Dieser Artikel wurde im Rahmen der Data Science Blogathon
Die verschiedenen Deep-Learning-Methoden verwenden Daten, um neuronale Netzwerkalgorithmen zu trainieren, um eine Vielzahl von maschinellen Lernaufgaben auszuführen., als Klassifizierung verschiedener Objektklassen. Convolutional Neural Networks sind sehr leistungsfähige Deep-Learning-Algorithmen für die Bildanalyse. In diesem Artikel wird erklärt, wie man baut, Trainieren und evaluieren Sie neuronale Faltungsnetze.
Außerdem lernen Sie, wie Sie Ihre Fähigkeit verbessern, aus Daten zu lernen und Trainingsergebnisse zu interpretieren.. Deep Learning hat mehrere Anwendungen wie die Bildverarbeitung, Verarbeitung natürlicher Sprache, etc. Es wird auch in der Medizin verwendet, Medien und Unterhaltung, Autonome Autos, etc.
Was ist CNN?
CNN ist ein leistungsstarker Algorithmus für die Bildverarbeitung. Diese Algorithmen sind derzeit die besten Algorithmen, die wir für die automatisierte Bildverarbeitung haben.. Viele Unternehmen verwenden diese Algorithmen, um beispielsweise Objekte in einem Bild zu identifizieren.
Bilder enthalten RGB-Kombinationsdaten. Matplotlib kann verwendet werden, um ein Bild aus einer Datei in den Speicher zu importieren. Der Computer sieht kein Bild, alles was du siehst ist ein Array von Zahlen. Farbbilder werden in dreidimensionalen Arrays gespeichert. Die ersten beiden Dimensionen entsprechen der Höhe und Breite des Bildes (die Anzahl der Pixel). Die letzte Dimension entspricht den Farben Rot, Grün und Blau in jedem Pixel vorhanden.
Drei Schichten CNN
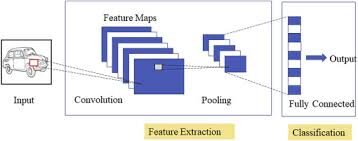
Spezialisierte neuronale Faltungsnetze für Bild- und Videoerkennungsanwendungen. CNN wird hauptsächlich bei Bildanalyseaufgaben wie der Bilderkennung verwendet, Objekterkennung und Segmentierung.
Es gibt drei Arten von Schichten in Convolutional Neural Networks:
1) Faltdeckel: in einem typischen neuronalen Netz, jedes Eingabeneuron ist mit der nächsten versteckten Schicht verbunden. Und CNN, nur ein kleiner Bereich der Neuronen der Eingabeschicht verbindet sich mit der verborgenen Neuronenschicht.
2) Gruppierungsebene: der Gruppierungs-Layer wird verwendet, um die Dimensionalität der Feature-Map zu reduzieren. Es wird mehrere Ebenen der Aktivierung und Gruppierung innerhalb der versteckten Ebene von CNN geben.
3) Vollständig verbundene Schicht: Vollständig verbundene Ebenen bilden die letzten deckt Im Netz. Der Eingang zum vollständig verbundene Schicht ist die Ausgabe der endgültigen Gruppierung oder Faltung Vorderseite, die abgeflacht und dann in die vollständig verbundene Schicht.
MNIST-Datensatz
In diesem Artikel, wir arbeiten an der Objekterkennung in Bilddaten mit dem MNIST-Datensatz für die handschriftliche Ziffernerkennung.
Der MNIST-Datensatz besteht aus Ziffernbildern einer Vielzahl gescannter Dokumente. Jedes Bild ist ein Quadrat von 28 x 28 Pixel. In diesem Datensatz, werden verwendet 60.000 Bilder zum Trainieren des Modells und 10.000 Bilder zum Testen des Modells. Es gibt 10 Ziffern (0 ein 9) Ö 10 Klassen vorherzusagen.

Laden des MNIST-Datensatzes
Installieren Sie die TensorFlow-Bibliothek und importieren Sie den Datensatz als Trainings- und Testdatensatz.
