Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Machine Learning ist ein Technologiefeld, das mit immensen Fähigkeiten und Anwendungen in der Automatisierung von Aufgaben entwickelt wird, wo kein menschliches Eingreifen oder explizite Programmierung erforderlich ist.
Die Leistungsfähigkeit des maschinellen Lernens ist so groß, dass wir sehen können, dass seine Anwendungen in unserem täglichen Leben fast überall im Trend liegen.. ML hat viele Probleme gelöst, die es zuvor gab, und Unternehmen in der Welt große Fortschritte gemacht.
Heute, Wir werden eines dieser praktischen Probleme analysieren und eine Lösung finden (Modell) auf eigene Faust mit ML.
Was ist daran so spannend?
Gut, Wir werden unser Modell implementieren, das mit Flask- und Heroku-Anwendungen erstellt wurde. Am Ende, wir werden voll funktionsfähige Webanwendungen in unseren Händen haben.
Warum ist es wichtig, Ihr Modell zu implementieren?
Modelle des maschinellen Lernens zielen im Allgemeinen darauf ab, eine Lösung für ein oder mehrere bestehende Probleme zu sein. Und irgendwann in deinem Leben, Sie müssen sich gedacht haben, wie wäre Ihr Modell eine Lösung und wie würden die Leute dies verwenden?? Eigentlich, Leute können ihre Notizbücher und ihren Code nicht direkt verwenden, und hier müssen Sie Ihr Modell implementieren.
Sie können Ihr Modell implementieren, als API oder Webservice. Hier verwenden wir das Flask Micro-Framework. Flask definiert eine Reihe von Einschränkungen für die Webanwendung zum Senden und Empfangen von Daten.
Achtung Preisvorhersagesystem
Wir sind dabei, ein ML-Modell zur Vorhersage und Analyse von Autoverkaufspreisen zu implementieren. Diese Art von System ist für viele Menschen nützlich.
Stellen Sie sich eine Situation vor, in der Sie ein altes Auto haben und es verkaufen möchten. Natürlich, Sie können sich dafür an einen Makler wenden und den Marktpreis ermitteln, aber später musst du für ihren Service beim Verkauf deines Autos aus Taschengeld bezahlen. Aber, Was ist, wenn Sie den Verkaufspreis Ihres Autos ohne die Intervention eines Agenten herausfinden können?? Oder wenn Sie ein Agent sind, das wird dir die Arbeit auf jeden Fall erleichtern. Jawohl, dieses System hat schon seit Jahren die bisherigen Verkaufspreise diverser Autos kennengelernt.
Dann, deutlich sein, Diese implementierte Webanwendung liefert Ihnen den ungefähren Verkaufspreis Ihres Autos je nach Kraftstoffart, Dienstjahre, der preis des ausstellungsraums, die Anzahl der Vorbesitzer, die gefahrenen Kilometer, wenn Sie ein Händler sind / individuell und schließlich, wenn die Art der Übertragung manuell ist / automatisch. Und das ist ein Brownie-Punkt.
Jede Art von Modifikation kann auch später in diese Anwendung eingearbeitet werden. Es ist nur möglich, später eine Einrichtung zu machen, um Käufer zu treffen. Dies ist eine gute Idee für ein großartiges Projekt, das Sie ausprobieren können. Sie können dies als Anwendung wie OLA oder eine beliebige E-Commerce-Anwendung implementieren. Anwendungen für maschinelles Lernen enden hier nicht. Auf die gleiche Weise, Es gibt endlose Möglichkeiten, die Sie erkunden können. Aber für den Moment, Lassen Sie mich Ihnen helfen, das Modell für die Autopreisvorhersage und den Implementierungsprozess zu erstellen.
Datensatz importieren
Der Datensatz ist im GitHub-Ordner angehängt. Überprüfe hier
Die Daten bestehen aus 300 Reihen und 9 Säulen. Denn unser Ziel ist es, den Verkaufspreis zu finden, das Zielattribut und ist auch der Verkaufspreis, die restlichen Merkmale werden für Analysen und Vorhersagen verwendet.
