Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Einführung
Brunnen! Wir alle lieben Kuchen. Schaut man sich den Backvorgang genauer an, Sie werden merken, wie die richtige Kombination der verschiedenen Zutaten und ein smarter Hefewirkstoff, Backpulver, Sie können das Steigen und Fallen Ihres Kuchens bestimmen.
“Den Kuchen backen” mag im Whitepaper fehl am Platz erscheinen, aber ich denke, es ist ziemlich zuordenbar und eine schöne Analogie, um die Bedeutung von EDA im Data Science-Prozess zu verstehen.
Wenn Baking the Cake für die Data Science Pipeline ist, entonces Cleveres Treibmittel (Backpulver) ist für die explorative Datenanalyse.
Bevor dir das Wasser im Mund zusammenläuft für einen Kuchen wie meinen, lass uns verstehen.
Was genau ist explorative Datenanalyse?
Explorative Datenanalyse ist ein Ansatz zur Datenanalyse, der eine Vielzahl von Techniken verwendet, um:
- Erhalten Sie Einblick in die Daten.
- Mache Gesundheitschecks. (Um sicher zu sein, dass die Erkenntnisse, die wir extrahieren, tatsächlich aus dem richtigen Datensatz stammen).
- Finden Sie heraus, wo Daten fehlen.
- Auf Ausreißer prüfen.
- Fassen Sie die Daten zusammen.
Nehmen Sie die berühmte Fallstudie von “SCHWARZER FREITAG-VERKAUF” verstehen, Warum brauchen wir EDA?

Das Kernproblem besteht darin, das Kundenverhalten zu verstehen, indem die Kaufsumme vorhergesagt wird. Aber, Ist es nicht zu abstrakt und lässt Sie ratlos, was Sie mit den Daten anfangen sollen, vor allem, wenn Sie so viele verschiedene Produkte mit verschiedenen Kategorien haben?
Bevor Sie weiterlesen, Denk ein bisschen über diese Frage nach: Würden Sie alle verfügbaren Zutaten in die Küche geben, so wie sie in den Ofen sind, um den Kuchen zu backen??
Offensichtlich, Die Antwort ist nein! Bevor Sie den vollständigen Datensatz in Betracht ziehen, sollten Sie ihn im Modell für maschinelles Lernen backen, werde wollen
- Extrahieren Sie wichtige Informationen
- Variablenidentifikation (ob die Daten kategoriale oder numerische Variablen oder eine Kombination aus beidem enthalten).
- Das Verhalten der Variablen (wenn die Variablen Werte von haben 0 ein 10 o de 0 ein 1 Million).
- Beziehung zwischen Variablen (wie Variablen voneinander abhängen).
-
Datenkonsistenz prüfen
- Um sicherzustellen, dass alle Daten vorhanden sind. (Wenn wir drei Jahre lang Daten gesammelt haben, fehlende Wochen können in späteren Phasen ein Problem sein).
- Gibt es einen fehlenden Wert??
- Gibt es Ausreißer im Datensatz?? (zum Beispiel: eine Person mit 2000 Jahre ist definitiv eine Anomalie)
- Funktionsengineering
- Feature-Engineering (um neue Features aus vorhandenen Roh-Features im Dataset zu erstellen).
** EDA, im Wesentlichen, kann jedes Machine-Learning-Modell brechen oder ausführen. **
Schritte in der explorativen Datenanalyse

Es gibt 5 Schritte in EDA: ->
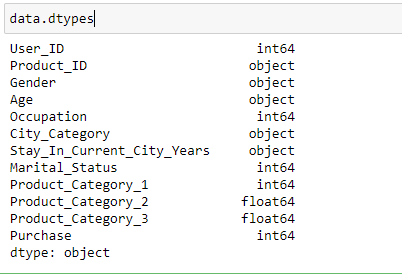
- Variablenidentifikation: In diesem Schritt, Wir identifizieren jede Variable, indem wir ihren Typ ermitteln. Nach unseren Bedürfnissen, wir können den Datentyp jeder Variablen ändern.

