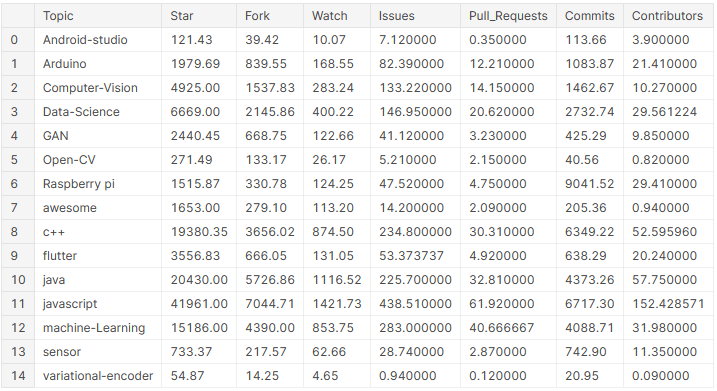
# Erstellen Sie einen Datenrahmen mit Durchschnittswerten der Spalten über alle Themen
pop_mean_df = github_df.groupby('Thema').bedeuten().reset_index()
pop_mean_df
1.1 Sternanalyse
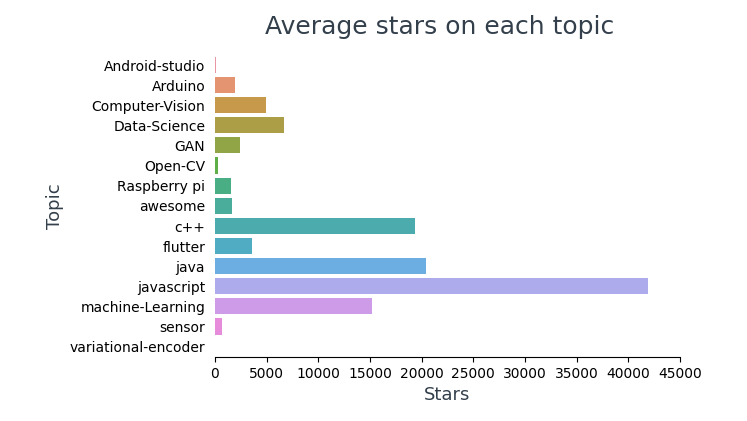
Zeigen Sie die durchschnittliche Anzahl von Sternen in jedem Thema an,
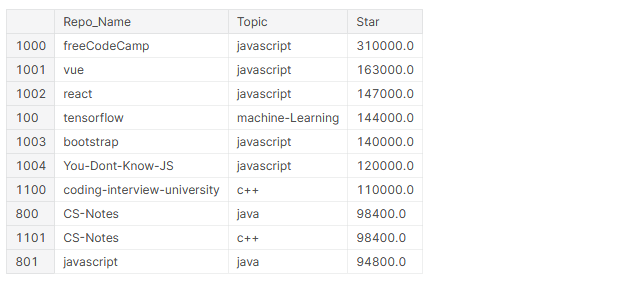
# oben 10 Repos mit den meisten Sternen github_df.nlargest(n=10, Spalten="Stern")[['Repo_Name','Thema','Stern']]
# Schneller Tipp: '33[1m' druckt eine Zeichenfolge in Fettdruck und '33[0m druckt es normal zurück.
drucken('Das Repository mit den meisten Sternchen ist {}{}{} im thema {}{}{} mit {}{}{} Sterne'.
Format('33[1m',github_df.iloc[github_df['Stern'].idxmax ()]['Repo_Name'], '33[0m',
'33[1m',github_df.iloc[github_df['Stern'].idxmax ()]['Thema'], '33[0m',
'33[1m',github_df.iloc[github_df['Stern'].idxmax ()]['Stern'], '33[0m'))

Ganz oben 10 Repositories mit den meisten Sternchen, 4 sind Rahmen (Gesehen, Reagieren, TensorFlow, Stiefelriemen) und 6 davon handelt es sich um JavaScript.
