Dieser Artikel wurde im Rahmen der Data Science Blogathon
In der heutigen technologiegetriebenen Welt, jede Sekunde wird eine große Datenmenge erzeugt. Eine ständige Überwachung und korrekte Analyse dieser Daten ist notwendig, um aussagekräftige und nützliche Informationen zu erhalten..
Echtzeit Sensordaten, IoT-Geräte, Protokolldateien, sozialen Medien, etc. müssen genau überwacht und sofort bearbeitet werden. Deswegen, für Echtzeit-Datenanalyse, wir brauchen eine hoch skalierbare Datenübertragungs-Engine, zuverlässig und fehlertolerant.
Datenübertragung
Datenstreaming ist eine Möglichkeit, Daten kontinuierlich in Echtzeit aus mehreren Datenquellen in Form von Datenströmen zu sammeln.. Sie können sich Datastream als eine Tabelle vorstellen, die kontinuierlich aggregiert wird.
Die Datenübertragung ist unerlässlich, um riesige Mengen an Live-Daten zu verarbeiten. Solche Daten können aus einer Vielzahl von Quellen stammen, z. B. aus Online-Transaktionen, Protokolldateien, Sensoren, Spieleraktivitäten im Spiel, etc.
Es gibt mehrere Techniken, um Daten in Echtzeit zu übertragen, Was Apache KafkaApache Kafka ist eine verteilte Messaging-Plattform, die für die Verarbeitung von Echtzeit-Datenströmen entwickelt wurde. Ursprünglich entwickelt von LinkedIn, Bietet hohe Verfügbarkeit und Skalierbarkeit, Dies macht es zu einer beliebten Wahl für Anwendungen, die die Verarbeitung großer Datenmengen erfordern. Kafka ermöglicht Entwicklern die Veröffentlichung, Abonnieren und Speichern von Ereignisprotokollen, Erleichterung der Systemintegration und Echtzeitanalyse...., Spark-Streaming, Apache GerinneFlume ist eine Open-Source-Software, die für die Datenerfassung und den Datentransport entwickelt wurde. Verwenden Sie einen flussbasierten Ansatz, Ermöglicht das Verschieben von Daten aus verschiedenen Quellen auf Speichersysteme wie Hadoop. Seine modulare und skalierbare Architektur erleichtert die Integration mit mehreren Datenquellen, Das macht es zu einem wertvollen Werkzeug für die Verarbeitung und Analyse großer Informationsmengen in Echtzeit.... etc. In diesem Beitrag, Wir besprechen die Datenübertragung mit Spark-Streaming.
Spark-Streaming
Spark Streaming ist ein wesentlicher Bestandteil von API-Zentrale von Spark für Echtzeit-Datenanalyse. Ermöglicht es uns, eine skalierbare Live-Streaming-Anwendung zu erstellen, leistungsstark und fehlertolerant.
Spark Streaming unterstützt die Echtzeit-Datenverarbeitung aus verschiedenen Eingabequellen und das Speichern der verarbeiteten Daten auf verschiedenen Ausgabeempfängern.
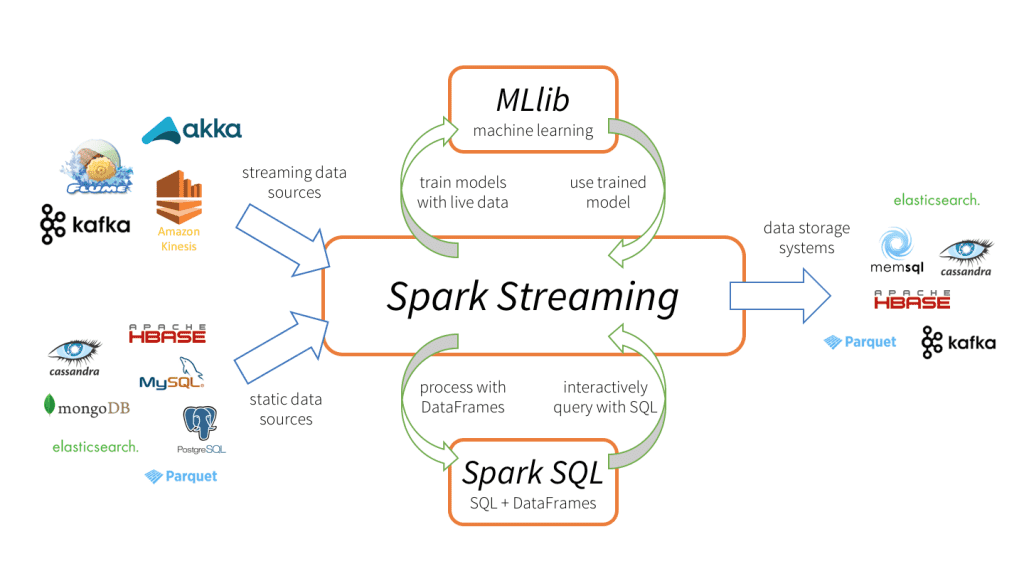
Spark Streaming-Tiene 3 Hauptbestandteile, wie im Bild oben gezeigt.
