Einführung
Was ist Datenbereinigung?? Entfernen von Nulldatensätzen, Entfernen unnötiger Spalten, die Behandlung fehlender Werte, Korrektur von unerwünschten Werten oder Ausreißern, Umstrukturierung der Daten, um sie in einem besser lesbaren Format zu bearbeiten, etc., es ist als Datenbereinigung bekannt.

Eines der häufigsten Beispiele für die Datenbereinigung ist die Anwendung in Data Warehouses. Ein Data Warehouse speichert eine Reihe von Daten aus zahlreichen Quellen und optimiert sie für die Analyse, bevor eine Modellanpassung durchgeführt werden kann.
Datenbereinigung ist nicht nur das Entfernen vorhandener Informationen, um neue Informationen hinzuzufügen, aber einen Weg finden, die Genauigkeit eines Datensatzes zu maximieren, ohne notwendigerweise vorhandene Informationen aufzugeben. Unterschiedliche Arten von Daten erfordern unterschiedliche Arten der Bereinigung, aber denken Sie immer daran, dass die richtige Herangehensweise der entscheidende Faktor ist.
Nach dem Bereinigen der Daten, wird mit anderen ähnlichen Datensätzen im System konsistent.. Sehen wir uns die Schritte zum Bereinigen der Daten an;
Null-Datensätze löschen / Duplikate
Wenn in einer bestimmten Zeile eine erhebliche Datenmenge fehlt, Dann wäre es besser, diese Zeile zu löschen, da es unserem Modell keinen Mehrwert verleihen würde. kann den Wert unterstellen; einen geeigneten Ersatz für fehlende Daten bieten. Denken Sie auch daran, doppelte Werte immer zu löschen / redundant Ihres Datensatzes, da sie zu Verzerrungen in Ihrem Modell führen könnten.
Als Beispiel, Betrachten Sie den Schülerdatensatz mit den folgenden Datensätzen.
| Name | Spielstand | Adresse | Höhe | Last |
| EIN | 56 | Gehe zu | 165 | 56 |
| B | 45 | Bombay | 3 | Fünfundsechzig |
| C | 87 | Delhi | 170 | 58 |
| D | ||||
| mich | 99 | Mysore | 167 | 60 |
Wie wir sehen, entspricht es dem Namen des Schülers „D“, die meisten Daten fehlen, deshalb, wir verwerfen diese spezielle Zeile.
student_df.dropna() # lässt Zeilen fallen mit 1 oder mehr Nan-Wert
#Produktion
| Name | Spielstand | Adresse | Höhe | Last |
| EIN | 56 | Gehe zu | 165 | 56 |
| B | 45 | Bombay | 3 | Fünfundsechzig |
| C | 87 | Delhi | 170 | 58 |
| mich | 99 | Mysore | 167 | 60 |
Löschen Sie unnötige Spalten
Wenn wir Daten von Interessenten erhalten, im Allgemeinen ist es riesig. Möglicherweise gibt es einen Datensatz, der unserem Modell möglicherweise keinen Mehrwert verleiht. Es ist besser, diese Daten zu löschen, da dies mit wertvollen Ressourcen wie Speicher und Verarbeitungszeit erledigt wäre.
Als Beispiel, Beobachten der Schülerleistung bei einem Test, das Gewicht oder die Größe der Schüler haben nichts zum Modell beizutragen.
student_df.drop(['Höhe','Last'], Achse = 1,inplace=True) #Drops Height Spalte aus dem Datenrahmen
#Produktion
| Name | Spielstand | Adresse |
| EIN | 56 | Gehe zu |
| B | 45 | Bombay |
| C | 87 | Delhi |
| mich | 99 | Mysore |
Spalten umbenennen
Es ist immer am besten, die Spalten umzubenennen und sie in das lesbarste Format zu formatieren, das sowohl der Datenwissenschaftler als auch das Unternehmen verstehen können.. Als Beispiel, im Schülerdatensatz, Spalte umbenennen „Name“ Was „Sudent_Name“ macht Sinn.
student_df.rename(Spalten={'Name': 'Name des Studenten'}, inplace=Wahr) #benennt die Namensspalte in Student_Name um
#Produktion
| Name des Studenten | Spielstand | Adresse |
| EIN | 56 | Gehe zu |
| B | 45 | Bombay |
| C | 87 | Delhi |
| mich | 99 | Mysore |
Umgang mit fehlenden Werten
Es gibt viele Alternativen, um fehlende Werte in einem Datensatz zu berücksichtigen. Es liegt am Data Scientist und dem vorliegenden Datensatz, die am besten geeignete Methode auszuwählen. Die am häufigsten verwendeten Methoden sind die Imputation des Datensatzes mit Mittelwert, MedianDer Median ist ein statistisches Maß, das den zentralen Wert eines Satzes geordneter Daten darstellt. Um es zu berechnen, Die Daten werden von der niedrigsten zur höchsten sortiert und die Zahl in der Mitte wird identifiziert. Wenn es eine gerade Anzahl von Beobachtungen gibt, Die beiden Kernwerte werden gemittelt. Dieser Indikator ist besonders nützlich bei asymmetrischen Verteilungen, da es nicht von Extremwerten beeinflusst wird.... o moda. Löschen dieser bestimmten Datensätze mit einem oder mehreren fehlenden Werten und, in manchen Fällen, Das Erstellen von Algorithmen für maschinelles Lernen wie lineare Regression und nächster Nachbar K wird auch verwendet, um mit fehlenden Werten umzugehen.