numpy als np importieren Pandas als pd importieren data = pd.read_csv(r'C:BenutzerSURABHIOneDriveDocumentsprojectsdatasetscar.csv') daten.kopf()
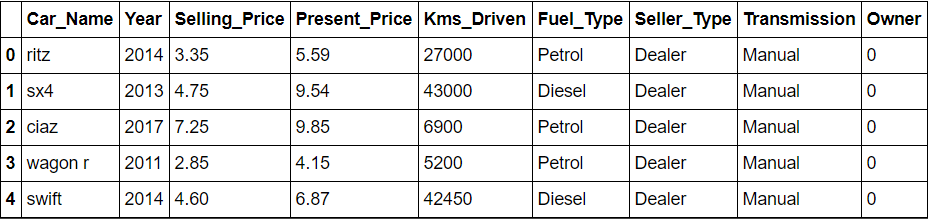
Funktionsengineering
Die Daten. korr () es gibt Ihnen eine Vorstellung von der Korrelation zwischen allen Attributen im Datensatz. Weitere korrelierte Funktionen können entfernt werden, da sie eine übermäßige Passform des Modells verursachen können.
data = data.drop(['Autoname'], Achse=1) Daten['laufendes Jahr'] = 2020 Daten['kein_Jahr'] = Daten['laufendes Jahr'] - Daten['Jahr'] data = data.drop(['Jahr','laufendes Jahr'],Achse = 1) data = pd.get_dummies(Daten,drop_first=Wahr) Daten = Daten[['Verkaufspreis','Gegenwärtiger_Preis','Kms_gefahren','kein_Jahr','Eigentümer','Fuel_Type_Diesel','Fuel_Type_Petrol', 'Seller_Type_Individual','Transmission_Manual']] Daten
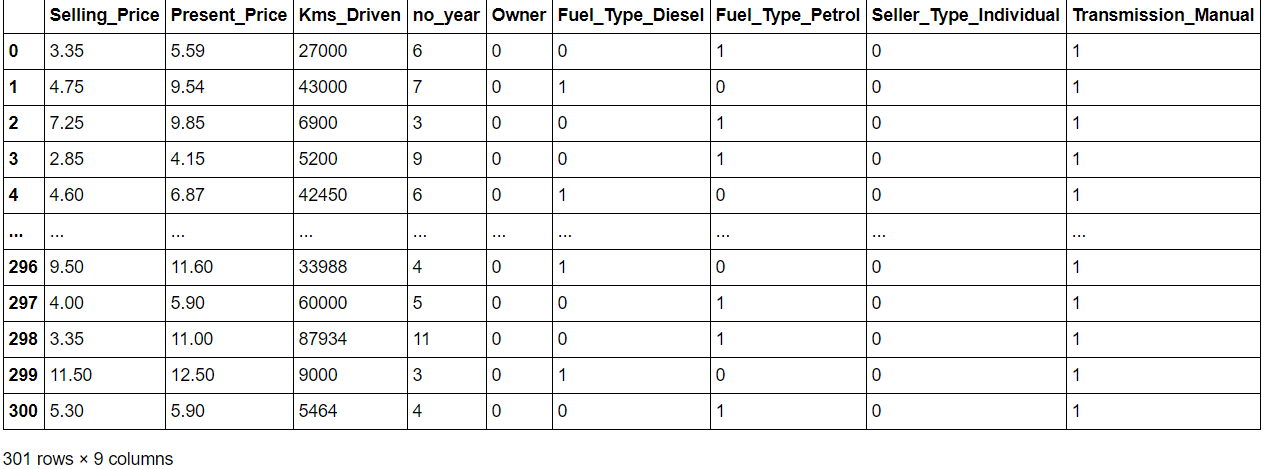
daten.korr()
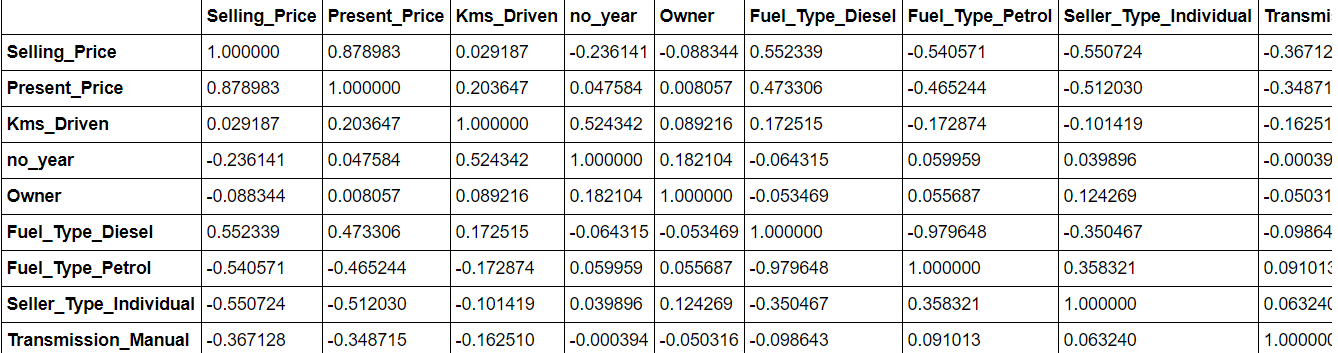
Dann, wir teilen die Daten in Trainings- und Test-Sets auf.