Plotten Sie die Bildbeispielausgabe
!pip installieren tensorflow
aus keras.datasets importieren mnist
import matplotlib.pyplot als plt
(X_Zug,y_train), (X_test, y_test)= mnist.load_data()
plt.subplot()
plt.imshow(X_Zug[9], cmap=plt.get_cmap('grau'))
Produktion:
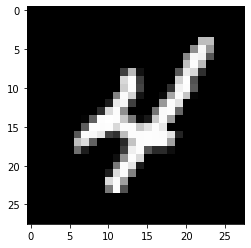
Deep-Learning-Modell mit mehrschichtigen Perzeptronen unter Verwendung von MNIST
Bei diesem Modell, wir werden ein einfaches neuronales Netzwerkmodell mit einer einzelnen versteckten Schicht für den MNIST-Datensatz für die handschriftliche Ziffernerkennung erstellen.
Ein Perzeptron ist ein einzelnes Neuronenmodell, das der Baustein der größten neuronalen Netze ist. Das mehrschichtige Perzeptron besteht aus drei Schichten, nämlich, die Eingabeschicht, die versteckte Schicht und die Ausgabeschicht. Die versteckte Schicht ist für die Außenwelt nicht sichtbar. Nur die Eingabeschicht und die Ausgabeschicht sind sichtbar. Für alle DL-Modelle, Daten müssen numerischer Natur sein.
Paso 1: Schlüsselbibliotheken importieren
numpy als np importieren von keras.models importieren Sequential aus keras.layers importieren dicht aus keras.utils importieren np_utils
Paso 2: die Daten umformen
Jedes Bild ist 28X28 groß, also da ist 784 Pixel. Dann, die Ausgabeschicht hat 10 Abflüge, die versteckte Schicht hat 784 Neuronen und die Eingabeschicht hat 784 Karten. Später, der Datensatz wird in einen Float-Datentyp konvertiert.
number_pix=X_train.shape[1]*X_train.shape[2]
X_train=X_train.reshape(X_train.shape[0], number_pix).astyp('float32')
X_test=X_test.reshape(X_test.shape[0], number_pix).astyp('float32')
Paso 3: Daten normalisieren
NN-Modelle erfordern im Allgemeinen skalierte Daten. In diesem Code-Schnipsel, Daten werden normalisiert von (0-255) ein (0-1) und die Zielvariable wird in einer einzigen Verwendung für die weitere Analyse kodiert. Die Zielvariable hat insgesamt 10 Lektionen (0-9)
X_train=X_train/255 X_test=X_test/255 y_train= np_utils.to_categorical(y_train) y_test= np_utils.to_categorical(y_test) num_classes=y_train.shape[1] drucken(Anzahl_Klassen)
Produktion:
10
Jetzt, wir erstellen eine Funktion NN_model und kompilieren sie
Paso 4: Modellfunktion definieren
def nn_model():
model=sequentiell()
model.add(Dicht(number_pix, input_dim=number_pix, Aktivierung = 'neu lesen'))
mode.add(Dicht(Anzahl_Klassen, Aktivierung='Softmax'))
model.compile(Verlust="kategoriale_Kreuzentropie", optimieren ="Adam", Metriken=['Richtigkeit'])
Rückgabemodell
Es gibt zwei Schichten, eine ist eine versteckte Ebene mit der ReLu-Triggerfunktion und die andere ist die Ausgabeebene, die die Softmax-Funktion verwendet.
Paso 5: führe das Modell aus
model=nn_model()
model.fit(X_Zug, y_train, Validation_data=(X_test,y_test),Epochen=10, batch_size=200, ausführlich=2)
score= model.evaluate(X_test, y_test, ausführlich=0)
drucken('Der Fehler ist: %.2F%%'%(100-Spielstand[1]*100))
Produktion:
Epoche 1/10 300/300 - 11S - Verlust: 0.2778 - Richtigkeit: 0.9216 - Wertverlust: 0.1397 - val_accuracy: 0.9604 Epoche 2/10 300/300 - 2S - Verlust: 0.1121 - Richtigkeit: 0.9675 - Wertverlust: 0.0977 - val_accuracy: 0.9692 Epoche 3/10 300/300 - 2S - Verlust: 0.0726 - Richtigkeit: 0.9790 - Wertverlust: 0.0750 - val_accuracy: 0.9778 Epoche 4/10 300/300 - 2S - Verlust: 0.0513 - Richtigkeit: 0.9851 - Wertverlust: 0.0656 - val_accuracy: 0.9796 Epoche 5/10 300/300 - 2S - Verlust: 0.0376 - Richtigkeit: 0.9892 - Wertverlust: 0.0717 - val_accuracy: 0.9773 Epoche 6/10 300/300 - 2S - Verlust: 0.0269 - Richtigkeit: 0.9928 - Wertverlust: 0.0637 - val_accuracy: 0.9797 Epoche 7/10 300/300 - 2S - Verlust: 0.0208 - Richtigkeit: 0.9948 - Wertverlust: 0.0600 - val_accuracy: 0.9824 Epoche 8/10 300/300 - 2S - Verlust: 0.0153 - Richtigkeit: 0.9962 - Wertverlust: 0.0581 - val_accuracy: 0.9815 Epoche 9/10 300/300 - 2S - Verlust: 0.0111 - Richtigkeit: 0.9976 - Wertverlust: 0.0631 - val_accuracy: 0.9807 Epoche 10/10 300/300 - 2S - Verlust: 0.0082 - Richtigkeit: 0.9985 - Wertverlust: 0.0609 - val_accuracy: 0.9828 Der Fehler ist: 1.72%
In den Modellergebnissen, wird sichtbar, wenn die Anzahl der Epochen zunimmt, verbessert die Genauigkeit. Der Fehler ist von 1,72%, geringfügig ist der Fehler, desto höher die Genauigkeit des Modells.
