Einführung
Alle Modelle sind falsch, aber einige sind nützlich – George Box
Die Regressionsanalyse markiert den ersten Schritt in der prädiktiven Modellierung. Zweifellos, es ist ganz einfach zu implementieren. Weder seine Syntax noch seine Parameter verursachen irgendeine Art von Verwirrung. Aber, nur eine Codezeile ausführen, löst den Zweck nicht. Nicht nur auf die R²- oder MSE-Werte schauen. Regression sagt noch viel mehr!!
Ein R, Regressionsanalyse liefert 4 Grafiken mit plot(model_name) Funktion. Jeder der Plots liefert wichtige Informationen bzw. eine interessante Geschichte zu den Daten. Leider, viele der Anfänger können die Informationen nicht entziffern oder kümmern sich nicht darum, was diese Plots sagen. Sobald Sie diese Diagramme verstanden haben, Sie können Ihr Regressionsmodell deutlich verbessern.
Um das Modell zu verbessern, Sie müssen auch Regressionsannahmen und Möglichkeiten zu ihrer Korrektur verstehen, wenn sie verletzt werden.
In diesem Artikel, Ich habe die wichtigen Regressionsannahmen und Grafiken erklärt (mit Fixes und Lösungen) um Ihnen zu helfen, das Konzept der Regression genauer zu verstehen. Wie oben erwähnt, Mit diesem Wissen können Sie Ihre Modelle drastisch verbessern.
Notiz: Um diese Diagramme zu verstehen, muss die Grundlagen der Regressionsanalyse kennen. Wenn du ganz neu dabei bist, du kannst hier anfangen. Später, weiter mit diesem Artikel.

Regressionsannahmen
Regression ist ein parametrischer Ansatz. 'Parametrisch’ bedeutet, dass Sie Annahmen über die Daten für Analysezwecke treffen. Aufgrund seiner parametrischen Seite, Regression ist restriktiver Natur. Funktioniert nicht gut mit Datensätzen, die nicht Ihren Annahmen entsprechen. Deswegen, für eine erfolgreiche Regressionsanalyse, Es ist wichtig, diese Annahmen zu validieren.
Dann, Wie würden Sie überprüfen? (würde bestätigen) wenn ein Datensatz allen Regressionsannahmen folgt? Überprüfen Sie es mit Regressionsgraphen (unten erklärt) zusammen mit einigen statistischen Beweisen.
Schauen wir uns die wichtigen Annahmen in der Regressionsanalyse an:
- Zwischen der abhängigen Variablen muss ein linearer und additiver Zusammenhang bestehen (Antworten) und die unabhängige Variable (vorhersagen). Eine lineare Beziehung legt nahe, dass eine Änderung der Antwort Y aufgrund einer Änderung von X¹ um eine Einheit konstant ist, unabhängig vom Wert von X¹. Eine additive Beziehung legt nahe, dass die Wirkung von X¹ auf Y unabhängig von anderen Variablen ist.
- Es sollte keine Korrelation zwischen den Resttermen bestehen (Error). Das Fehlen dieses Phänomens wird als Autokorrelation bezeichnet..
- Die unabhängigen Variablen dürfen nicht korreliert sein. Das Fehlen dieses Phänomens wird als Multikollinearität bezeichnet..
- Die Fehlerterme müssen eine konstante Varianz haben. Dieses Phänomen wird als Homoskedastizität bezeichnet.. Das Vorhandensein nicht konstanter Varianz bezieht sich auf Heteroskedastizität.
- Die Fehlerterme sollten normal verteilt sein.
Was ist, wenn diese Annahmen verletzt werden??
Lassen Sie uns spezifische Annahmen analysieren und mehr über Ihre Ergebnisse erfahren (wenn sie vergewaltigt werden):
1. Linear und additiv: Wenn Sie ein lineares Modell an einen nicht-linearen, nicht-additiven Datensatz anpassen, der Regressionsalgorithmus würde den Trend nicht mathematisch erfassen, was zu einem ineffizienten Modell führen würde. Was ist mehr, Dies führt zu falschen Vorhersagen in einem unsichtbaren Datensatz.