x = data.iloc[:,1:] y = data.iloc[:,0]
Entdecken Sie die Bedeutung von Funktionen, um unerwünschte Funktionen zu eliminieren
Die extratressregressor-Bibliothek ermöglicht es Ihnen, die Bedeutung von Funktionen zu erkennen und, Daher, Entfernen Sie die weniger wichtigen Merkmale der Daten. Es wird immer empfohlen, unnötige Funktionen zu entfernen, da sie definitiv bessere Genauigkeitsergebnisse erzielen können.
von sklearn.ensemble importieren ExtreesRegressor model = ExtraTreesRegressor() model.fit(x,Ja)

model.feature_importances_
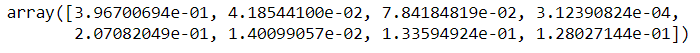
Hyperparameter-Optimierung
Dies geschieht, um die optimalen Werte für den Einsatz in unserem Modell zu erhalten, das kann teilweise auch
helfen, gute Vorhersageergebnisse zu erzielen
n_Schätzer = [int(x) für x in np.linspace(beginnen = 100, Stopp = 1200,num = 12)] max_features = ['Auto','sqrt'] max_tiefe = [int(x) für x in np.linspace(5,30,Zahl = 6)] min_samples_split = [2,5,10,15,100] min_samples_leaf = [1,2,5,10]
Gitter = {'n_Schätzer': n_Schätzer,
'max_features': max_features,
'maximale Tiefe': maximale Tiefe,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf}
drucken(Netz)
# Produktion
{'n_Schätzer': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200],
'max_features': ['Auto', 'sqrt'],
'maximale Tiefe': [5, 10, 15, 20, 25, 30],
'min_samples_split': [2, 5, 10, 15, 100],
'min_samples_leaf': [1, 2, 5, 10]}
Split-Zug-Test
from sklearn.model_selection import train_test_split #Importieren des Zugtest-Split-Moduls x_train, x_test,y_train,y_test = train_test_split(x,Ja,random_state=0,test_size=0.2)
Modell trainieren
Wir haben den Random Forest Regressor verwendet, um Verkaufspreise vorherzusagen, da dies ein Regressionsproblem ist und dieser Random Forest mehrere Entscheidungsbäume verwendet und gute Ergebnisse für mein Modell gezeigt hat.
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor()
hyp = RandomizedSearchCV(Schätzer = Modell,
param_distributions=Gitter,
n_iter=10,
Scoring = 'neg_mean_squared_error'
cv=5, ausführlich = 2,
random_state = 42,n_jobs = 1)
hyp.fit(x_train,y_train)
hyp ist ein Modell, das unter Verwendung der optimalen Hyperparameter erstellt wurde, die durch eine Kreuzvalidierung mit zufälliger Suche erhalten wurden
Produktion
Jetzt verwenden wir das Modell endlich, um den Testdatensatz vorherzusagen.
y_pred = hyp.predict(x_test) y_pred

So verwenden Sie das Flask-Framework für die Bereitstellung, Es ist notwendig, all dieses Modell zu packen und in eine Python-Datei zu importieren, um Webanwendungen zu erstellen. Deswegen, Wir legen unser Modell mit dem angegebenen Code in die Pickle-Datei.