Faltungsneurales Netzwerkmodell mit MNIST
In diesem Abschnitt, wir werden einfache CNN-Modelle für MNIST erstellen, die Faltungsschichten demonstrieren, Gruppieren von Ebenen und Ablegen von Ebenen.
Paso 1: alle notwendigen Bibliotheken importieren
numpy als np importieren von keras.models importieren Sequential aus keras.layers importieren dicht aus keras.utils importieren np_utils aus keras.layers importieren Dropout aus keras.layers importieren Flatten aus keras.layers.convolutional importieren Conv2D aus keras.layers.convolutional import MaxPooling2D
Paso 2: Richten Sie den Seed für Reproduzierbarkeit ein und laden Sie die MNIST-Daten
Samen=10 np.random.seed(Samen) (X_Zug,y_train), (X_test, y_test)= mnist.load_data()
Paso 3: Daten in Float-Werte umwandeln
X_train=X_train.reshape(X_train.shape[0], 1,28,28).astyp('float32')
X_test=X_test.reshape(X_test.shape[0], 1,28,28).astyp('float32')
Paso 4: Daten normalisieren
X_train=X_train/255 X_test=X_test/255 y_train= np_utils.to_categorical(y_train) y_test= np_utils.to_categorical(y_test) num_classes=y_train.shape[1] drucken(Anzahl_Klassen)
Eine klassische CNN-Architektur sieht wie folgt aus:
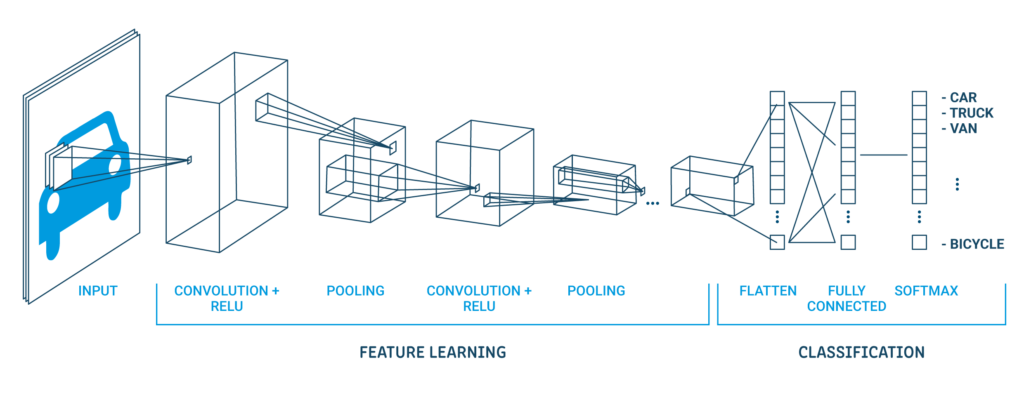
| Ausgabeschicht (10 Abflüge) |
| Versteckter Umhang (128 Neuronen) |
| Flache Schicht |
| Umhang der Verlassenheit 20% |
| Maximale Gruppierungsebene 2 × 2 |
| Faltdeckel 32 Karten, 5 × 5 |
| Sichtbare Schicht 1x28x28 |
Die erste versteckte Schicht ist eine Faltungsschicht namens Convolution2D. Entsorgen 32 Feature-Maps mit Größe 5 × 5 und Schleiffunktion. Dies ist die Eingabeschicht. Das Folgende ist die Pooling-Schicht, die den maximalen Wert namens MaxPooling2D . annimmt. Bei diesem Modell, ist als Poolgröße von . konfiguriert 2 × 2.