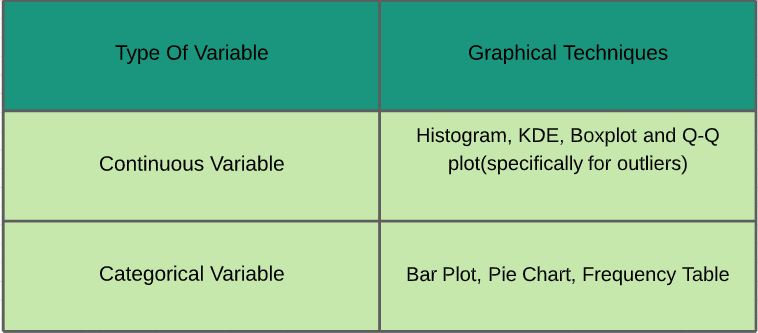
~ Statistiken spielen eine wichtige Rolle bei der Datenanalyse. Es ist ein Satz von Regeln und Konzepten für die Analyse und Interpretation von Daten. Es gibt verschiedene Arten von Analysen, die je nach Anforderung durchgeführt werden müssen. ~ Lass uns sie studieren - Univariate Analyse: In der univariaten Analyse, Wir untersuchen die individuellen Merkmale jedes Merkmals / Variable im Datensatz vorhanden. Es gibt zwei Arten von Funktionen: kontinuierlich und kategorisch. Im Bild unten, Ich habe einen Spickzettel mit verschiedenen grafischen Techniken gegeben, die angewendet werden können, um sie zu analysieren.

