Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Apache SparkApache Spark ist eine Open-Source-Datenverarbeitungs-Engine, die die schnelle und effiziente Analyse großer Informationsmengen ermöglicht. Sein Design basiert auf dem Speicher, Dies optimiert die Leistung im Vergleich zu anderen Batch-Verarbeitungstools. Spark wird häufig in Big-Data-Anwendungen verwendet, Maschinelles Lernen und Echtzeitanalysen, Dank seiner Benutzerfreundlichkeit und... es un marco utilizado en entornos de computación en ClusterEin Cluster ist eine Gruppe miteinander verbundener Unternehmen und Organisationen, die im selben Sektor oder geografischen Gebiet tätig sind, und die zusammenarbeiten, um ihre Wettbewerbsfähigkeit zu verbessern. Diese Gruppierungen ermöglichen die gemeinsame Nutzung von Ressourcen, Wissen und Technologien, Förderung von Innovation und Wirtschaftswachstum. Cluster können sich über eine Vielzahl von Branchen erstrecken, Von der Technologie bis zur Landwirtschaft, und sind von grundlegender Bedeutung für die regionale Entwicklung und die Schaffung von Arbeitsplätzen.... para analizar big data. Apache Spark kann in einer verteilten Umgebung auf einer Gruppe von Computern in einem Cluster arbeiten, um große Datenmengen effektiver zu verarbeiten. Diese Open-Source-Spark-Engine unterstützt eine Vielzahl von Programmiersprachen, einschließlich Scala, Java, R und Python.
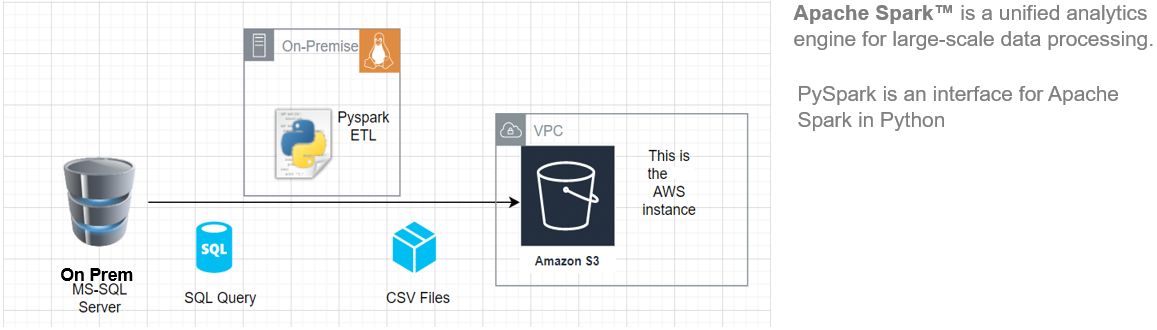
In diesem Artikel, Ich zeige Ihnen, wie Sie mit der Installation von Pyspark auf Ihrem beginnen Ubuntu Maschine und bauen Sie dann eine grundlegende ETL-Pipeline auf, um Übertragungslastdaten von einem Remote-RDBMS-System zu einem AWS S3 Eimer.
Esta arquitectura ETL se puede utilizar para transferir cientos de Gigabytes de datos desde cualquier servidor de DatenbankEine Datenbank ist ein organisierter Satz von Informationen, mit dem Sie, Effizientes Verwalten und Abrufen von Daten. Einsatz in verschiedenen Anwendungen, Von Unternehmenssystemen bis hin zu Online-Plattformen, Datenbanken können relational oder nicht-relational sein. Das richtige Design ist entscheidend für die Optimierung der Leistung und die Gewährleistung der Informationsintegrität, und erleichtert so eine fundierte Entscheidungsfindung in verschiedenen Kontexten.... RDBMS (in diesem Artikel haben wir MS SQL Server verwendet) hat einen Amazon S3-Bucket.
Hauptvorteile der Verwendung von Apache Spark:
- Arbeitslasten ausführen 100 mal schneller als Hadoop
- Java-kompatibel, Scala, Python, R und SQL
Quelle: Dies ist ein Originalbild.
Anforderungen
Anfangen, wir müssen die folgenden voraussetzungen haben:
- Ein System mit Ubuntu 18.04 oder Ubuntu 20.04
- Ein Benutzerkonto mit sudo-Berechtigungen
- Ein AWS-Konto mit Upload-Zugriff auf den S3-Bucket
Vor dem Herunterladen und Konfigurieren von Spark, Sie müssen die erforderlichen Paketabhängigkeiten installieren. Stellen Sie sicher, dass die folgenden Pakete bereits auf Ihrem System konfiguriert sind.