Wie zu überprüfen: Suchen Sie nach Diagrammen für Restwerte und angepasste Werte (unten erklärt). Was ist mehr, kann Polynomterme enthalten (x, X², X³) in Ihrem Modell, um den nichtlinearen Effekt zu erfassen.
2. Autokorrelation: Das Vorhandensein einer Korrelation in Bezug auf Fehler reduziert die Genauigkeit des Modells drastisch. Dies tritt normalerweise in Zeitreihenmodellen auf, bei denen der nächste Zeitpunkt vom vorherigen Zeitpunkt abhängt.. Wenn die Fehlerterme korreliert sind, geschätzte Standardfehler neigen dazu, den wahren Standardfehler zu unterschätzen.
Wenn das passiert, macht Konfidenzintervalle und Vorhersageintervalle enger. Ein engeres Konfidenzintervall bedeutet, dass ein Konfidenzintervall von 95% hätte eine Wahrscheinlichkeit kleiner als 0,95 den reellen Wert der Koeffizienten enthalten. Lassen Sie uns enge Vorhersageintervalle anhand eines Beispiels verstehen:
Zum Beispiel, der Kleinste-Quadrate-Koeffizient von X¹ ist 15.02 und sein Standardfehler ist 2.08 (keine Autokorrelation). Aber in Gegenwart von Autokorrelation, der Standardfehler reduziert sich auf 1,20. Infolge, das Vorhersageintervall wird auf reduziert (13.82, 16.22) aus (12.94, 17.10).
Was ist mehr, geringere Standardfehler würden die zugehörigen p-Werte niedriger machen als die tatsächlichen. Dies führt dazu, dass wir fälschlicherweise schlussfolgern, dass ein Parameter statistisch signifikant ist..
Wie zu überprüfen: Sehen Sie sich die Durbin-Watson-Statistik an (DW). Muss dazwischen sein 0 Ja 4. Wenn DW = 2, bedeutet keine Autokorrelation, 0 <DW <2 impliziert positive Autokorrelation, während 2 <DW <4 zeigt negative Autokorrelation an. Was ist mehr, Sie können das Residuendiagramm gegen die Zeit anzeigen und nach dem saisonalen oder korrelierten Muster in den Residuen suchen.
3. Multikollinearität: Dieses Phänomen tritt auf, wenn festgestellt wird, dass die unabhängigen Variablen eine mäßige oder hohe Korrelation aufweisen. In einem Modell mit korrelierten Variablen, Es wird eine schwierige Aufgabe, die wahre Beziehung eines Prädiktors zu einer Antwortvariablen herauszufinden. Mit anderen Worten, schwer herauszufinden, welche Variable tatsächlich zur Vorhersage der Antwortvariablen beiträgt.
Ein weiterer Punkt, mit Vorhandensein korrelierter Prädiktoren, Standardfehler nehmen tendenziell zu. Ja, mit großen Standardfehlern, das Konfidenzintervall wird breiter, führt zu weniger genauen Schätzungen der Steigungsparameter.
Was ist mehr, wenn Prädiktoren korreliert sind, der geschätzte Regressionskoeffizient einer korrelierten Variablen hängt davon ab, welche anderen Prädiktoren im Modell verfügbar sind. Wenn das passiert, Sie werden am Ende zu der falschen Schlussfolgerung gelangen, dass eine Variable einen starken Einfluss hat / schwach zur Zielgröße. Angenommen, selbst wenn Sie eine korrelierte Variable aus dem Modell entfernen, Ihre geschätzten Regressionskoeffizienten würden sich ändern. Das ist nicht gut!
Wie zu überprüfen: Sie können das Streudiagramm verwenden, um den Korrelationseffekt zwischen Variablen zu visualisieren. Was ist mehr, Sie können auch den VIF-Faktor verwenden. Der Wert von VIF = 10 impliziert ernsthafte Multikollinearität. Über alles, eine Korrelationstabelle sollte auch den Zweck erfüllen.