Essiggurke importieren
Datei = öffnen("file.pkl", "wb") # Öffnen einer neuen Datei im Schreibmodus
pickle.dump(hyp, Datei) # Dumping des erstellten Modells in eine Pickle-Datei
Vollständiger Code
https://github.com/SurabhiSuresh22/Car-Price-Prediction/blob/master/car_project.ipynb
Flaschenrahmen
Was wir brauchen, ist eine Webanwendung, die ein Formular enthält, um die Benutzereingaben aufzunehmen und die Vorhersagen des Modells zurückzugeben. Dann, wir werden dafür eine einfache Webanwendung entwickeln. Die Schnittstelle wird mit einfachem HTML und CSS erstellt. Ich empfehle Ihnen, die Grundlagen der Webentwicklung zu überprüfen, um die Bedeutung des Codes zu verstehen, der für die Schnittstelle geschrieben wurde. Es wäre auch toll, wenn ich den Rahmen der Flasche wüsste. Kreuz ist Video wenn Sie neu bei FLASK . sind.
Lass mich dir erklären, knapp, was ich mit FLASK codiert habe.
Dann, Beginnen wir den Code, indem wir alle hier verwendeten Bibliotheken importieren.
aus Flaschenimport Flasche, render_template, Anfrage Essiggurke importieren Importanfragen numpy als np importieren
Woher weißt du das, wir müssen das gespeicherte Modell hier importieren, um die Vorhersagen der vom Benutzer bereitgestellten Daten zu treffen. Wir importieren also das gespeicherte Modell
model = pickle.load(offen("model.pkl", "rb"))
Gehen wir nun zum Code, um die eigentliche Kolbenanwendung zu erstellen.
app = Flasche(_Name_)
@app.route("/") # Dies führt uns zur Startseite, wenn wir auf unseren Web-App-Link klicken
auf jeden Fall zu Hause():
render_template zurückgeben("home.html") # Startseite
@app.route("/Vorhersagen", Methoden = ["POST"]) # Dies funktioniert, wenn der Benutzer auf die Vorhersageschaltfläche klickt
auf jeden Fall vorhersagen():
Jahr = int(Anfrage.Formular["Jahr"]) # Jahreseingabe vom Benutzer nehmen
tot_year = 2020 - Jahr
present_price = float(Anfrage.Formular["Geschenkpreis"]) #den gegenwärtigen Preis entgegennehmen
Fuel_type = request.form["Treibstoffart"] # Kraftstoffart des Autos
# if-Schleife zum Zuweisen von Zahlenwerten
wenn Kraftstofftyp == "Benzin":
Kraftstoff_P = 1
Kraftstoff_D = 0
anders:
Kraftstoff_P = 0
Kraftstoff_D = 1
kms_driven = int(Anfrage.Formular["kms_driven"]) # gefahrene Gesamtkilometer des Autos
Übertragung = Anfrage.Formular["Übertragung"] # Übertragungsart
# Zahlenwerte zuweisen
wenn Übertragung == "Manuel":
Transmission_manual = 1
anders:
Transmission_manual = 0
Seller_type = request.form["Verkäufertyp"] # Verkäufertyp
if seller_type == "Individuell":
Seller_individual = 1
anders:
Seller_individual = 0
Eigentümer = int(Anfrage.Formular["Eigentümer"]) # Anzahl der Besitzer
Werte = [[
Geschenkpreis,
kms_driven,
Eigentümer,
tot_year,
Kraftstoff_D,
Kraftstoff_P,
verkäufer_individuell,
getriebe_manual
]]
# eine Liste aller vom Benutzer eingegebenen Werte erstellt, dann benutze es für die Vorhersage
Vorhersage = model.predict(Werte)
Vorhersage = Runde(Vorhersage[0],2)
# Rückgabe des vorhergesagten Werts zur Anzeige in der Front-End-Webanwendung
render_template zurückgeben("home.html", pred = "Autopreis ist {} Lakh".Format(schweben(Vorhersage)))
wenn _name_ == "_hauptsächlich_":
app.run(debuggen = wahr)
Umsetzung mit Heroku
Alles, was Sie tun müssen, ist Ihr GitHub-Repository, das alle für das Projekt benötigten Dateien enthält, mit Heroku zu verbinden. Für alle die nicht wissen was Heroku ist, Heroku ist eine Plattform, auf der Entwickler erstellen können, Cloud-Anwendungen ausführen und betreiben.