So bestätigen Sie die installierten Abhängigkeiten durch Ausführen dieser Befehle:
Java-Version; git --version; python --version

PySpark installieren
Laden Sie die gewünschte Version von Spark von der offiziellen Apache-Website herunter. Wir werden Spark herunterladen 3.0.3 mit Hadoop 2.7 da es die aktuelle version ist. Dann, Verwenden Sie den Befehl wget und die direkte URL, um das Spark-Paket herunterzuladen.
Ändere dein Arbeitsverzeichnis in / opt / Funke.
cd /opt/spark
sudo wget https://downloads.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz

Extrahieren Sie das gespeicherte Paket mit dem Befehl tar. Sobald der Streuvorgang abgeschlossen ist, die Ausgabe zeigt die Dateien, die aus dem Archiv entpackt wurden.
tar xvf Funke-*
ls -lrt Funke-*

Einrichten der Spark-Umgebung
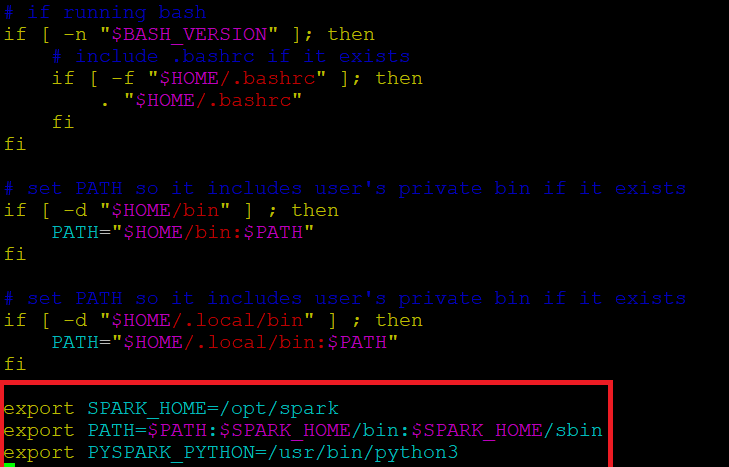
Vor dem Starten eines Spark-Servers, wir müssen einige Umgebungsvariablen setzen. Es gibt einige Spark-Verzeichnisse, die wir zum Standardprofil hinzufügen müssen. Verwenden Sie den vi-Editor oder einen anderen Editor, um diese drei Zeilen zu .profile . hinzuzufügen:
vi ~ / .profil
Fügen Sie diese ein 3 Zeilen am Ende der .profile-Datei.
export SPARK_HOME=/opt/spark export PFAD=$PFAD:$SPARK_HOME/bin:$SPARK_HOME/sbin exportiere PYSPARK_PYTHON=/usr/bin/python3
Speichern Sie die Änderungen und verlassen Sie den Editor. Wenn Sie mit der Bearbeitung der Datei fertig sind, laden die .Profil Datei in der Befehlszeile durch Eingabe von. Alternative, Wir können den Server verlassen und uns wieder anmelden, damit die Änderungen wirksam werden.
Quelle ~/.profile
Start / Spark Master stoppen & Arbeiter
Gehen Sie zum Spark-Installationsverzeichnis / opt / Funke / Funke *. Es hat alle notwendigen Skripte zum Starten / Spark-Dienste stoppen.
Führen Sie diesen Befehl aus, um Spark Master zu starten.