-
Eingabedatenquellen: Streaming-Datenquellen (als Kafka, Gerinne, Kinese, etc.), statische Datenquellen (wie MySQL, MongoDB, Kassandra, etc.), Sockets TCP, Twitter, etc.
-
Motorfunken-Streaming: Um eingehende Daten mit verschiedenen integrierten Funktionen zu verarbeiten, komplexe Algorithmen. Was ist mehr, Wir können Live-Übertragungen überprüfen, wenden maschinelles Lernen mit Spark SQL bzw. MLlib an.
-
Auslaufspülen: Verarbeitete Daten können in Dateisystemen gespeichert werden, Datenbanken (relational und NoSQL), Live-Panels, etc.
Solche einzigartigen Datenverarbeitungsfunktionen, Eingabe- und Ausgabeformat tun Spark-Streaming attraktiver, führt zu einer schnellen Akzeptanz.
Vorteile von Spark-Streaming
-
Einheitlicher Übertragungsrahmen für alle Datenverarbeitungsaufgaben (einschließlich maschinellem Lernen, Grafikverarbeitung, SQL-Operationen) in Live-Datenströmen.
-
Dynamischer Lastenausgleich und besseres Ressourcenmanagement durch effiziente Verteilung der Arbeitslast zwischen den Mitarbeitern und paralleles Starten der Aufgabe.
-
Tief integriert in fortschrittliche Verarbeitungsbibliotheken wie Spark SQL, MLlib, GraphX.
-
Schnellere Wiederherstellung nach Fehlern durch paralleles Neustarten fehlgeschlagener Aufgaben auf anderen freien Knoten.
Spark-Streaming-Grundlagen
Spark Streaming teilt die Live-Eingangsdatenströme in Batches auf, die dann von . verarbeitet werden Funkenmotor.

DStream (diskretisierte Strömung)
DStream ist eine High-Level-Abstraktion von Spark Streaming, Grundsätzlich, bedeutet den kontinuierlichen Datenfluss. Kann aus Streaming-Datenquellen erstellt werden (als Kafka, Gerinne, Kinese, etc.) oder Ausführen von High-Level-Operationen auf anderen DStreams.
Im Inneren, DStream ist ein RDD-Stream und dieses Phänomen ermöglicht die Integration von Spark Streaming mit anderen Spark-Komponenten wie MLlib, GraphX, etc.

Beim Erstellen einer Streaming-App, wir müssen auch die Batch-Dauer angeben, um in regelmäßigen Zeitabständen neue Batches zu erstellen. Normalerweise, die Dauer der Charge variiert von 500 ms bis mehrere Sekunden. Zum Beispiel, Sohn 3 Sekunden, dann werden die Eingabedaten alle gesammelt 3 Sekunden.
Mit Spark Streaming können Sie Code in gängigen Programmiersprachen wie Python schreiben, Scala und Java. Schauen wir uns eine Beispiel-Streaming-App an, die PySpark verwendet.
Beispiel-App
Wie wir bereits besprochen haben, Spark-Streaming es ermöglicht auch den Empfang von Datenströmen über TCP-Sockets. Schreiben wir also ein einfaches Streaming-Programm, um Textstreams an einem bestimmten Port zu empfangen, Führen Sie eine grundlegende Textbereinigung durch (So entfernen Sie Leerzeichen, Stoppwort entfernen, lematización, etc.) und drucke den sauberen Text auf dem Bildschirm aus.
Beginnen wir nun mit der Implementierung, indem wir die folgenden Schritte ausführen.
