Distanzmetriken sind ein wichtiger Bestandteil verschiedener Algorithmen für maschinelles Lernen. Diese Entfernungsmetriken werden sowohl in der überwachtes LernenÜberwachtes Lernen ist ein Ansatz des maschinellen Lernens, bei dem ein Modell mit einem Satz von beschrifteten Daten trainiert wird. Jede Eingabe im Dataset ist mit einer bekannten Ausgabe verknüpft, So kann das Modell lernen, Ergebnisse für neue Eingaben vorherzusagen. Diese Methode wird häufig in Anwendungen wie der Bildklassifizierung eingesetzt., Spracherkennung und Trendvorhersage, und unterstreicht seine Bedeutung in... als unbeaufsichtigt, allgemein um die Ähnlichkeit zwischen Datenpunkten zu berechnen.
Eine effektive Distanzmetrik verbessert die Leistung unseres Modells für maschinelles Lernen, entweder zum Sortieren oder Gruppieren von Aufgaben.
Nehmen wir an, wir möchten Cluster mit dem K-Means-Clustering- oder Nearest Neighbor-Algorithmus erstellen, um ein Klassifizierungs- oder Regressionsproblem zu lösen.. Wie würden Sie hier die Ähnlichkeit zwischen verschiedenen Beobachtungen definieren?? Wie können wir feststellen, dass zwei Punkte einander ähnlich sind??
Dies geschieht, wenn ihre Eigenschaften ähnlich sind, Wahrheit? Wenn wir diese Punkte zeichnen, werden in der Ferne näher beieinander sein.
Deswegen, wir können den Abstand zwischen den Punkten berechnen und dann die Ähnlichkeit zwischen ihnen definieren. Hier ist die Millionen-Dollar-Frage: Wie berechnen wir diese Distanz und was sind die verschiedenen Distanzmetriken beim maschinellen Lernen?
Das wollen wir in diesem Artikel beantworten. Wir analysieren 4 Arten von Entfernungsmetriken in maschinelles Lernen und verstehen, wie sie arbeiten Felshaken.
4 Arten von Distanzmetriken beim maschinellen Lernen
- Euklidische Entfernung
- Entfernung von Manhattan
- Minkowski-Distanz
- Hamming-Abstand
Beginnen wir mit der am häufigsten verwendeten Distanzmetrik: die euklidische Distanz.
1. Euklidische Entfernung
Die euklidische Distanz stellt die kürzeste Distanz zwischen zwei Punkten dar.
Die meisten Algorithmen für maschinelles Lernen, einschließlich K-Means, Verwenden Sie diese Distanzmetrik, um die Ähnlichkeit zwischen Beobachtungen zu messen. Nehmen wir an, wir haben zwei Punkte wie unten gezeigt:
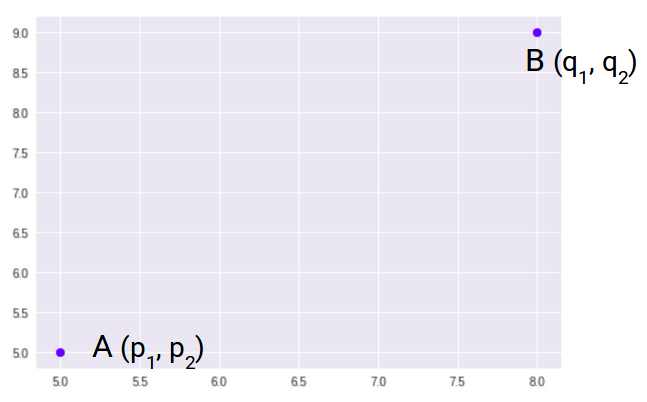
Dann, der euklidische Abstand zwischen diesen beiden Punkten A und B ist:
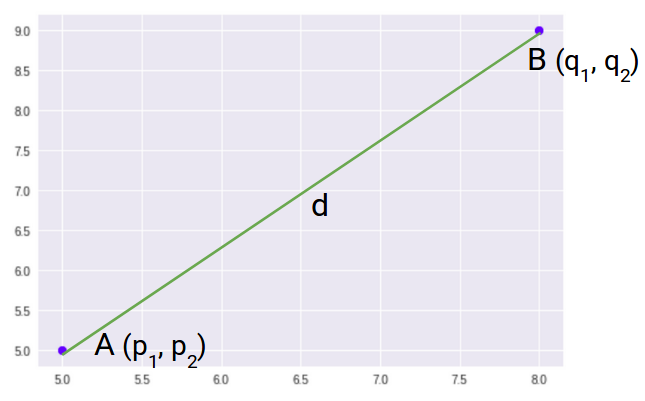
Hier ist die Formel für den euklidischen Abstand:
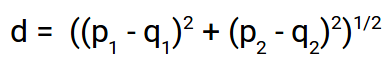
Wir verwenden diese Formel, wenn es um geht 2 Maße. Wir können dies für einen n-dimensionalen Raum verallgemeinern als:
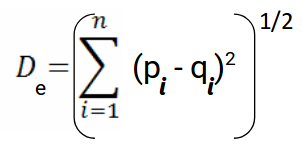
Woher,
- n = Anzahl der Dimensionen
- Pi, qi = Datenpunkte
Lassen Sie uns die euklidische Distanz in codieren Felshaken. Dadurch erhalten Sie ein besseres Verständnis dafür, wie diese Entfernungsmetrik funktioniert..