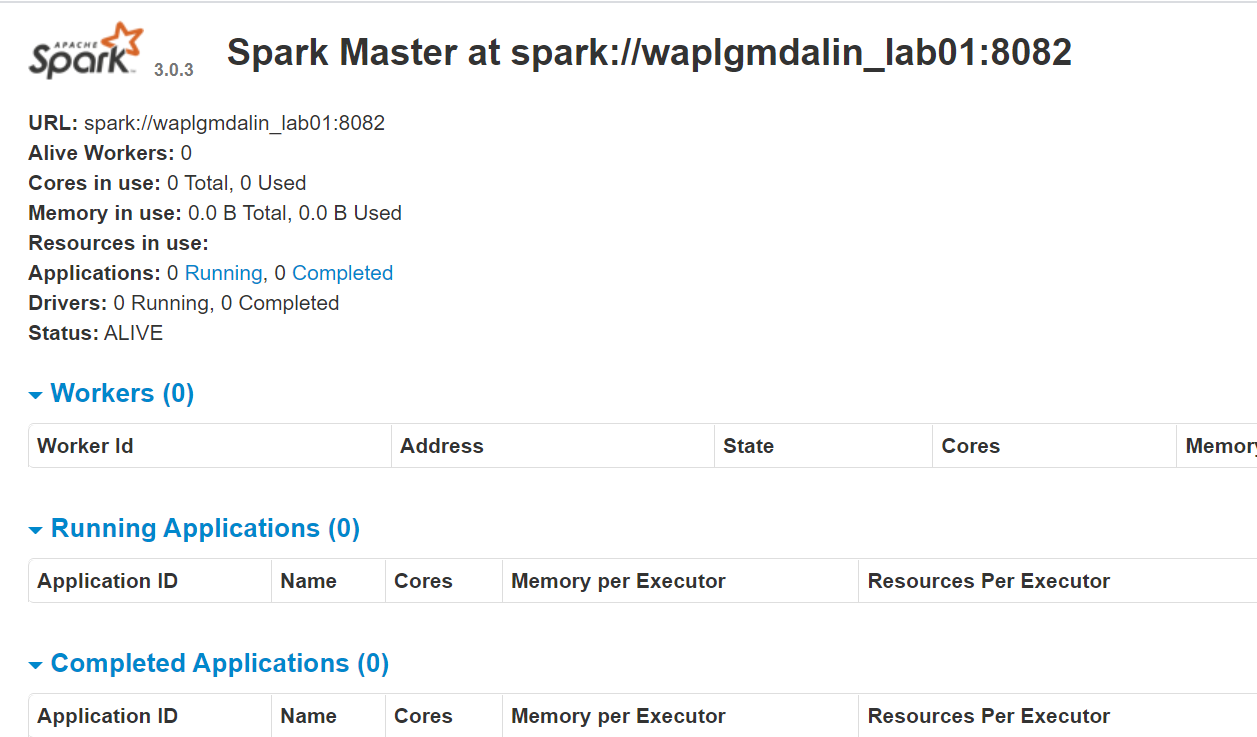
start-master.shSo zeigen Sie die Spark-Weboberfläche an, Öffnen Sie einen Webbrowser und geben Sie die IP-Adresse des lokalen Hosts in den Port ein 8080. (Dies ist der Standardport, den Spark verwendet, wenn Sie ihn ändern müssen, mach es im start-master.sh Skript). Alternative, ersetzen können 127.0.0.1 mit der tatsächlichen Netzwerk-IP-Adresse Ihres Host-Rechners.
http://127.0.0.1:8080/Die Webseite zeigt die Spark-Master-URL, Arbeiterknoten, CPU-Ressourcenauslastung, die Erinnerung, laufende Anwendungen, etc.
Jetzt, Führen Sie diesen Befehl aus, um eine Spark-Worker-Instanz zu starten.
start-slave.sh Funke://0.0.0.0:8082
Ö
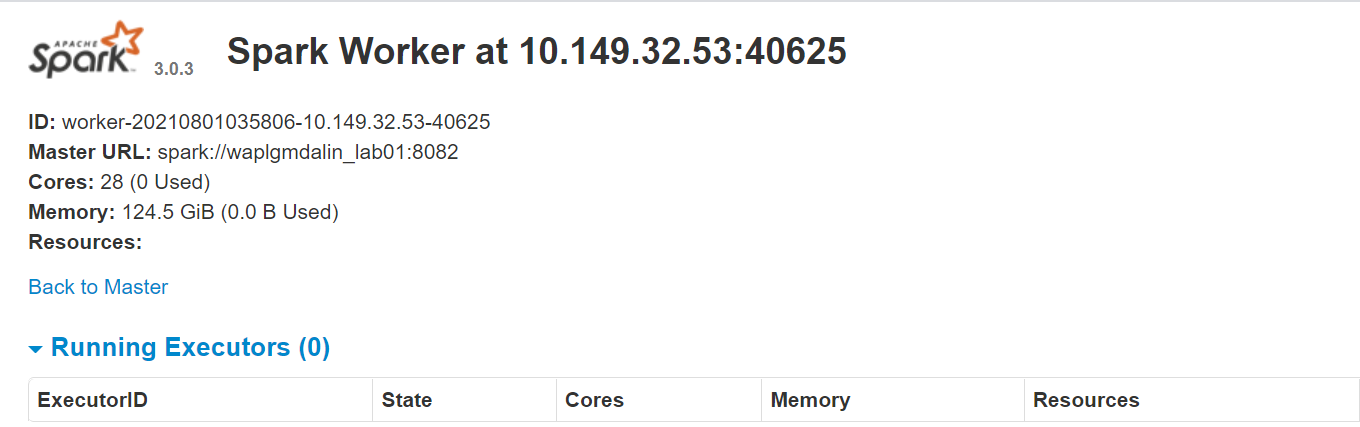
start-slave.sh Funke://waplgmdalin_lab01:8082
Die eigene Website des Arbeitnehmers läuft weiter http://127.0.0.1:8084/ aber es muss mit dem Lehrer verbunden sein. Aus diesem Grund übergeben wir die Spark-Master-URL als Parameter an das Skript start-slave.sh. Um zu bestätigen, ob der Arbeiter richtig mit dem Master verbunden ist, öffne den Link in einem Browser.