1.2 Analyse der Uhr
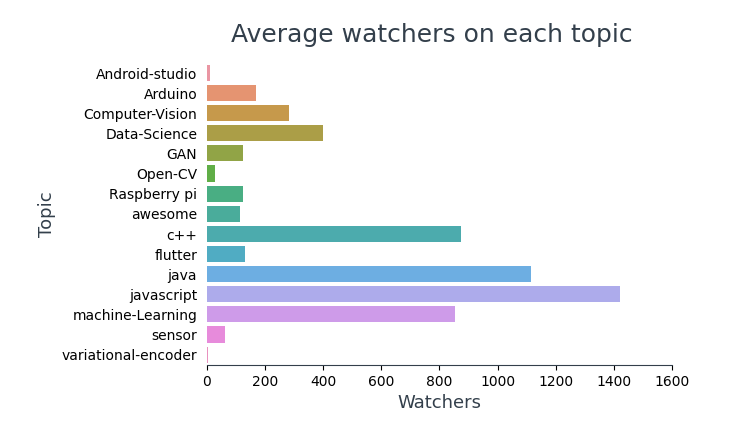
Visualisierung der durchschnittlichen Zuschauerzahl für jedes Thema,
Notiz: Der Code für die obige Grafik ist mit Ausnahme der Spaltennamen derselbe wie die "Durchschnittssterne zu jedem Thema".. Ich habe nicht dasselbe hinzugefügt, um Redundanz zu vermeiden.
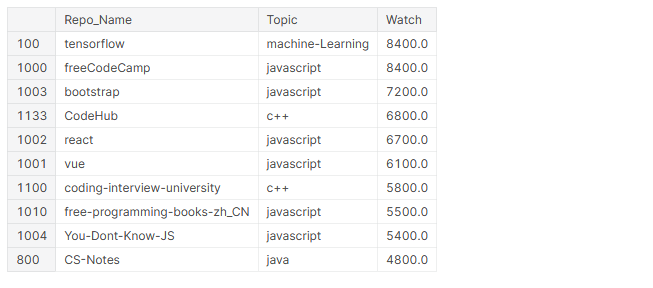
# oben 10 meistgesehene Repos github_df.nlargest(n=10, Spalten="Betrachten")[['Repo_Name','Thema','Betrachten']]
drucken('Das meistgesehene Repository ist {}{}{} im thema {}{}'.
Format('33[1m',github_df.iloc[github_df['Betrachten'].idxmax()]['Repo_Name'],
'33[0m','33[1m',github_df.iloc[github_df['Betrachten'].idxmax()]['Thema']))

Im 10 meistgesehene Repositorys, 4 Sohn-Frameworks (TensorFlow, Stiefelriemen, Reagieren, Gesehen), 6 sind über JavaScript und 5 davon enthalten Lerninhalte für Programmierer.
1.3 Gabelanalyse
Zeigen Sie die durchschnittliche Anzahl von Forks in jedem Thema an,
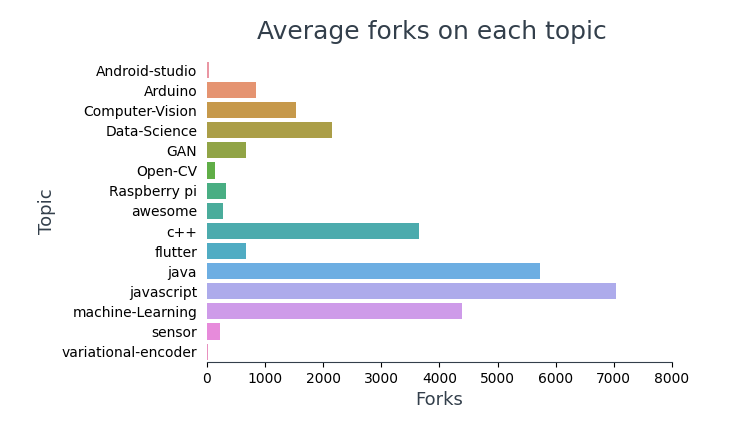
# oben 10 die meisten gegabelten Repos github_df.nlargest(n=10, Spalten="Gabel")[['Repo_Name','Thema','Gabel']]
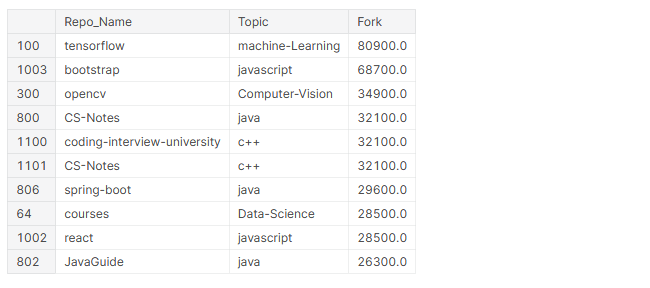
drucken('Das meist gegabelte Repository ist {}{}{} im thema {}{}'.