Zuerst importieren wir die notwendigen Bibliotheken. Ich werde die SciPy-Bibliothek verwenden, die vorgefertigte Codes für die meisten in Python verwendeten Distanzfunktionen enthält:
![]()
Dies sind die beiden Beispielpunkte, die wir verwenden werden, um die verschiedenen Distanzfunktionen zu berechnen. Berechnen wir nun den euklidischen Abstand zwischen diesen beiden Punkten:
![]()
So können wir den euklidischen Abstand zwischen zwei Punkten in Python berechnen. Lassen Sie uns nun die Metrik des zweiten Abstands verstehen, die Entfernung von Manhattan.
2. Entfernung von Manhattan
Die Manhattan-Distanz ist die Summe der absoluten Differenzen zwischen Punkten in allen Dimensionen.
Wir können die Entfernung von Manhattan darstellen als:
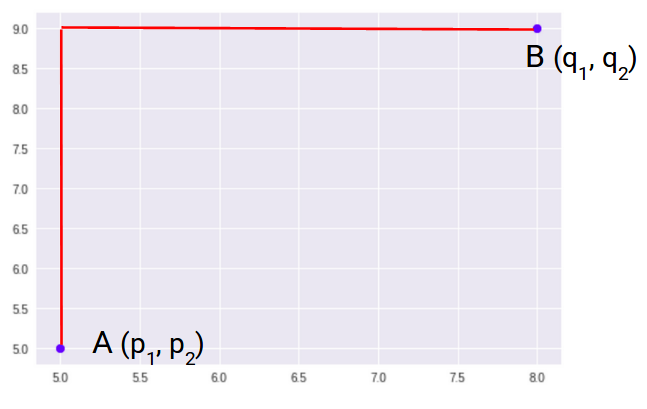
Da die obige Darstellung zweidimensional ist, um die Entfernung von Manhattan zu berechnen, wir nehmen die Summe der absoluten Distanzen in x- und y-Richtung. Dann, die Entfernung von Manhattan im zweidimensionalen Raum ist gegeben als:
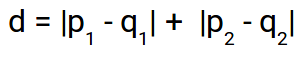
Und die verallgemeinerte Formel für einen n-dimensionalen Raum ist gegeben als:
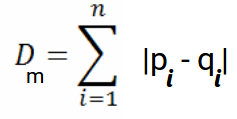
Woher,
- n = Anzahl der Dimensionen
- Pi, qi = Datenpunkte
Jetzt, wir berechnen den Manhattan-Abstand zwischen den beiden Punkten:
![]()
Beachten Sie, dass Die Entfernung von Manhattan wird auch als City-Block-Distanz bezeichnet. SciPy hat eine Funktion namens Häuserblock was den Manhattan-Abstand zwischen zwei Punkten zurückgibt.
Schauen wir uns nun die folgende Distanzmetrik an: Minkowski-Distanz.
3. Minkowski-Distanz
Die Minkowski-Distanz ist die verallgemeinerte Form der Euklidischen und Manhattan-Distanz.
Die Formel für den Minkowski-Abstand lautet:
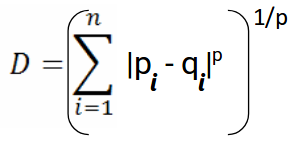
Hier, p steht für die Ordnung der Norm. Berechnen wir die Minkowski-Distanz der Ordnung 3:
![]()
Der Parameter p der SciPy Minkowski Distanzmetrik repräsentiert die Ordnung der Norm. Bei Bestellung (P) es ist 1, die Entfernung von Manhattan darstellt und wenn die Reihenfolge in der obigen Formel ist 2, repräsentiert die euklidische Distanz.