Zuweisen von Ressourcen zum Spark-Worker
Standardmäßig, wenn Sie eine Worker-Instanz starten, nutzt alle verfügbaren Kerne auf der Maschine. Aber trotzdem, aus praktischen Gründen, Vielleicht möchten Sie die Anzahl der Kerne und die Menge an RAM begrenzen, die jedem Worker zugewiesen wird.
start-slave.sh Funke://0.0.0.0:8082 -C 4 -m 512M
Hier, wir haben zugewiesen 4 Kerne Ja 512 MB RAM zum Arbeiter. Bestätigen wir dies, indem wir die Worker-Instanz neu starten.
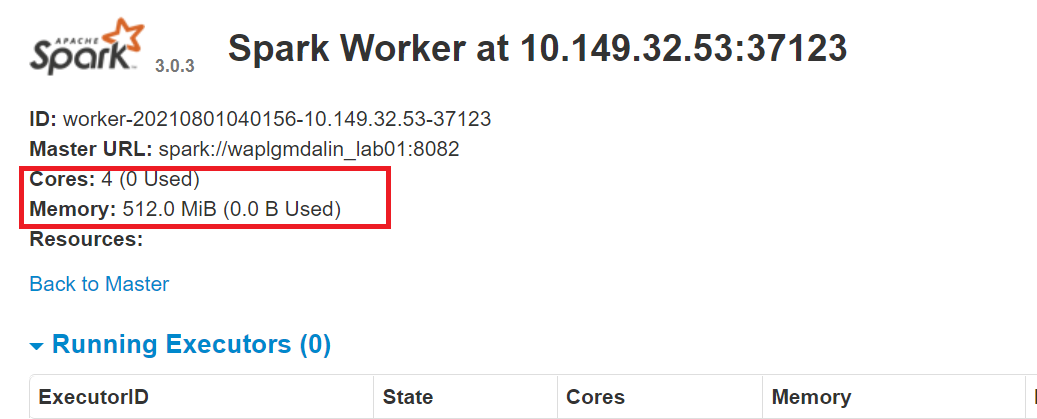
Um den Meister zu stoppen Instanz gestartet, indem das obige Skript ausgeführt wird, Lauf:
stop-master.shUm einen laufenden Arbeiter zu stoppen Prozess, gib diesen Befehl ein:
stop-slave.shMS SQL-Verbindung konfigurieren
In diesem PySpark-ETL, Wir werden eine Verbindung zu einer MS SQL-Serverinstanz als Quellsystem herstellen und SQL-Abfragen ausführen, um Daten zu erhalten. Dann, Zuerst müssen wir die notwendigen Abhängigkeiten herunterladen.