4. Heteroskedastizität: Das Vorhandensein einer nicht konstanten Varianz in den Fehlertermen führt zu Heteroskedastizität. Allgemein, nicht konstante Varianz entsteht bei Vorliegen von Ausreißern oder extremen Leverage-Werten. Diese Werte scheinen zu viel Gewicht zu haben, sie beeinflussen also überproportional die Leistung des Modells. Wenn dieses Phänomen auftritt, das Konfidenzintervall für Out-of-Sample-Vorhersagen ist tendenziell unrealistisch breit oder eng.
Wie zu überprüfen: Sie können das Diagramm der Residuen vs. angepasst sehen. Bei Heteroskedastizität, der Graph zeigt ein trichterförmiges Muster an (im nächsten Abschnitt gezeigt). Was ist mehr, Sie können den Breusch-Pagan-Test verwenden / Kochen – Weisberg oder Whites allgemeiner Test, um dieses Phänomen zu erkennen.
5. Normalverteilung der Fehlerterme: Wenn die Fehlerterme nicht normal verteilt sind, Konfidenzintervalle können zu breit oder zu eng werden. Sobald das Konfidenzintervall instabil wird, die Schätzung von Koeffizienten basierend auf der Minimierung der kleinsten Quadrate ist schwierig. Das Vorhandensein einer abnormalen Verteilung deutet darauf hin, dass es einige ungewöhnliche Datenpunkte gibt, die genau untersucht werden müssen, um ein besseres Modell zu erstellen..
Wie zu überprüfen: Sie können das QQ-Diagramm sehen (unten gezeigt). Sie können auch statistische Tests auf Normalität wie den Kolmogorov-Smirnov-Test durchführen., der Shapiro-Wilk-Test.
Interpretation von Regressionsgraphen
Bis zu diesem Punkt, wir haben wichtige Annahmen und Methoden zur Regression kennengelernt, wenn diese Annahmen verletzt werden.
Aber das ist nicht das Ende. Jetzt, Sie sollten die Lösungen auch kennen, um die Verletzung dieser Annahmen zu beheben. In diesem Abschnitt, Ich habe das erklärt 4 Regressionsgraphen zusammen mit Methoden zur Überwindung der Einschränkungen der Annahmen.
1. Restwerte vs. angepasste Werte
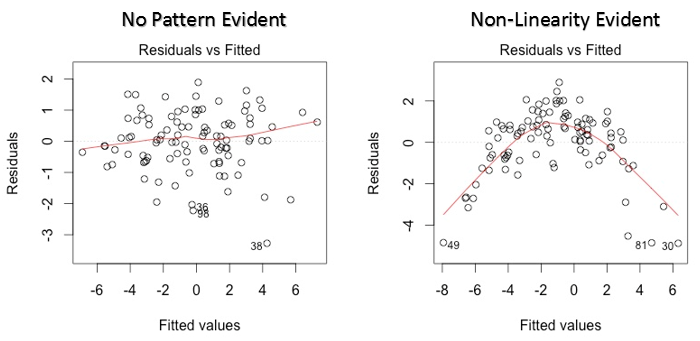
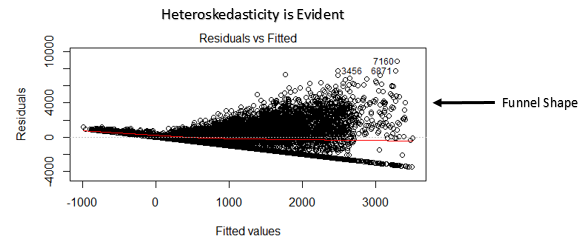
Dieses Streudiagramm zeigt die Verteilung der Residuen (Fehler) im Vergleich zu angepassten Werten (vorhergesagte Werte). Es ist eine der wichtigsten Handlungen, die jeder lernen sollte. Enthüllt verschiedene nützliche Erkenntnisse, inklusive Ausreißer. Die Ausreißer in diesem Diagramm sind mit ihrer Beobachtungsnummer gekennzeichnet, wodurch sie leicht zu erkennen sind.
