Bisherige Anforderungen: Grundlegende Programmiersprache R und Grundkenntnisse der Klassifikation
Während der Validierungssatzansatz funktioniert, indem der Datensatz einmal geteilt wird, k-Fold macht es fünf oder zehn Mal. Stellen Sie sich vor, Sie führen den Validierungssatzansatz zehnmal mit einem anderen Datensatz durch.
Sagen wir, wir haben 100 Datenzeilen. Wir teilen sie nach dem Zufallsprinzip in zehn Gruppen von Falten ein. Jede Falte besteht aus ca. 10 Datenzeilen. El primer pliegue se utilizará como conjunto de validación y el resto es para el conjunto de AusbildungTraining ist ein systematischer Prozess zur Verbesserung der Fähigkeiten, körperliche Kenntnisse oder Fähigkeiten. Es wird in verschiedenen Bereichen angewendet, wie Sport, Aus- und Weiterbildung. Zu einem effektiven Trainingsprogramm gehört auch die Zielplanung, Regelmäßiges Üben und Bewerten der Fortschritte. Anpassung an individuelle Bedürfnisse und Motivation sind Schlüsselfaktoren, um in jeder Disziplin erfolgreiche und nachhaltige Ergebnisse zu erzielen..... Anschließend trainieren wir unser Modell mit diesem Datensatz und berechnen die Präzision oder den Verlust. Dann wiederholen wir diesen Vorgang, verwenden jedoch eine andere Faltung für den Validierungssatz. Siehe das Bild unten.
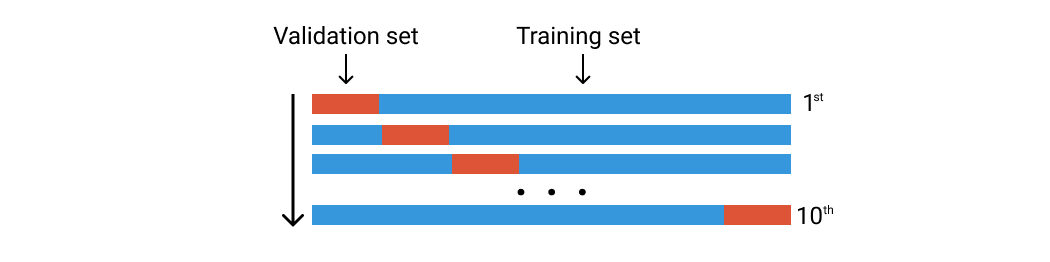
Kreuzvalidierung von K-Fold. Bild des Autors
Kommen wir zum Code
Die von uns verwendeten Bibliotheken sind diese beiden:
Bücherei(ordentlichversum) Bücherei(Caret)
Die hier verwendeten Daten sind Herzkrankheitsdaten der Intensivstation, die heruntergeladen werden können unter Kaggle. Sie können für dieses Experiment auch beliebige Klassifizierungsdaten verwenden.
Daten <- lesen.csv("../input/herzkrankheit-uci/heart.csv")
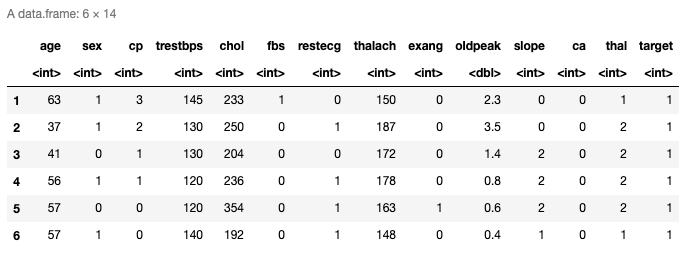
Kopf(Daten)
Hier sind die oberen sechs Zeilen der geladenen Daten. Tiene trece predictores y la última columna es la VariableIn Statistik und Mathematik, ein "Variable" ist ein Symbol, das einen Wert darstellt, der sich ändern oder variieren kann. Es gibt verschiedene Arten von Variablen, und qualitativ, die nicht-numerische Eigenschaften beschreiben, und quantitative, numerische Größen darstellen. Variablen sind grundlegend in Experimenten und Studien, da sie die Analyse von Beziehungen und Mustern zwischen verschiedenen Elementen ermöglichen, das Verständnis komplexer Phänomene zu erleichtern.... de respuesta. Sie können die letzten Zeilen auch mit der Schwanzfunktion überprüfen ().