Format('33[1m',github_df.iloc[github_df['Gabel'].idxmax()]['Repo_Name'],'33[0m',
'33[1m',github_df.iloc[github_df['Gabel'].idxmax()]['Thema']))

Oben drauf 10 mehr gespaltene Repositorys, 4 Sohn-Frameworks (TensorFlow, Bootstrap, Frühlingsstiefel, reagieren) Ja 5 davon enthalten Lerninhalte für Programmierer.
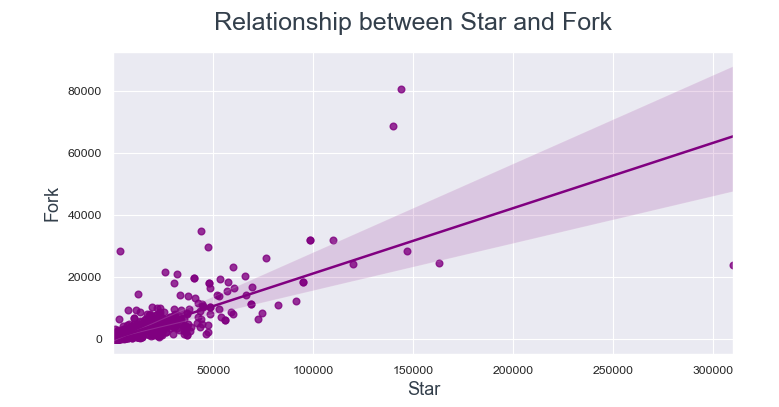
1.4 Star-Beziehung, Haarnadel und schau
Häufig, Benutzer forken ein Repository, wenn sie dazu beitragen möchten. Dann, Lassen Sie uns die Beziehung zwischen Sterngabel und Uhrgabel untersuchen.
# Bildgröße und dpi . einstellen
Feige, ax = plt.subplots(Feigengröße=(8,4), dpi=100)
# Seaborn-Thema für Hintergrundraster einstellen
sns.set_theme('Papier')
# Plotten Sie die Daten
sns.regplot(data=github_df, x='Beobachten', y='Gabel', Farbe="Violett");
# Legen Sie Beschriftungen und Titel für die X- und Y-Achse fest
ax.set_xlabel('Betrachten', Schriftgröße=13, Farbe="#333F4B")
ax.set_ylabel('Gabel', Schriftgröße=13, Farbe="#333F4B")
fig.Untertitel('Beziehung zwischen Wache und Gabel',Schriftgröße=18, Farbe="#333F4B")
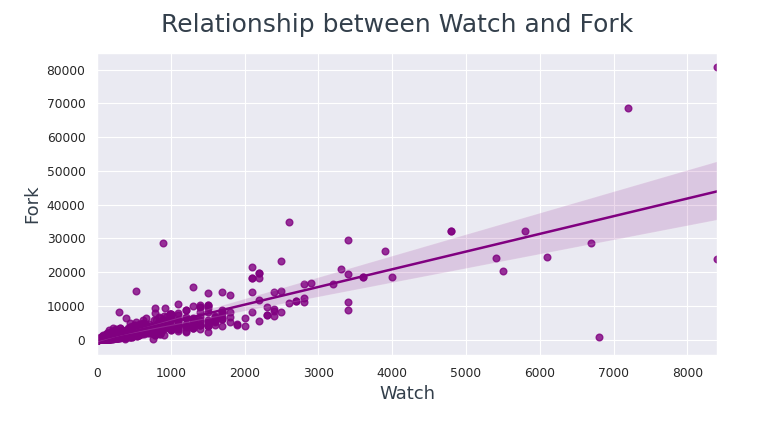
Die Datenpunkte liegen viel näher an der Regressionslinie zwischen Watch und Fork im Vergleich zu Star und Fork.