Laden Sie die MS-SQL-JAR-Datei herunter (mssql-jdbc-9.2.1.jre8) von der Microsoft-Website und kopieren Sie es in das Verzeichnis „/ opt / Funke / Gläser“.
https://www.microsoft.com/en-us/download/details.aspx?id=11774
Laden Sie die Spark SQL-JAR-Datei herunter (chispa-sql_2.12-3.0.3.jar) desde el sitio de descarga de Apache y cópielo en el directorio ‚/ opt / Funke / Gläser“.
https://jar-download.com/?search_box=org.apache.spark+spark.sql
Bearbeiten Sie das .profil, PySpark- und Py4J-Klassen zum Python-Pfad hinzufügen:
exportiere PYTHONPATH=$SPARK_HOME/python/:$PYTHONPFAD exportiere PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:$PYTHONPFAD
Konfigurieren Sie die AWS S3-Verbindung
So stellen Sie eine Verbindung zu einer AWS-Instanz her, Wir müssen die drei JAR-Dateien herunterladen und in das Verzeichnis kopieren „/ opt / Funke / Gläser“. Überprüfen Sie die Version von Hadoop, die Sie derzeit verwenden. Sie können es aus jedem in Ihrer Spark-Installation vorhandenen Glas beziehen. Wenn die Hadoop-Version 2.7.4, Laden Sie die JAR-Datei für die gleiche Version herunter. Para Java SDK, Sie müssen dieselbe Version herunterladen, die zum Generieren des Hadoop-aws-Pakets verwendet wurde.
Stellen Sie sicher, dass die Versionen die neuesten sind.
- hadoop-aws-2.7.4.jar
- aws-java-sdk-1.7.4.jar
- jets3t-0.9.4.Krug
sudo wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk/1.11.30/aws-java-sdk-1.7.4.jar sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/2.7.3/hadoop-aws-2.7.4.jar sudo wget https://repo1.maven.org/maven2/net/java/dev/jets3t/jets3t/0.9.4/jets3t-0.9.4.jar
Python-Entwicklung
Cree un directorio de trabajo llamado ‚Skripte‘ um alle Python-Skripte und Konfigurationsdateien zu speichern. Erstellen Sie eine Datei namens „sqlfile.py“ die die SQL-Abfragen enthält, die wir auf dem entfernten Datenbankserver ausführen möchten.
vi sqlfile.py
Fügen Sie die folgende SQL-Abfrage in die Datei sqlfile.py ein, die die Daten extrahiert. Vor diesem Schritt, Es wird empfohlen, einen Testlauf dieser SQL-Abfrage auf dem Server durchzuführen, um eine Vorstellung von der Anzahl der zurückgegebenen Datensätze zu erhalten.
Abfrage1 = """(auswählen * aus Verkaufsdaten wobei Datum >= '2021-01-01' und Status="Vollendet")"""
Datei speichern und beenden.
Erstellen Sie eine Konfigurationsdatei namens „config.ini“ que almacenará las credenciales de inicio de SitzungDas "Sitzung" Es ist ein Schlüsselbegriff im Bereich der Psychologie und Therapie. Bezieht sich auf ein geplantes Treffen zwischen einem Therapeuten und einem Klienten, wo Gedanken erforscht werden, Emotionen und Verhaltensweisen. Diese Sitzungen können in Länge und Häufigkeit variieren, und ihr Hauptzweck ist es, persönliches Wachstum und Problemlösung zu erleichtern. Die Wirksamkeit der Sitzungen hängt von der Beziehung zwischen dem Therapeuten und dem Therapeuten ab.. und das ParameterDas "Parameter" sind Variablen oder Kriterien, die zur Definition von, ein Phänomen oder System zu messen oder zu bewerten. In verschiedenen Bereichen wie z.B. Statistik, Informatik und naturwissenschaftliche Forschung, Parameter sind entscheidend für die Etablierung von Normen und Standards, die die Datenanalyse und -interpretation leiten. Ihre richtige Auswahl und Handhabung sind entscheidend, um genaue und relevante Ergebnisse in jeder Studie oder jedem Projekt zu erhalten.... aus der Datenbank.
vi config.ini
Fügen Sie die folgenden AWS- und MSSQL-Verbindungsparameter in die Datei ein. Beachten Sie, dass wir separate Abschnitte zum Speichern der AWS- und MSSQL-Verbindungsparameter erstellt haben. Sie können beliebig viele DB-Verbindungsinstanzen erstellen, solange jeder in einem eigenen Abschnitt aufbewahrt wird (mssql1, mssql2, aws1, aws2, etc.).
[aws]
ACCESS_KEY=BBIYYTU6L4U47BGGG&^CF SECRET_KEY=Uy76BBJabczF7h6vv+BFssqTVLDVkKYN/f31puYHtG BUCKET_NAME=s3-bucket-name VERZEICHNIS=Vertriebsdatenverzeichnis [mssql] url = jdbc:SQL Server://PPOP24888S08YTA.APAC.PAD.COMPANY-DSN.COM:1433;databaseName=Transaktionen Datenbank = Transaktionen Benutzer = MSSQL-BENUTZER Passwort = MSSQL-Passwort dbtable = Verkaufsdaten Dateiname = data_extract.csv
Datei speichern und beenden.