Datenverteilung
Hier wollen wir bestätigen, dass die Verteilung zwischen den Daten zweier Labels nicht sehr unterschiedlich ist. Weil unausgeglichene Datensätze zu unausgeglichener Genauigkeit führen können. Das bedeutet, dass Ihr Modell immer auf ein einzelnes Label prognostiziert., oder wird immer vorhersagen 0 Ö 1.
hist(Daten$Ziel,col="Koralle") prop.tabelle(Tisch(Daten$Ziel))
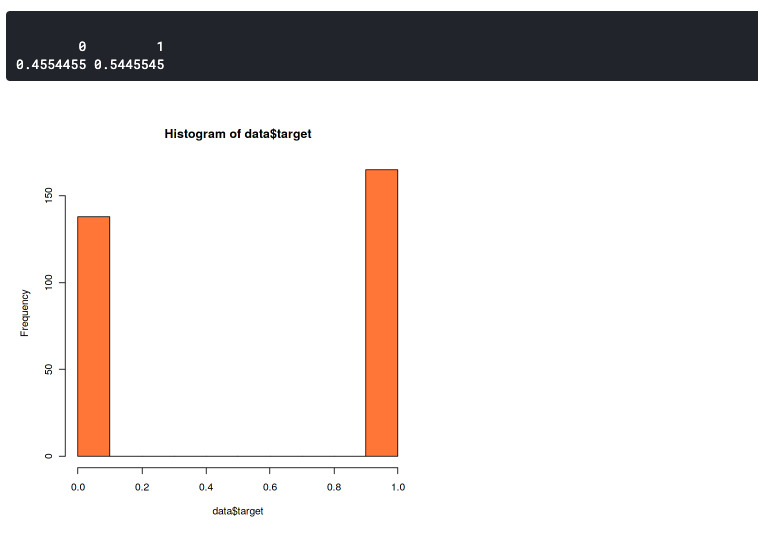
Diese Grafik zeigt, dass unser Datensatz etwas unausgeglichen, aber immer noch gut genug ist. Es hat ein Verhältnis von 46:54. Sie sollten sich Sorgen machen, wenn Ihr Datensatz mehr als 60% der Daten in einer Klasse. Dann, Sie können SMOTE verwenden, um einen unausgeglichenen Datensatz zu verarbeiten.
Die k-Falte
set.seed(100) trctrl <- trainControl(Methode = "Lebenslauf", Zahl = 10, savePredictions=TRUE) nb_fit <- Bahn(Faktor(Ziel) ~., Daten = Daten, Methode = "naiv_bayes", trControl=trctrl, tuneLänge = 0) nb_fit
Die erste Zeile besteht darin, den Samen des Pseudozufalls so zu setzen, dass das gleiche Ergebnis reproduziert werden kann. Sie können eine beliebige Zahl für den Anfangswert verwenden.
Dann, wir können die k-Fold-Einstellung in der trainControl-Funktion einstellen (). Stellen Sie den Methodenparameter auf „cv“ und den numerischen Parameter auf 10. Das bedeutet, dass wir die Kreuzvalidierung mit zehn Falten festlegen. Wir können die Falznummer mit einer beliebigen Zahl festlegen, aber die gebräuchlichste Methode ist die Einstellung auf fünf oder zehn.
Die Zugfunktion () wird verwendet, um die von uns verwendete Methode zu bestimmen. Hier verwenden wir die Naive Bayes-Methode und setzen tuneLength auf Null, da wir uns darauf konzentrieren, die Methode für jede Falte zu bewerten. También podemos establecer tuneLength si queremos hacer el ajuste de ParameterDas "Parameter" sind Variablen oder Kriterien, die zur Definition von, ein Phänomen oder System zu messen oder zu bewerten. In verschiedenen Bereichen wie z.B. Statistik, Informatik und naturwissenschaftliche Forschung, Parameter sind entscheidend für die Etablierung von Normen und Standards, die die Datenanalyse und -interpretation leiten. Ihre richtige Auswahl und Handhabung sind entscheidend, um genaue und relevante Ergebnisse in jeder Studie oder jedem Projekt zu erhalten.... durante la validación cruzada. Zum Beispiel, wenn wir die K-NN-Methode verwenden und analysieren möchten, wie viele K für unser Modell am besten sind.
Sie können die unterstützte Methode in . sehen Dokumentation R.