Daraus können wir schließen, wenn ein Benutzer ein Repository anzeigt, eher gabel es.
2. Analyse von Benutzern mit mehr Repositorys
Werfen wir einen Blick auf die Benutzer mit den beliebtesten Repositorys.
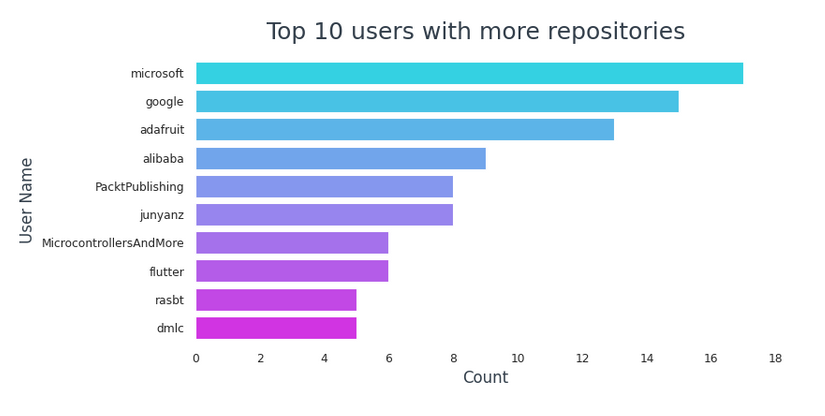
Oben drauf 10 Benutzer mit mehr Repositorys,
- Microsoft führt die Liste an mit 17 Repositorys.
- Google macht weiter mit 15 Repositorys.
- 6 davon sind Unternehmen oder Eigentum eines Unternehmens (Microsoft, Google, Adafrucht, Alibaba, PacktPublishing, flattern)
- 3 sie sind einzelne Benutzer (junyanz, rasbt, MikrocontrollerAndMore)
3. Beitragsaktivitäten in Repositorien verstehen
GitHub ist berühmt für seinen Beitragsgraph.
Dieses Diagramm ist eine Aufzeichnung aller Beiträge, die ein Benutzer gemacht hat. Immer wenn ein Benutzer eine Bestätigung macht, ein Problem eröffnen oder eine Pull-Anfrage vorschlagen, gilt als Beitrag. Es gibt vier Spalten, die sich auf Beiträge in unserem Datensatz beziehen, Probleme, Pull_Requests, Verpflichtet, Mitarbeiter. Mal sehen, ob es eine echte Beziehung zwischen ihnen gibt.
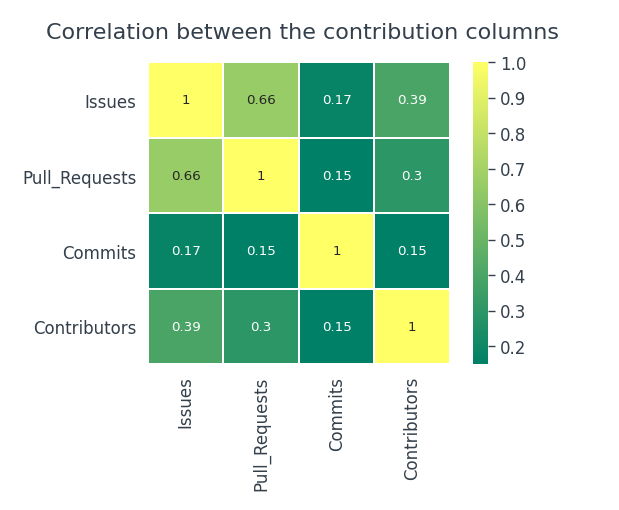
Die Anzahl der Bestätigungen hängt von keinem Problem ab, Pull-Requests oder Mitwirkende. Es besteht eine moderate positive Beziehung zwischen Issues und Pull-Requests.