Erstellen Sie ein Python-Skript namens „Datenextraktion.py“.
Bibliotheken für Spark und Boto3 importieren
Spark ist in Scala . implementiert, eine Sprache, die in der JVM läuft, aber da wir mit Python arbeiten werden wir PySpark verwenden. Die aktuelle Version von PySpark ist 2.4.3 und es funktioniert mit python 2.7, 3.3 und höher. Sie können sich PySpark als einen Python-basierten Container auf der Scala-API vorstellen.
Hier, AWS SDK für Python (Boto3) erschaffen, AWS-Services konfigurieren und verwalten, wie Amazon EC2 und Amazon S3. Das SDK bietet eine objektorientierte API, sowie Low-Level-Zugriff auf AWS-Services.
Importieren Sie die Python-Bibliotheken, um eine Spark-Sitzung zu starten, query1 von sqlfile.py und boto3.
aus pyspark.sql importieren SparkSession Shutil importieren Importieren von OS Globus importieren boto3 importieren aus sqlfile import query1 aus configparser importieren ConfigParser
Erstellen Sie eine SparkSession
SparkSession proporciona un único punto de entrada para interactuar con el motor Spark subyacente y permite programar Spark con API de DataFrame y Datensatzein "Datensatz" oder Datensatz ist eine strukturierte Sammlung von Informationen, die für statistische Analysen verwendet werden können, Maschinelles Lernen oder Forschung. Datensätze können numerische Variablen enthalten, kategorisch oder textuell, und ihre Qualität ist entscheidend für zuverlässige Ergebnisse. Sein Einsatz erstreckt sich auf verschiedene Disziplinen, wie z.B. Medizin, Wirtschafts- und Sozialwissenschaften, Erleichterung einer fundierten Entscheidungsfindung und der Entwicklung von Vorhersagemodellen..... Am wichtigsten ist, dass es die Anzahl der Konzepte und Builds einschränkt, mit denen ein Entwickler arbeiten muss, während er mit Spark interagiert.. In diesem Punkt, du kannst den ... benutzen ‚Funke – Funke‘ Variable als Instanzobjekt, um für die Dauer Ihres Spark-Jobs auf Ihre öffentlichen Methoden und Instanzen zuzugreifen. Gib der App einen Namen.
AppName = "PySpark-ETL-Beispiel - über MS-SQL JDBC"
Meister = "lokal"
Spark = SparkSession
.Baumeister
.Meister(Meister)
.App Name(App Name)
.Konfiguration("spark.driver.extraClassPath","/opt/spark/jars/mssql-jdbc-9.2.1.jre8.jar")
.getOrCreate()
Lesen Sie die Konfigurationsdatei
Wir haben die Parameter in einer Datei gespeichert „config.ini“ um statische Parameter von Python-Code zu trennen. Dies hilft, saubereren Code ohne jegliche Codierung zu schreiben. Este-Modul implementiert eine grundlegende Konfigurationssprache, die eine ähnliche Struktur wie in Microsoft Windows .ini-Dateien bietet.
URL = config.get('mssql-onprem', 'URL')
user = config.get('mssql-onprem', 'Benutzer')
Passwort = config.get('mssql-onprem', 'Passwort')
dbtable = config.get('mssql-onprem', 'dbtable')
Dateiname = config.get('mssql-onprem', 'Dateiname')
ACCESS_KEY=config.get('aws', 'ZUGANGSSCHLÜSSEL')
SECRET_KEY=config.get('aws', 'GEHEIMER SCHLÜSSEL')
BUCKET_NAME=config.get('aws', 'BUCKET_NAME')
VERZEICHNIS=config.get('aws', 'VERZEICHNIS')
Datenextraktion ausführen
Spark incluye una DatenquelleEIN "Datenquelle" bezieht sich auf jeden Ort oder jedes Medium, an dem Informationen erhalten werden können. Diese Quellen können sowohl primär als auch, wie z.B. Erhebungen und Experimente, als sekundär, als Datenbanken, Wissenschaftliche Artikel oder statistische Berichte. Die richtige Wahl einer Datenquelle ist entscheidend, um die Gültigkeit und Zuverlässigkeit von Informationen in Forschung und Analyse zu gewährleisten.... que puede leer datos de otras bases de datos utilizando JDBC. Führen Sie SQL auf der Remote-Datenbank aus, die eine Verbindung mit dem Microsoft SQL Server JDBC-Treiber und den Verbindungsparametern herstellt. In Option „Anfrage“, wenn du eine ganze Tabelle lesen willst, Geben Sie den Tabellennamen an; andererseits, wenn Sie die Auswahlabfrage ausführen möchten, das gleiche angeben. Die von SQL zurückgegebenen Daten werden in einem Spark-Datenrahmen gespeichert.