Bitte beachten Sie, dass die Kreuzvalidierung von k-Fold eine Weile dauern kann, da Sie den Trainingsprozess zehn Mal durchlaufen.
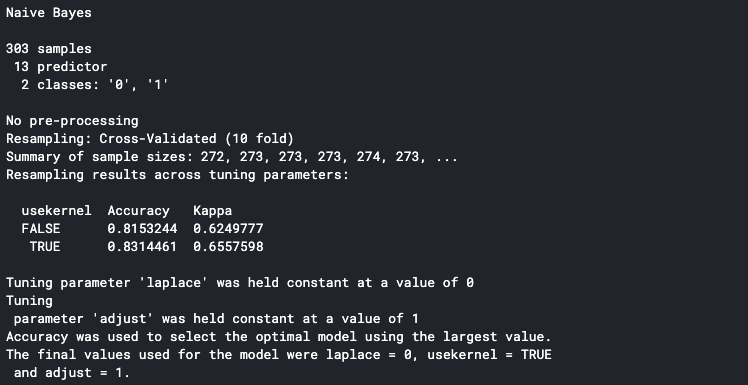
Es druckt die Details an die Konsole, sobald es fertig ist. Die auf der Konsole angezeigte Genauigkeit ist die durchschnittliche Genauigkeit aller Trainingsfalten. Wir können sehen, dass unser Modell eine durchschnittliche Genauigkeit von hat 83%.
Entfalte die K-Falte
Wir können feststellen, dass unser Modell in jeder Falte gut abschneidet, indem wir die Präzision jeder Falte betrachten.. Um dies zu tun, stellen Sie sicher, dass speichernVorhersagen Parameter auf TRUE in der trainControl-Funktion ().
pred <- nb_fit$pred pred$gleich <- ansonsten(pred $ pred == pred $ obs, 1,0)
jedesmal <- Vor%>%
gruppiere nach(Resample) %>%
zusammenfassen_at(deren(gleich),
aufführen(Genauigkeit = Mittelwert))
jedesmal
Hier ist die Präzisionstabelle in jeder Falte.

Wir können es auch in die Grafik einzeichnen, um die Analyse zu erleichtern. In diesem Fall, wir verwenden den Boxplot, um unsere Genauigkeiten darzustellen.
ggplot(data=eachfold, aes(x=Resample, y=Genauigkeit, Gruppe=1)) + geom_boxplot(Farbe="kastanienbraun") + geom_point() + thema_minimal()
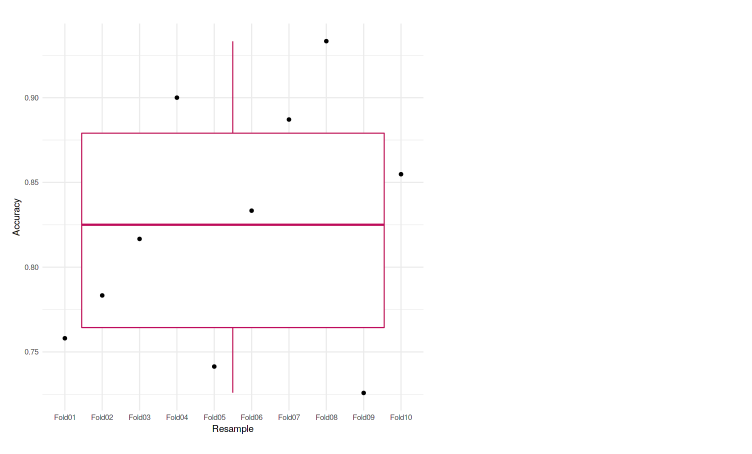
Wir können sehen, dass jede der Falten eine Präzision erreicht, die sich nicht viel voneinander unterscheidet. Die niedrigste Genauigkeit ist 72,58%, und auch im Boxplot, Wir sehen keine Ausreißer. Das bedeutet, dass unser Modell bei der Kreuzvalidierung von k mal gut funktioniert hat.
Was kommt als nächstes
- Probieren Sie eine andere Anzahl von Falten aus
- Nehmen Sie eine Parametereinstellung vor
- Andere Datensätze und Methoden verwenden
Kurzbiographie des Autors
Ich heiße Muhammad Arnold, ein Enthusiast für maschinelles Lernen und Data Science. Derzeit Masterstudent in Informatik in Indonesien.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