| Name des Studenten | Spielstand | Adresse |
| EIN | 56 | Gehe zu |
| B | 45 | Bombay |
| C | Delhi | |
| mich | 99 | Mysore |
Student_df['col_name'].Fillna((Student_df['col_name'].bedeuten()), inplace=Wahr) # Na-Werte in col_name werden durch Mittelwert ersetzt
#Produktion
| Name des Studenten | Spielstand | Adresse |
| EIN | 96 | Gehe zu |
| B | 45 | Bombay |
| C | 66 | Delhi |
| mich | 99 | Mysore |
Erkennung atypischer Werte
Ausreißer können im Datensatz als Rauschen betrachtet werden. Ausreißer können mehrere Gründe haben, als Dateneingabefehler, Fehlerhandbuch, Fehler experimentell, etc.
Als Beispiel, im folgenden Beispiel, Schülernote „B“ du betrittst 130, was eindeutig nicht richtig ist.
| Name des Studenten | Spielstand | Adresse | Höhe | Last |
| EIN | 56 | Gehe zu | 165 | 56 |
| B | 45 | Bombay | 3 | Fünfundsechzig |
| C | 66 | Delhi | 170 | 58 |
| mich | 99 | Mysore | 167 | 60 |
Das Auftragen der Höhe auf einem Boxplot ergibt das folgende Ergebnis
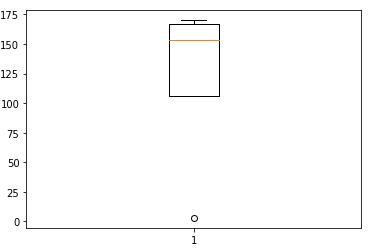
Nicht alle Extremwerte sind Ausreißer, einige können auch zu interessanten Entdeckungen führen, aber das ist ein Thema für einen anderen Tag. Tests wie der Z-Score-Test können verwendet werden, der Boxplot oder das einfache Zeichnen der Daten in der Grafik werden die Ausreißer aufdecken.
Reform / die Daten umstrukturieren
Die meisten Geschäftsdaten, die dem Datenwissenschaftler zur Verfügung gestellt werden, liegen nicht im lesbarsten Format vor. Unsere Aufgabe ist es, die Daten umzuformen und in ein Format zu bringen, das für die Analyse verwendet werden kann.. Als Beispiel, creando una nueva VariableIn Statistik und Mathematik, ein "Variable" ist ein Symbol, das einen Wert darstellt, der sich ändern oder variieren kann. Es gibt verschiedene Arten von Variablen, und qualitativ, die nicht-numerische Eigenschaften beschreiben, und quantitative, numerische Größen darstellen. Variablen sind grundlegend in Experimenten und Studien, da sie die Analyse von Beziehungen und Mustern zwischen verschiedenen Elementen ermöglichen, das Verständnis komplexer Phänomene zu erleichtern.... a partir de las variables existentes o combinando 2 oder mehr Variablen.
Fußnoten
Sicherlich, Es gibt viele Vorteile, mit sauberen Daten zu arbeiten, einige davon sind die verbesserte Genauigkeit der Modelle, bessere Entscheidungsfindung durch Stakeholder, la facilidad de implementación del modelo y el ajuste de ParameterDas "Parameter" sind Variablen oder Kriterien, die zur Definition von, ein Phänomen oder System zu messen oder zu bewerten. In verschiedenen Bereichen wie z.B. Statistik, Informatik und naturwissenschaftliche Forschung, Parameter sind entscheidend für die Etablierung von Normen und Standards, die die Datenanalyse und -interpretation leiten. Ihre richtige Auswahl und Handhabung sind entscheidend, um genaue und relevante Ergebnisse in jeder Studie oder jedem Projekt zu erhalten...., Zeit und Ressourcen sparen, und viele mehr. Denken Sie immer daran, die Daten als ersten und wichtigsten Schritt zu bereinigen, bevor Sie ein Modell anpassen.
Verweise
https://www.geeksforgeeks.org/
Die in diesem Beitrag gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