Kontinuierliche Variable:
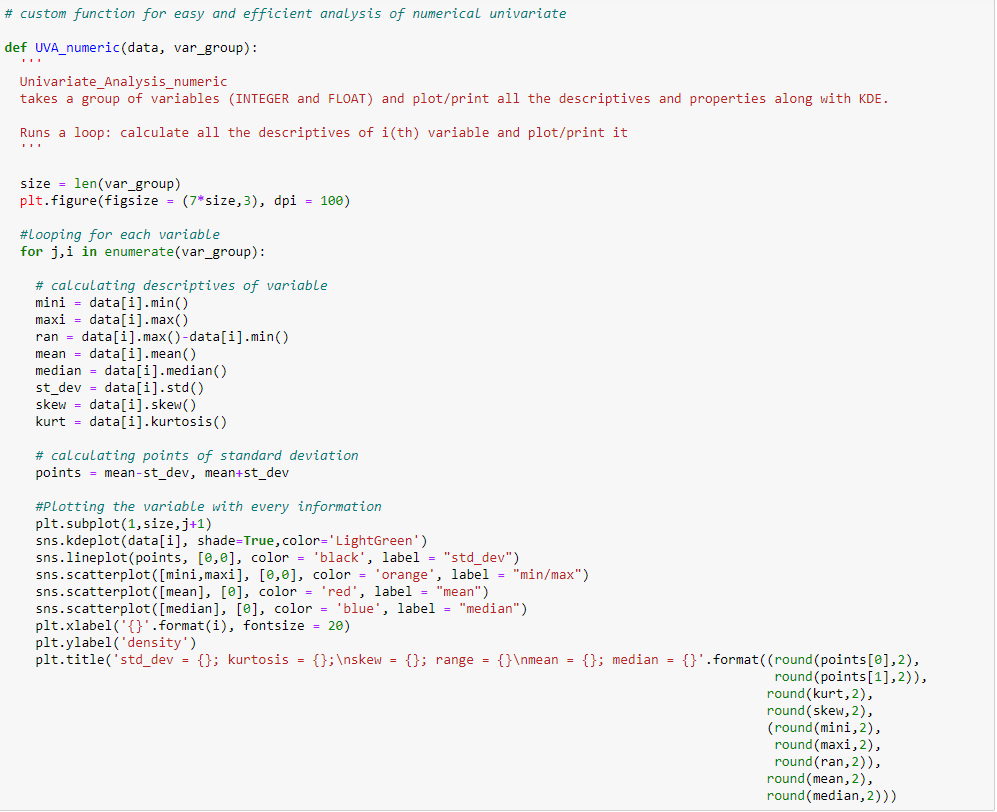
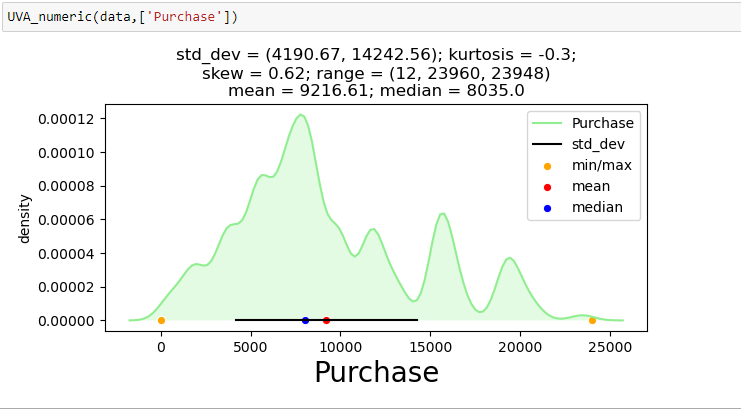
So zeigen Sie die univariate Analyse einer der kontinuierlichen Variablen aus dem Black Friday-Verkaufsdatensatz an: “Kaufen”, Ich habe eine Funktion erstellt, die Daten als Eingabe verwendet und einen KDE-Graphen zeichnet, der die Eigenschaften der Funktion erklärt.


Kategoriale Variable
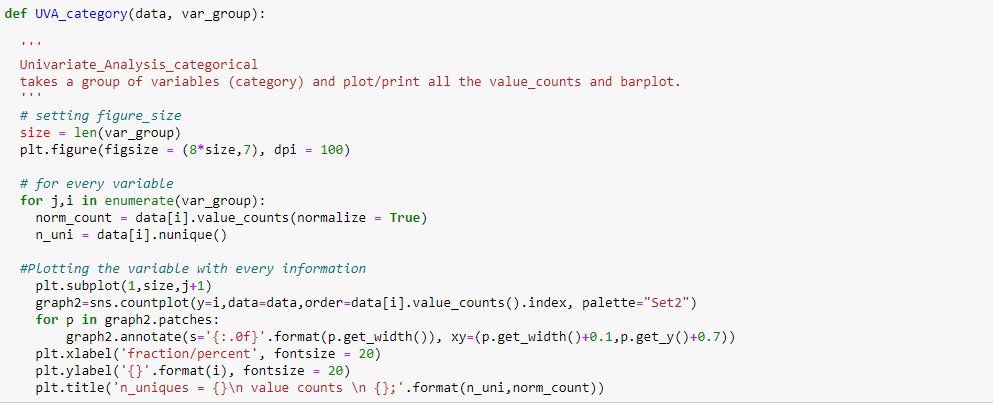
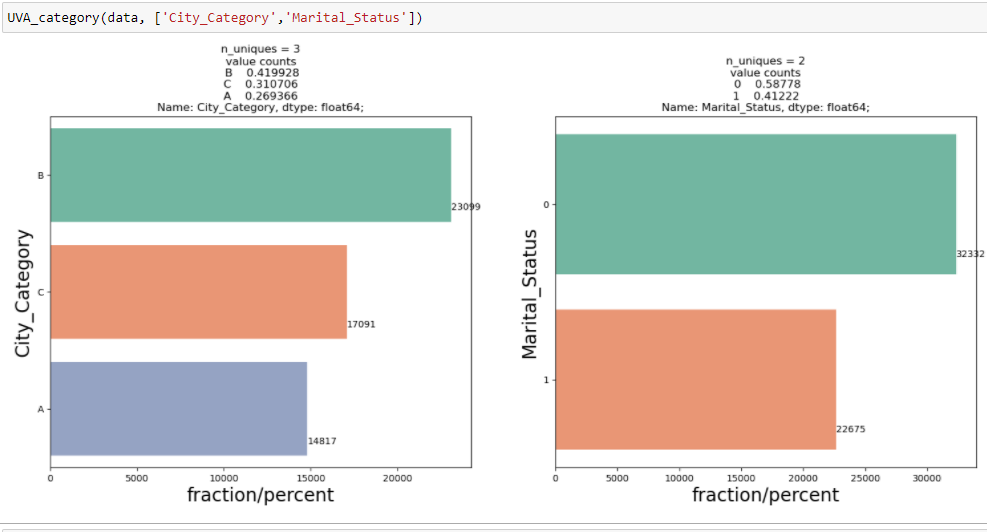