Dies ist der Link zu der Webanwendung, die ich mit der Heroku-Plattform erstellt habe. Dann, Wir haben den Prozess des Aufbaus und der Implementierung eines Modells für maschinelles Lernen gesehen. Kannst du auch machen, Erfahren Sie mehr und fühlen Sie sich frei, neue Dinge auszuprobieren und zu entwickeln.
https://car-price-analysis-app.herokuapp.com/
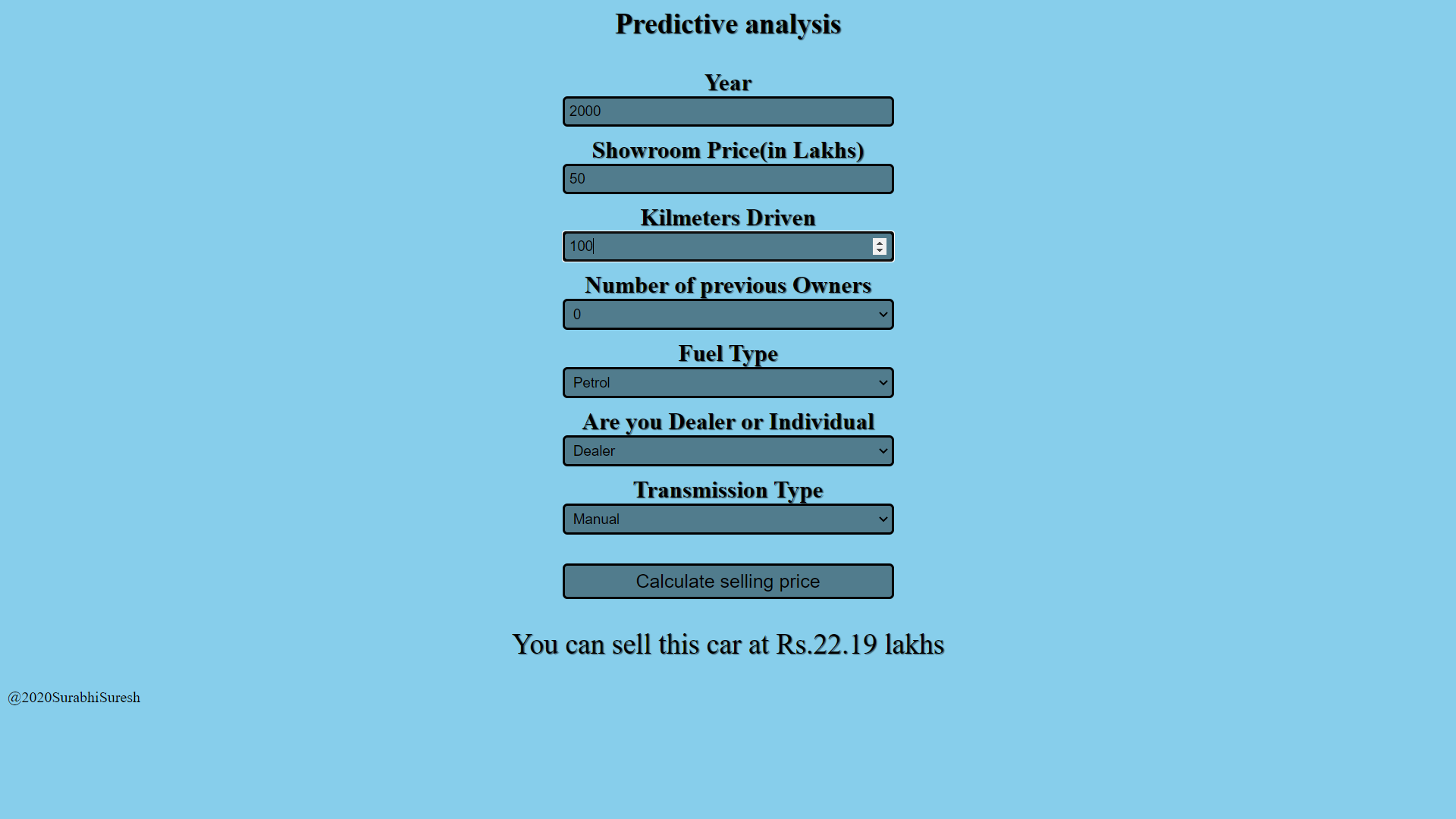
Fazit
Dann, Wir haben den Prozess des Aufbaus und der Implementierung eines Modells für maschinelles Lernen gesehen. Kannst du auch machen, Erfahren Sie mehr und fühlen Sie sich frei, neue Dinge auszuprobieren und zu entwickeln. Fühlen Sie sich frei, mit mir in Verbindung zu treten verlinkt in.
Vielen Dank
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