Erkunden wir die 100 beliebtesten Repositories und mal sehen, ob es dasselbe ist,
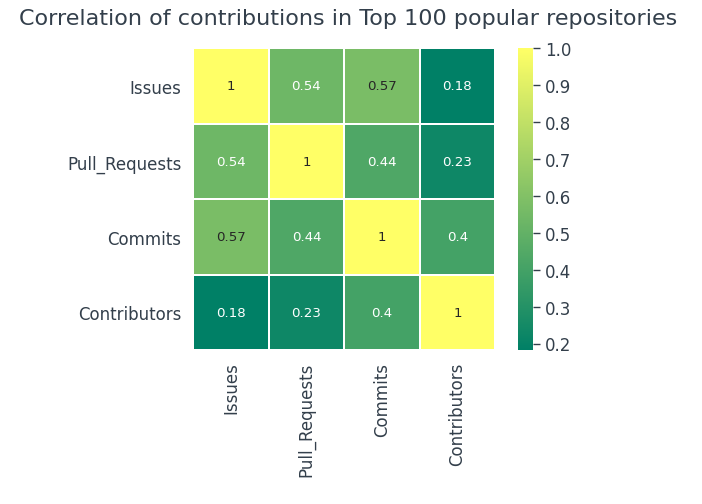
Es ist fast das gleiche in 100 beliebtere Repositorys als im allgemeinen Datensatz.
Lassen Sie uns Benutzer mit mehr Repositorys finden,
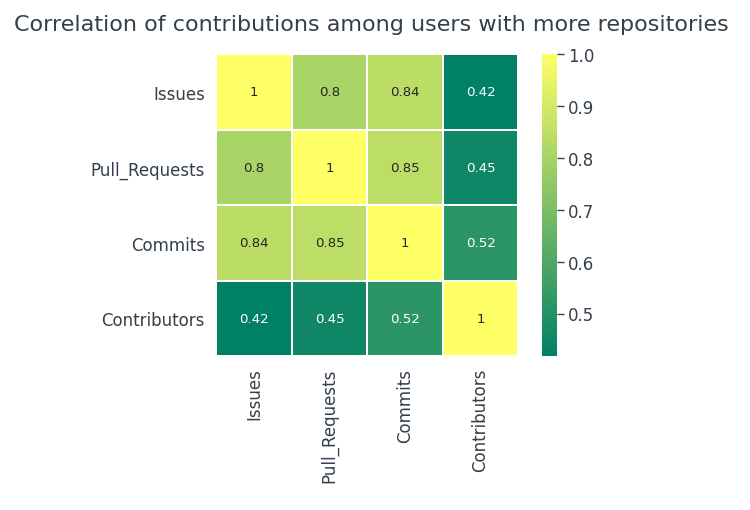
Überraschenderweise, Benutzer mit mehr Repositorys sind in der Regel aktiver. Es gibt eine ziemlich starke positive Korrelation zwischen
- Anfragen bestätigen und extrahieren
- Kompromisse und Probleme
- Pull-Requests und Probleme
Zu den Beiträgen,
- Es besteht kein wirklicher Zusammenhang zwischen den Beitragsaktivitäten im Gesamtdatensatz.
- Es besteht auch keine Korrelation zwischen den Beiträgen in der 100 beliebtesten Repositorys.
- Wenn Benutzer dazu neigen, mehr Repositorys zu haben, dann sind die Möglichkeiten der Beiträge viel höher.
4. Themen-Tag-Analyse
Die Spalte topic_tags besteht aus Listen. So finden Sie beliebte Tags, Konvertieren Sie die gesamte Spalte in eine Liste von Listen und zählen Sie das Vorkommen jedes Labels. Damit, Wir können einige der beliebtesten Themen-Tags visualisieren und sehen, welche Themen am häufigsten getaggt werden.