Es gibt zwei wichtige Dinge, die Sie lernen müssen:
- Wenn es ein Muster gibt (könnte sein, eine parabolische Form) in dieser Grafik, Betrachten Sie es als Zeichen der Nichtlinearität in den Daten. Das bedeutet, dass das Modell keine nichtlinearen Effekte erfasst.
- Wenn die Form eines Trichters in der Grafik erkennbar ist, Betrachten Sie es als Zeichen einer nicht konstanten Varianz, nämlich, Heteroskedastizität.
Lösung: Um das Problem der Nichtlinearität zu überwinden, Sie können eine nichtlineare Transformation von Prädiktoren wie log . durchführen (x), √X oder X² transformieren die abhängige Variable. Heteroskedastizität überwinden, Eine Möglichkeit besteht darin, die Antwortvariable in log . umzuwandeln (Ja) das √Y. Was ist mehr, Sie können die Methode der gewichteten kleinsten Quadrate verwenden, um Heteroskedastizität zu adressieren.
2. Normales QQ-Diagramm
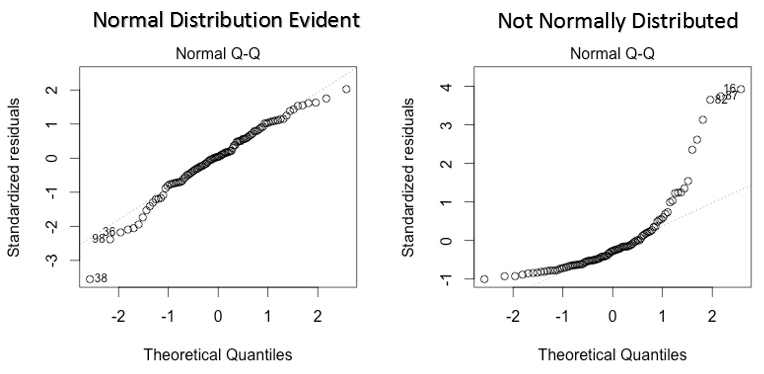
Dieses qq- oder Quantil-Quantil ist ein Streudiagramm, das uns hilft, die Annahme der Normalverteilung in einem Datensatz zu validieren. Anhand dieses Graphen können wir ableiten, ob die Daten aus einer Normalverteilung stammen. Wenn ja, der Graph würde eine ziemlich gerade Linie zeigen. Es gibt keine Normalität bei Fehlern mit Abweichung in einer geraden Linie.
Wenn Sie sich fragen, was ein 'Quantil' ist, hier ist eine einfache definition: Stellen Sie sich Quantile als Punkte in Ihren Daten vor, unter die ein bestimmter Anteil der Daten fällt. Das Quantil wird oft als Perzentile bezeichnet. Zum Beispiel: wenn wir sagen, dass der Perzentilwert 50 es ist 120, bedeutet, dass die Hälfte der Daten darunter liegt 120.
Lösung: Wenn die Fehler nicht normal verteilt sind, die nichtlineare Transformation der Variablen (Reaktion oder Prädiktoren) kann eine Verbesserung des Modells bringen.