So zeigen Sie univariate Analysen zu kategorialen Variablen im Black Friday-Verkaufsdatensatz an: `City_Category` y` Familienstatus`, Ich habe eine Funktion erstellt, die Daten und Merkmale als Eingabe verwendet, die ein Zähldiagramm zurückgibt, das die Häufigkeit der Kategorien in dem Merkmal erklärt.


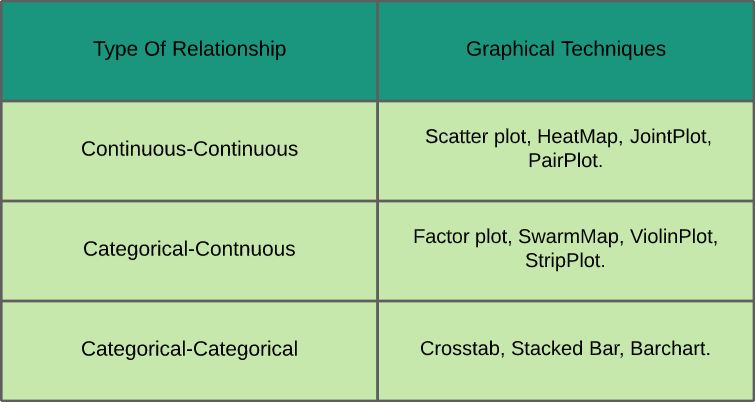
- Bivariate Analyse: In bivariater Analyse, Wir untersuchen die Beziehung zwischen zwei beliebigen Variablen, die kategorisch-stetig sein können, kategorisch-kategorial oder kontinuierlich-kontinuierlich (wie in dem unten gezeigten Referenzblatt zusammen mit den grafischen Techniken gezeigt, die zu ihrer Analyse verwendet wurden).