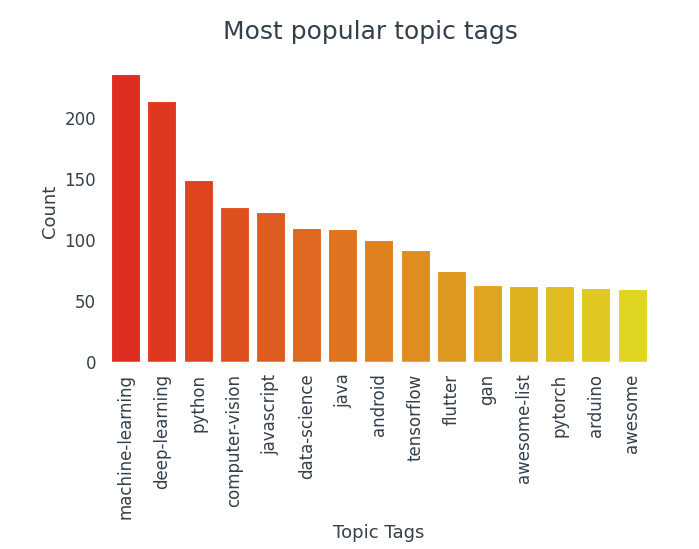
Des 15 die beliebtesten Tags, 10 gehören zur Welt der Data Science.
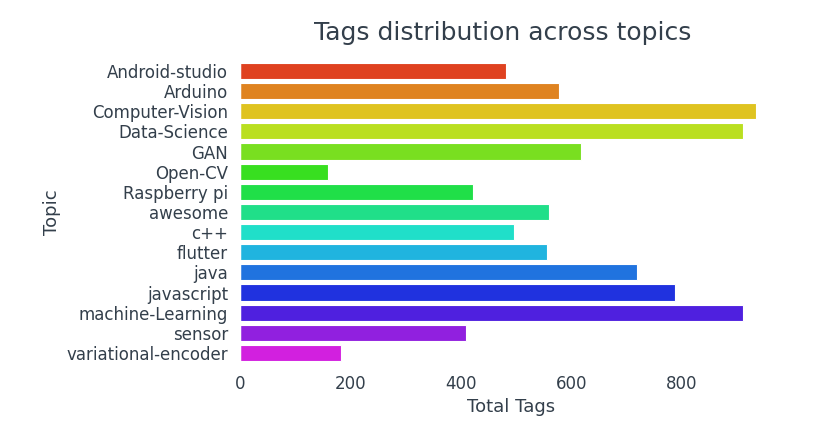
Repositories mit Computer Vision-Themen, Data Science und Machine Learning werden tendenziell stärker beschriftet.
Lassen Sie uns mit einer Wortwolke von topic_tags schließen,
Inferenz:
- Zwischen den 10 bekanntesten Repositorien, gesehen und gegabelt, 4 Sohn-Frameworks.
- Tensorflow ist das am meisten beobachtete gegabelte Repository.
- Wenn ein Benutzer ein Repository ansieht, eher gabel es.
- Microsoft und Google sind in der Regel Benutzer mit beliebteren Repositorys.
- Oben drauf 10 Benutzer mit den beliebtesten Repositorys, 6 davon sind Unternehmen.
- Es besteht kein wirklicher Zusammenhang zwischen Beitragsaktivitäten (Probleme, Pull-Requests, Bestätigungen).
- Die am häufigsten verwendeten Tags sind Machine Learning, Tiefes Lernen, Python, Computer Vision, JavaScript.
- Repositories mit Computer Vision-Themen, Data Science und maschinelles Lernen haben mehr Labels.
Wenn wir Daten von vor einem Jahrzehnt analysiert hätten, diese Trends wären ganz anders gewesen. Es ist, als ob Data Science in den letzten Jahren ein enormes Wachstum erlebt hätte!!
Danke fürs Zuschauen hier! ich würde mich gerne verbinden LinkedIn
Lass es mich im Kommentarbereich wissen, wenn du Bedenken hast, Kommentar oder Kritik. Einen schönen Tag noch!
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