Lass uns das in Python überprüfen:
![]()
Hier, das sieht man bei der bestellung 1, Sowohl Minkowski als auch Manhattan Distance sind gleich. Lassen Sie uns auch den euklidischen Abstand überprüfen:

Wenn die Bestellung ist 2, Wir können sehen, dass die Minkowski- und Euklidischen Distanzen gleich sind.
Bis jetzt, Wir haben die Entfernungsmetriken behandelt, die beim Umgang mit kontinuierlichen oder numerischen Variablen verwendet werden. Aber Was ist, wenn wir kategoriale Variablen haben?? Wie können wir die Ähnlichkeit zwischen kategorialen Variablen bestimmen?? Hier können wir eine andere Distanzmetrik namens Hamming Distance verwenden.
4. Hamming-Abstand
Die Hamming-Distanz misst die Ähnlichkeit zwischen zwei gleich langen Strings. Der Hamming-Abstand zwischen zwei gleich langen Zeichenfolgen ist die Anzahl der Stellen, an denen sich die entsprechenden Zeichen unterscheiden.
Lassen Sie uns das Konzept anhand eines Beispiels verstehen. Sagen wir, wir haben zwei Saiten:
„Euklidiana“ Ja „Manhattan“
Da die Länge dieser Strings gleich ist, wir können die Hamming-Distanz berechnen. Wir werden Charakter für Charakter gehen und uns den Ketten anschließen. Das erste Zeichen beider Strings (e bzw. m) ist anders. Ähnlich, das zweite Zeichen beider Strings (uya) ist anders. und so weiter.
Schau genau hin: sieben Zeichen sind anders, während zwei Charaktere (die letzten beiden zeichen) Sie sind sich ähnlich:

Deswegen, die Hamming-Distanz wird hier sein 7. Beachten Sie, dass je größer die Hamming-Distanz zwischen zwei Saiten ist, desto unterschiedlicher werden diese Saiten sein (und umgekehrt).
Mal sehen, wie wir den Hamming-Abstand von zwei Strings in Python berechnen können. Zuerst, Wir werden zwei Strings definieren, die wir verwenden werden:
Das sind die beiden Ketten „Euklidisch“ Ja „Manhattan“ das haben wir auch im Beispiel gesehen. Berechnen wir nun den Hamming-Abstand zwischen diesen beiden Strings:
![]()
Wie wir im vorherigen Beispiel gesehen haben, die Hamming-Distanz zwischen "euklidisch" und "manhattan" beträgt 7. Wir haben auch gesehen, dass der Hamming-Abstand nur funktioniert, wenn wir Saiten gleicher Länge haben.
Mal sehen, was passiert, wenn wir Ketten unterschiedlicher Länge haben:
![]()
Sie können sehen, dass die Längen der beiden Ketten unterschiedlich sind. Mal sehen, was passiert, wenn wir versuchen, den Hamming-Abstand zwischen diesen beiden Strings zu berechnen:
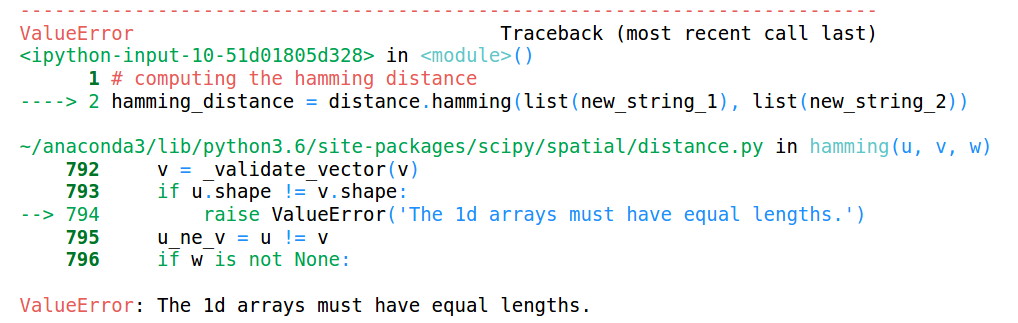
Dies wirft einen Fehler aus, der besagt, dass die Längen der Arrays gleich sein müssen. Deswegen, Hamming-Distanz funktioniert nur, wenn wir Strings oder Arrays derselben Länge haben.
Dies sind einige der Ähnlichkeitsmaße oder Distanzmatrizen, die im Allgemeinen beim maschinellen Lernen verwendet werden.