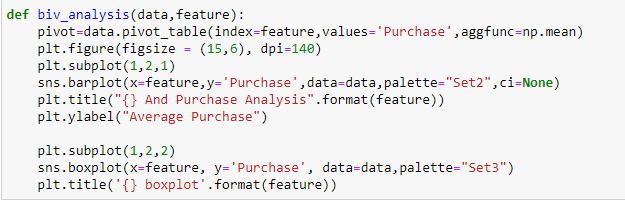
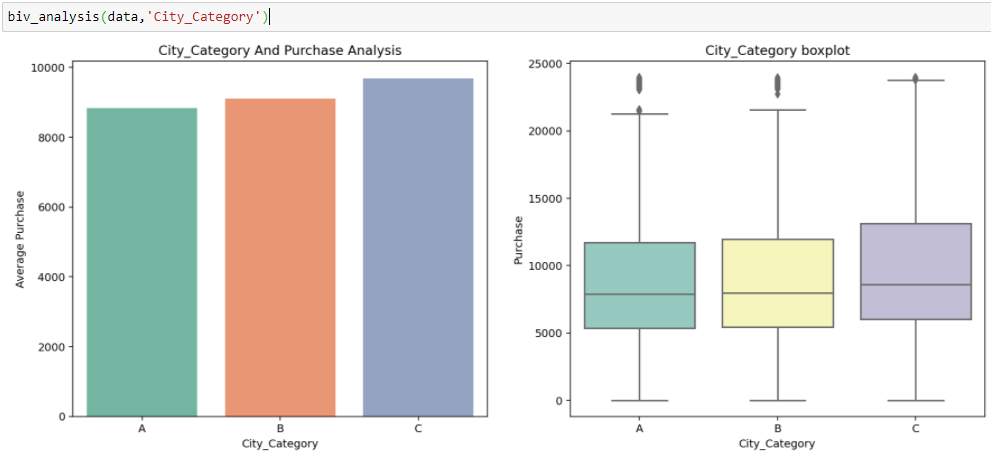
En Black Friday-Verkäufe, wir haben kategoriale unabhängige Variablen und kontinuierliche Zielvariablen, damit wir eine kategorisch-kontinuierliche Analyse durchführen können, um die Beziehung zwischen ihnen zu verstehen.

Inferenz:
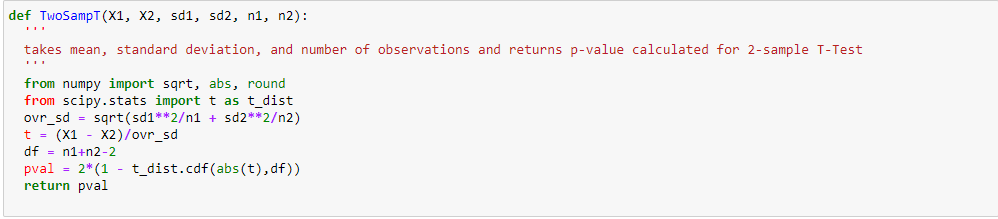
Aus den beiden vorherigen Analysen, Wir haben in der univariaten Analyse beobachtet, dass die Anzahl der Kunden in der Stadtkategorie B maximal ist. Aber die bivariate Analyse, wenn sie zwischen `City_Category` und ` Purchase` durchgeführt wird, zeigt eine andere Geschichte, dass der durchschnittliche Kauf maximal der Stadtkategorie C entspricht, Diese Schlussfolgerungen können uns eine bessere Intuition über die Daten geben, was wiederum zu einer besseren Datenaufbereitung und Feature-Engineering von Features beiträgt.Es ist wichtig zu beachten, dass es ziemlich irreführend sein kann, sich einfach auf univariate und bivariate Analysen zu verlassen., Um die Schlussfolgerungen aus diesen beiden zu überprüfen, können Sie mit validieren Hypothesentest. Wir können einen t-Test machen, Chi-Quadrat-Test, Anova, mit dem wir quantifizieren können, ob zwei Proben signifikant ähnlich sind oder sich voneinander unterscheiden. Hier habe ich eine Funktion erstellt, um kontinuierliche und kategoriale Beziehungen zu analysieren, die den Wert der t-Statistik zurückgeben.


 In der Univariaten Analyse beobachten wir, dass es einen signifikanten Unterschied zwischen der Anzahl der verheirateten und unverheirateten Klienten gibt. Aus dem t-Test, wir erhalten den Wert der Statistik t 0.89, die größer ist als das Signifikanzniveau, nämlich, 0.05, was zeigt, dass es keinen signifikanten Unterschied zwischen dem durchschnittlichen Kauf von Alleinstehenden und Eheleuten gibt.