jdbcDF = spark.read.format("jdbc")
.Möglichkeit("URL", URL)
.Möglichkeit("Anfrage", Abfrage2)
.Möglichkeit("Benutzer", Benutzer)
.Möglichkeit("Passwort", Passwort)
.Möglichkeit("Treiber", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.Belastung()
jdbcDF.show(5)
Datenrahmen als CSV-Datei speichern
Der Datenrahmen kann als Datei auf dem Server gespeichert werden. CSV-Archiv. Etwas, Dieser Schritt ist optional, falls Sie den Datenrahmen direkt in einen S3-Bucket schreiben möchten, dieser Schritt kann übersprungen werden. PySpark, Ursprünglich, mehrere Partitionen erstellen, Um dies zu vermeiden, können wir sie mit der Koalesce-Funktion als einzelne Datei speichern (1). Dann, Wir verschieben die Datei in den angegebenen Ausgabeordner. Optional, Entfernen Sie das erstellte Ausgabeverzeichnis, wenn Sie den Datenrahmen nur im S3-Bucket speichern möchten.
Pfad="Ausgang"
jdbcDF.coalesce(1).Schreiboption("Header","Stimmt").Möglichkeit("sep",",").Modus("überschreiben").csv(Weg)
Shutil.move(glob.glob(os.getcwd() + '/' + Weg + '/' + r '*.csv')[0], os.getcwd()+ '/' + Dateiname )
Shutil.rmtree(os.getcwd() + '/' + Weg)
Datenrahmen in Bucket S3 kopieren
Zuerst, cree una sesión ‚boto3‘ Verwenden von AWS-Zugriff und geheimen Schlüsselwerten. Rufen Sie die Werte aus dem S3-Bucket und dem Unterverzeichnis ab, in das Sie die Datei hochladen möchten. das Datei hochladen() akzeptiert einen Dateinamen, ein Bucket-Name und ein Objektname. Die Methode verarbeitet große Dateien, indem sie sie in kleinere Blöcke aufteilt und jeden Block parallel lädt.
Sitzung = boto3.Sitzung(
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=GEHEIM_SCHLÜSSEL,
)
Bucket_name=BUCKET_NAME
s3_output_key=VERZEICHNIS + Dateiname
s3 = session.resource('s3')
# Dateiname - Datei zum Hochladen
# Eimer - Bucket zum Hochladen (das Verzeichnis der obersten Ebene unter AWS S3)
# Taste - S3-Objektname (kann Unterverzeichnisse enthalten). Wenn nicht angegeben, wird file_name verwendet
s3.meta.client.upload_file(Dateiname=Dateiname, Bucket=bucket_name, Schlüssel=s3_output_key)
Dateien bereinigen
Nach dem Hochladen der Datei in den S3-Bucket, alle auf dem Server verbliebenen Dateien löschen; andererseits, Ich habe einen Fehler geworfen.
if os.path.isfile(Dateiname):
entfernt(Dateiname)
anders:
drucken("Fehler: %s-Datei nicht gefunden" % Dateiname)
Fazit
Apache Spark ist ein Open-Source-Cluster-Computing-Framework mit In-Memory-Verarbeitungsfunktionen. Es wurde in der Programmiersprache Scala entwickelt. Spark bietet viele Funktionen und Fähigkeiten, die es zu einem effizienten Big-Data-Framework machen. Leistung und Geschwindigkeit sind die Hauptvorteile von Spark. Sie können die Terabyte an Daten laden und reibungslos verarbeiten, indem Sie einen Multi-Node-Cluster einrichten. Dieser Artikel gibt eine Vorstellung davon, wie man eine Python-basierte ETL schreibt.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