3. Standortdiagramm skalieren
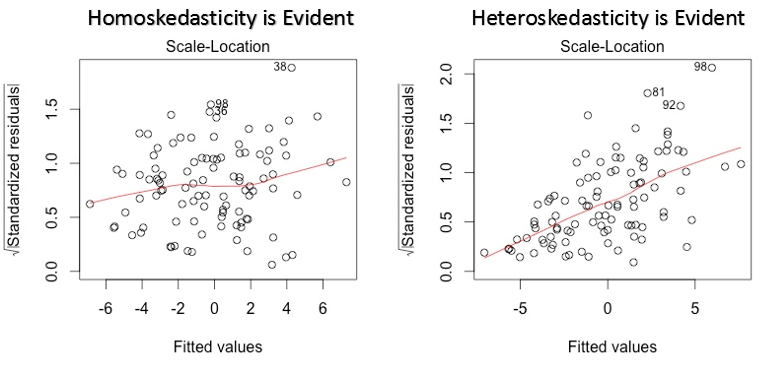
Dieser Graph wird auch verwendet, um Homoskedastizität zu erkennen (Annahme gleicher Varianz). Zeigt an, wie die Residuen über den Bereich der Prädiktoren verteilt sind.. Es ähnelt dem Diagramm Restwert vs. bereinigte, außer dass standardisierte Restwerte verwendet werden. Im Idealfall, es sollte kein erkennbares Muster in der Handlung geben. Dies würde bedeuten, dass die Fehler normalverteilt sind. Aber, falls die Grafik ein erkennbares Muster zeigt (wahrscheinlich eine trichterform), würde eine nicht-normale Fehlerverteilung implizieren.
Lösung: Folgen Sie der Lösung für Heteroskedastizität im Graphen 1.
4. Residual vs. Leverage-Diagramm
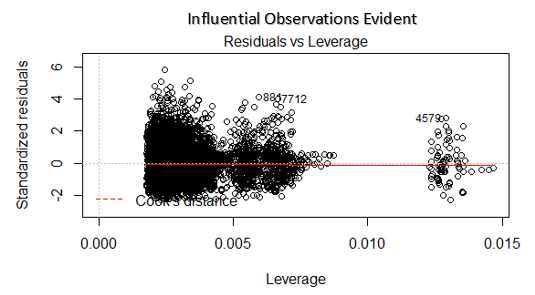
Auch bekannt als Cooks Distanzdiagramm. Cooks Distanz versucht, die Punkte zu identifizieren, die mehr Einfluss haben als andere Punkte. Solche Einflusspunkte haben tendenziell einen erheblichen Einfluss auf die Regressionsgeraden.. Mit anderen Worten, Das Hinzufügen oder Entfernen solcher Punkte aus dem Modell kann die Modellstatistik vollständig ändern.
Aber, Können diese einflussreichen Beobachtungen als Ausreißer behandelt werden?? Diese Frage lässt sich erst nach Blick auf die Daten beantworten. Deswegen, in dieser Grafik, große Werte, die durch den Kochabstand gekennzeichnet sind, erfordern möglicherweise weitere Untersuchungen.
Lösung: Zur Beeinflussung von Beobachtungen, die nichts anderes als Ausreißer sind, ja nicht viele, Sie können diese Zeilen löschen. Alternative, Sie können die Beobachtung von Ausreißern mit dem maximalen Wert in den Daten reduzieren oder diese Werte als fehlende Werte behandeln.
Fallstudie: Wie ich mein Regressionsmodell mit logarithmischer Transformation verbessert habe
Abschließende Anmerkungen
Sie können die wahre Stärke der Regressionsanalyse nutzen, indem Sie die oben beschriebenen Lösungen anwenden.. Die Implementierung dieser Korrekturen in R ist ziemlich einfach. Wenn Sie eine bestimmte Lösung in R . wissen möchten, du kannst einen kommentar hinterlassen, Ich helfe Ihnen gerne bei den Antworten..
Der Zweck dieses Artikels bestand darin, Ihnen zu helfen, die zugrunde liegenden Einsichten und Perspektiven der Annahmen und Regressionsdiagramme zu gewinnen.. Diesen Weg, Sie haben mehr Kontrolle über Ihre Analyse und können die Analyse Ihren Bedürfnissen anpassen.
Fanden Sie diesen Artikel nützlich?? Haben Sie diese Korrekturen verwendet, um die Leistung des Modells zu verbessern?? Teile deine Erfahrung / Vorschläge in den Kommentaren.