In der Univariaten Analyse beobachten wir, dass es einen signifikanten Unterschied zwischen der Anzahl der verheirateten und unverheirateten Klienten gibt. Aus dem t-Test, wir erhalten den Wert der Statistik t 0.89, die größer ist als das Signifikanzniveau, nämlich, 0.05, was zeigt, dass es keinen signifikanten Unterschied zwischen dem durchschnittlichen Kauf von Alleinstehenden und Eheleuten gibt. - Behandlung von Wertverlusten : Der Hauptgrund für diesen Schritt ist herauszufinden, ob es einen bestimmten Grund gibt, warum diese Werte fehlen und wie wir sie behandeln. Denn wenn wir sie nicht behandeln, kann das Muster stören, das auf den Daten läuft, was wiederum die Modellleistung verschlechtern kann. Einige der Möglichkeiten, wie mit fehlenden Werten umgegangen werden kann, sind: – Fülle sie mit Medien, Median, Modus und kann Imputer verwenden.
- Ausreißer entfernen : Es ist wichtig, dass wir das Vorhandensein von Ausreißern verstehen, da einige der Vorhersagemodelle empfindlich auf sie reagieren und wir sie entsprechend behandeln sollten.

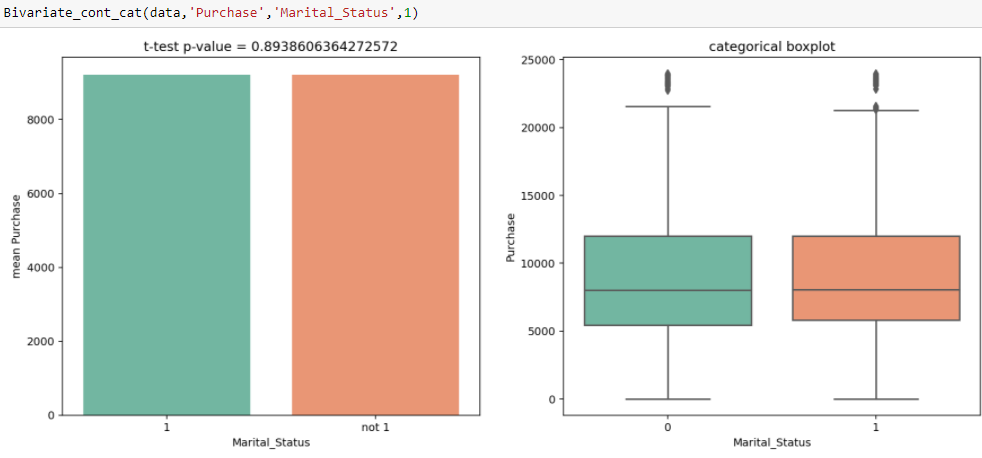 In der Univariaten Analyse beobachten wir, dass es einen signifikanten Unterschied zwischen der Anzahl der verheirateten und unverheirateten Klienten gibt. Aus dem t-Test, wir erhalten den Wert der Statistik t 0.89, die größer ist als das Signifikanzniveau, nämlich, 0.05, was zeigt, dass es keinen signifikanten Unterschied zwischen dem durchschnittlichen Kauf von Alleinstehenden und Eheleuten gibt.
In der Univariaten Analyse beobachten wir, dass es einen signifikanten Unterschied zwischen der Anzahl der verheirateten und unverheirateten Klienten gibt. Aus dem t-Test, wir erhalten den Wert der Statistik t 0.89, die größer ist als das Signifikanzniveau, nämlich, 0.05, was zeigt, dass es keinen signifikanten Unterschied zwischen dem durchschnittlichen Kauf von Alleinstehenden und Eheleuten gibt.Abschließende Anmerkungen
In diesem Artikel, Ich habe kurz die Bedeutung von EDA in der Data-Science-Pipeline und die Schritte besprochen, die zu einer ordnungsgemäßen Analyse gehören. Ich habe auch gezeigt, wie eine falsche oder unvollständige Analyse ziemlich irreführend sein kann und die Leistung von Modellen des maschinellen Lernens erheblich beeinträchtigen kann..
“Wenn Sie Ihre Daten nicht bräunen, du bist nur eine andere person mit einer meinung”;)