1. Kontext zum Senden und Empfangen von Datenströmen erstellen
Streaming-Kontext ist der Haupteinstiegspunkt für jede Streaming-Anwendung. Es kann durch Instanziieren erstellt werden Streaming-Kontext So'ne Art pyspark.streaming Modul.
from pyspark import SparkContext aus pyspark.streaming importieren StreamingContext
Beim Erstellen Streaming-Kontext wir können die Dauer der Charge angeben, zum Beispiel, hier ist die Dauer der Charge 3 Sekunden.
sc = SparkContext(AppName = "Textreinigung") strc = StreamingContext(SC, 3)
Sobald die Streaming-Kontext es ist erstellt, Wir können mit dem Empfang von Daten in Form von DStream über das TCP-Protokoll an einem bestimmten Port beginnen. Zum Beispiel, hier wird der Hostname angegeben als „localhost“ und der verwendete Port ist 8084.
text_data = strc.socketTextStream("localhost", 8084)
2. Ausführen von Operationen an Datenströmen
Nach dem Erstellen von a DStream Objekt, wir können Operationen darauf durchführen, wie es erforderlich ist. Hier, Wir haben eine benutzerdefinierte Textbereinigungsfunktion geschrieben.
Diese Funktion wandelt zuerst den eingegebenen Text in Kleinbuchstaben um, dann entferne zusätzliche Leerzeichen, nicht alphanumerische Zeichen, Links / URL, Stoppwörter und dann das weitere Stemmen des Textes mit der NLTK-Bibliothek.
Importieren
aus nltk.corpus importieren Stoppwörter
stop_words = gesetzt(Stoppwörter.Wörter('Englisch'))
aus nltk.stem importieren WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def clean_text(Satz):
Satz = Satz.lower()
Satz = re.sub("s+"," ", Satz)
Satz = re.sub("W"," ", Satz)
Satz = re.sub(R"httpS+", "", Satz)
Satz=" ".beitreten(Wort für Wort im Satz.split() wenn Wort nicht in stop_words)
Satz = [lemmatizer.lemmatize(Zeichen, "v") für Token im Satz.split()]
Satz = " ".beitreten(Satz)
Rückgabesatz.strip()
3. Streaming-Dienst starten
Der Streamingdienst ist noch nicht gestartet. Verwenden Sie die Anfang() Funktion an der Spitze der Streaming-Kontext Objekt, um es zu starten und bis zum Beendigungsbefehl weiterhin Übertragungsdaten zu empfangen (Strg + C oder Strg + MIT) nicht empfangen werden waitTermination () Funktion.
strc.start() strc.awaitTermination()
HINWEIS – Der vollständige Code kann heruntergeladen werden unter hier.
Jetzt müssen wir zuerst die ‚North Carolina‚Befehl (Netcat Dienstprogramm) um die Textdaten vom Datenserver an den Spark-Streaming-Server zu senden. Netcat ist ein kleines Dienstprogramm, das auf Unix-ähnlichen Systemen verfügbar ist, um Netzwerkverbindungen über TCP- oder UDP-Ports zu lesen und zu schreiben. Ihre beiden Hauptoptionen sind:
-
-l: Lassen North Carolina auf eine eingehende Verbindung warten, anstatt eine Verbindung zu einem entfernten Host aufzubauen.
-
-k: Kasse North Carolina um auf eine andere Verbindung eingestellt zu bleiben, nachdem die aktuelle Verbindung abgeschlossen ist.
Also führe folgendes aus North Carolina Befehl im Terminal.
nc -lk 8083
Ähnlich, Führen Sie das pyspark-Skript in einem anderen Terminal mit dem folgenden Befehl aus, um die Textbereinigung der empfangenen Daten durchzuführen.
Spark-Senden streaming.py localhost 8083
Nach dieser Demonstration, jeder im Terminal eingegebene Text (Laufen netcat Server) wird bereinigt und der bereinigte Text wird alle auf einem anderen Terminal gedruckt 3 Sekunden (Chargendauer).


Abschließende Anmerkungen
In diesem Artikel, wir diskutierten Spark-Streaming, Ihre Vorteile bei der Echtzeit-Datenübertragung und einer Beispielanwendung (utilizando-Sockets TCP) um Live-Datenströme zu empfangen und bedarfsgerecht zu verarbeiten.
Die in diesem Artikel gezeigten Medien zur Implementierung von Modellen für maschinelles Lernen, die CherryPy und Docker nutzen, sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet..