Die Regularisierung erfolgt in der Abbruchschicht. Es ist so eingestellt, dass die nach dem Zufallsprinzip ausgeschlossen wird 20% Schichtneuronen, um eine Überanpassung zu vermeiden. Die fünfte Ebene ist die abgeflachte Ebene, die die 2D-Matrixdaten in einen Vektor namens Flatten . umwandelt. Ermöglicht die vollständige Verarbeitung der Ausgabe durch eine vollständig verbundene Standardschicht.
Dann, die vollständig verbundene Schicht wird verwendet mit 128 Neuronen und die Aktivierungsfunktion des Gleichrichters. Schließlich, die Ausgabeschicht hat 10 Neuronen für 10 Klassen und eine Softmax-Triggerfunktion, um wahrscheinlichkeitsähnliche Vorhersagen für jede Klasse zu generieren.
Paso 5: führe das Modell aus
def cnn_model():
model=sequentiell()
model.add(Conv2D(32,5,5, padding='gleich',input_shape=(1,28,28), Aktivierung = 'neu lesen'))
model.add(MaxPooling2D(pool_size=(2,2), padding='gleich'))
model.add(Aussteigen(0.2))
model.add(Ebnen())
model.add(Dicht(128, Aktivierung = 'neu lesen'))
model.add(Dicht(Anzahl_Klassen, Aktivierung='Softmax'))
model.compile(Verlust="kategoriale_Kreuzentropie", Optimierer="Adam", Metriken=['Richtigkeit'])
Rückgabemodell
model=cnn_model()
model.fit(X_Zug, y_train, Validation_data=(X_test,y_test),Epochen=10, batch_size=200, ausführlich=2)
score= model.evaluate(X_test, y_test, ausführlich=0)
drucken('Der Fehler ist: %.2F%%'%(100-Spielstand[1]*100))
Produktion:
Epoche 1/10 300/300 - 2S - Verlust: 0.7825 - Richtigkeit: 0.7637 - Wertverlust: 0.3071 - val_accuracy: 0.9069 Epoche 2/10 300/300 - 1S - Verlust: 0.3505 - Richtigkeit: 0.8908 - Wertverlust: 0.2192 - val_accuracy: 0.9336 Epoche 3/10 300/300 - 1S - Verlust: 0.2768 - Richtigkeit: 0.9126 - Wertverlust: 0.1771 - val_accuracy: 0.9426 Epoche 4/10 300/300 - 1S - Verlust: 0.2392 - Richtigkeit: 0.9251 - Wertverlust: 0.1508 - val_accuracy: 0.9537 Epoche 5/10 300/300 - 1S - Verlust: 0.2164 - Richtigkeit: 0.9325 - Wertverlust: 0.1423 - val_accuracy: 0.9546 Epoche 6/10 300/300 - 1S - Verlust: 0.1997 - Richtigkeit: 0.9380 - Wertverlust: 0.1279 - val_accuracy: 0.9607 Epoche 7/10 300/300 - 1S - Verlust: 0.1856 - Richtigkeit: 0.9415 - Wertverlust: 0.1179 - val_accuracy: 0.9632 Epoche 8/10 300/300 - 1S - Verlust: 0.1777 - Richtigkeit: 0.9433 - Wertverlust: 0.1119 - val_accuracy: 0.9642 Epoche 9/10 300/300 - 1S - Verlust: 0.1689 - Richtigkeit: 0.9469 - Wertverlust: 0.1093 - val_accuracy: 0.9667 Epoche 10/10 300/300 - 1S - Verlust: 0.1605 - Richtigkeit: 0.9493 - Wertverlust: 0.1053 - val_accuracy: 0.9659 Der Fehler ist: 3.41%
In den Modellergebnissen, wird sichtbar, wenn die Anzahl der Epochen zunimmt, verbessert die Genauigkeit. Der Fehler ist 3.41%, geringerer Fehler höhere Modellgenauigkeit.
Ich hoffe, es hat Ihnen Spaß gemacht zu lesen und zögern Sie nicht, meinen Code zu verwenden, um ihn für Ihre Zwecke zu testen. Was ist mehr, wenn es einen Kommentar zum Code oder nur zum Blogbeitrag gibt, kontaktiere mich gerne unter [E-Mail geschützt]
Die in diesem CNN-Bildverarbeitungsartikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





